大数据开发工程师需要了解的数仓中的维度设计
Posted <一蓑烟雨任平生>
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据开发工程师需要了解的数仓中的维度设计相关的知识,希望对你有一定的参考价值。
目录
(1)数仓模型如何分层
企业常用的数据模型分为三层:
- 操作数据层(ODS)
- 公共维度模型层(CDM)
- 数据应用层(ADS)
其中公共维度模型层包括:
- 明细数据层(DWD)
- 汇总数据层(DWS)

操作数据层(ODS) :把操作系统数据几乎无处理地存放在数据仓库系统中。
- 同步:结构化数据增量或全量同步数仓
- 结构化 :非结构化(日志)结构化处理并存储到数仓
- 累积历史、清洗:根据数据业务需求及稽核和审计要求保存历数据、清洗数据
公共维度模型层(CDM) :存放明细事实数据、维表数据及公共指标汇总数据
其中明细事实数据、维表数据一般根据ODS层数据加工生成;
公共指标汇总数据一般根据维表数据和明细事实数据加工生成。
CDM层又细分为:
- DWD层:明细数据层
- DWS层:汇总数据层
采用维度模型方法作为理论基础,更多地采用一些维度退化手法,将维度退化至事实表中,减少事实表和维表的关联,提高明细数据表的易用性;同时在汇总数据层,加强指标的维度退化,采取更多的宽表化手段构建公共指标数据层,提升公共指标的复用性,减少重复加工。
其主要功能如下:
- 组合相关和相似数据:采用明细宽表,复用关联计算,减少数据扫描
- 公共指标统一加工 :基于One Data体系构建命名规范、口径一致和算法统一的统计指标,为上层数据产品、应用和服务提供公共指标;建立逻辑汇总宽表。
- 建立一致性维度:建立一致的数据分析维表,降低数据计算口径算法不统一 的风险。
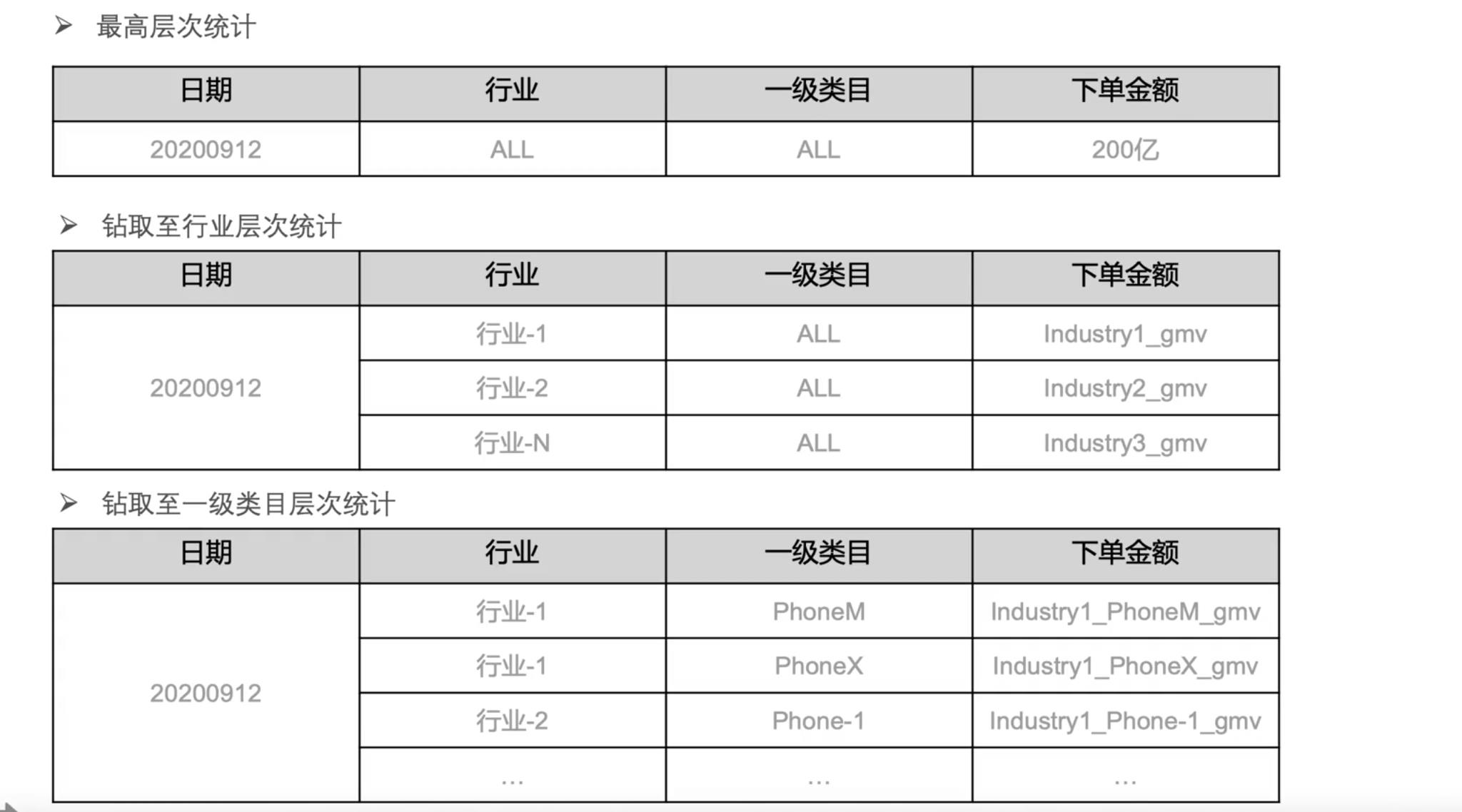
(2)企业数仓模型分层架构

(3)维度设计如何理解
维度是维度建模的基础和灵魂。在维度建模中,将度量称为“事实”将环境描述为“维度”,维度是用于分析事实所需要的多样环境。 例如,在分析交易过程时,可以通过买家、卖家、商品和时间等维度描述交易发生的环境。
维度所包含的表示维度的列,称为维度属性。维度属性是查询约束条件、分组和报表标签生成的基本来源,是数据易用性的关键。
例如,在查询请求中,获取某类目的商品、正常状态的商品等,是通过约束商品类目属性和商品状态属性来实现的;统计不同商品类目的每日成交金额,是通过商品维度的类目属性进行分组的;
我们在报表中看到的类目都是维度属性。所以维度的作用一般是查询约束、分类汇总以及排序等。
如何获取维度或维度属性
- 报表中获取
- 和业务人员的交谈中发现维度或维度属性
因为它们经常出现在查询或报表请求中的“按照”(group by)语句内。 例如,用户要“按照”月份和产品来查看销售情况,那么用来描述其业务的自然方法应该作为维度或维度属性包括在维度模型中。
维度的基本设计方法
维度的设计过程就是确定维度属性的过程,如何生成维度属性,以及所生成的维度属性的优劣,决定了维度使用的方便性,成为数据仓库易用性的关键。正如Kimball所说的,数据仓库的能力直接与维度属性的质量和深度成正比。
- 第一步:选择维度或新建维度。作为维度建模的核心,在企业级数据仓库中必须保证维度的唯一性, 只允许有个维度定义。
- 第二步:确定主维表。此处的主维表一般是ODS表,直接与业务系统同步。
- 第三步:确定相关维表。数据仓库是业务源系统的数据整合,不同业务系统或者同一业务系统中的表之间存在关联性。根据对业务的梳理,确定哪些表和主维表存在关联关系,并选择其中的某些表用于生成维度属性。以商品维度为例,根据对业务逻辑的梳理,可以得到商品与类目、卖家、店铺等维度存在关联关系。
- 第四步:确定维度属性。本步骤主要包括两个阶段,其中第一个阶段是从主维表中选择维度属性或生成新的维度属性;第二个阶段是从相关维表中选择维度属性或生成新的维度属性
确定维度属性的几点提示
- 尽可能多地给出包括一些富有意义的文字性描述
- 属性不应该是编码,而应该是真正的文字,一 般是编码和文字同时存在,比如商品维度中的商品ID和商品标题类目ID和类目名称等。ID一般用于不同表之间的关联,而名称一般用于报表标签。
- 区分数值型属性和事实
- 数值型字段是作为事实还是维度属性,可以参考字段的一般用途。如果通常用于查询约束条件或分组统计,则是作为维度属性;如果通常用于参与度量的计算,则是作为事实。比如商品价格,可以用于查询约束条件或统计价格区间的商品数量,此时是作为维度属性使用的;也可以用于统计某类目下商品的平均价格,此时是作为事实使用的。另外,如果数值型字段是离散值,则作为维度属性存在的可能性较大;如果数值型字段是连续值,则作为度量存在的可能性较大,但并不绝对,需要同时参考字段的具体用途。
- 尽量沉淀出通用的维度属性
- 有些维度属性获取需要进行比较复杂的逻辑处理,有些需要通过多表关联得到,或者通过单表的不同字段混合处理得到,或者通过对单表的某个字段进行解析得到。此时,需要将尽可能多的通用的维度属性进行沉淀
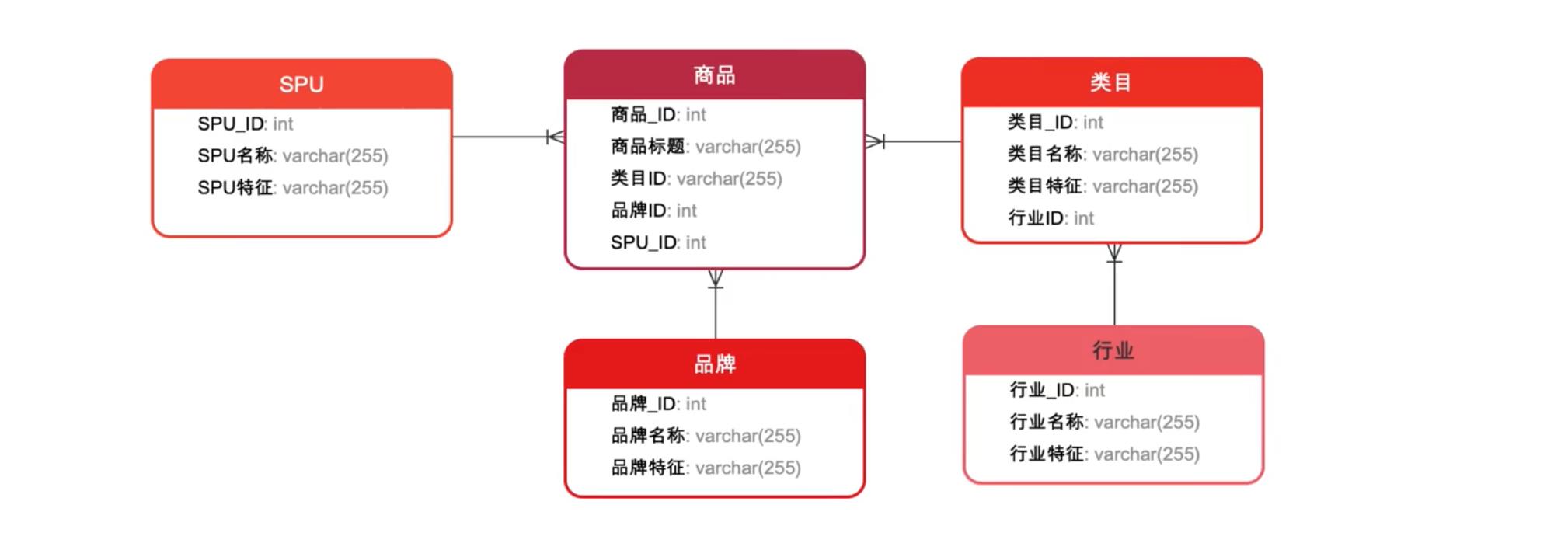
(4)维表是怎么生成的
维度的层次结构
规范化与反规范化
对于商品维度,采用雪花模式进行规范化处理,如果将维度的属性层次合并到单个维度中的操作称为反规范化。分析系统的主要目的是用于数据分析好统计,如何更方便用户进行统计分析决定了分析系统的优劣。采用雪花模式,用户在统计分析的过程中需要大量的关联操作,使用复杂度高,同时查询性能很差;而采用反规范化处理,则方便、易用性能好。
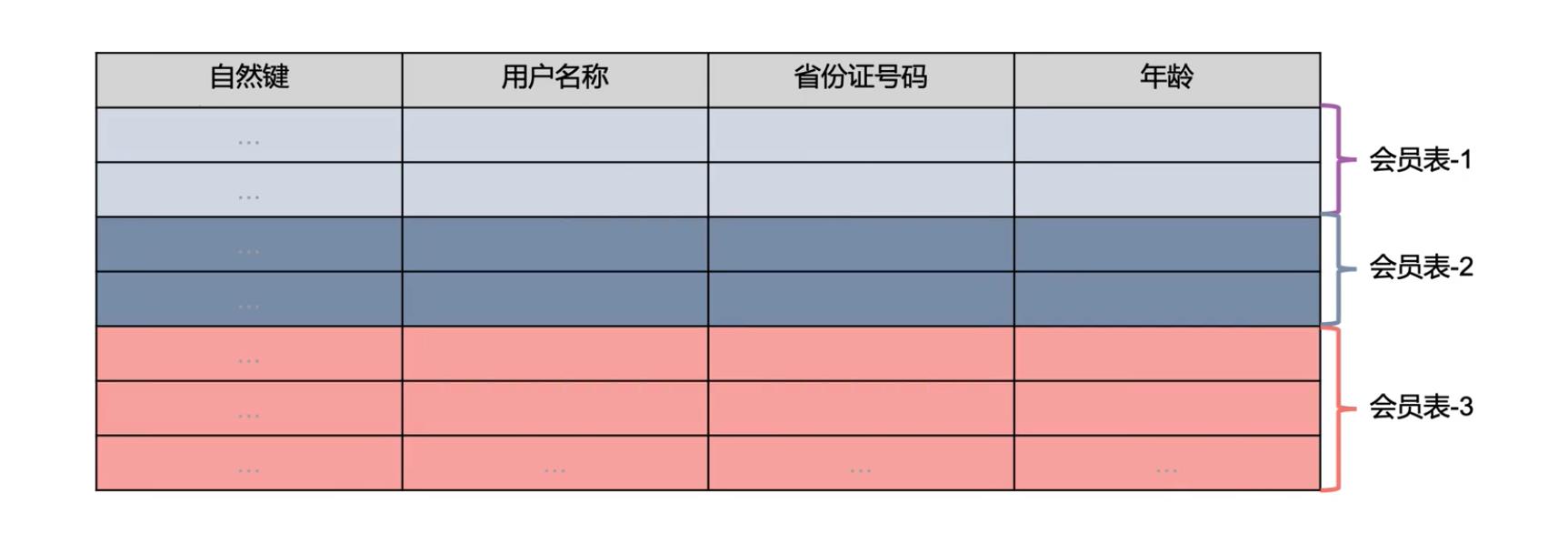
(5)维度整合的两种策略
第一种是垂直整合,即不同的来源表包含相同的数据集,只是存储的信息不同。

第二种是水平整合,即不同的来源表包含不同的数据集。
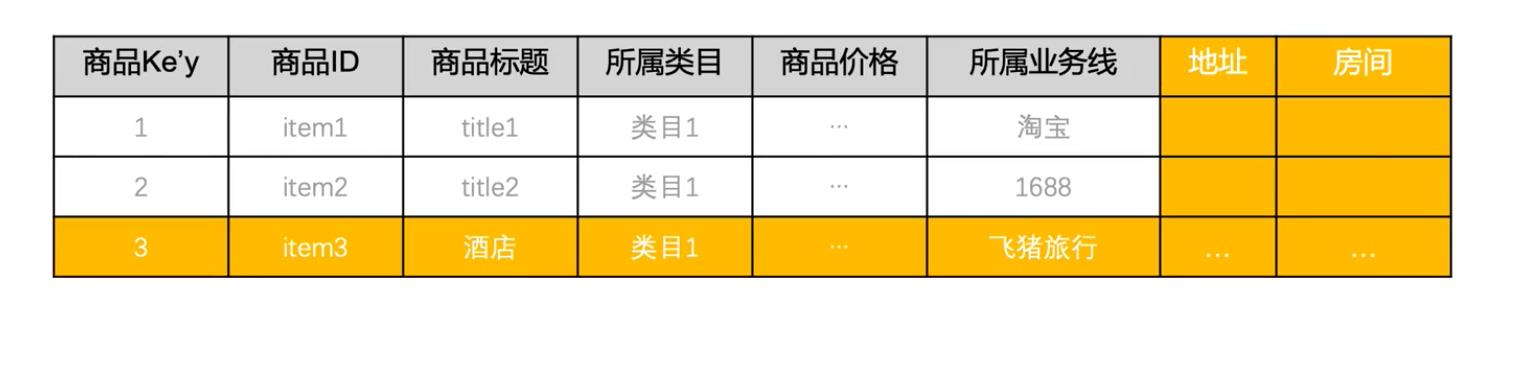
(6)维度拆分的最佳方案
水平拆分
维度通常可以按照类别或类型进行细分。比如淘系商品表,根据业务线或行业等可以对商品进行细分,如淘宝的商品、天猫的商品、1688的商品、飞猪旅行的商品、 淘宝海外的商品、天猫国际的商品等。不同分类的商品,其维度属性可能相同,也可能不同。比如航旅的商品和普通的淘系商品,都属于商品,都有商品价格、标题、类型、上架时间类目等维度属性,但是航旅的商品除了有这些公共属性外,还有酒店景点、门票、旅行等自已独特的维度属性。
主要有两种解决方案
方案一:是将维度的不同分类实例化为不同的维度,同时在主维度中保存公共属性

当维度属性随类型两个依据变化较大时,将所有可能的属性建立在一个表中是不切合实际的,也没有必要这样做,此时建议采用此方案。定义一个主维度用于存放公共属性;同时定义多个子维度,其中除了包含公共属性外,还包含各自的特殊属性。公共属性一般比较稳定,通过核心的商品维度,保证了核心维度的稳定性;通过扩展子维度的方式,保证了模型的扩展性。
方案二:是维护单一维度,包含所有可能的属性

通常来说推荐方案二。
垂直拆分
在进行维度设计时,依据维度设计的原则,尽可能丰富维度属性,同时进行反规范化处理。对于具体实现时可能存在的问题,一是在“水平拆分”中提到的,由于维度分类的不同而存在特殊的维度属性,可以通过水平拆分的方式解决此问题。二是某些维度属性的来源表产出时间较早,而某些维度属性的来源表产出时间较晚;或者某些维度属性的热度高、使用频繁,而某些维度属性的浓度低、较少使用;或者某些维度属性经常变化,而某些维度属性比较稳定。在“水平拆分”中提到的模型设计的三个原则同样适合解决此问题。出于扩展性、产出时间、易用性等方面的考虑,设计主从维度。主维表存放稳定、产出时间早、热度高的属性;从维表存放变化较快、产出时间晚、热度低的属性。

(7)缓慢变化维的处理方式
维度的属性并不是静态的,它会随着时间的流逝发生缓慢的变化。与数据增长较为快速的事实表相比,维度变化相对缓慢。在维度建模理论中,有三种处理缓慢变维的方式:
第一种处理方式: 重写维度值。说白了就是做update,采用此种方式,不保留历史数据,始终取最新数据。

第二种处理方式: 插入新的维度。采用此种方式,保留历史数据,维度值变化前的事实和过去的的维度值关联。维度值变化后的事实和当前维度值关联。

第三种处理方式: 添加维度列。采用第二种方式不能将变化前后记录的事实归一为变化前的维度或归一为变化后的维度。

(8)企业中处理缓慢变化维的最佳方案
在企业 数据仓库实践中,处理缓慢变化维的方法是采用快照方式。
数据仓库的计算周期一般是每天一次,基于此周期,处理维度变化的方式就是每天保留一份全量快照数据。比如商品维度,每天保留一份全量商品快照数据。任意一天的事实均可以获取到当天的商品信息,也可以获取到最新的商品信息,通过限定日期,采用自然键进行关联即可。
此方法既有优点,也有弊端。
优点主要有以下两点:
- 简单而有效, 开发和维护成本低
- 使用方便,理解性好。数据使用方只需要限定日期,即可获取到当天的快照数据。任意一 天的事实快照和维度快照通过维度的自然键进行关联即可。
弊端主要体现在存储的极大浪费上。比如某维度,每天的变化量占总体数据量的比例很低,在极端情况下,每天无变化,使得存储浪费很严重。此方法主要就是实现了牺牲存储获取ETL效率的优化和逻辑上的简化。但是一定 要杜绝过度使用这种方法,而且必须要有对应的数据生命周期制度,清除无用的历史数据。
对上述方案的优化:
基于第二处处理方案的基础之,上采用拉链表存储,即我们可以增加两个时间戳字段。

这个方案的缺陷:
这种存储方式对于下游使用方存在一定的理解障碍,特别是ODS数据面向的下游用户包括数据分析师、前端开发人员等,他们不怎么理解维度模型的概念,因此会存在较高的解释成本。
透明化
底层的数据还是历史拉链表,但是上层做一个视图操作或者在Hive里做一个hook, 通过分析语句的语法树,让查询透明化
select * from A where ds = 20200910
等价于
select * from A where start_dt <= 20200910 and end_dt > 20200910
(9)微型维度到底有没有用
通过将一些属性从维表中移出,放置到全新的维表中,可以解决维度的过渡增长。解决方法有两种,一种是之前讲到的垂直拆分,保持主维度的稳定性;另一种解决方式是采用微型维度。
微型维度的创建是通过将一部分不稳定的属性从主维度中移出,并将他们放置到拥有自己代理键的新表中来实现。这些属性相互之间没有之间关联,不存在自然键。
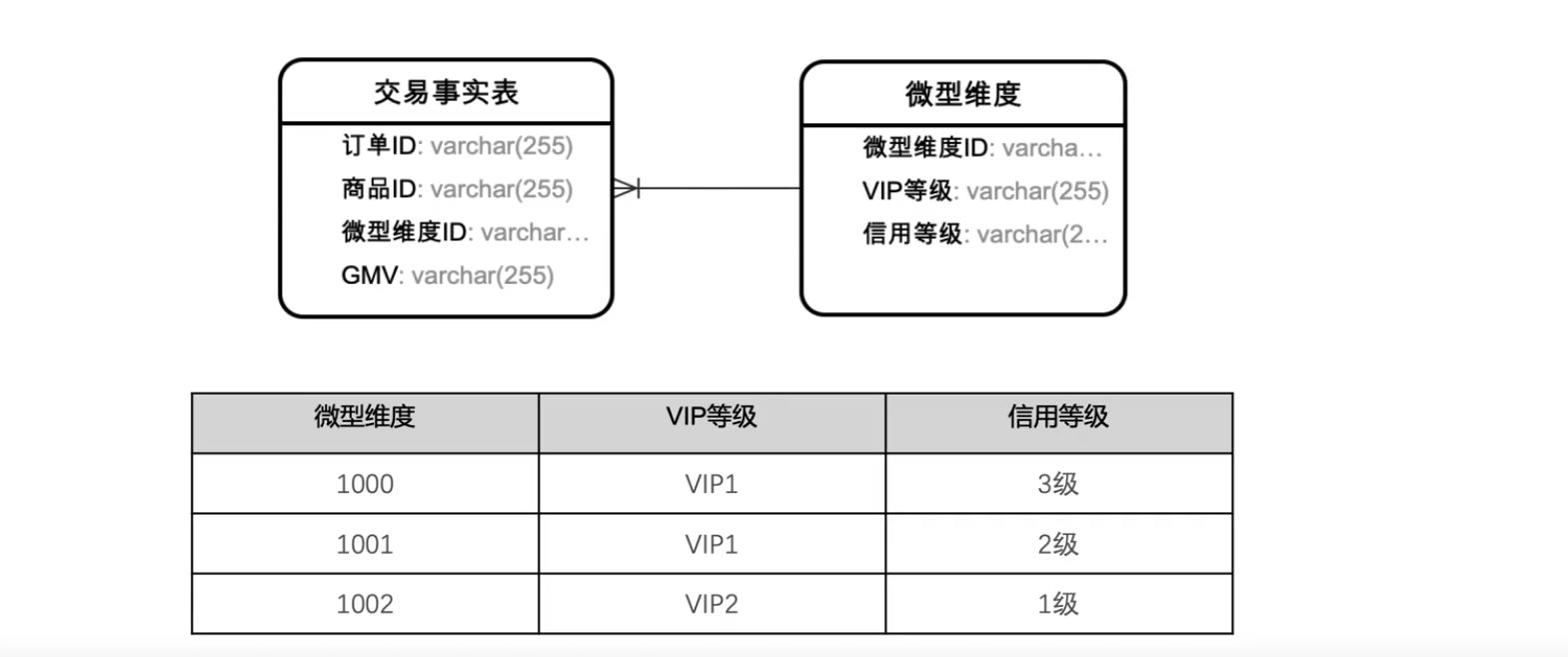
一般企业对微信维度用的比较少,原因是:
微型维度是事先用所有可能值的组合加载的,需要考虑每个属性的基数,且必须是枚举值。很多属性可能是非枚举型,比如数值类型,如VIP分数、 信用分数等;时间类型,如,上架时间、下架时间、变更时间等。
(10)特殊维度中的递归层次
递归层次指的是某维度的实例值的层次关系
维度的递归层次,按照层次是否固定分为均衡层次结构和非均衡层次结构。
比如:
- 均衡层次有:
类目:一级、二级、三级、四级
地区:乡镇、区县、城市、省份、国家 - 非均衡层次有:
公司(比如公司之间的关系,每个公司可能存在一个母公司,但可能没有固定的一级、二级等层次关系)

由于很多数据仓库系统和商业智能工具不支持递归SQL,且用户使用递归SQL的成本较高,所以在维度模型中,需要对递归层次进行处理。
方案一:层次结构扁平化,对于均衡层次结构,采用扁平化最有效
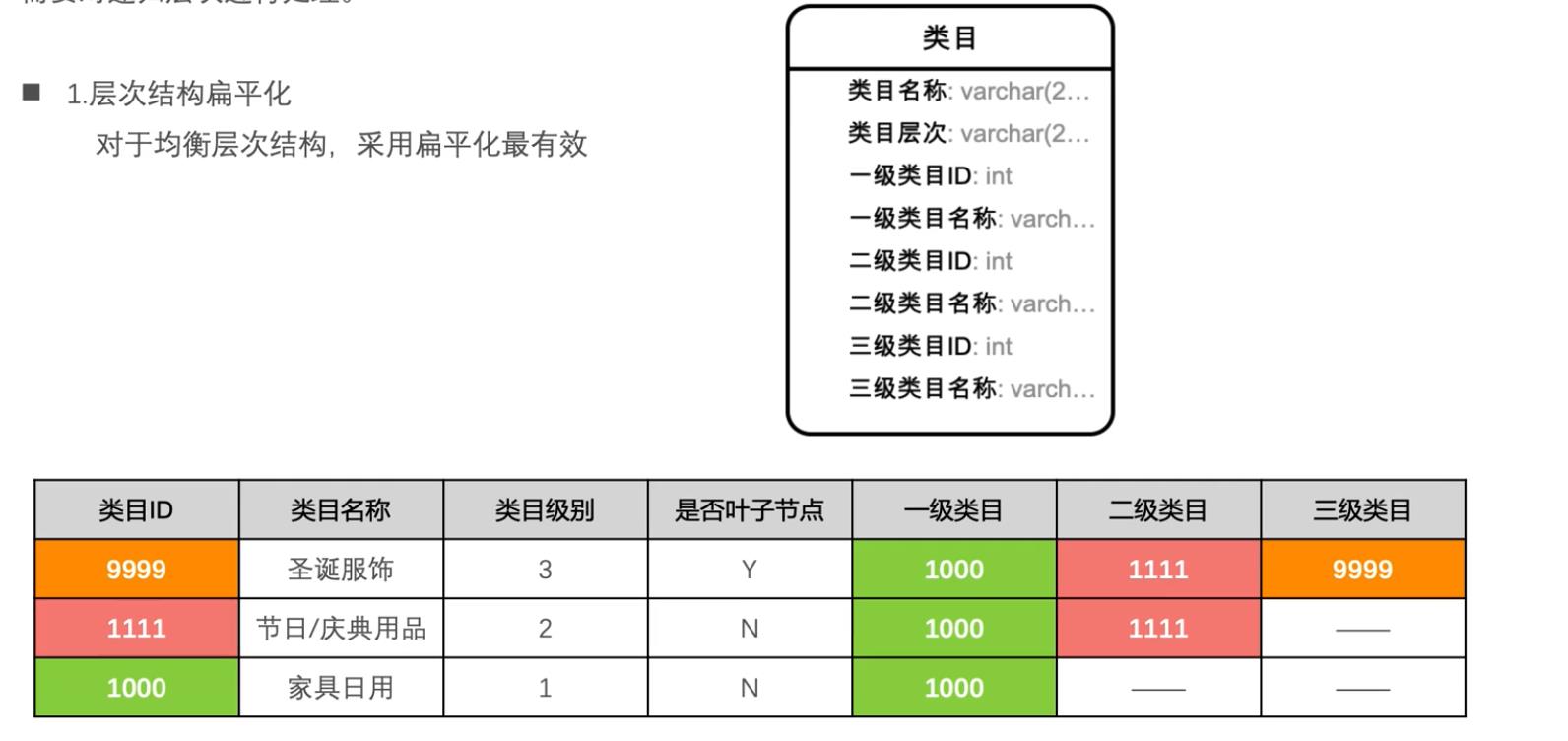
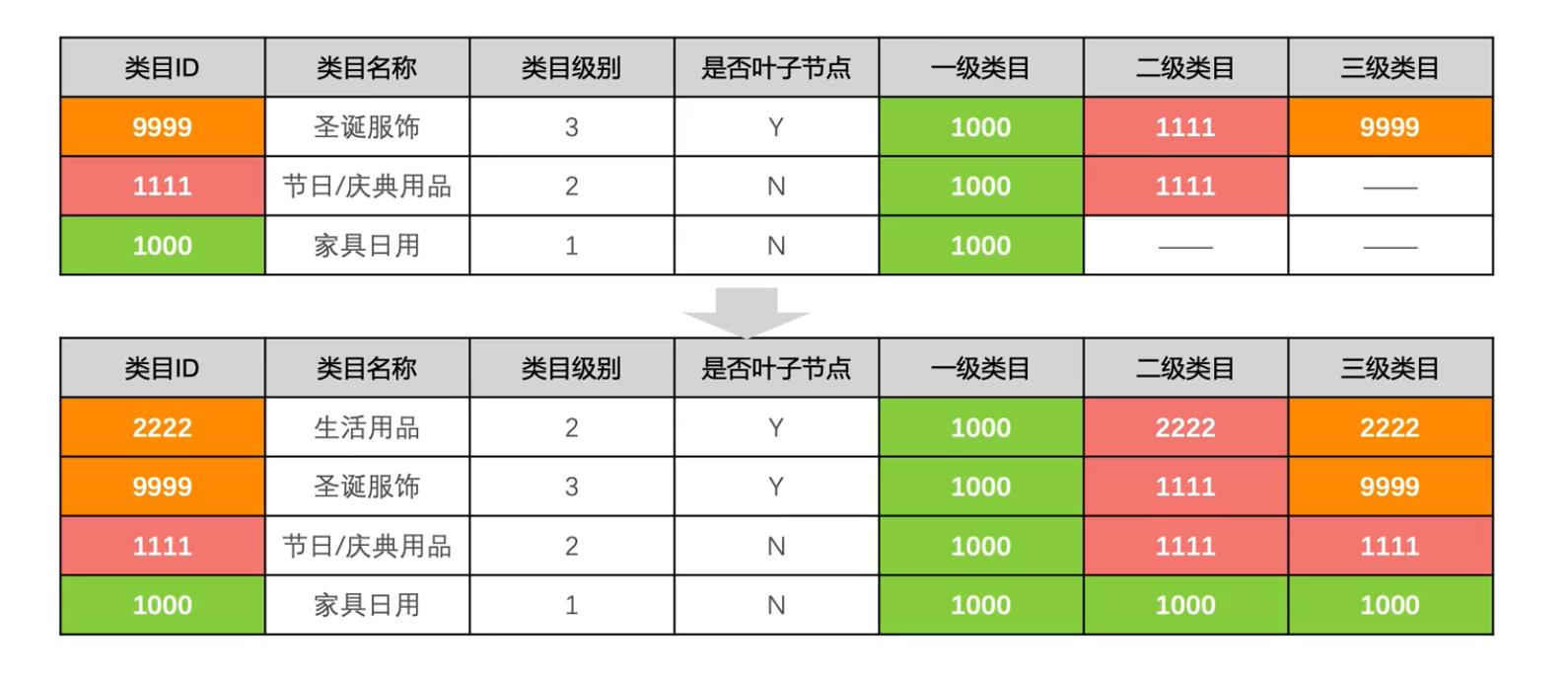
与事实表关联后,有的三级类目为空,导致根据三级类目无法统计交易结果。所以下游为了规避此问题, 如果此类目对应的三级类目为空,则取二级类目;如果二级类目为空,则取一级类目。
所以我们可以采用类目回填的方式,将类目向下虚拟。
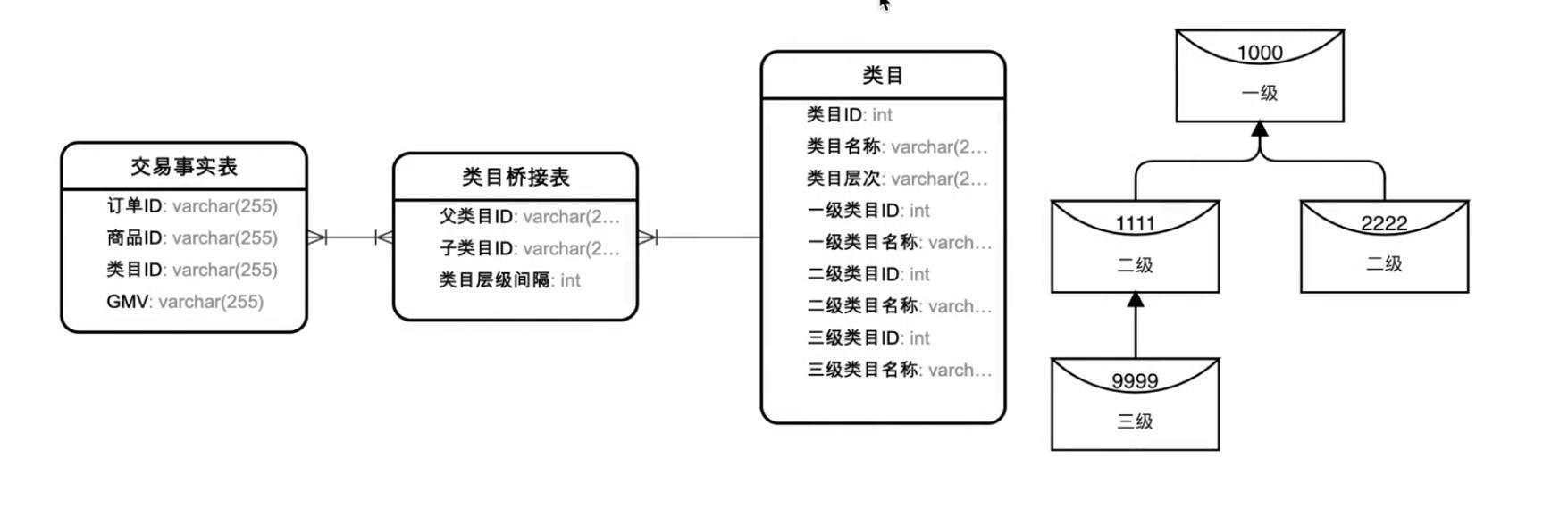
方案二: 层次桥接表
针对层次结构扁平化所存在的问题,可以采用桥接表的方式来解决,不需要预先知道所属层级,不需要回填, .也可解决非均衡层次结构的问题。与扁平化方法相比,该方法适合解决更宽泛的分析问题,灵活性好;但复杂性高,使用成本高。
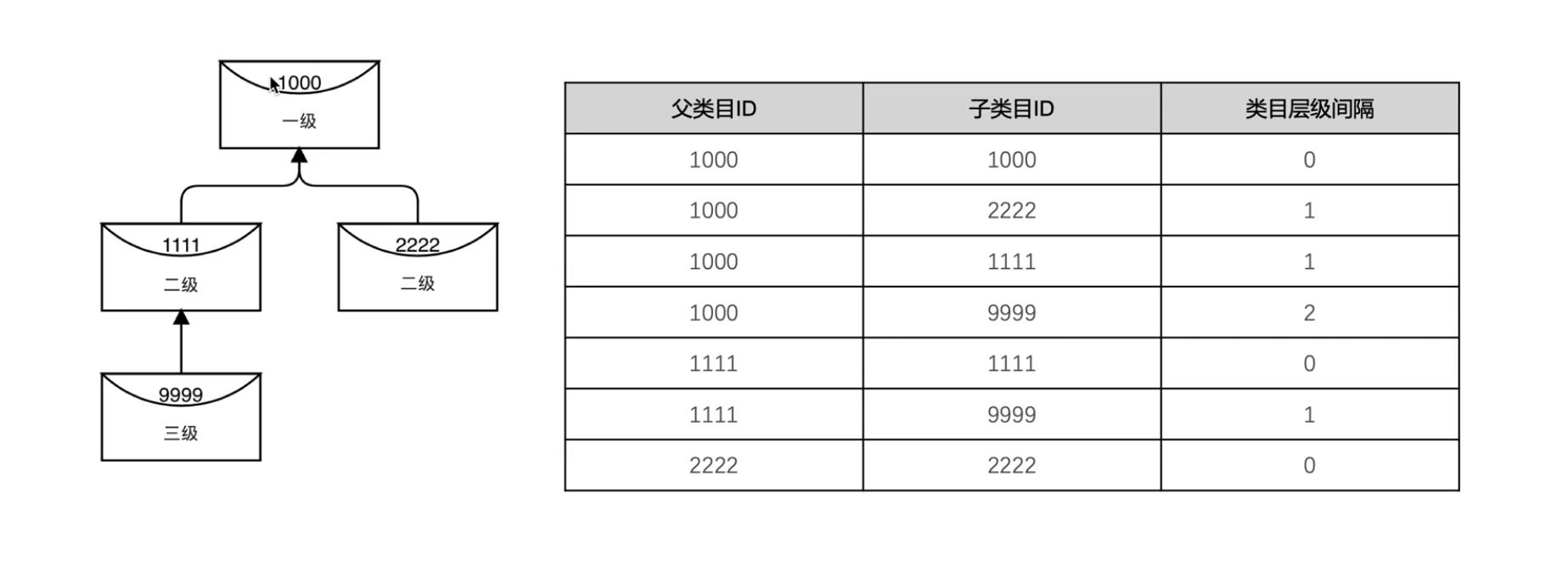
(11)多值维度的处理方式
事实表的一条记录在商品维表中有多条记录与之对应,比如买家一次购买了多种商品。
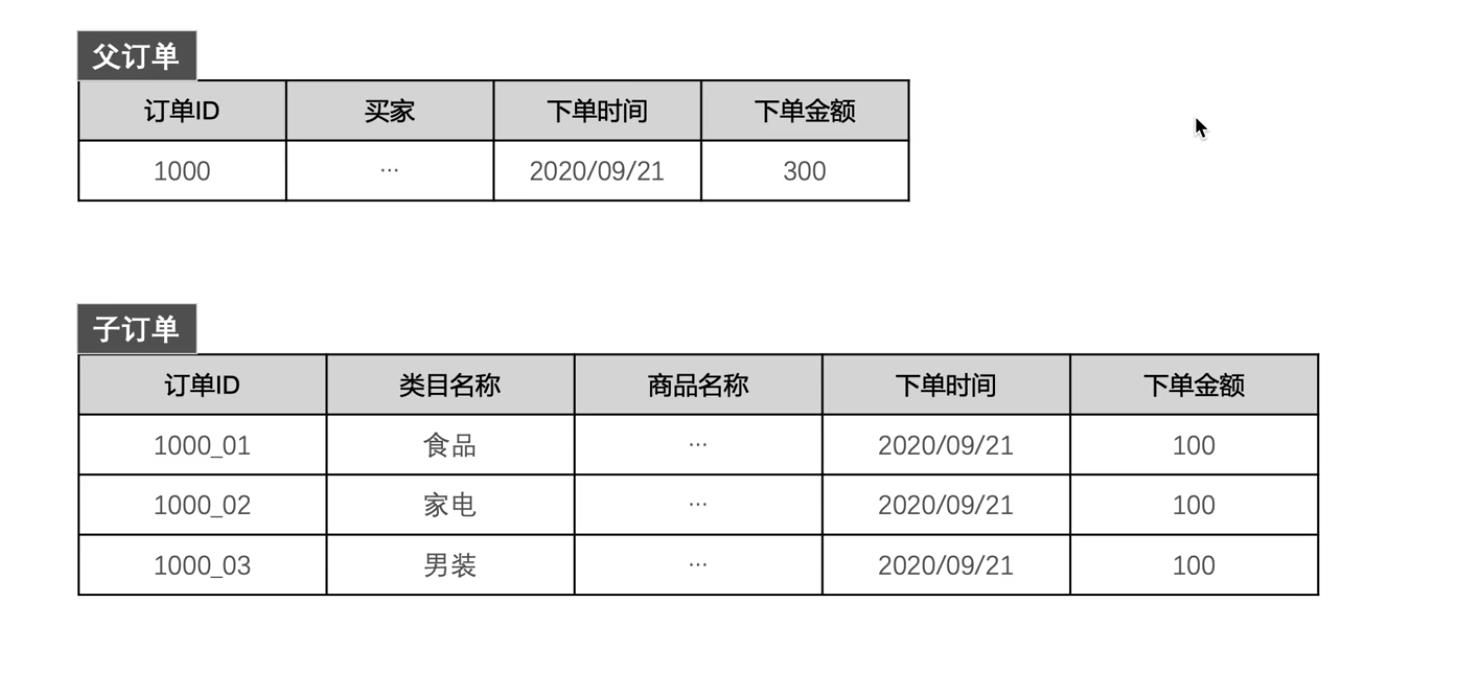
多值维度的处理方式有三种:
-
第一种:降低事实表的粒度, 将交易订单设置为子订单粒度,对于每个子订单,
只有一种商品与之对应。对于其中的事实,则采用分摊到子订单的方式来解决。 -
第二种:采用多字段。比如在房地产销售中,每次合同签订都可能存在多个买受
方的情况。如夫妻合买,对于合同签订事实表,每条记录可能对应多个买受方,而合同已经是此事实中的最细粒度,无法通过降低粒度的方式来解决,由于合同签订的买受人不会太多,所以一般采用多字段方式。 -
第三种:采用较为通用的桥接表。桥接表方式更加灵活、扩展性好。但逻辑复杂、开发和维护成本高。

桥接表包含和事实表关联的分组KEY,以及作为买买方维表外键的买受方ID.如果事实表的一条记录对应两个买受方,则桥接表针对这两个买受方建立两条记录,分组KEY相同。
(12)多值属性的处理方式
维表中的某个属性字段同时有多个值,称之为多值维度。它是多维度的另一种表现形式。互联网公司的电商项目中存在很多维表,如商品的SKU维表、商品属性维表、商品标签维表等。每个商品均有一到多个SKU、一到多个属性和一到多个标签,所以商品的SKU、属性、标签都是多堆垛的关系。
- SPU = Standard Product Unit (标准化产 品单元),SPU是商品信息聚合的最小单位,是一组可复用、易检索的标准化信息的集合,该集合描述了一个产品的特性。通俗点讲,属性值、特性相同的商品就可以称为一个SPU。例如,iphone4就是一 一个SPU, N97也是一个SPU, 这个与商家无关,与颜色、 款式、套餐也无关。
- SKU=stock keeping unit(库存量单位),SKU即库存进出计量的单位,可以是以件、 盒、托盘等为单位。在服装、鞋类商品中使用最多最普遍。例如纺织品中一个SKU通常表示: 规格、颜色、款式。
SKU是物理上不可分割的最小存货单元。在使用时要根据不同业态,不同管理模式来处理。比如一香烟是50条,一条里有十盒,一盒中有20支,这些单位就要根据不同的需要来设定SKU。
常见的多值属性处理方式有三种:
- 第一种处理方式是保持维度主键不变,将多值属性放在维度的一个属性字段中,通过K-V对的形式

- 第二种处理方式是保持维度主键不变,将多值属性放在维度的多个属性字段中。
比如卖家主营类目,由于卖家店铺中可能同时会销售男装、女装、内衣等。所以卖家主营类目可能有多个,但业务需求是计算TopN,

- 第三种处理方式是维度主键发 生变化,一个维度值存放多条记录。
主键是商品的ID + SKU的ID

以上内容仅供参考学习,如有侵权请联系我删除!
如果这篇文章对您有帮助,左下角的大拇指就是对博主最大的鼓励。
您的鼓励就是博主最大的动力!
以上是关于大数据开发工程师需要了解的数仓中的维度设计的主要内容,如果未能解决你的问题,请参考以下文章