量化交易中,如何快速把股票代码转换成Int整形?
Posted beyondma
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了量化交易中,如何快速把股票代码转换成Int整形?相关的知识,希望对你有一定的参考价值。
最近笔者在量化交易的大神沟通中,收到这样一个需求,需要快速把股票代码转换成整形变量,也就是需要把新收到的股票交易信息,迅速与历史的股票信息结合起来,从而通过交易策略快速决策。
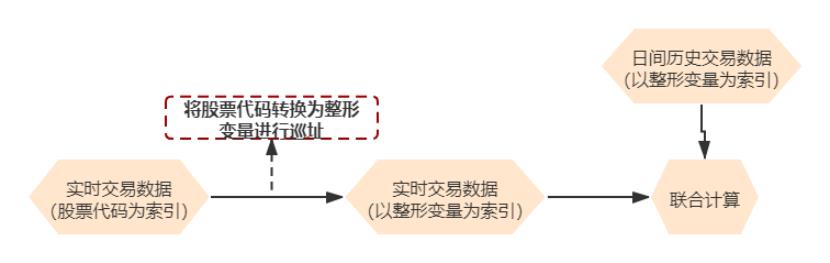
由于量化交易速度就是生命线,因此直接通过股票代码去在数据库中查询到同一股票的历史数据对于这个场景来说就太慢了。目前来说比较通行的做法就是把股票代码直接映射成整 形,而映射之后的这个整形又是历史数据的内存地址,这样才是效果比较高的做法。如下图:
由于量化交易一般都是武装到牙齿的,所以资源基本不是什么问题,总而言之就是一定要快。
解决方案分析
一般来说目前的做法是用xxhash等高速哈希算法来进行这个转换,但是xxhash的时间复杂度对于量化场景来说还是有点高,那么在提出优化方案之前我们再对于这个需求进行一下分析:
- 需要转换的股票代码数量不过两万:中、美、港、欧等主流市场的上市公司总数量大约在几万这个量级,但是不同的市场一般都要用不同的量化模型策略,同一模型所能跟踪的股票代码连同期货、期权等交易品种的数量一般不会过万,最高也不超过2万。
- 股票代码大多由4位组成,也部分如io2111-c-4900之类的长代码。
解决方案设计思路
目前如xxhash高速哈希算法的最大特点就是稳定,不管多长的字符串他都能在一个稳定的时间内转换成一个int值,但是xxhash没有充分利用如高速缓存等现代计算机体系结构中的一些优势方案。而对此由字符串转换成整形的方案其实和现代操作系统内存管理的策略相似。因此我计划借鉴内存映射的方案。从以下几方面来设计一个更高速的方案。
- 充分利用高速缓存:我们知道目前主流操作系统在进行内存地址映射时都是分级管理,而且通过MMU进行加速的。而且考虑到我们需要转换的股票代码数量上限也就是2万个左右,因此我们也需要考虑利用股票代码中的前1到2位建立上级索引,并尽量压缩这个索引的大小,使其能够被加载到L1一级高速缓存中。
- 尽量避免判断分支,这点我在之前的《为什么现代编程语言如此讨厌if-else结构》中有过阐述了,分支预测往往是性能下降的重要元凶。
解决方案及代码
1.将所有股票代码的字符串存成一个数组并做排序,数组下标就是要转换的int
2.将代码前两位做索引,记录在整体排序数组中的起止序号,如szjc的前两位sz是索引,通过map记录sz开头的所有股票代码的起止序号,从A股市场的情况看这个索引的数据大约是300多个,考虑到他每个成员是由一个两位的字符串(2byte)和一个整形(4byte)组成,一共6byte,那么6*350=2.2k,map存储的空间复杂度一般是3倍冗,2.2*3=6.6k。这个大小基本上是可以进入到L1一级缓存的。
3查找时通过前两位索引,将相应起止位置的数组成员拷贝成新的数组,这个子数组的成员一般也不会超过1000个,平均每个5个字符,那么5k大小左右的空间,调入一级L1 cache,应该也比较简单,接下来用二分查找确认序号,也就得到了对应int值。
package main
import (
"fmt"
"math/rand"
"sort"
"strings"
"time"
)
func binFind(data []string, item string) int
if len(data) == 0
return -1
i, j := 0, len(data)-1 //双指针,注意j的值为末尾下标,不是长度
for
mid := (i + j) / 2 //此处需要向下取整,Go默认。其他语言需要注意
result := strings.Compare(item, data[mid])
if result == 0
return mid
if result < 0
j = mid - 1 //注意让出边界值
else
i = mid + 1 // 注意让出边界值
if i > j //不能用i与j
break
return -1
func main()
var length int = 20000
codeGen := "abcdefghijklmnopgrstuvwxyz1234567890"
codeGroup := make([]string, length, length)
codeOrderedGroup := make([]string, length, length)
codeIndex := make(map[string]int)
for j := 0; j < length; j++
code := ""
randomLen := rand.Intn(8) + 2
for i := 0; i < randomLen; i++
random := rand.Intn(len(codeGen) - 1)
code = code + codeGen[random:random+1]
codeGroup[j] = code
codeOrderedGroup[j] = code
sort.Strings(codeOrderedGroup)
for k, v := range codeOrderedGroup
prefix := v[0:2]
index, ok := codeIndex[prefix]
if ok
codeIndex[prefix] = index&0xFFFF0000 + k
else
codeIndex[prefix] = k<<16 + k
now := time.Now().UnixNano()
//以下将随机排列数组中的字符串转换为int形的方式
for _, v := range codeGroup
prefix := v[0:2]
index := codeIndex[prefix]
startIndex := index >> 16
endIndex := index & 0x0000FFFF
subcodeGroup := codeOrderedGroup[startIndex : endIndex+1]
result := binFind(subcodeGroup, v)
//binFind(subcodeGroup, v)
fmt.Println(result+startIndex, v)
fmt.Println(time.Now().UnixNano() - now)
当然这里还有进一步地优化空间,比如实时交易数据中接收到的股票代码大多在字母顺序上比较相近,因此这个子数组的生成,二分查找可能还可以使用更加贪心的方式进行优化。
而且在高端CPU上也可以考虑用两个变量来记录子数组的起止索引,避免现在移位计算的方式,这样效率还会更高。
以上是关于量化交易中,如何快速把股票代码转换成Int整形?的主要内容,如果未能解决你的问题,请参考以下文章