实时风格迁移原来这么酷!用PyTorch分分钟搞定
Posted 雷克世界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实时风格迁移原来这么酷!用PyTorch分分钟搞定相关的知识,希望对你有一定的参考价值。
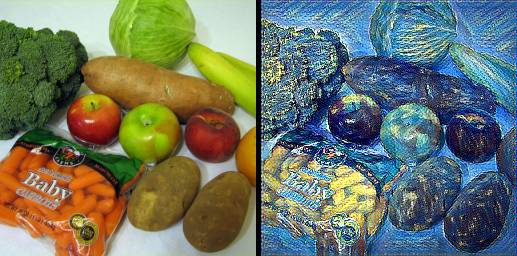
原文来源:medium
「机器人圈」编译:嗯~阿童木呀
 在这篇文章中,我将结合自身经验,简要讲解如何用编写并训练实时风格迁移模型。而这项研究主要是以为基础的,其运行效果非常完美。而我已经对它做了一些修改,一方面是为了让它变得更加有趣,另一方面是想让它能够更加适用于 Pytorch的运行环境。
在这篇文章中,我将结合自身经验,简要讲解如何用编写并训练实时风格迁移模型。而这项研究主要是以为基础的,其运行效果非常完美。而我已经对它做了一些修改,一方面是为了让它变得更加有趣,另一方面是想让它能够更加适用于 Pytorch的运行环境。
该模型使用的是以及(Instance Normalization)(未实施超分辨率)所描述那种方法。
下面就是我所添加到该模型实现中的三个主要部分:
1.使用。
2.在训练期间输入中级训练结果。
3.添加论文中所描述的(Total Variation Regularization)。
使用官方预训练的VGG模型
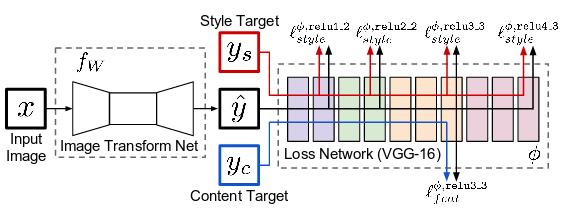
论文中的模型架构
首先,我们需要快速浏览一下该模型架构。可以说该论文的主要贡献在于,它提出将生成的图像反馈到预先训练的图像分类模型,并从一些中间层中提取输出以计算损耗,便将会产生和所得到的类似的结果,但这明显具有更少的计算资源。因此,该结构的第一部分是 “图像变换网”(Image Transform Net),它可以从输入图像中生成新的图像。而第二部分只是一个“损失网络”,即前馈部分。而损失网络的权重是固定的,在训练过程中不会更新。
Abhishek的实现使用的是具有BGR信道顺序和中心信道偏移量为[-103.939,-116.779,-123.680](它似乎也是论文中所描述使用的一种方法)的传统VGG模型。使用的是一个统一格式:
所有预训练的模型都希望以相同的方式对输入图像进行归一化,即,预先形成小批量的3通道RGB图像(形式为3 x H x W),其中,H和W的预期值至少为224。图像必须加载到[0,1]的范围内,然后使用mean = [0.485, 0.456, 0.406]和std = [0.229, 0.224, 0.225]进行规范化。
以下是从官方预训练的模型中提取输出的代码:

启动:

除非明确指定,否则VGG模型中没有批量归一化(batch normalization)。所以,相较于之前的实现,该激活函数的值有很大的不同。一般来说,你需要放大风格损失(格拉姆矩阵)(gram matrix),因为大多数激活函数值小于1,而使用点积会使其更小。
在训练期间中级结果的输出
中级阶段,第75200个训练样本
当调整内容权重与风格权重比时,将会带来很大的帮助。你可以在训练期间停止训练,重新调整参数,而不必等待4个小时当完成训练之后才开始调整。
按照本文所述添加总变差正则化
该论文在实验部分提到了这一点——总变差正则化,但是似乎Abhishek没有实现这一目标:
输出图像是通过一种强度范围在1×10e^-6和1×10^e-4之间的总变差正则化进行正则化的, 这是由对每一种风格目标进行交叉验证选择得来的。
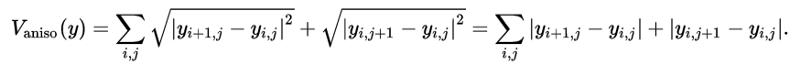
维基百科:二维信号图像的总变差正则化公式
其实这是很容易实现的:

将为你处理反向传播(backward propagation)。在实际上,我还没有找到该如何以一种较为恰当的方式来调整正则化的权重。到目前为止,我使用的权重似乎在输出图像上并没有太大差异。
训练结果
该模型使用的是Microsoft COCO数据集进行训练的。图像的大小重新调整为256 x 256,网络在大约2个时期内进行训练,批量大小为4(与论文所述相同)。使用GTX1070进行训练的时间约为4至4.5小时,与论文报告中所述的用时大致相当。基于我那稍显粗略的实验来说,其中大量的时间用来。如果我们使用原始的VGG模型(未经测试),训练可能会进行得更快。在一些手动调整之后,内容权重vs风格比通常设置为1:10e^3〜10e^5。

一个示例模型
因为网络是,你可以在测试时间内为网络提供比256 x 256更大或更小的图像。 与此同时,为了该模型更为有趣,我用和写了一些脚本来转换动画GIF和视频

在模型中使用的一些其他风格的图像

一只马赛克风格的猫在打字
经验总结
1.务必记住将输出numpy数组剪辑为[0,255]范围,并将其转换为uint8。否则,matplot.pyplot.imshow将显示奇怪的结果。结果,一开始我们还认为这是由于在模型训练代码中存在严重的错误,因此沿着这个错误思路花费了大量的时间进行纠错。
2.记住要使用model.train()和model.eval()。它只对包含dropout或批量归一化层的模型有影响,但这是一个你应该保持的好习惯。如果你之前用的是Keras,就更容易忘记这一点了。
可能的改进和未来工作规划
1.网络有时会在开放区域产生一些奇怪的补丁。我们不知道它是从哪里来的以及该如何修复。
2.也许给relu12、relu22、relu33、relu43输出配置不同的权重会带来更好的结果。
3.尝试使用不同的预训练网络作为损失网络。
4.尝试实现超分辨率(Super-Resolution)
5.将结果与进行比较。我尝试使用CycleGAN,但训练时间过于漫长,没有耐心等待,从而中止运行。应该再试一次。
6.规范化生成视频时连续帧之间的变化。这应该有助于减少播放过程中的闪烁。当然,这只是我道听途说得来的技术方法,但不知道该如何实现。

一个奇怪补丁的示例图片
代码资源
点击可获得代码资源,另外,关于代码的主要部分,存在于Jupyter notebooks中,点击链接可查看详情:和 。
欢迎加入
关注“机器人圈”后不要忘记置顶哟
↓↓↓点击阅读原文查看中国人工智能产业创新联盟手册
以上是关于实时风格迁移原来这么酷!用PyTorch分分钟搞定的主要内容,如果未能解决你的问题,请参考以下文章