风格迁移模型测试效果
Posted HenrySmale
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了风格迁移模型测试效果相关的知识,希望对你有一定的参考价值。
1 模型简介
Selfie2anime模型:动漫风格,训练集主要针对人物头像;对应论文为:U-gat-it: Unsupervised generative attentional networks with adaptive layer-instance normalization for image-to-image translation
Hayao模型:日本漫画;
Shinkai模型:日本漫画;
CartoonGan模型:tensorflow hub 开源模型:https://systemerrorwang.github.io/White-box-Cartoonization/,对应论文为:Learning to cartoonize using white-box cartoon representations
2 模型输入
Selfie2anime模型:
256
∗
256
256*256
256∗256,原始模型为4.7G,google实现版本为10.2M;
Hayao模型:
256
∗
256
256*256
256∗256;
Shinkai模型:
384
∗
384
384*384
384∗384;
CartoonGan模型:
512
∗
512
512*512
512∗512,经过量化(数据格式 float32-> unit8)后部署的模型,其模型文件大小为 2M,预测时间也最短。
3 测试结果
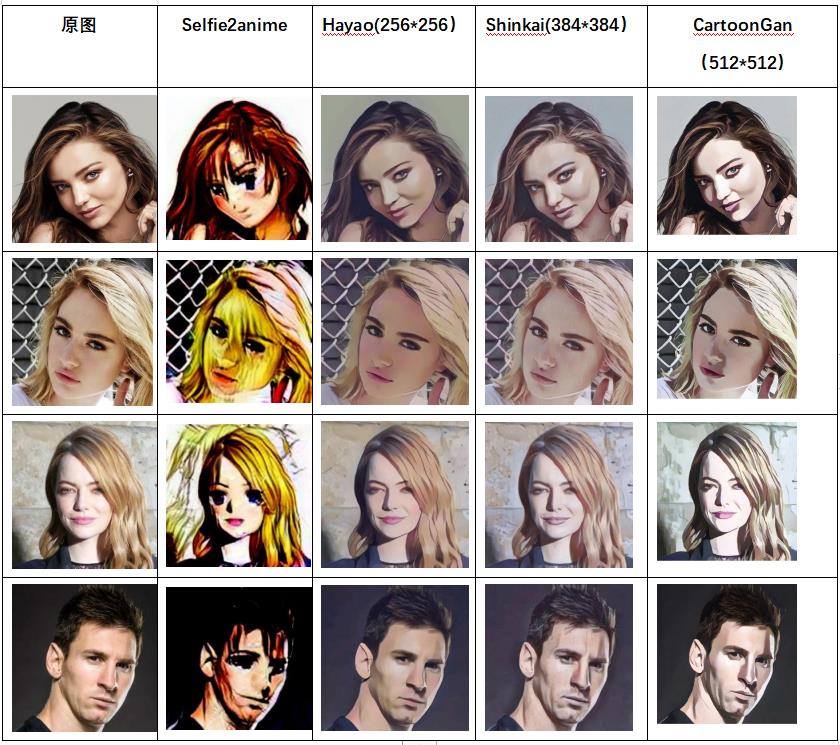
3.1 人物头像
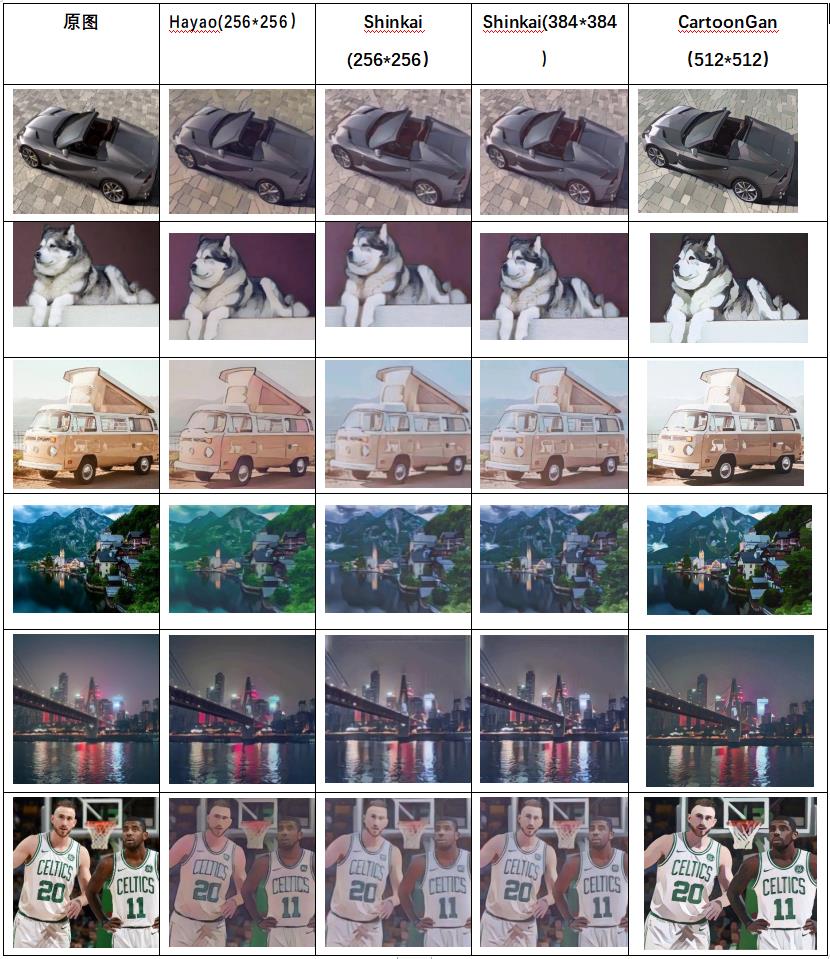
3.2 其他图像
3.3 分析
256 ∗ 256 256*256 256∗256 两种模型之间的相差并不大,差异表现在生成图片的整体颜色不同; 256 ∗ 256 256*256 256∗256 与 384 ∗ 384 384*384 384∗384 的模型之间整体差异不大,具体差异体现在细节上,例如人脸面部器官“眼睛”、“鼻子”上,在风景图片中相差并不大。
由于输入图片的长宽通常在 800 像素值以上,而网络的输入是固定的,因此在输入网络时需要将图片进行压缩、将图片缩小到目的尺寸(256 或者 384), 因此在缩小的过程中,难免会损失原图的细节信息,因此输入为 384 ∗ 384 384*384 384∗384 的模型效果理所当然会好很多。但 384 ∗ 384 384*384 384∗384 的图像同时也存在一定的弊端,即内存消耗较大。
3.4 内存分析
由于Shinkai 模型公布了网络结构,我们以这个模型为例来分析内存占用情况。Shinkai 模型中间最大的卷积层的图片通道数为 512,像素点的值为 float 类型,占用 4 个字节,因此这个卷积层占用的内存为: 384 ∗ 384 ∗ 512 ∗ 4 = 301 , 989 , 888 384*384*512*4=301,989,888 384∗384∗512∗4=301,989,888 字节,约为 302M 的内存,而 256 ∗ 256 256*256 256∗256 的图片只需要申请 134M 的内存, 600 ∗ 600 600*600 600∗600 的图片需要 737M 的内存,且在模型中包含多个卷积层,因此图片尺寸的增长会消耗更加大量的内存。
4 进一步说明
- 内存分析后可知,如果模型已经固定,增加输入图片的大小,就会增加内存空间。
- 现有的模型对接近“正方形”的图片处理效果最佳,长宽差距过大的图片则会影响生成图片的质量,因此在网络输入时,可以考虑通过设计一个裁剪框,让用户裁剪图片长宽为 1:1 的图像,最后再缩小到 384 ∗ 384 384*384 384∗384 的大小,输入网络得到结果后再放大。
- 当不得不对“长方形”的图片进行处理时,可以考虑将长方形进行切割,切割后分别进行风格迁移,将得到的结果进行拼接,返回原图像的迁移结果。
- 模型的内存与网络的卷积层结构参数有关,因此也可以从模型设计上进行改进,设计更小的网络。缺点:数据集较大,训练时间较长,对训练设备要求较高,且训练出的模型能减少内存占用量,却不能保证风格迁移的“效果” 会比现有的模型更好。
以上是关于风格迁移模型测试效果的主要内容,如果未能解决你的问题,请参考以下文章
PaddleHub--飞桨预训练模型应用工具{风格迁移模型词法分析情感分析Fine-tune API微调}
漫画风格迁移神器 AnimeGANv2:快速生成你的漫画形象
漫画风格迁移神器 AnimeGANv2:快速生成你的漫画形象