数据开发 的 代码规范 以及 代码评审脚本(不定更)
Posted 小基基o_O
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据开发 的 代码规范 以及 代码评审脚本(不定更)相关的知识,希望对你有一定的参考价值。
1、前言
- 在数据开发中,由于各程序员的风格不一、注释过少等原因,导致后期代码修改时困难重重
- 代码评审:通过 阅读代码 来 检查代码质量
代码评审有助于降低后期代码维护成本 - 使用代码评审自动化脚本(Python3实现),可提高代码评审的效率
2、代码规范
2.1、通用规范
- 注释
中文注释≥1行 或 不低于占比下限(例如:100行代码里,至少5行中文注释)
注释不用太多,建议代码即注释(建议用英文全称,并查词典)
涉及业务的代码建议加详细注释 - 代码中不得出现生产环境的明文密码
- 通常,单行代码不可太长(例外:长URL、长
import) - 代码要有说明文档,名为
README.md - 命名规范
建议用英文全称,并查词典
变量、参数 命名建议:[形容词+]名词
方法、函数 命名建议:动词[+名词]
当 名称过长 或 关键字冲突 时,可使用缩写
| 常见缩写 | 全称 | 中文 | 常见缩写 | 全称 | 中文 |
|---|---|---|---|---|---|
fn | function | 函数 | ymd | Year Month Day | 日期 |
txt | textfile | 文本文件 | cnt | count | v. 计数;n. 总数 |
obj | object | 对象 | num | number | 数字;号码 |
ls | list | n. 列表;v. 列清单 | lvl | level | 等级 |
lib | library | 软件库 | dw | data warehouse | 数据仓库 |
str | string | 字符串 | bak | backup | 备份 |
prob | probability | 概率 | sku | Stock Keeping Unit | 库存单位 |
conf | configuration file | 配置文件 | idx | index file | 索引文件 |
calc | calculation | n. 计算 | uv | unique visitor | 独立访客 |
regexp | regular expression | 正则表达式 | pv | page view | 页面浏览量 |
2.2、配置文件和传参规范
https://yellow520.blog.csdn.net/article/details/122088401
2.3、Python代码规范
| 命名规范 | 说明 | 示例 |
|---|---|---|
| 变量、方法、函数、包 | 全小写,下划线分隔单词 | function_name |
| 类中的方法和函数(不被外部直接调用的) | 双下划线开头,全小写,下划线分隔单词 | __method_name |
| 常量 | 全大写 和 下划线 | PUBLIC_CONSTANT |
| 模块 | 全小写,下划线分隔单词 | module_name.py |
| 类 | 每个单词首字母大写 | ClassName |
| 注释规范 | 注释建议 |
|---|---|
| 模块注释、函数注释、类注释、方法注释… | 三双引号,注释的前面没有空行 |
| 单行代码注释、多行代码注释 | 井号 |
| 多行注释(单行注释太长时,建议写成多行) | 井号(连续行) |
"""
模块注释
"""
from time import time
# 多行代码的注释
# 多行注释(一行写不下的时候建议写多行)
NUM = 5
CNT = 1000
def function1():
"""函数注释"""
t = time() # 单行代码注释
return t
class ClassName:
"""类注释"""
@classmethod
def method4(cls):
"""方法注释"""
if __name__ == '__main__':
print(__doc__)
print(function1.__doc__)
print(ClassName.__doc__)
print(ClassName.method4.__doc__)
| 其它规范 | 说明 |
|---|---|
| 缩进(4个空格)、空行、空格 | 建议把Pycharm更到最新,用Ctrl+Alt+l来规范代码 |
| 字符串 | 优先用单引号,多行则用三单引号 单行子字符串里有单引号时用双引号,如: sql = "SELECT '2021-12-02'"不使用三双引号 |
2.4、SQL代码规范
- 关键字:全大写
- 库名、表名、字段名:全小写,下划线分隔单词
库名:业务名称
表名:[临时表标识_]分层名_子业务名称 - 建表时,表和字段要有注释,建议用中文
- 慎用
SELECT * - 注释用
--(双减号+空格,mysql和HIVE都支持)
子查询用WITH AS,每个子查询都要有中文注释
WITH
-- 注释1
t1 AS (SELECT a FROM t0),
-- 注释2
t2 AS (SELECT a FROM t1),
-- 注释3
t3 AS (SELECT a FROM t2)
-- 注释4
SELECT a FROM t2;
- 代码头部
-- 名称:A9527
-- 所属业务:A
-- 需求文档:链接
-- 创建者:小基基
-- 创建日期: 2021-10-24
-- 修改日志(修改日期,修改人,修改内容):
-- 2021-12-12,小黄,添加xxx指标
2.5、其它
2.5.1、Java和Scala
| 注释 | 注释方式 |
|---|---|
| 文档注释 | /** */ |
| 多行注释 | /* */ |
| 单行注释 | // |
| 命名规范 | 说明 | 示例 |
|---|---|---|
| 变量、方法 | 第一个单词全小写,后续单词首字母大写 | methodName |
| 类 | 每个单词首字母大写 | ClassName |
| 包、项目名 | 全小写 | |
| 常量 | 全大写 和 下划线 | PUBLIC_CONSTANT |
2.5.2、JSON
| 命名规范 | 说明 | 示例 |
|---|---|---|
| 键 | 第一个单词全小写,后续单词首字母大写 | functionName |
3、代码评审 自动化脚本
功能:整体代码扫描、单个代码文件扫描
使用方法:
将(不含外部包)的代码 和 该代码扫描脚本 放到同级目录,使用Python3运行
代码扫描报告示例:
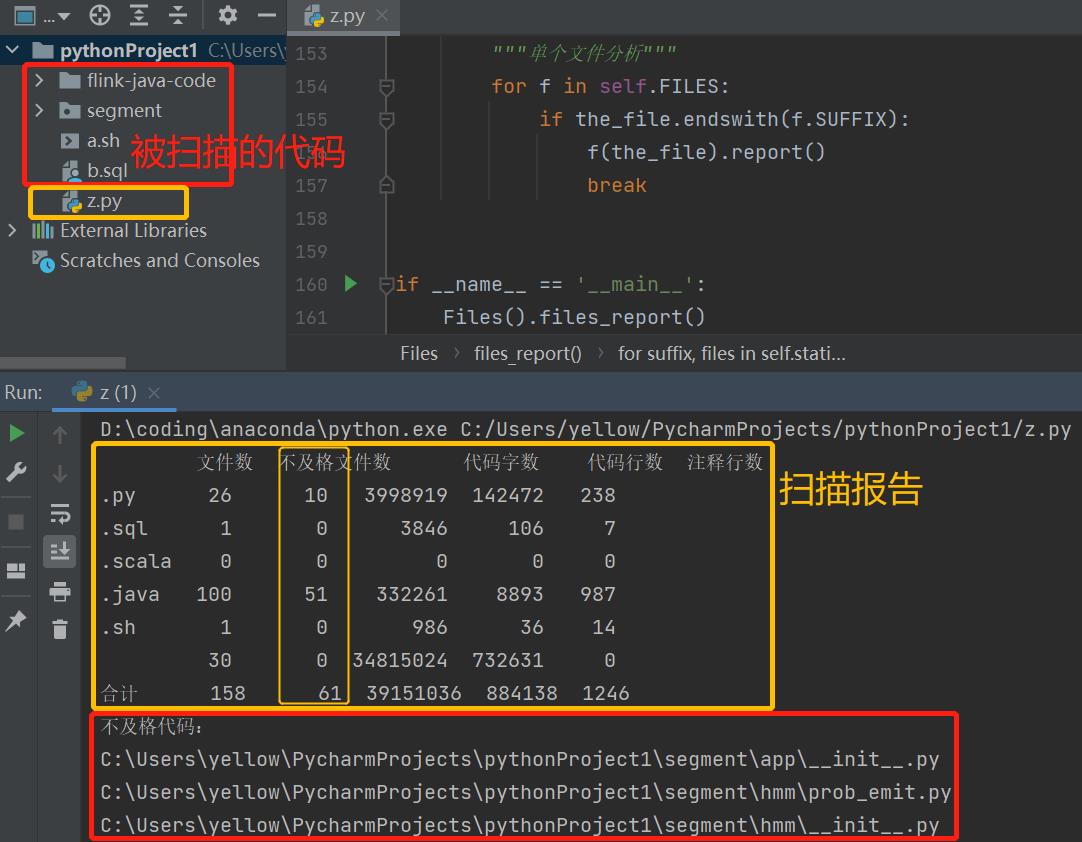
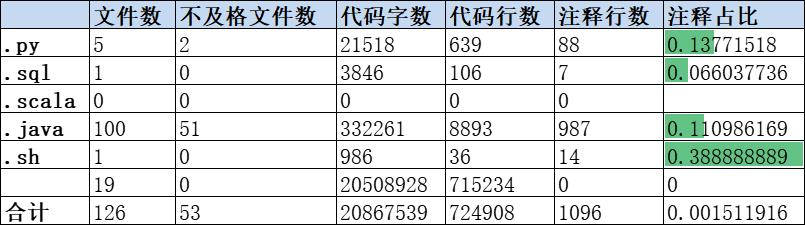
import os
import re
from collections import defaultdict
from pandas import DataFrame
class File:
class Compile:
@staticmethod
def findall(string):
return []
@staticmethod
def match(string):
return not None
# 文件名后缀
SUFFIX = ''
# 提取注释的正则表达式
COMMENT_PATTERN = Compile
# 合格代码的最低注释占比
COMMENT_PROPORTION_THRESHOLD = 0
# 代码头部模板
HEAD_PATTERN = Compile
# 不合规代码
UNQUALIFIED_CODE_PATTERN = Compile
# 单行代码最大长度
LINE_LENGTH_LIMIT = 120
def __init__(self, file_name):
self.file_name = file_name
# 读取文件
txt = self.read_file()
# 字数
self.number_of_words = len(txt)
# 行数
self.number_of_lines = len(txt.split('\\n'))
# 注释抽取
comments = self.COMMENT_PATTERN.findall(txt)
# 注释行数
self.number_of_comments = sum(len(c.strip().split('\\n')) for c in comments)
# 注释个数的占比
self.comment_proportion = self.number_of_comments / self.number_of_lines
# 代码是否合格
self.flunk = False
if self.comment_proportion < self.COMMENT_PROPORTION_THRESHOLD:
self.flunk = True # 注释太少
if self.HEAD_PATTERN.match(txt) is None:
self.flunk = True # 代码头部没有按照指定模板
if self.UNQUALIFIED_CODE_PATTERN.findall(txt):
self.flunk = True # 出现不合格的代码语句
if max(len(line) for line in txt.split('\\n')) > self.LINE_LENGTH_LIMIT:
self.flunk = True # 单行代码过长
def read_file(self):
try:
with open(self.file_name, encoding='utf-8') as f:
return f.read().strip()
except UnicodeDecodeError:
return ''
def report(self):
print('文件名称', self.file_name)
print('字数', self.number_of_words)
print('行数', self.number_of_lines)
print('注释行数', self.number_of_comments)
print('注释行数占比', self.comment_proportion)
print('不及格', self.flunk)
class PyFile(File):
SUFFIX = '.py'
COMMENT_PATTERN = re.compile(r'"""[\\s\\S]+?"""|# .+')
COMMENT_PROPORTION_THRESHOLD = 0.05
class SqlFile(File):
SUFFIX = '.sql'
COMMENT_PATTERN = re.compile('-- .+')
COMMENT_PROPORTION_THRESHOLD = 0.05
UNQUALIFIED_CODE_PATTERN = re.compile(r'select\\s+\\*', re.I)
class JavaFile(File):
SUFFIX = '.java'
COMMENT_PATTERN = re.compile(r'/\\*[\\s\\S]\\*/|//.+')
COMMENT_PROPORTION_THRESHOLD = 0.1
class ScalaFile(JavaFile):
SUFFIX = '.scala'
class ShFile(File):
SUFFIX = '.sh'
COMMENT_PATTERN = re.compile('# .+')
COMMENT_PROPORTION_THRESHOLD = 0.1
class Files:
FILES = (PyFile, SqlFile, ScalaFile, JavaFile, ShFile, File)
def __init__(self):
self.statistic = t.SUFFIX: [] for t in self.FILES
def traversal(self, path=os.path.dirname(__file__)):
"""递归遍历文件"""
for file_name in os.listdir(path):
abs_path = os.path.join(path, file_name)
if os.path.isdir(abs_path):
for p in self.traversal(abs_path):
yield p
elif os.path.isfile(abs_path):
yield abs_path
def calculate(self):
"""计算 文件数、代码量、注释量…"""
for abs_path in self.traversal():
if abs_path == __file__:
continue
for f in self.FILES:
if abs_path.endswith(f.SUFFIX):
self.statistic[f.SUFFIX].append(f(abs_path))
break
@property
def flunk(self):
"""不及格代码"""
return (f.file_name for files in self.statistic.values() for f in files if f.flunk)
def files_report(self):
"""整体分析"""
self.calculate()
df = defaultdict(list)
index = []
for suffix, files in self.statistic.items():
index.append(suffix)
df['文件数'].append(len(files))
df['不及格文件数'].append(sum(f.flunk for f in files))
df['代码字数'].append(sum(f.number_of_words for f in files))
df['代码行数'].append(sum(f.number_of_lines for f in files))
df['注释行数'].append(sum(f.number_of_comments for f in files))
df = DataFrame(df, index)
df.loc['合计'] = df.sum()
df['注释占比'] = df['注释行数'] / df['代码行数']
df['不及格率'] = df['不及格文件数'] / df['文件数']
print(df)
# df.to_excel('代码扫描报告.xlsx')
print('不及格代码:')
for f in self.flunk:
print(f)
def single_file_report(self, the_file):
"""单个文件分析"""
for f in self.FILES:
if the_file.endswith(f.SUFFIX):
f(the_file).report()
break
if __name__ == '__main__':
Files().files_report()
# Files().single_file_report(__file__) # 检查自己
以上是关于数据开发 的 代码规范 以及 代码评审脚本(不定更)的主要内容,如果未能解决你的问题,请参考以下文章