从单机百万tpmc到分布式千万tpmc,GaussDB性能提升的3个关键技术剖析
Posted 乌龟哥哥呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从单机百万tpmc到分布式千万tpmc,GaussDB性能提升的3个关键技术剖析相关的知识,希望对你有一定的参考价值。
文章目录
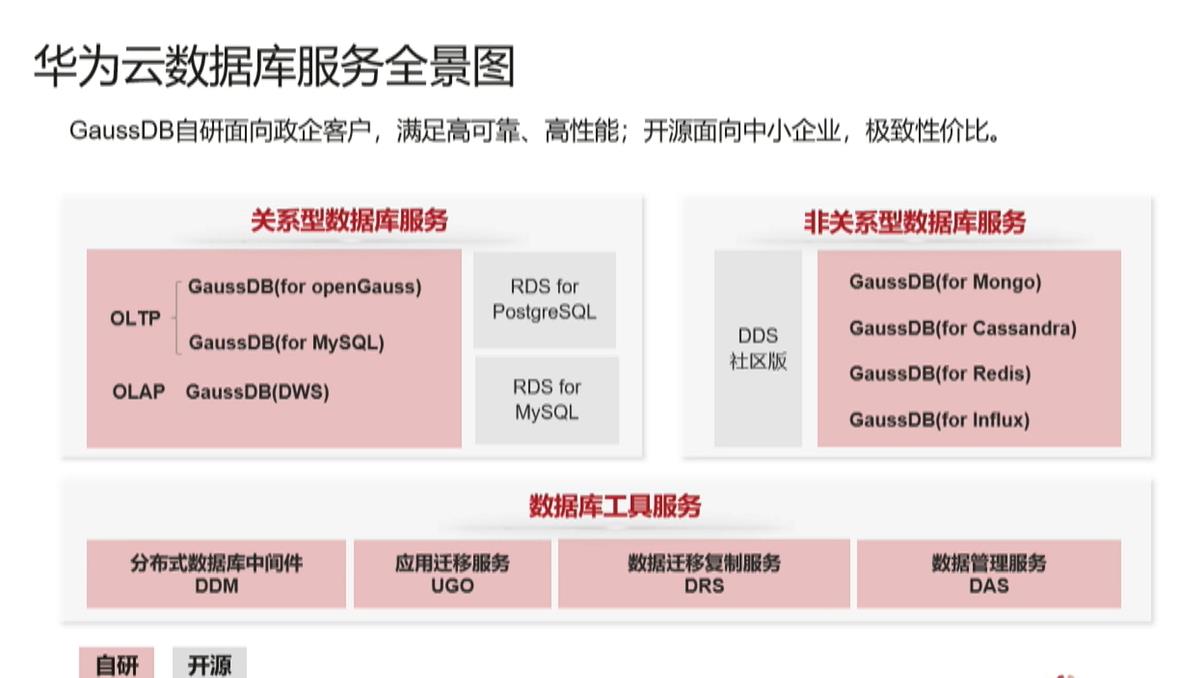
1 华为云数据库服务全景图
1.1 华为云数据库服务
华为云数据库服务分为自研数据库服务和云托管两个主要服务类型
1.2 关系型数据库和非关系型数据库
在关系型数据库中,我们有华为的自研数据库GaussDB,其目前可以支持多种不同的生态
- 支持mysql等主流数据库的接口和语法
- 支持数仓场景
- 支持TP和AP
在非关系型数据库中,我们有两大平台,一个是华为的自研数据库GaussDB,针对当前的市场上主流应用场景(文档型,宽表型,缓存型,实质型)都可以支持,并且和主流数据库接口兼容。
一个是MongoDB等数据库在云上也有托管,华为云提供了很多应用工具助力开发者
- 数据库迁移
- 数据迁移
- 数据库运维(面向不同人员)
- 数据中介服务
2 华为自研数据库关键技术
2.1 GAUSSDB(for openGauss)企业级分布式数据库
定位为企业级分布式云数据库,架构上着重构筑传统数据库的企业级能力和互联网分布式数据库的高扩展和高可用能力

GAUSSDB(for openGauss)架构图
GAUSSDB(for openGauss)面向企业核心应用场景,对标一流数据库打造。
2.1.1 GAUSSDB(for openGauss)遇到的问题
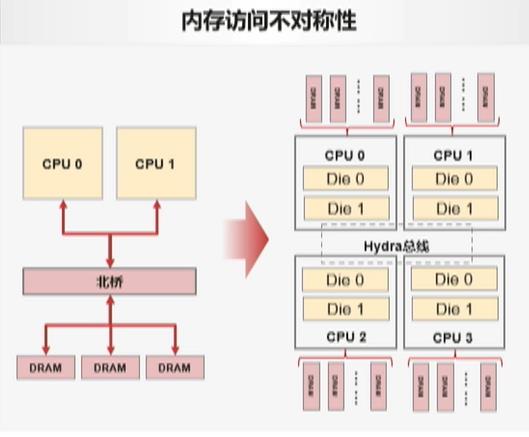
2.1.1.1 内存访问不对称问题

在传统的服务器结构中,我们有CPU,内存等,CPU的速度比内存快很多,需要北桥去对接CPU和内存,从而降低时延
这种情况下,数据库无需关注硬件的连接。
但是随着CPU的速度增加,内存越来越多,北桥的作用越来越小,逐渐被淘汰。
当前当前主机不同的CPU通过高速总线连接在一起,CPU也可以直接连接内存。
这时我们就需要数据库来考虑硬件架构。
2.1.1.2 缓存一致性问题
CPU和内存之间的速率不一样,为了解决速率问题,CPU有一级缓存,二级缓存,三级缓存等,但是当CPU数量过多时,如果数据库无法感知硬件架构,每个CPU都在同时访问
缓存时,都在加载同一个变量,CPU还要保证读写一致性,就会产生问题,这个效率会产生量级的降低
2.1.2 解决方法
2.1.2.1 GAUSSDB(for openGauss)黑科技1:NUMA-Aware极致优化
NUMA-Aware技术原理上感知CPU等硬件架构的不对称问题
实现方法:
- 把存在数据库的数据进行分区处理,尽可能降低CPU之间的冲突问题,提高并行能力,并提供CPU的整体利用率
- 数据库中全局变量有具体单CPU负责处理读操作,其它CPU进行写操作,减少数据访问冲突
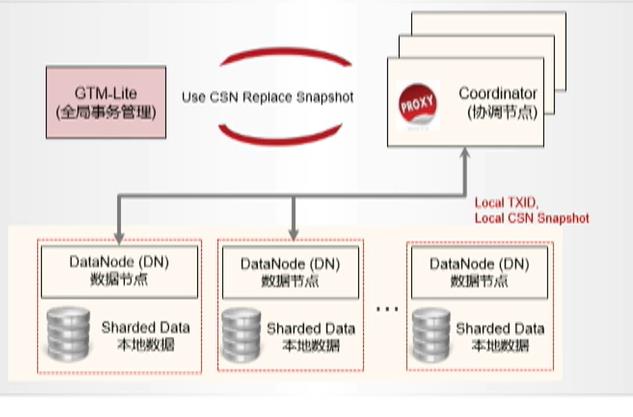
2.1.2.2 GAUSSDB(for openGauss)黑科技2:GTM-Lite分布式拓展技术
分布式强一致,分布式的GTM-Lite方案提供全局事务提交号管理,实现强一致性,且无中心节点性能瓶颈
实现方法:
- CSN时间戳和事务号TXID解耦;
- GTM-Lite仅仅管理全局时间戳;
- 本地时间戳和全局时间戳两维度管理;
- 仅在事务提交时推进全局时间戳;
- 仅在涉及跨Shard访问时才访问全局时间践,否则使用本地时间戳;
- GTM-Lite异步同步,降低GTM-Lite访问时延;
使用全局时间时,需要经过网络多跳,会增加时延。解决方法是协调结点进行同步
2.1.2.3 GAUSSDB(for openGauss)黑科技3:分布式优化器提供极致的分布式扩展能力
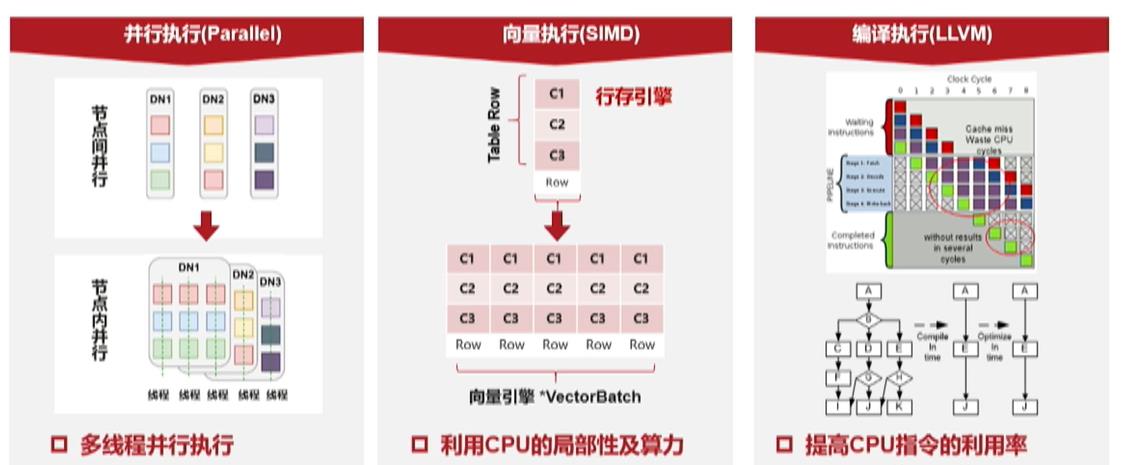
想要利用好系统的资源
-
提高并行执行能力
充分利用当前多核特点,通过多线程并发执行,提高系统吞吐量
-
优化器生成运行规则,通过向量执行,提高执行效率
-
编译执行提高CPU指令的利用率
从解释执行向编译执行转变,答复降低算子的指令数量,提高运算效率
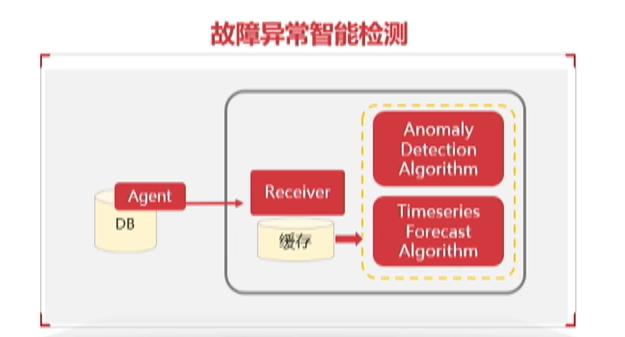
- AI加持驱动数据库自优化,自诊断
结合深度强化学习与全局优化算法,针对不同类别的参数进行细粒度调优
- 调优时间:由天降至分钟级
- 索引推荐:基于用户的单条语句或批量负载,推荐最优索引

持续采集数据库运行数据,基于时序预测和异常检测等算法实现智能监测
- 故障预警:预测资源、性能变化趋势,故障异常智能检测
2.1.3 GAUSSDB(for openGauss)实现效果

优化效果非常不错
2.1.4 GAUSSDB(for openGauss)应用场景举例
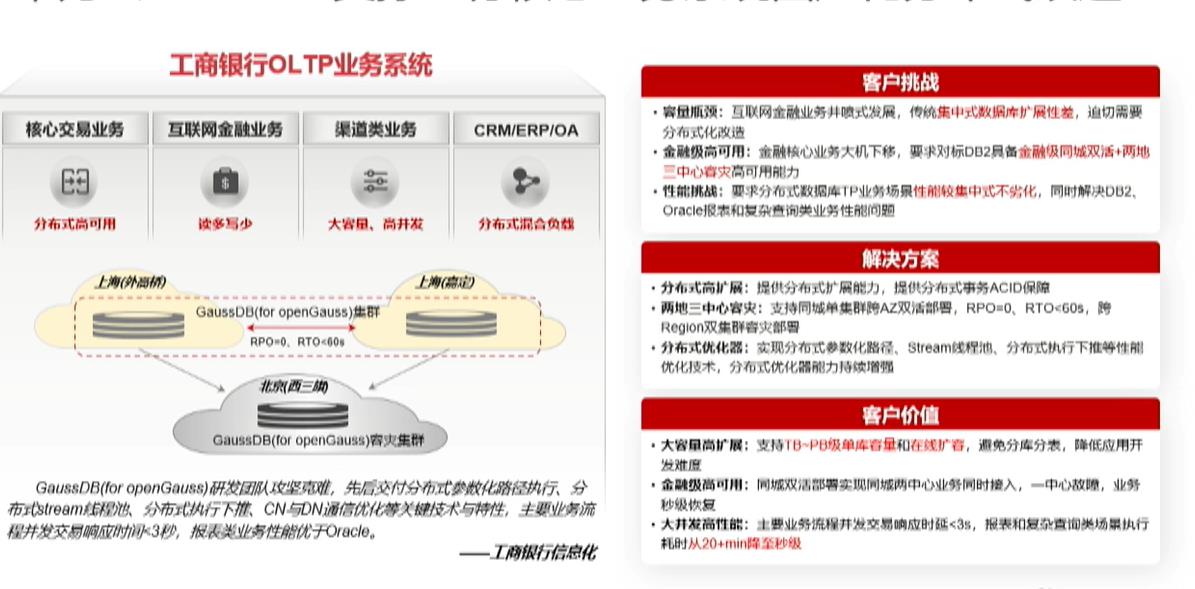
华为云GaussDB支撑工行核心业务系统国产化分布式改造
2.2 面向互联网的云原生数据库架构解析
2.2.1开源Mysql的挑战
- 主备切换RTO时间较长
- 重建实例耗时过长
- 备机只读数据新鲜度低
- 计算与存储不解耦,利用率低
- 网络资源利用率
- 备机数量有限(影响主机性能、组网复杂)

2.2.2 解决方案
2.2.2.1 黑科技1:LOG IS DATABASE,存算分离的云原生数据

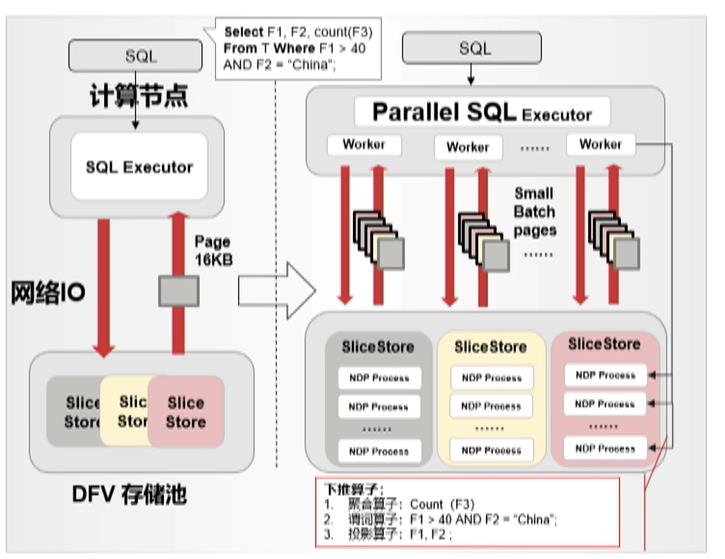
2.2.2.2黑科技2:Near Data Process+并行,提供极致性能

NDP
算子下推支持:投影,谓词,聚合算子,MVCC可见性判断。在存储节点对页面进行判断处理,极大精简返回页面大小,缩减网络IO。count(*)查询缩减IO吞吐达到40-80倍
高度并行(三层并行)
第一层:计算节点多worker并行查询
第二层:由原有一个一个页面串行读,变成批量读多个页面,Page分布在不同slice上,多slice上并行读取
第三层:单个存储节点上,多个NDP处理线程并行处理Page,运算下推算子逻辑。
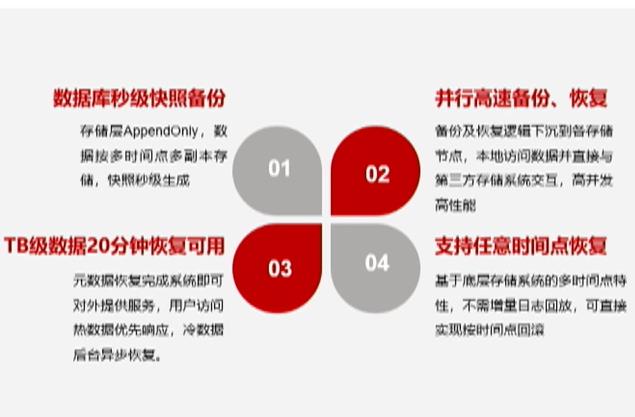
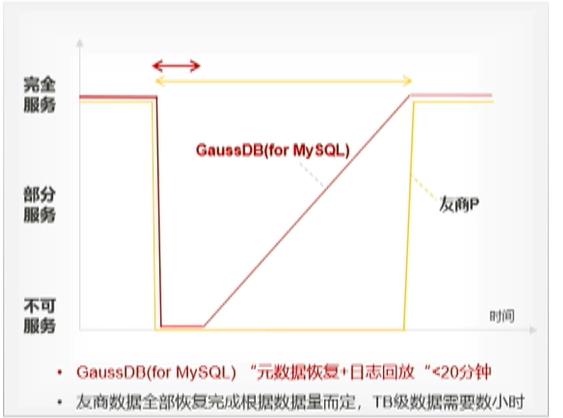
2.2.2.3黑科技3:极致备份恢复
数据库专用分布式存储系统,极致的数据备份恢复性能
整体故障恢复时间比较

2.2.3GaussDB和开源数据库相比优势

2.2.4应用举例
永安保险成功从某主流商业数据库搬迁至GaussDB(for MySQL)

2.3 华为云GaussDB(for Influx)亿级时间线技术解密
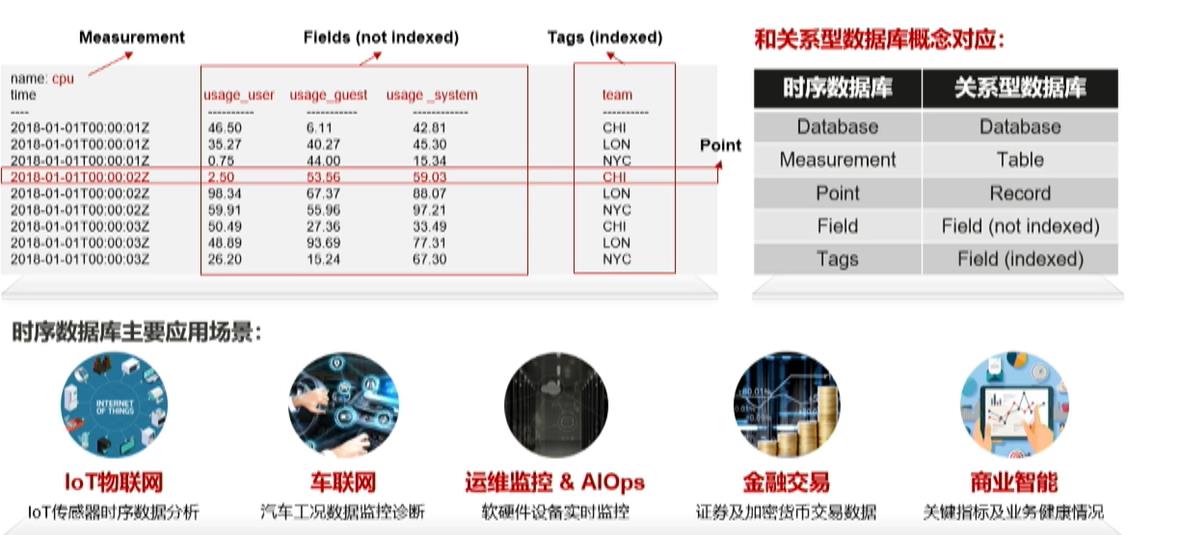
2.3.1 时序数据模型及主要应用场景
时序数据模型应用最多的两个领域是Iot和监控

2.3.2 公有云SRE趋势
2.3.2.1 公有云SRE趋势1:爆炸式增长的时序数据
以CloudMonitorCenter为例,时序数据库支持了两种业务场景的监控原始数据采集与存储
- 系统指标:主要监控CPu、Disk、网卡、负载、TCP、NTP、Ping等。
- 自定义指标:包含容器监控指标、数据库指标、进程指标、中间件指标、日志指标、业务指标等,不同指标类型的指标名称、数据标签、数据类型各不相同.
2.3.2.2 公有云SRE趋势2:时序数据的价值越来越高
2.3.3云上运维监控系统面临的挑战
2.3.3.1 架构现状
2.3.3.2数据膨胀+业务复杂化+业务变化快
华为云业务快速增长过程中的挑战:
- 业务类型多,变化快,分析诉求难于得到快速满足
- 数据规模大,增长速度快数据处理实效要求高
- 不同业务关联度高,故障根因分析困难
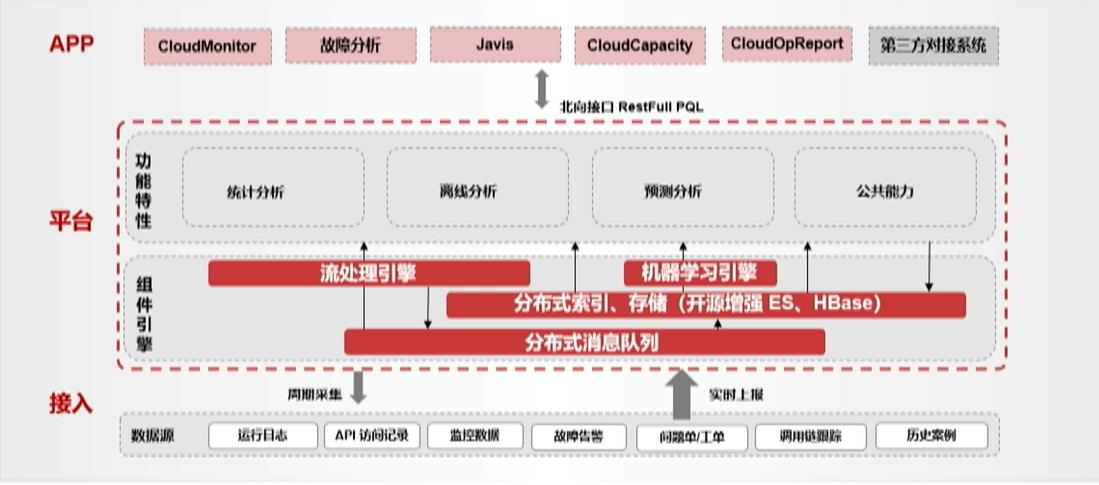
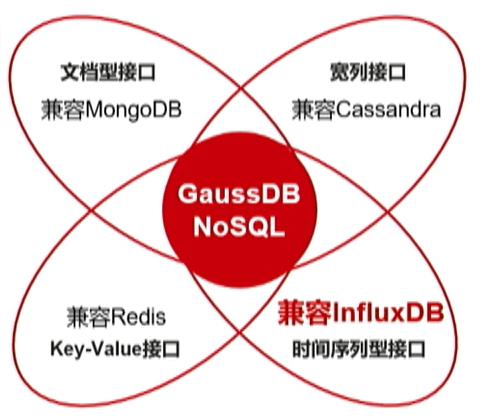
2.3.3.3多模NoSQL服务GaussDB NoSQL
GaussDB NoSQL是基于华为最新一代DFV计算存储分离架构打造的Active-Active全分布式架构多模NoSQL数据库服务,高度兼容MongoDB、Cassandra、Redis、InfluxDB四款主流NoSQL接口,支持跨3AZ高可用集群,相比社区版具有分钟级计算扩容、秒级存储扩容、数据强一致、超低时延、高速备份恢复的优势。适用于loT、气象、互联网、游戏等领域。
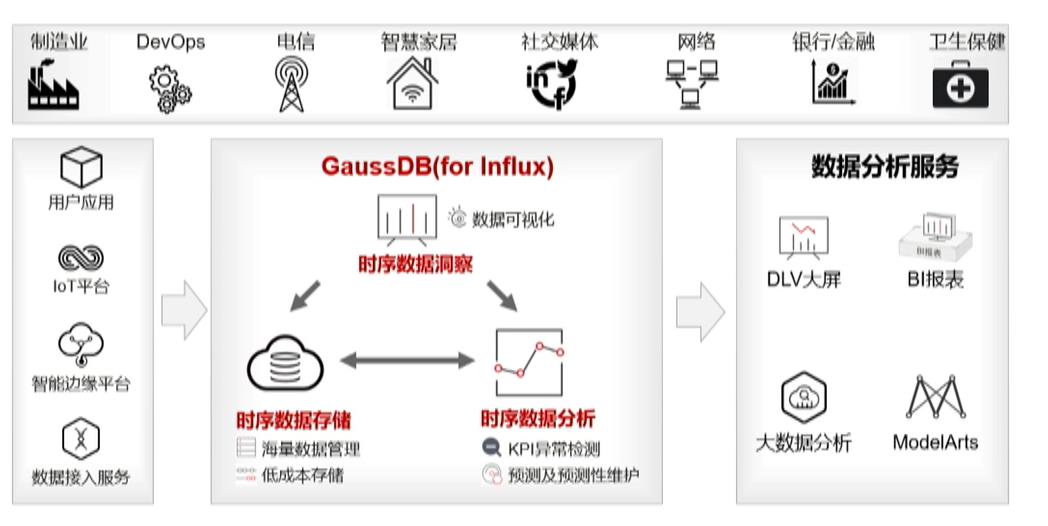
GaussDB(for Influx) : 一站式时序数据存储、分析及洞察平台

2.3.4 云原生时序数据库GaussDB(for Influx)架构
分布式+存储计算分离+高可用

2.3.5GaussDB(for Influx)亿级时间线技术解密
时序数据90%的热点在近期数据,保障海量数据存储的同时提供极致性能
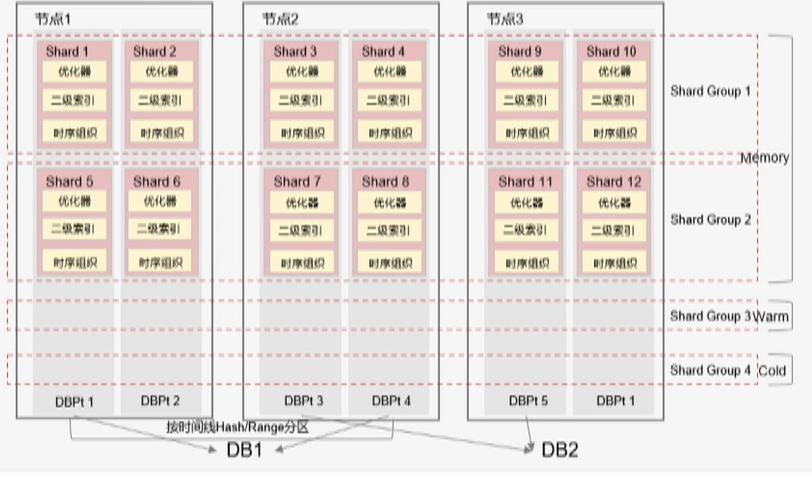
两级分区策略
- 时间分区:数据按时间段分区,分区时长可配置,可根据需求定义全内存、全热存储或者全冷存储数据库。
时间线分区:根据shard key作Range/Hash分区。 - 可根据需求在新的时间分区切换分区策略
(hash/range)
数据分级
- 数据按照时间段分级·热数据在内存
- 温数据在SSD·冷数据放HDD
专用存储引擎
写性能加速
- 批流结合预聚合数据
- 异步日志
- 行列混合内存布同,减小数据转换开销
时序文件布局
- 面向时序数据专用布局
- 列式存储,多级索引
- 多版本平滑升级
多级压缩算法
- 时间相似性压缩算法
- 时间差量压缩
多模索引
- 维度索引:倒排索引定位数据源
- 时间线索引∶海量时间线kv索引
查询加速
- 增加立件级BRIN索引,减小聚合计算,加速Scan
- 多级cache,加速聚合查询
- 优化器代价评估,作大查询控制,选择二级索引or扫描
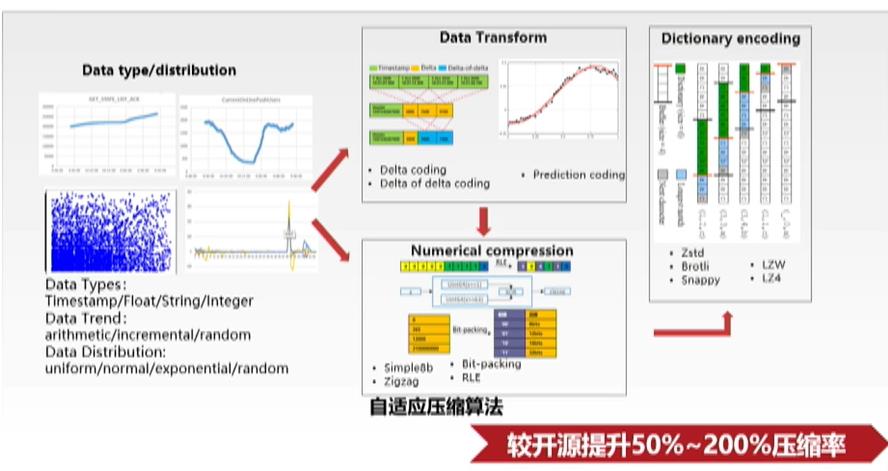
自适应压缩算法
根据Timestamp以及field data不同数据类型以及数据变化趋势,采用不同的数值变换算法,再根据变换后的数据分布设计自适应数值压缩算法,最后结合高性能的字典编码方法实现时序数据的高效自适应压缩。同时针对TSM文件内的时间羸进行相似性压缩,进一步降低时序数据存储成本。
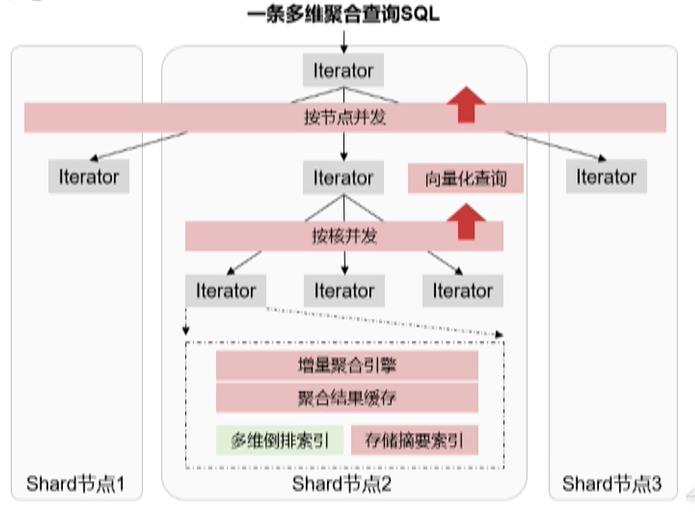
高性能多维聚合查
大数据量聚合查询性能是开源的2~5倍;支持多维条件组合查询;
技术方案
- MPP架构,一条查询语句在多节点及多核并发执行;
- 向量化查询引擎,每次迭代批量返回数据,大数据星下查询性能更好;
- 增量聚合引擎基于滑动窗口的聚合查询,大部分从聚合结果缓存直接命中返回,仅而要聚合增量数据部分即可;
- 支持多维倒排索引,支持多维条件组合查询,避免大量Scan数据;
- 支持存储摘要索引,能够更快的过滤无关数据;

存储分析告截

以上是关于从单机百万tpmc到分布式千万tpmc,GaussDB性能提升的3个关键技术剖析的主要内容,如果未能解决你的问题,请参考以下文章
从单机百万tpmc到分布式千万tpmc,GaussDB性能提升的3个关键技术剖析
猿创征文|从单机百万tpmc到分布式千万tpmc,GaussDB性能提升的3个关键技术剖析
猿创征文|从单机百万tpmc到分布式千万tpmc,GaussDB性能提升的3个关键技术剖析