redis源码学习快速列表 quicklist
Posted 看,未来
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了redis源码学习快速列表 quicklist相关的知识,希望对你有一定的参考价值。

关于quicklist
上一篇学习了ziplist,是一种很紧凑的列表。但是在中间删除的效率真的是不敢恭维。然后我也写了点自己的想法,不过倒是没有想到deque。deque是STL中的一种数据结构,不过似乎在STL中不如其他几个数据结构大众化。在nginx的节点设计中这种deque模式可是大放异彩。
说了这么多,如果对STL了解稍多或者看过nginx源码就应该能猜到这个quicklist是什么了吧。
一整块的 ziplist 增删(非尾)效率不高,那把完整的一块拆成几块,那可不就是提高效率了嘛。
提几个比较有意思的创新点子,以前没有接触过。咱就是说,好东西咱是不会落下的嘛。
无损压缩算法
当链表很长的时候,中间节点数据访问频率比较低,这时redis会将中间节点进行压缩,进一步节省内存空间。
采用无损压缩算法:LZF算法。
/* quicklistLZF is a 4+N byte struct holding 'sz' followed by 'compressed'.
* 'sz' is byte length of 'compressed' field.
* 'compressed' is LZF data with total (compressed) length 'sz'
* NOTE: uncompressed length is stored in quicklistNode->sz.
* When quicklistNode->zl is compressed, node->zl points to a quicklistLZF */
typedef struct quicklistLZF
unsigned int sz; /* LZF size in bytes*/
char compressed[];
quicklistLZF;
sz:压缩后的ziplist大小
compressed:存放压缩后的ziplist字节数组
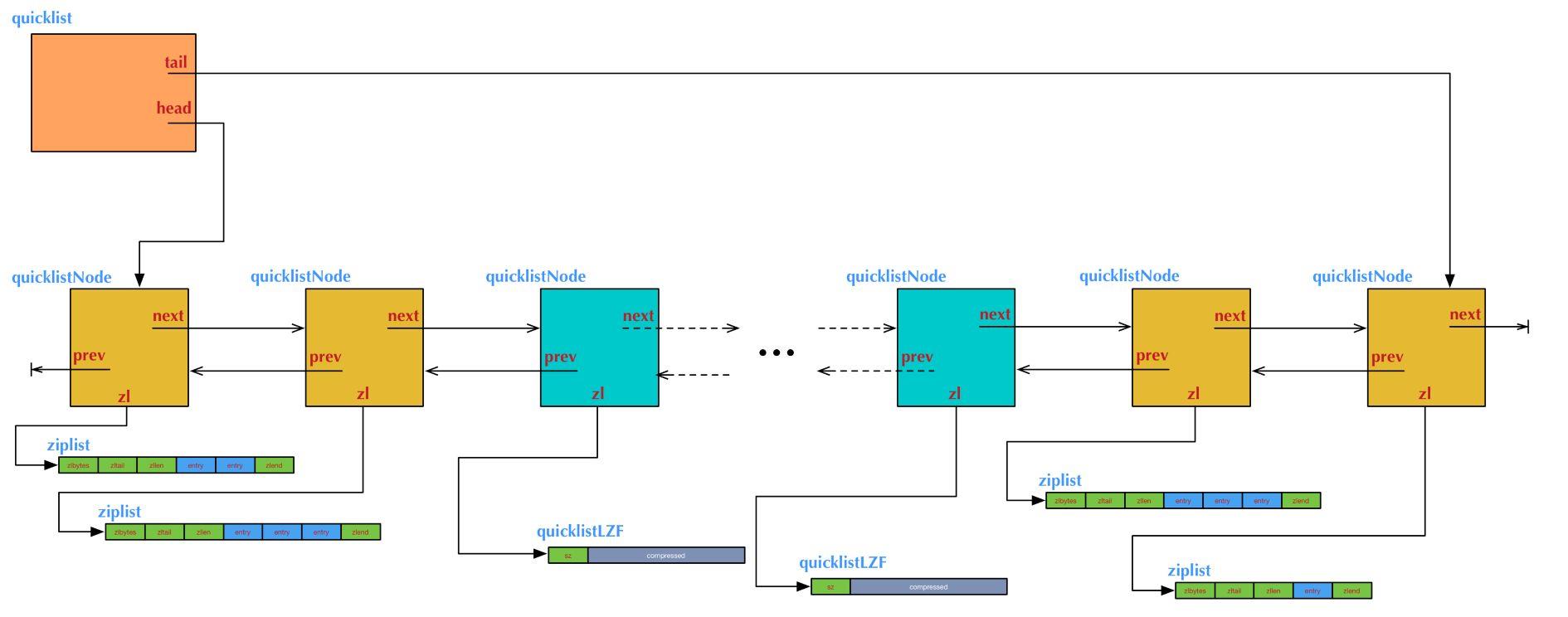
核心数据结构
/* quicklist is a 40 byte struct (on 64-bit systems) describing a quicklist.
* 'count' is the number of total entries.
* 'len' is the number of quicklist nodes.
* 'compress' is: -1 if compression disabled, otherwise it's the number
* of quicklistNodes to leave uncompressed at ends of quicklist.
* 'fill' is the user-requested (or default) fill factor.
* 'bookmakrs are an optional feature that is used by realloc this struct,
* so that they don't consume memory when not used. */
typedef struct quicklist
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all ziplists */
unsigned long len; /* number of quicklistNodes */
int fill : QL_FILL_BITS; /* fill factor for individual nodes */
unsigned int compress : QL_COMP_BITS; /* depth of end nodes not to compress;0=off */
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
quicklist;
当fill大于0时,表示每个ziplist最多能有多少个节点;当fill小于0时:
-1:ziplist节点最大4KB
-2:最大8KB
-3:16KB
-4:32
-5:64
可通过配置文件修改
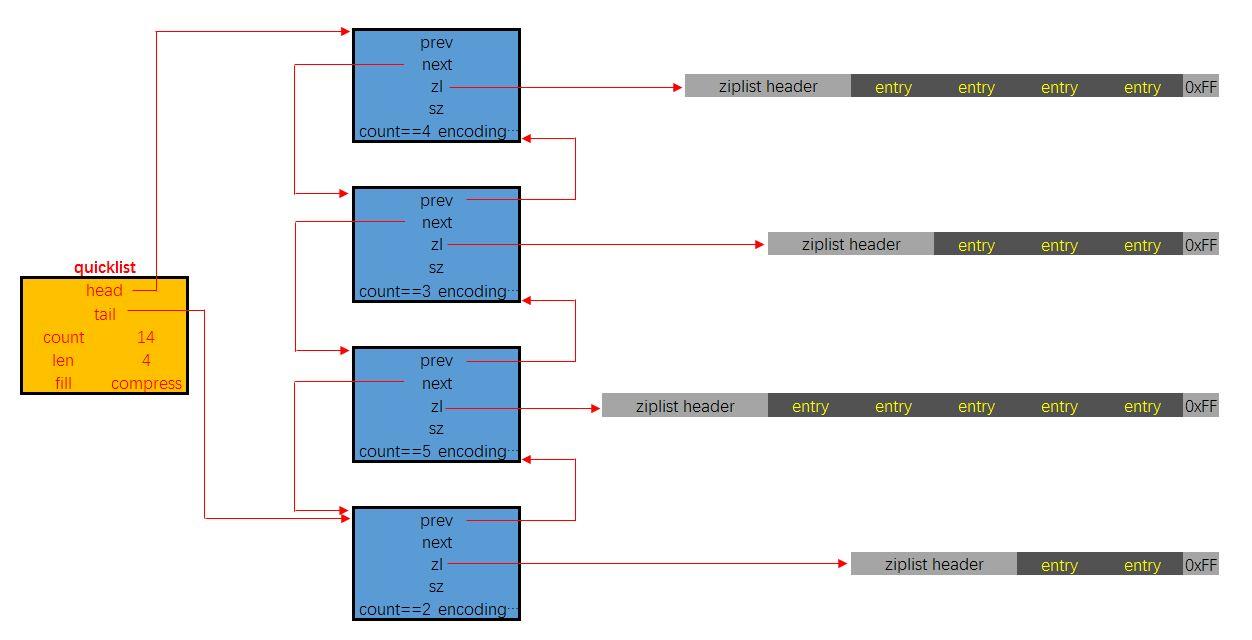
compress:两端各有这么多个数据不压缩。我去找张图来。
这就是compress=2的情况。
再看一下单个节点的情况:
/* Node, quicklist, and Iterator are the only data structures used currently. */
/* quicklistNode is a 32 byte struct describing a ziplist for a quicklist.
* We use bit fields keep the quicklistNode at 32 bytes.
* count: 16 bits, max 65536 (max zl bytes is 65k, so max count actually < 32k).
* encoding: 2 bits, RAW=1, LZF=2.
* container: 2 bits, NONE=1, ZIPLIST=2.
* recompress: 1 bit, bool, true if node is temporarry decompressed for usage.
* attempted_compress: 1 bit, boolean, used for verifying during testing.
* extra: 10 bits, free for future use; pads out the remainder of 32 bits */
typedef struct quicklistNode
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl; //指向对应的ziplist
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */ //若是,使用前需要解压缩,用完再压回去
unsigned int attempted_compress : 1; /* node can't compress; too small */ //测试时使用
unsigned int extra : 10; /* more bits to steal for future usage */ //预留
quicklistNode;
在quicklist使用ziplist时,给了如下的结构体来承载:
typedef struct quicklistEntry
const quicklist *quicklist; //指向当前quicklist
quicklistNode *node;
unsigned char *zi; //指向当前ziplist
unsigned char *value; //该节点字符串内容
long long longval; //该节点整形值
unsigned int sz; //节点大小
int offset; //该节点相对于整个ziplist的偏移量(该节点是整块儿ziplist里的第几个entry)
quicklistEntry;
迭代器少不了吧:
typedef struct quicklistIter
const quicklist *quicklist;
quicklistNode *current;
unsigned char *zi;
long offset; /* offset in current ziplist */
int direction; //迭代器方向
quicklistIter;
关于这个压缩和解压算法我就不贴出来了。位于lzf_c.c 和 lzf_d.c,有兴趣的朋友可以自己去看。
讲真,我看不懂。
以上是关于redis源码学习快速列表 quicklist的主要内容,如果未能解决你的问题,请参考以下文章