图解HIVE累积型快照事实表
Posted 小基基o_O
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图解HIVE累积型快照事实表相关的知识,希望对你有一定的参考价值。
概述
-
什么是事实表?
每行数据代表一个业务事件,通常有很多外键(地区、用户…)
业务事件可以是:下单、支付、退款、评价…
业务事件有数字度量,如:数量、金额、次数…
行数较多,列数较少
每天很多新增 -
事实表的分类
| 分类 | 说明 | 特点 | 场景 |
|---|---|---|---|
| 事务型事实表 | 以每个事务为单位 | 数据只追加不修改 | 一个订单支付 一笔订单退款 |
| 周期型快照事实表 | 保留固定时间间隔的数据 | 不会保留所有数据 | 点赞数 |
| 累积型快照事实表 | 跟踪业务事实的变化 | 数据可修改 | 订单状态 |
- 本文以订单状态表为例
行转多列

1、按
订单ID分组,聚合订单状态和时间,转为MAP
SELECT
order_id,
STR_TO_MAP(CONCAT_WS(',',COLLECT_SET(CONCAT(order_status,'=',operation_time))),',','=') m
FROM
ods_order_status
GROUP BY
order_id
打印结果
+--------+----------------------------------------------------------+
|order_id|m |
+--------+----------------------------------------------------------+
|P2 |[end -> 2020-01-01 23:45:00, start -> 2020-01-01 22:45:00]|
|P3 |[start -> 2020-01-01 23:30:00] |
|P1 |[start -> 2020-01-01 08:00:00, end -> 2020-01-01 08:01:00]|
+--------+----------------------------------------------------------+
2、按Key获取MAP值
WITH
t1 AS (
SELECT
order_id,
STR_TO_MAP(CONCAT_WS(',',COLLECT_SET(CONCAT(order_status,'=',operation_time))),',','=') m
FROM
ods_order_status
GROUP BY
order_id
)
SELECT
order_id,
m['start'] start_time,
m['end'] end_time
FROM
t1
打印结果
+--------+-------------------+-------------------+
|order_id|start_time |end_time |
+--------+-------------------+-------------------+
|P2 |2020-01-01 22:45:00|2020-01-01 23:45:00|
|P3 |2020-01-01 23:30:00|null |
|P1 |2020-01-01 08:00:00|2020-01-01 08:01:00|
+--------+-------------------+-------------------+
数仓详细
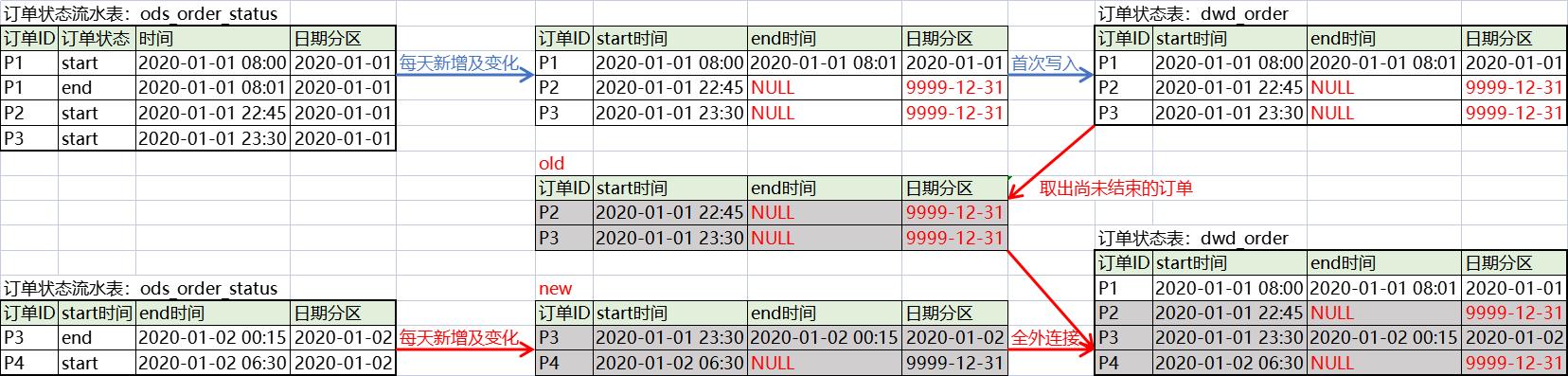
数据路径
| 表名 | 表名 | 路径 | 策略 | 备注 |
|---|---|---|---|---|
| ods_order | 订单表 | sqoop > hdfs > ods | 增量变化同步 按 create_time和operate_time | 此处省略 |
| ods_order_status | 订单状态流水表 | sqoop > hdfs > ods | 增量同步 按 operate_time | |
| dwd_order | 订单表 | ods > dwd | 未结束订单写到9999-12-31分区结束订单按结束日期写到日期分区 |
代码
1、数据准备
-- 建库:e-commerce
DROP DATABASE IF EXISTS ec CASCADE;
CREATE DATABASE ec LOCATION '/ec';
USE ec;
-- 建表:原始层,订单状态表
DROP TABLE IF EXISTS ec.ods_order_status;
CREATE TABLE ec.ods_order_status (
order_id STRING,
order_status STRING,
operation_time STRING)
PARTITIONED BY (ymd STRING)
LOCATION '/ec/ods_order_status';
-- 建表:明细层,订单(累积型快照事实)表
DROP TABLE IF EXISTS ec.dwd_order;
CREATE TABLE ec.dwd_order (
order_id STRING,
start_time STRING,
end_time STRING)
PARTITIONED BY (ymd STRING)
LOCATION '/ec/dwd_order';
-- 造数据,写到原始层
INSERT INTO TABLE ec.ods_order_status PARTITION(ymd='2020-01-01') VALUES
("P1","start","2020-01-01 08:00:00"),
("P1","end","2020-01-01 08:01:00"),
("P2","start","2020-01-01 22:45:00"),
("P3","start","2020-01-01 23:30:00");
INSERT INTO TABLE ec.ods_order_status PARTITION(ymd='2020-01-02') VALUES
("P3","end","2020-01-02 00:15:00"),
("P4","start","2020-01-02 06:30:00");
2、设置动态分区
-- 开启动态分区功能
SET hive.exec.dynamic.partition=true;
-- 设置动态分区为非严格模式
SET hive.exec.dynamic.partition.mode=nonstrict;
3、第一天数据写入
数据查询
WITH
t1 AS(
SELECT
order_id,
STR_TO_MAP(CONCAT_WS(',',COLLECT_SET(CONCAT(order_status,'=',operation_time))),',','=') m
FROM ec.ods_order_status
WHERE ymd='2020-01-01'
GROUP BY order_id
)
SELECT
order_id,
m['start'] start_time,
m['end'] end_time,
CASE
WHEN m['end'] IS NOT NULL THEN '2020-01-01'
ELSE '9999-12-31'
END ymd
FROM t1;
查询结果
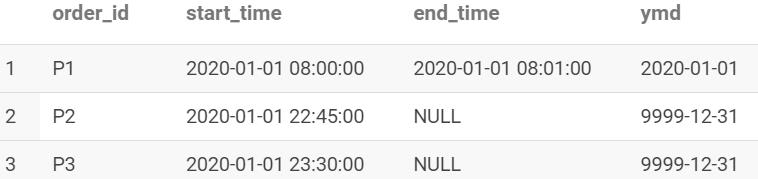
数据写入
注意:语法要求WITH写在INSERT前面
WITH
t1 AS(
SELECT
order_id,
STR_TO_MAP(CONCAT_WS(',',COLLECT_SET(CONCAT(order_status,'=',operation_time))),',','=') m
FROM ec.ods_order_status
WHERE ymd='2020-01-01'
GROUP BY order_id
)
INSERT OVERWRITE TABLE ec.dwd_order PARTITION(ymd)
SELECT
order_id,
m['start'] start_time,
m['end'] end_time,
CASE
WHEN m['end'] IS NOT NULL THEN '2020-01-01'
ELSE '9999-12-31'
END ymd
FROM t1;
写入后结果

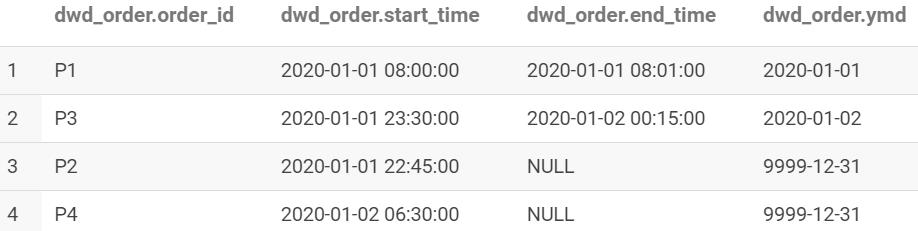
4、第二天数据写入
数据查询
WITH
t1 AS(
SELECT
order_id,
STR_TO_MAP(CONCAT_WS(',',COLLECT_SET(CONCAT(order_status,'=',operation_time))),',','=')m
FROM ec.ods_order_status
WHERE ymd='2020-01-02'
GROUP BY order_id
),
new AS(
SELECT
order_id,
m['start'] start_time,
m['end'] end_time,
CASE
WHEN m['end'] IS NOT NULL THEN '2020-01-02'
ELSE '9999-12-31'
END ymd
FROM
t1
),
old AS (SELECT * FROM ec.dwd_order WHERE ymd='9999-12-31')
SELECT
NVL(new.order_id,old.order_id) order_id,
NVL(new.start_time,old.start_time) start_time,
NVL(new.end_time,old.end_time) end_time,
NVL(new.ymd,old.ymd) ymd
FROM new
FULL OUTER JOIN old
ON new.order_id=old.order_id;
查询结果

数据写入
注意:语法要求WITH写在INSERT前面
WITH
t1 AS(
SELECT
order_id,
STR_TO_MAP(CONCAT_WS(',',COLLECT_SET(CONCAT(order_status,'=',operation_time))),',','=')m
FROM ec.ods_order_status
WHERE ymd='2020-01-02'
GROUP BY order_id
),
new AS(
SELECT
order_id,
m['start'] start_time,
m['end'] end_time,
CASE
WHEN m['end'] IS NOT NULL THEN '2020-01-02'
ELSE '9999-12-31'
END ymd
FROM
t1
),
old AS (SELECT * FROM ec.dwd_order WHERE ymd='9999-12-31')
INSERT OVERWRITE TABLE ec.dwd_order PARTITION(ymd)
SELECT
NVL(new.order_id,old.order_id) order_id,
NVL(new.start_time,old.start_time) start_time,
NVL(new.end_time,old.end_time) end_time,
NVL(new.ymd,old.ymd) ymd
FROM new
FULL OUTER JOIN old
ON new.order_id=old.order_id;
写入后结果
补充
上面的订单状态比较简单,这个全一点,SQL的思路是一样的