Greenplum 实时数据仓库实践——事实表技术
Posted wzy0623
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Greenplum 实时数据仓库实践——事实表技术相关的知识,希望对你有一定的参考价值。
目录
上一篇里介绍了几种基本的维度表技术,并用示例演示了每种技术的实现过程。本篇说明多维数据仓库中常见的事实表技术。我们将讲述五种基本事实表扩展技术,分别是周期快照、累积快照、无事实的事实表、迟到的事实和累积度量。和讨论维度表一样,也会从概念开始认识这些技术,继而给出常见的使用场景,最后以销售订单数据仓库为例,给出实现代码和测试过程。
8.1 事实表概述
发生在业务系统中的操作型事务,其所产生的可度量数值,存储在事实表中,从最细节粒度级别看,事实表和操作型事务表的数据有一一对应的关系。因此,数据仓库中事实表的设计应该依赖于业务系统,而不受可能产生的最终报表影响。除数字类型的度量外,事实表总是包含所引用维度表的外键,也能包含可选的退化维度键或时间戳。数据分析的实质就是基于事实表开展计算和聚合操作。
事实表中的数字度量值可划分为可加、半可加、不可加三类。可加性度量可以按照与事实表关联的任意维度汇总,就是说按任何维度汇总得到的度量和是相同的,事实表中的大部分度量属于此类。半可加度量可以对某些维度汇总,但不能对所有维度汇总。余额是常见的半可加度量,除时间维度外,它们可以跨所有维度进行加法操作。另外还有些度量是完全不可加的,例如比例。对非可加度量,较好的处理方法是尽可能存储构成非可加度量的可加分量,如构成比例的分子和分母,并将这些分量汇总到最终的结果集合中,而对不可加度量的计算通常发生在BI层或OLAP层。
事实表中可以存在空值度量。所有聚合函数,如sum、count、min、max、avg等均可针对空值度量计算,其中sum、count(字段名)、min、max、avg会忽略空值,而count(1)或count(*)在计数时会将空值包含在内。然而,事实表中的外键不能存在空值,否则会导致违反参照完整性的情况发生。关联的维度表必须用默认代理键而不是空值表示未知的条件。
很多情况下数据仓库需要装载如下三种不同类型的事实表。
- 事务事实表:以每个事务或事件为单位,例如一个销售订单记录、一笔转账记录等,作为事实表里的一行数据。这类事实表可能包含精确的时间戳和退化维度键,其度量值必须与事务粒度保持一致。销售订单数据仓库中的sales_order_fact表就是事务事实表。
- 周期快照事实表:这种事实表里并不保存全部数据,只保存固定时间间隔的数据,例如每天或每月的销售额,或每月的账户余额等。
- 累积快照事实表:累积快照用于跟踪事实表的变化。例如,数据仓库可能需要累积或存储销售订单从下订单的时间开始,到订单中的商品被打包、运输和到达的各阶段的时间点数据来跟踪订单生命周期的进展情况。当这个过程进行时,随着以上各种时间的出现,事实表里的记录也要不断更新。
8.2 周期快照
周期快照事实表中的每行汇总了发生在某一标准周期,如一天、一周或一月的多个度量,其粒度是周期性的时间段,而不是单个事务。周期快照事实表通常包含许多数据的总计,因为任何与事实表时间范围一致的记录都会被包含在内。在这些事实表中,外键的密度是均匀的,因为即使周期内没有活动发生,通常也会在事实表中为每个维度插入包含0或空值的行。
周期快照是在一个给定的时间对事实表进行一段时期的总计。有些数据仓库用户,尤其是业务管理者或者运营部门,经常要看某个特定时间点的汇总数据。下面在示例数据仓库中创建一个月销售订单周期快照,用于按产品统计每个月总的销售订单金额和产品销售数量。
1. 建立周期快照表
假设需求是要按产品统计每个月的销售金额和销售数量。单从功能上看,此数据能够从事务事实表中直接查询得到。例如,要取得2021年12月的销售数据,可使用下面的查询:
select b.month_sk, a.product_sk, sum(order_amount), sum(order_quantity)
from sales_order_fact a,
month_dim b,
order_date_dim d
where a.order_date_sk = d.order_date_sk
and b.month = d.month
and b.year = d.year
and b.month = 12
and b.year = 2021
group by b.month_sk, a.product_sk;只要将年、月参数传递给这条查询语句,就可以获得任何年月的统计数据。但即便是在如此简单的场景下,我们仍然需要建立独立的周期快照事实表。事务事实表的数据量都会很大,如果每当需要月销售统计数据时,都从最细粒度的事实表查询,那么性能将会差到不堪忍受的程度。再者,月统计数据往往只是下一步数据分析的输入信息,有时把更复杂的逻辑放到一个单一的查询语句中效率会更差。因此,好的做法是将事务型事实表作为一个基石事实数据,以此为基础,向上逐层建立需要的快照事实表。图8-1中的模式显示了一个名为month_end_sales_order_fact的周期快照事实表。
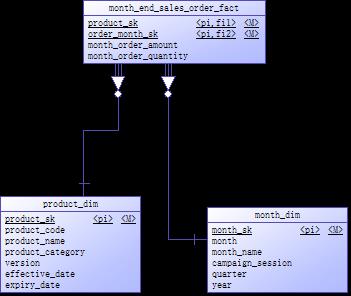
图8-1 月销售统计周期快照事实表
新的周期快照事实表中有两个度量值,month_order_amount和month_order_quantity。这两个值是不能加到sales_order_fact表中的,因为sales_order_fact表和新的度量值有不同的时间属性,也即数据的粒度不同。sales_order_fact表包含的是单一事务记录,新的度量值存的是每月的汇总数据。销售周期快照是一个普通的引用两个维度的事实表。月份维度表包含以月为粒度的销售周期描述符。产品代理键对应有效的产品维度行,也就是给定报告月的最后一天对应的产品代理键,以保证月末报表是对当前产品信息的准确描述。快照中的事实包含每月的数字度量和计数,它们是可加的。使用下面的脚本建立month_end_sales_order_fact表,由于是新建表,不需要事先停止Canal服务。
set search_path=tds;
create table month_end_sales_order_fact (
order_month_sk int,
product_sk int,
year_month int,
month_order_amount decimal(10,2),
month_order_quantity bigint,
primary key (order_month_sk, product_sk, year_month)
) distributed by (order_month_sk)
partition by range (year_month)
( partition p202106 start (202106) inclusive ,
partition p202107 start (202107) inclusive ,
partition p202108 start (202108) inclusive ,
partition p202109 start (202109) inclusive ,
partition p202110 start (202110) inclusive ,
partition p202111 start (202111) inclusive ,
partition p202112 start (202112) inclusive ,
partition p202201 start (202201) inclusive ,
partition p202202 start (202202) inclusive ,
partition p202203 start (202203) inclusive
end (202204) exclusive );和销售订单事实表一样,月销售周期快照表也以年月做分区。这样做主要有两点好处:
- 按年月查询周期快照表时,可以利用分区消除提高性能。
- 便于维护周期快照事实表,可以单独清空分区对应的子表,或删除分区。
2. 初始装载
建立了month_end_sales_order_fact表后,现在需要向表中装载数据。实际装载时,月销售周期快照事实表的数据源是已有的销售订单事务事实表,而并没有关联产品维度表。之所以可以这样做,是因为事务事实表先于周期快照事实表被处理,并且事务事实表中的产品代理键就是当时有效的产品描述。这样做还有一个好处是,不必要非在1号装载上月的数据。执行下面的语句初始装载月销售数据。
insert into month_end_sales_order_fact
select month_sk, product_sk, year_month, coalesce(sum(order_amount),0),coalesce(sum(order_quantity),0)
from sales_order_fact, month_dim
where year_month = year*100+month
and year_month < to_char(current_date,'yyyymm')::integer
group by month_sk,product_sk,year_month; 3. 定期装载
按月汇总只需要定期执行,不涉及实时性问题。fn_month_sum函数用于定期装载月销售订单周期快照事实表,函数定义如下。
create or replace function tds.fn_month_sum(p_year_month int)
returns void as $$
declare
sqlstring varchar(1000);
begin
-- 幂等操作,先删除上月数据
sqlstring := 'truncate table month_end_sales_order_fact_1_prt_p' || cast(p_year_month as varchar);
execute sqlstring;
-- 插入上月销售汇总数据
insert into month_end_sales_order_fact
select month_sk, product_sk, t1.year_month, coalesce(t2.month_order_amount,0),coalesce(t2.month_order_quantity,0)
from (select month_sk, year*100+month year_month from month_dim
where year*100+month = p_year_month) t1
left join (select product_sk, year_month, sum(order_amount) month_order_amount,sum(order_quantity) month_order_quantity
from sales_order_fact where year_month = p_year_month
group by product_sk,year_month) t2
on t1.year_month = t2.year_month;
end; $$
language plpgsql;执行以下语句装载上个月的销售汇总数据。该语句可重复执行,汇总数据不会重复累加。
select tds.fn_month_sum(cast(extract(year from current_date - interval '1 month') * 100 + extract(month from current_date - interval '1 month') as int));周期快照表的外键密度是均匀的,因此这里使用外连接关联月份维度和事务事实表。即使上个月没有任何销售记录,周期快照中仍然会有一行记录。在这种情况下,周期快照记录中只有年月,而产品代理键的值为空,度量为0。查询销售订单事实表时可以利用分区消除提高性能。
每个月给定的任何一天,执行一次fn_month_sum函数,装载上个月的销售订单汇总数据。Greenplum没有提供如PostgreSQL中的pg_cron、mysql中的event、Oracle中的dbms_scheduler或dbms_job等定时任务功能组件,只能通过操作系统的crontab,或者类似于Oozie的外部工具定时调度。例如,crontab在每月10号2点执行:
0 2 10 * * dt=$(date -d '1 month ago' +%Y%m);psql -d dw -c "select tds.fn_month_sum($dt) as int;" 有时我们创建了一个crontab任务,但是这个任务却无法自动执行,而手动执行脚本却没有问题,这种情况一般是由于在crontab文件中没有配置环境变量引起的。cron从用户所在的主目录,使用shell调用需要执行的命令。cron为每个shell提供了一个缺省的环境,Linux下的定义如下:
SHELL=/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=用户名
HOME=用户主目录在crontab文件中定义多个调度任务时,需要特别注意的一个问题就是环境变量的设置,因为我们手动执行某个脚本时,是在当前shell环境下进行的,程序能找到环境变量,而系统自动执行任务调度时,除了缺省的环境,是不会加载任何其它环境变量的。因此就需要在crontab文件中指定任务运行所需的所有环境变量。
不要假定cron知道所需要的特殊环境,它其实并不知道。所以用户要保证在shell脚本中提供所有必要的路径和环境变量,除了一些自动设置的全局变量。以下三点需要注意:
- 脚本中涉及文件路径时写绝对路径。
- 脚本执行要用到环境变量时,通过source命令显式引入,例如:
#!/bin/sh
source /etc/profile- 当手动执行脚本没问题,但是crontab不执行时,可以尝试在crontab中直接引入环境变量解决问题,例如:
0 * * * * . /etc/profile;/bin/sh /path/to/myscript.sh关于Oozie的配置和使用参见“基于Hadoop生态圈的数据仓库实践 —— ETL(三)”。
4. 测试
首先清空上个月的周期快照数据:
truncate table month_end_sales_order_fact_1_prt_p202112;然后在shell脚本:
dt=$(date -d '1 month ago' +%Y%m);psql -d dw -c "select tds.fn_month_sum($dt) as int;"执行成功后查询month_end_sales_order_fact表,结果如下。可以看到,已经生成了上个月的销售汇总周期快照数据。
dw=> select * from month_end_sales_order_fact order by year_month;
order_month_sk | product_sk | year_month | month_order_amount | month_order_quantity
----------------+------------+------------+--------------------+----------------------
18 | 1 | 202106 | 42985.00 | 0
18 | 2 | 202106 | 85304.00 | 0
19 | 2 | 202107 | 59831.00 | 0
19 | 1 | 202107 | 74012.00 | 0
20 | 1 | 202108 | 85951.00 | 0
20 | 2 | 202108 | 52528.00 | 0
21 | 2 | 202109 | 88138.00 | 0
21 | 1 | 202109 | 85835.00 | 0
24 | 1 | 202112 | 32268.00 | 150
24 | 4 | 202112 | 100506.00 | 638
24 | 2 | 202112 | 72229.00 | 415
24 | 5 | 202112 | 31233.00 | 75
(12 rows)8.3 累积快照
累积快照事实表用于定义业务过程开始、结束以及期间的可区分的里程碑事件。通常在此类事实表中针对过程中的关键步骤都包含日期外键,并包含每个步骤的度量,这些度量的产生一般都会滞后于数据行的创建时间。累积快照事实表中的一行,对应某一具体业务的多个状态。例如,当订单产生时会插入一行。当该订单的状态改变时,累积事实表行被访问并修改。这种对累积快照事实表行的一致性修改在三种类型的事实表(事务、周期快照、累积快照)中具有独特性,对于前面介绍的两类事实表只追加数据,不会对已经存在的行进行更新操作。除了日期外键与每个关键过程步骤关联外,累积快照事实表中还可以包含其他维度和可选退化维度的外键。
累积快照事实表在库存、采购、销售、电商等业务领域都有广泛应用。比如在电商订单里面,下单的时候只有下单时间,但是在支付的时候,又会有支付时间,同理,还有发货时间,完成时间等。下面以我们的销售订单数据仓库为例,讨论累积快照事实表的实现。
假设希望跟踪以下五个销售订单的里程碑:下订单、分配库房、打包、配送和收货,分别用状态N、A、P、S、R表示。这五个里程碑的日期及其各自的数量来自源数据库的销售订单表。一个订单完整的生命周期由五行数据描述:下订单时生成一条销售订单记录;订单商品被分配到相应库房时,新增一条记录,存储分配时间和分配数量;产品打包时新增一条记录,存储打包时间和数量;类似的,订单配送和订单客户收货时也都分别新增一条记录,保存各自的时间戳与数量。为了简化示例,不考虑每种状态出现多条记录的情况(例如,一条订单中的产品可能是在不同时间点分多次出库),并且假设这五个里程碑是以严格的时间顺序正向进行的。
对订单的每种状态新增记录只是处理这种场景的多种设计方案之一。如果里程碑的定义良好并且不会轻易改变,也可以考虑在源订单事务表中新增每种状态对应的数据列,例如,新增8列,保存每个状态的时间戳和数量。新增列的好处是仍然能够保证订单号的唯一性,并保持相对较少的记录数。
1. 停止Canal Server、Canal Adapter
# 停止Canal Server,构成Canal HA的126、127两台都执行
~/canal_113/deployer/bin/stop.sh
# 停止Canal Adapter,126执行
~/canal_113/adapter/bin/stop.sh2. 修改表结构
(1)修改源数据库表结构
执行下面的脚本将源数据库中销售订单事务表结构做相应改变,以处理五种不同的状态。
-- 在MySQL 126主库执行
use source;
-- 新建表
create table sales_order_new (
id int(10) unsigned not null auto_increment comment '主键',
order_number int(11) not null,
customer_number int(11) default null comment '客户编号',
product_code int(11) default null comment '产品编码',
verification_ind char(1) default null,
credit_check_flag char(1) default null,
new_customer_ind char(1) default null,
web_order_flag char(1) default null,
status_date datetime default null,
order_status varchar(1) default null,
request_delivery_date date default null,
entry_date datetime default null comment '登记时间',
order_amount decimal(10,2) default null comment '销售金额',
quantity int(11) default null,
primary key (id),
key customer_number (customer_number),
key product_code (product_code),
constraint sales_order_new_ibfk_1 foreign key (customer_number) references customer (customer_number) on delete cascade on update cascade,
constraint sales_order_new_ibfk_2 foreign key (product_code) references product (product_code) on delete cascade on update cascade
) ;
-- 装载数据
insert into sales_order_new
(order_number,customer_number,product_code,verification_ind,credit_check_flag,new_customer_ind,web_order_flag,
status_date,order_status,request_delivery_date,entry_date,order_amount,quantity)
select order_number,customer_number,product_code,verification_ind,credit_check_flag,new_customer_ind,web_order_flag,
order_date,null,request_delivery_date,entry_date,order_amount,order_quantity
from sales_order;
-- 删除老表
drop table sales_order;
-- 新表改为原名
rename table sales_order_new to sales_order;说明:
- 由于sales_order表需要修改主键,如果在原表上执行alter进行修改,Canal Server启动时会报错空指针错误,因此需要新建表。
- 将order_date字段改名为status_date,因为日期不再单纯指订单日期,而是指变为某种状态日期。
- 将order_quantity字段改名为quantity,因为数量变为某种状态对应的数量。
- 在status_date字段后增加order_status字段,存储N、A、P、S、R等订单状态之一。它描述了status_date列对应的状态值,例如,如果一条记录的状态为N,则status_date列是下订单的日期。如果状态是R,status_date列是收货日期。
- 每种状态都会有一条订单记录,这些记录具有相同的订单号,因此订单号不能再作为事务表的主键,需要删除order_number字段上的自增属性与主键约束。
- 新增id字段作为销售订单表的主键,它是表中的第一个字段。
(2)修改RDS数据库模式里的表
set search_path to rds;
alter table sales_order rename order_date to status_date;
alter table sales_order rename order_quantity to quantity;
alter table sales_order add order_status varchar(1);
update sales_order set order_status='D';
–删除主键
alter table sales_order drop constraint sales_order_pkey;
–新增主键
alter table sales_order add constraint sales_order_pkey primary key(order_number, order_status, entry_date);说明:
- 将销售订单事实表中order_date和order_quantity字段的名称修改为与源表一致。
- 增加订单状态字段。
- rds.sales_order并没有增加id列,原因有两个:一是该列只作为MySQL源表中的自增主键,不用在目标同步表中存储;二是不需要再重新导入已有数据。
- order_number的值不再唯一,需要重建rds.sales_order表的主键,将新增的order_status列加入主键中。由于主键值不能为空,先将已存在数据的order_status列更新为一个缺省值'D'。
- 不用修改分布键,因为order_number依然是主键的子集。
(3)修改TDS数据库模式里的表
执行下面的脚本将数据仓库中的事务事实表改造成累积快照事实表。
set search_path to tds;
alter table sales_order_fact
add allocate_date_sk int,
add allocate_quantity int,
add packing_date_sk int,
add packing_quantity int,
add ship_date_sk int,
add ship_quantity int,
add receive_date_sk int,
add receive_quantity int;
-- 建立四个日期维度视图
create view allocate_date_dim
(allocate_date_sk, allocate_date, month, month_name, quarter, year)
as
select date_sk, date, month, month_name, quarter, year
from date_dim ;
create view packing_date_dim
(packing_date_sk, packing_date, month, month_name, quarter, year)
as
select date_sk, date, month, month_name, quarter, year
from date_dim ;
create view ship_date_dim
(ship_date_sk, ship_date, month, month_name, quarter, year)
as
select date_sk, date, month, month_name, quarter, year
from date_dim ;
create view receive_date_dim
(receive_date_sk, receive_date, month, month_name, quarter, year)
as
select date_sk, date, month, month_name, quarter, year
from date_dim ;说明:
- 在销售订单事实表中新增加八个字段存储四个状态的日期代理键和度量值。
- 新增八个字段的初始值为空。
- 建立四个日期角色扮演维度视图,用来获取相应状态的日期代理键。
3. 修改Canal Adapter表映射
在sales_order.yml文件中修改主键和字段映射。
[mysql@node2~/canal_113/adapter/conf/rdb]$cat sales_order.yml
dataSourceKey: defaultDS
destination: example
groupId: g1
outerAdapterKey: Greenplum
concurrent: true
dbMapping:
database: source
table: sales_order
targetTable: rds.sales_order
targetPk:
order_number: order_number
order_status: order_status
# mapAll: true
targetColumns:
order_number: order_number
customer_number: customer_number
product_code: product_code
status_date: status_date
entry_date: entry_date
order_amount: order_amount
quantity: quantity
request_delivery_date: request_delivery_date
verification_ind: verification_ind
credit_check_flag: credit_check_flag
new_customer_ind: new_customer_ind
web_order_flag: web_order_flag
order_status: order_status
commitBatch: 30000 # 批量提交的大小4. 重建sales_order_fact事实表rule
drop rule r_insert_sales_order on rds.sales_order;
create rule r_insert_sales_order as on insert to rds.sales_order do also
(
-- 下单
insert into sales_order_fact(order_number,customer_sk,product_sk,order_date_sk,request_delivery_date_sk,year_month,order_amount,order_quantity, sales_order_attribute_sk,customer_zip_code_sk,shipping_zip_code_sk)
select new.order_number, customer_sk, product_sk, d.date_sk, e.date_sk, to_char(new.status_date, 'YYYYMM')::int, new.order_amount, new.quantity, f.sales_order_attribute_sk, g.customer_zip_code_sk, h.shipping_zip_code_sk
from customer_dim b, product_dim c, date_dim d, date_dim e, sales_order_attribute_dim f, customer_zip_code_dim g, shipping_zip_code_dim h, rds.customer i
where new.customer_number = b.customer_number and b.expiry_dt = '2200-01-01'
and new.product_code = c.product_code and c.expiry_dt = '2200-01-01'
and date(new.status_date) = d.date
and date(new.request_delivery_date) = e.date
and new.verification_ind = f.verification_ind
and new.credit_check_flag = f.credit_check_flag
and new.new_customer_ind = f.new_customer_ind
and new.web_order_flag = f.web_order_flag
and new.customer_number = i.customer_number
and i.customer_zip_code = g.customer_zip_code and g.expiry_date = '2200-01-01'
and i.shipping_zip_code = h.shipping_zip_code and h.expiry_date = '2200-01-01'
and new.order_status='N';
-- 分配库房、打包、配送、收货
update sales_order_fact t1
set allocate_date_sk = (case when new.order_status = 'A' then t2.allocate_date_sk else t1.allocate_date_sk end),
allocate_quantity = (case when new.order_status = 'A' then new.quantity else t1.allocate_quantity end),
packing_date_sk = (case when new.order_status = 'P' then t3.packing_date_sk else t1.packing_date_sk end),
packing_quantity = (case when new.order_status = 'P' then new.quantity else t1.packing_quantity end),
ship_date_sk = (case when new.order_status = 'S' then t4.ship_date_sk else t1.ship_date_sk end),
ship_quantity = (case when new.order_status = 'S' then new.quantity else t1.ship_quantity end),
receive_date_sk = (case when new.order_status = 'R' then t5.receive_date_sk else t1.receive_date_sk end),
receive_quantity = (case when new.order_status = 'R' then new.quantity else t1.receive_quantity end)
from allocate_date_dim t2, packing_date_dim t3, ship_date_dim t4, receive_date_dim t5
where t1.order_number = new.order_number
and new.order_status in ('A', 'P', 'S', 'R')
and date(new.status_date) = t2.allocate_date
and date(new.status_date) = t3.packing_date
and date(new.status_date) = t4.ship_date
and date(new.status_date) = t5.receive_date;
);需要修改r_insert_sales_order规则,针对五个里程碑分别处理。首先装载新增的订单,对于累积快照,需要增加订单状态order_status = 'N'的判断,还要修改字段名。
其他四个状态的处理和新增订单有所不同。因为此时订单记录已经存在,除了与特定状态相关的日期维度代理键和状态数量,其他的信息不需要更新。例如,当一个订单的状态由新增变为分配库房时,只要使用订单号字段关联累积快照事实表和过渡区的事务表,以事务表的order_status = 'A'为筛选条件,更新累积快照事实表的状态日期代理键和状态数量两个字段即可。对其它三个状态的处理是类似的,只要将过滤条件换成对应的状态值,并关联相应的日期维度视图获取日期代理键。
注意,本示例中的累积周期快照表仍然是以订单号字段作为主键。数据装载过程实际上是做了一个行转列的操作,用源数据表中的状态行信息更新累积快照的状态列。
5. 启动Canal Server、Canal Adapter
# 启动Canal Server,在构成Canal HA的126、127两台顺序执行
~/canal_113/deployer/bin/startup.sh
# 在126执行
~/canal_113/adapter/bin/startup.sh6. 测试
(1)在源数据库的销售订单事务表中新增两个销售订单记录。
use source;
set @order_date := from_unixtime(unix_timestamp('2022-01-04 00:00:01') + rand() * (unix_timestamp('2022-01-04 12:00:00') - unix_timestamp('2022-01-04 00:00:01')));
set @request_delivery_date := date(date_add(@order_date, interval 5 day));
set @amount := floor(1000 + rand() * 9000);
set @quantity := floor(10 + rand() * 90);
insert into source.sales_order values (null, 141, 1, 1, 'y', 'y', 'y', 'y', @order_date, 'N', @request_delivery_date, @order_date, @amount, @quantity);
set @order_date := from_unixtime(unix_timestamp('2022-01-04 12:00:00') + rand() * (unix_timestamp('2022-01-05 00:00:00') - unix_timestamp('2022-01-04 12:00:00')));
set @request_delivery_date := date(date_add(@order_date, interval 5 day));
set @amount := floor(1000 + rand() * 9000);
set @quantity := floor(10 + rand() * 90);
insert into source.sales_order values (null, 142, 2, 2, 'y', 'y', 'y', 'y', @order_date, 'N', @request_delivery_date, @order_date, @amount, @quantity);
commit;(2)查询sales_order_fact里的两个销售订单,确认定期装载成功。
select a.order_number, c.order_date, d.allocate_date, e.packing_date, f.ship_date, g.receive_date
from sales_order_fact a
left join order_date_dim c on a.order_date_sk = c.order_date_sk
left join allocate_date_dim d on a.allocate_date_sk = d.allocate_date_sk
left join packing_date_dim e on a.packing_date_sk = e.packing_date_sk
left join ship_date_dim f on a.ship_date_sk = f.ship_date_sk
left join receive_date_dim g on a.receive_date_sk = g.receive_date_sk
where a.order_number > 140
order by order_number;查询结果如下,只有order_date列有值,其他日期都是空,因为这两个订单是新增的,并且还没有分配库房、打包、配送或收货。
order_number | order_date | allocate_date | packing_date | ship_date | receive_date
--------------+------------+---------------+--------------+-----------+--------------
141 | 2022-01-04 | | | |
142 | 2022-01-04 | | | |
(2 rows)(3)添加销售订单作为这两个订单的分配库房和/或打包的里程碑。
use source;
set @order_date := from_unixtime(unix_timestamp('2022-01-05 00:00:00') + rand() * (unix_timestamp('2022-01-05 12:00:00') - unix_timestamp('2022-01-05 00:00:00')));
insert into sales_order
select null, order_number, customer_number, product_code, verification_ind,
credit_check_flag, new_customer_ind, web_order_flag, @order_date, 'A',
request_delivery_date, @order_date, order_amount, quantity
from sales_order
where order_number = 141;
set @order_date := from_unixtime(unix_timestamp('2022-01-05 12:00:00') + rand() * (unix_timestamp('2022-01-06 00:00:00') - unix_timestamp('2022-01-05 12:00:00')));
insert into sales_order
select null, order_number, customer_number, product_code, verification_ind,
credit_check_flag, new_customer_ind, web_order_flag, @order_date, 'P',
request_delivery_date, @order_date, order_amount, quantity
from sales_order
where id = 143;
set @order_date := from_unixtime(unix_timestamp('2022-01-05 12:00:00') + rand() * (unix_timestamp('2022-01-06 00:00:00') - unix_timestamp('2022-01-05 12:00:00')));
insert into sales_order
select null, order_number, customer_number, product_code, verification_ind,
credit_check_flag, new_customer_ind, web_order_flag, @order_date, 'A',
request_delivery_date, @order_date, order_amount, quantity
from sales_order
where order_number = 142;
commit;(4)查询sales_order_fact表里的两个销售订单,确认定期装载成功。查询结果如下。
order_number | order_date | allocate_date | packing_date | ship_date | receive_date
--------------+------------+---------------+--------------+-----------+--------------
141 | 2022-01-04 | 2022-01-05 | 2022-01-05 | |
142 | 2022-01-04 | 2022-01-05 | | |
(2 rows)第一个订单具有了allocate_date和packing_date,第二个只具有allocate_date。
(5)添加销售订单作为这两个订单后面的里程碑:打包、配送和/或收货。注意四个日期可能相同。
use source;
set @order_date := from_unixtime(unix_timestamp('2022-01-06 00:00:00') + rand() * (unix_timestamp('2022-01-06 12:00:00') - unix_timestamp('2022-01-06 00:00:00')));
insert into sales_order
select null, order_number, customer_number, product_code, verification_ind,
credit_check_flag, new_customer_ind, web_order_flag, @order_date, 'S',
request_delivery_date, @order_date, order_amount, quantity
from sales_order
where order_number = 141
order by id desc
limit 1;
set @order_date := from_unixtime(unix_timestamp('2022-01-06 12:00:00') + rand() * (unix_timestamp('2022-01-07 00:00:00') - unix_timestamp('2022-01-06 12:00:00')));
insert into sales_order
select null, order_number, customer_number, product_code, verification_ind,
credit_check_flag, new_customer_ind, web_order_flag, @order_date, 'R',
request_delivery_date, @order_date, order_amount, quantity
from sales_order
where order_number = 141
order by id desc
limit 1;
set @order_date := from_unixtime(unix_timestamp('2022-01-06 12:00:00') + rand() * (unix_timestamp('2022-01-07 00:00:00') - unix_timestamp('2022-01-06 12:00:00')));
insert into sales_order
select null, order_number, customer_number, product_code, verification_ind,
credit_check_flag, new_customer_ind, web_order_flag, @order_date, 'P',
request_delivery_date, @order_date, order_amount, quantity
from sales_order
where order_number = 142
order by id desc
limit 1;
commit;(6)查询sales_order_fact表里的两个销售订单,确认定期装载成功。查询结果如下。
order_number | order_date | allocate_date | packing_date | ship_date | receive_date
--------------+------------+---------------+--------------+------------+--------------
141 | 2022-01-04 | 2022-01-05 | 2022-01-05 | 2022-01-06 | 2022-01-06
142 | 2022-01-04 | 2022-01-05 | 2022-01-06 | |
(2 rows)第一个订单号为141的订单,具有了全部日期,这意味着订单已完成(客户已经收货)。第二个订单已经打包,但是还没有配送。
8.4 无事实的事实表
在多维数据仓库建模中,有一种事实表叫做“无事实的事实表”。普通事实表中,通常会保存若干维度外键和多个数字型度量,度量是事实表的关键所在。然而在无事实的事实表中没有这些度量值,只有多个维度外键。表面上看,无事实事实表是没有意义的,因为作为事实表,毕竟最重要的就是度量。但在数据仓库中,这类事实表有其特殊用途。无事实的事实表通常用来跟踪某种事件或者说明某些活动的范围。
无事实的事实表可以用来跟踪事件的发生。例如,在给定的某一天中发生的学生参加课程的事件,可能没有可记录的数字化事实,但该事实行带有一个包含日期、学生、教师、地点、课程等定义良好的外键。利用无事实的事实表可以按各种维度计数上课这个事件。
无事实的事实表还可以用来说明某些活动的范围,常被用于回答“什么未发生”这样的问题。例如:促销范围事实表。通常销售事实表可以回答如促销商品的销售情况,可是无法回答的一个重要问题是:处于促销状态但尚未销售的产品包括哪些?销售事实表所记录的仅仅是实际卖出的产品。事实表行中不包括由于没有销售行为而销售数量为零的行,因为如果将包含零值的产品都加到事实表中,那么事实表将变得非常巨大。这时,通过建立促销范围事实表,将商场需要促销的商品单独建立事实表保存,然后通过这个促销范围事实表和销售事实表即可得出哪些促销商品没有销售出去。
为确定当前促销的产品中哪些尚未卖出,需要两步过程:首先,查询促销无事实的事实表,确定给定时间内促销的产品。然后从销售事实表中确定哪些产品已经卖出去了。答案就是上述两个列表的差集。这样的促销范围事实表只是用来说明促销活动的范围,其中没有任何事实度量。可能有读者会想,建立一个单独的促销商品维度表能否可以达到同样的效果呢?促销无事实的事实表包含多个维度的主键,可以是日期、产品、商店、促销等,将这些键作为促销商品的属性是不合适的,因为每个维度都有自己的属性集合。
促销无事实事实表看起来与销售事实表相似。然而,它们的粒度存在显著差别。假设促销是以一周为持续期,在促销范围事实表中,将为每周每个商店中促销的产品加载一行,无论产品是否卖出。该事实表能够确保看到被促销定义的键之间的关系,而与其他事件,如产品销售无关。
下面以销售订单数据仓库为例,说明如何处理源数据中没有度量的需求。我们将建立一个无事实的事实表,用来统计每天发布的新产品数量。产品源数据不包含产品数量信息,如果系统需要得到历史某一天新增产品的数量,很显然不能简单地从数据仓库中得到。这时就要用到无事实的事实表技术。使用此技术可以通过持续跟踪产品发布事件来计算产品的数量。可以创建一个只有产品(计什么数)和日期(什么时候计数)维度代理键的事实表。之所以叫做无事实的事实表是因为表本身并没有数字型度量值。这里定义的新增产品是指在某一给定日期,源产品表中新插入的产品记录,不包括由于SCD2新增的产品版本记录。注意,单从这个简单需求来看,也可以通过查询产品维度表获取结果。这里只为演示无事实事实表的实现过程。
1. 建立新产品发布的无事实事实表
在TDS模式中新建一个产品发布的无事实事实表product_count_fact,该表中只包含两个字段,分别是引用日期维度表和产品维度表的外键,同时这两个字段也构成了无事实事实表的逻辑主键。图8-2显示了跟踪产品发布数量的表。

图8-2 无事实的事实表
执行下面的语句,在数据仓库模式中创建产品发布日期视图及其无事实事实表。由于是新建表,不需要事先停止Canal服务。
set search_path=tds;
create view product_launch_date_dim
(product_launch_date_sk,product_launch_date, month_name, month, quarter, year)
as
select distinct date_sk, date, month_name, month, quarter, year
from product_dim a, date_dim b
where date(a.effective_dt) = b.date
and a.version = 1;
create table product_count_fact (
product_sk int,
product_launch_date_sk int,
primary key (product_sk, product_launch_date_sk))
distributed by (product_sk);说明:
- 与之前创建的很多日期角色扮演维度不同,产品发布日期视图只获取产品生效日期,而不是日期维度里的所有记录,因此在定义视图的查询语句中关联了产品维度和日期维度两个表。product_launch_date_dim维度是日期维度表的子集。
- 从字段定义上看,产品维度表中的生效日期明显就是新产品的发布日期。
- version = 1 过滤掉由于SCD2新增的产品版本记录。
2. 初始装载无事实事实表
下面的语句从产品维度表向无事实事实表装载已有的产品发布信息。insert语句添加所有产品的第一个版本,即产品的首次发布日期。
insert into product_count_fact
select a.product_sk product_sk, b.date_sk date_sk
from product_dim a,date_dim b
where date(a.effective_dt) = b.date and a.version = 1;查询product_count_fact表以确认正确执行了初始装载。
dw=> select product_sk,product_launch_date_sk
dw-> from tds.product_count_fact
dw-> order by product_sk;
product_sk | product_launch_date_sk
------------+------------------------
1 | 518
2 | 518
3 | 518
5 | 728
(4 rows)3. 重建r_insert_product规则
drop rule r_insert_product on product;
create rule r_insert_product as on insert to product do also
(
insert into product_dim (product_code,product_name,product_category,version,effective_dt,expiry_dt)
values (new.product_code,new.product_name,new.product_category,1,now(),'2200-01-01');
insert into product_count_fact
select a.product_sk product_sk, b.date_sk date_sk
from product_dim a,date_dim b
where date(a.effective_dt) = b.date and a.version = 1
and a.product_code = new.product_code;
); 该规则在处理产品维度表后增加了装载product_count_fact表的语句。4. 测试
修改源数据库的product表数据,把产品编码为1的产品名称改为‘Regular Hard Disk Drive’,并新增一个产品‘High End Hard Disk Drive’(产品编码为5)。执行下面的语句完成此修改。
-- 在MySQL 126主库执行
use source;
update product set product_name = 'Regular Hard Disk Drive' where product_code=1;
insert into product values (5, 'High End Hard Disk Drive', 'Storage');
commit;通过查询product_count_fact表确认定期装载执行正确。
select c.product_sk psk,
c.product_code pc,
b.product_launch_date_sk plsk,
b.product_launch_date pld
from product_count_fact a,
product_launch_date_dim b,
product_dim c
where a.product_launch_date_sk = b.product_launch_date_sk
and a.product_sk = c.product_sk
order by pc, pld;查询结果如下。可以看到只是增加了一条新产品记录,原有数据没有变化。
psk | pc | plsk | pld
-----+----+------+------------
1 | 1 | 518 | 2021-06-01
2 | 2 | 518 | 2021-06-01
3 | 3 | 518 | 2021-06-01
5 | 4 | 728 | 2021-12-28
6 | 5 | 736 | 2022-01-05
(5 rows)无事实事实表是没有任何度量的事实表,它本质上是一组维度的交集。用这种事实表记录相关维度之间存在多对多关系,但是关系上没有数字或者文本的事实。无事实事实表为数据仓库设计提供了更多的灵活性。
8.5 迟到的事实
数据仓库通常建立在一种理想的假设情况下,这就是数据仓库的度量(事实记录)与度量的环境(维度记录)同时出现在数据仓库中。当同时拥有事实记录和正确的当前维度行时,就能够从容地首先维护维度键,然后在对应的事实表行中使用这些最新的键。然而,各种各样的原因会导致需要ETL系统处理迟到的事实数据。例如,某些线下的业务,数据进入操作型系统的时间会滞后于事务发生的时间。再或者出现某些极端情况,如源数据库系统出现故障,直到恢复后才能补上故障期间产生的数据。
在销售订单示例中,晚于订单日期进入源数据的销售订单可以看做是一个迟到事实的例子。销售订单数据被装载进其对应的事实表时,装载日期晚于销售订单产生的日期,因此是一个迟到的事实。
必须对标准的ETL过程进行特殊修改以处理迟到的事实。首先,当迟到度量事件出现时,不得不反向搜索维度表历史记录,以确定事务发生时间点的有效的维度代理键,因为当前的维度内容无法匹配输入行的情况。此外,还需要调整后续事实行中的所有半可加度量,例如,由于迟到的事实导致客户当前余额的改变。迟到事实可能还会引起周期快照事实表的数据更新。例如8.2节讨论的月销售周期快照表,如果2021年12月的销售订单金额已经计算并存储在month_end_sales_order_fact快照表中,这时一个迟到的12月订单在2022年1月某天被装载,那么2021年12月的快照金额必须因迟到事实而重新计算。
下面就以销售订单数据仓库为例,说明如何处理迟到的事实。
1. 停止Canal Server、Canal Adapter
# 停止Canal Server,构成Canal HA的126、127两台都执行
~/canal_113/deployer/bin/stop.sh
# 停止Canal Adapter,126执行
~/canal_113/adapter/bin/stop.sh 2. 修改数据仓库表结构
在8.2节中建立的月销售周期快照表,其数据来自已经处理过的销售订单事务事实表。因此为了确定事实表中的一条销售订单记录是否是迟到的,需要把源数据中的登记日期列装载进销售订单事实表。为此在要销售订单事实表上添加登记日期代理键列。为了获取登记日期代理键的值,还要使用维度角色扮演技术添加登记日期维度表。执行下面的语句在销售订单事实表里添加名为entry_date_sk的日期代理键列,并且从日期维度表创建一个叫做entry_date_dim的数据库视图。
set search_path=tds;
-- 给销售订单事实表增加登记日期代理键
alter table sales_order_fact add column entry_date_sk int;
-- 建立登记日期维度视图
create view entry_date_dim
(entry_date_sk, entry_date, month_name, month, quarter, year)
as
select date_sk, date, month_name, month, quarter, year
from date_dim;3. 重建sales_order_fact事实表rule
drop rule r_insert_sales_order on rds.sales_order;
create rule r_insert_sales_order as on insert to rds.sales_order do also
(
-- 下单
insert into sales_order_fact(order_number,customer_sk,product_sk,order_date_sk,request_delivery_date_sk,year_month,order_amount,order_quantity, sales_order_attribute_sk,customer_zip_code_sk,shipping_zip_code_sk,entry_date_sk)
select new.order_number, customer_sk, product_sk, d.date_sk, e.date_sk, to_char(new.status_date, 'YYYYMM')::int, new.order_amount, new.quantity, f.sales_order_attribute_sk, g.customer_zip_code_sk, h.shipping_zip_code_sk, j.entry_date_sk
from customer_dim b, product_dim c, date_dim d, date_dim e, sales_order_attribute_dim f, customer_zip_code_dim g, shipping_zip_code_dim h, rds.customer i, entry_date_dim j
where new.customer_number = b.customer_number and new.status_date >= b.effective_dt and new.status_date < b.expiry_dt
and new.product_code = c.product_code and new.status_date >= c.effective_dt and new.status_date < c.expiry_dt
and date(new.status_date) = d.date
and date(new.request_delivery_date) = e.date
and new.verification_ind = f.verification_ind
and new.credit_check_flag = f.credit_check_flag
and new.new_customer_ind = f.new_customer_ind
and new.web_order_flag = f.web_order_flag
and new.customer_number = i.customer_number
and i.customer_zip_code = g.customer_zip_code and new.status_date >= g.effective_date and new.status_date < g.expiry_date
and i.shipping_zip_code = h.shipping_zip_code and new.status_date >= h.effective_date and new.status_date < h.expiry_date
and new.order_status='N'
and date(new.entry_date) = j.entry_date;
-- 分配库房、打包、配送、收货
update sales_order_fact t1
set allocate_date_sk = (case when new.order_status = 'A' then t2.allocate_date_sk else t1.allocate_date_sk end),
allocate_quantity = (case when new.order_status = 'A' then new.quantity else t1.allocate_quantity end),
packing_date_sk = (case when new.order_status = 'P' then t3.packing_date_sk else t1.packing_date_sk end),
packing_quantity = (case when new.order_status = 'P' then new.quantity else t1.packing_quantity end),
ship_date_sk = (case when new.order_status = 'S' then t4.ship_date_sk else t1.ship_date_sk end),
ship_quantity = (case when new.order_status = 'S' then new.quantity else t1.ship_quantity end),
receive_date_sk = (case when new.order_status = 'R' then t5.receive_date_sk else t1.receive_date_sk end),
receive_quantity = (case when new.order_status = 'R' then new.quantity else t1.receive_quantity end)
from allocate_date_dim t2, packing_date_dim t3, ship_date_dim t4, receive_date_dim t5
where t1.order_number = new.order_number
and new.order_status in ('A', 'P', 'S', 'R')
and date(new.status_date) = t2.allocate_date
and date(new.status_date) = t3.packing_date
and date(new.status_date) = t4.ship_date
and date(new.status_date) = t5.receive_date;
);本节开头曾经提到,需要为迟到的事实行获取事务发生时间点的有效的维度代理键。在装载脚本中使用销售订单过渡表的状态日期字段限定当时的维度代理键。例如,为了获取事务发生时的客户代理键,筛选条件为:
status_date >= customer_dim.effective_date and status_date < customer_dim.expiry_date之所以可以这样做,原因在于本示例满足以下两个前提条件:在最初源数据库的销售订单表中,status_date存储的是状态发生时的时间;维度的生效时间与过期时间构成一条连续且不重叠的时间轴,任意status_date日期只能落到唯一的生效时间、过期时间区间内。
3. 修改周期快照事实表的数据装载
迟到的事实记录会对周期快照中已经生成的月销售汇总数据产生影响,因此必须做适当的修改。可以使用两种方案实现周期快照事实表的数据装载,一是关联更新,二是二次汇总。本例中采用关联更新方案。
(1)关联更新
因为订单可能会迟到数月才进入数据库,甚至涉及全部已经汇总的销售数据,我们不能再按部就班地只处理上月数据,而要将迟到数据累加到周期快照中对应的数据行上。此方案需要修改8.2节创建的fn_month_sum函数,并且不具有幂等性。 月销售周期快照表存储的是某月某产品汇总的销售数量和销售金额,表中有月份代理键、产品代理键、年月、销售金额、销售数量五个字段。由于迟到事实的出现,需要将事务事实表中的数据划分为三类:非迟到的事实记录;迟到的事实,但周期快照表中尚不存在相关记录;迟到的事实,并且周期快照表中已经存在相关记录。对这三类事实数据的处理逻辑各不相同,前两类数据需要汇总后插入快照表,而第三种情况需要更新快照表中的现有数据。修改后的fn_month_sum函数如下。
create or replace function tds.fn_month_sum(p_year_month int)
returns void as $$
declare
sqlstring varchar(1000);
begin
-- 非幂等操作
update month_end_sales_order_fact t1
set month_order_amount = t1.month_order_amount + t2.order_amount,
month_order_quantity = t1.month_order_quantity + t2.order_quantity
from (select d.month_sk month_sk,
a.product_sk product_sk,
coalesce(sum(order_amount),0) order_amount,
coalesce(sum(order_quantity),0) order_quantity
from sales_order_fact a,
order_date_dim b,
entry_date_dim c,
month_dim d
where a.order_date_sk = b.order_date_sk
and a.entry_date_sk = c.entry_date_sk
and c.year*100+c.month = p_year_month
and b.month = d.month
and b.year = d.year
and b.order_date <> c.entry_date
group by d.month_sk, a.product_sk) t2
where t1.order_month_sk = t2.month_sk
and t1.product_sk = t2.product_sk;
-- 幂等操作
insert into month_end_sales_order_fact
select d.month_sk, a.product_sk, d.year*100+d.month, coalesce(sum(order_amount),0), coalesce(sum(order_quantity),0)
from sales_order_fact a,
order_date_dim b,
entry_date_dim c,
month_dim d
where a.order_date_sk = b.order_date_sk
and a.entry_date_sk = c.entry_date_sk
and c.year*100+c.month = p_year_month
and b.month = d.month
and b.year = d.year
and not exists (select 1 from month_end_sales_order_fact p
where p.order_month_sk = d.month_sk
and p.product_sk = a.product_sk)
group by d.month_sk , a.product_sk, d.year*100+d.month;
end; $$
language plpgsql;按事务发生时间的先后顺序,我们先处理第三种情况。为了更新周期快照表数据,子查询用于从销售订单事实表中获取所有上个月录入的,并且是迟到的数据行的汇总。用b.order_date <> c.entry_date作为判断迟到的条件。外层查询把具有相同产品代理键和月份代理键的迟到事实的汇总数据加到已有的快照数据行上。产品代理键和月份代理键共同构成了周期快照表的逻辑主键,可以唯一标识一条记录。之后关联更新周期快照表。注意此更新是一个非幂等操作,每次执行都会累加销售数量和销售金额。
第二条语句将第一、二类数据统一处理。使用相关子查询获取所有上个月新录入的,并且在周期快照事实表中尚未存在的产品销售月汇总数据,插入到周期快照表中。销售订单事实表的粒度是实时,而周期快照事实表的粒度是每月,因此必须使用订单日期代理键对应的月份代理键进行比较。此插入是一个幂等操作,因为再次执行时就不会满足not exists条件。 在本示例中,迟到事实对月周期快照表数据的影响逻辑并不是很复杂。当逻辑主键,即月份代理键和产品代理键的组合匹配时,将从销售订单事实表中获取的销售数量和销售金额汇总值累加到月周期快照表对应的数据行上,否则将新的汇总数据添加到月周期快照表中。这个逻辑非常适合使用merge into语句,例如在Oracle中可以写成如下的样子:
declare
pre_month_date date;
month1 int;
year1 int;
begin
select add_months(sysdate,-1) into pre_month_date from dual;
select extract(month from pre_month_date), extract(year from pre_month_date) into month1, year1
from dual;
merge into month_end_sales_order_fact t1
using (select d.month_sk month_sk, a.product_sk product_sk, d.year*100+d.month year_month,
sum(order_amount) order_amount,sum(order_quantity) order_quantity
from sales_order_fact a,
order_date_dim b,
entry_date_dim c,
month_dim d
where a.order_date_sk = b.order_date_sk
and a.entry_date_sk = c.entry_date_sk
and c.month = month1
and c.year = year1
and b.month = d.month
and b.year = d.year
group by d.month_sk , a.product_sk, d.year*100+d.month) t2
on (t1.order_month_sk = t2.month_sk and t1.product_sk = t2.product_sk)
when matched then
update set t1.month_order_amount = t1.month_ord以上是关于Greenplum 实时数据仓库实践——事实表技术的主要内容,如果未能解决你的问题,请参考以下文章