华人团队开源史上最大的推荐训练系统
Posted 人工智能博士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了华人团队开源史上最大的推荐训练系统相关的知识,希望对你有一定的参考价值。
点上方人工智能算法与Python大数据获取更多干货
在右上方 ··· 设为星标 ★,第一时间获取资源
仅做学术分享,如有侵权,联系删除
转载于 :新智元
不够大!还不够大?
在NLP领域,从BERT的亿级参数,到OpenAI的1700亿参数,再到Google Switch Transformer的1.6万亿参数,研究人员对参数量增长的渴望从来没有停止过,而我等吃瓜群众对参数量也早已经麻了。

那,100000000000000够不够?不用数了,后面14个零!一百万亿!
最近来自快手和苏黎世联邦理工学院的研究人员提出了一个新的推荐系统Persia,最高支持100万亿级参数的模型训练,比目前最大的FB-ZionEX推荐系统还高出一个数量级。

论文地址:https://arxiv.org/pdf/2111.05897.pdf
开源地址:https://github.com/PersiaML/Persia
为了支持如此庞大规模模型的训练,同时保证训练效率和训练精度,文中提出了一种全新的混合训练算法:通过混合异步、同步机制对embedding层和dense层进行分别训练。
用了这套机制的推荐系统Persia(parallel recommendation training system with hybrid acceleration,即混合加速的并行推荐系统)在一百万亿级参数量的模型上进行了理论和实验验证,证实了这种设计和实现的合理性。
作者表示,使用这套机制,任何人都可以很容易训练一个百万亿级参数量的模型。(只有3060Ti可以吗?)

值得一提的是,除了2016年Alibaba-XDL和2018年Baidu-AIBox以外,其他大规模推荐系统模型都没有开源。
Persia的理论基础
在推荐系统中,深度学习模型目前也成了主流,同样遵循着「参数量大一级压死人」原则。
是不是感觉购物app、短视频app越来越容易猜到了你的想法了?
实际上,现代推荐系统取得的进展很大程度上就是来源于不断增大的模型规模,Google旗下的Youtube在2016年首次将推荐系统的模型规模推向十亿参数,从此模型参数量开始一路狂奔,Facebook(Meta)最新的模型将规模拉到12万亿,比Youtube的参数量高出12000倍!
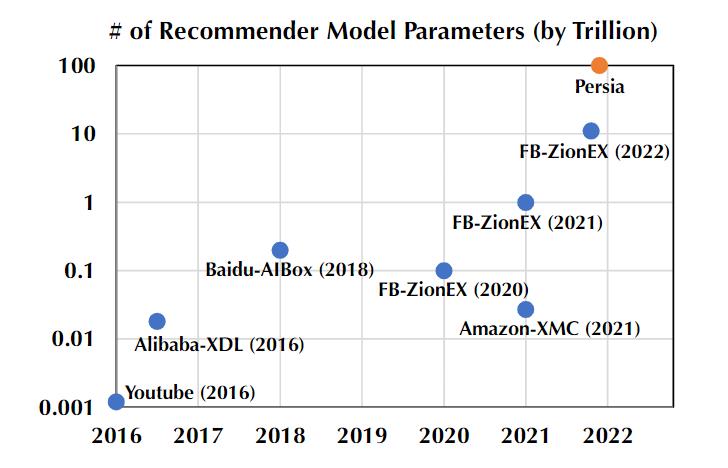
模型参数量的规模每次上一个新台阶,都能带来性能上的明显改进,所以剑指100万亿也是有实际意义的。
一般来说,推荐系统模型首先需要将不同的ID特征(如用户ID和session ID)映射到一个固定长度的低维向量,而系统中的用户ID、交叉特征数量都特别多,就需要更大规模的模型来捕获特征和映射。但更大规模的embedding layer也需要更大的内存来载入,不得不说大模型太费钱了!
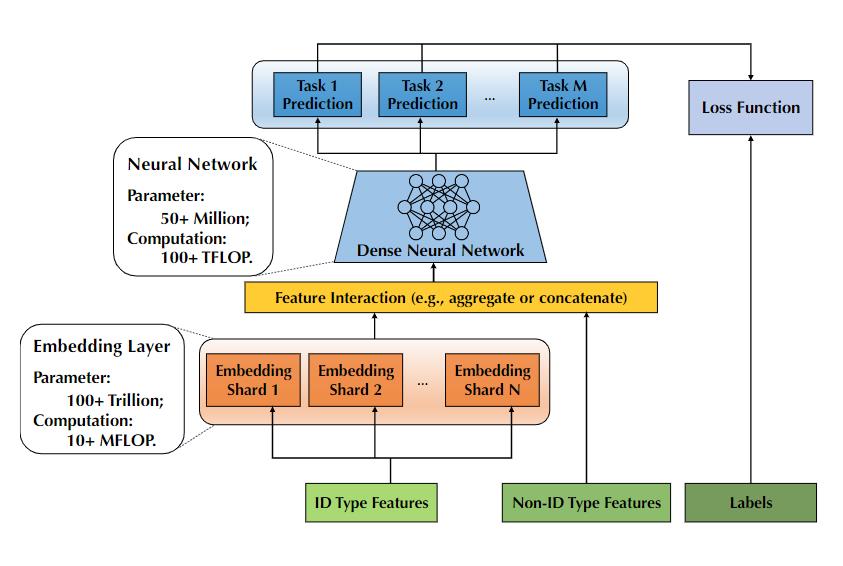
有了embedding后,剩下的工作就简单了,设计后续layer来适配不同的任务。通常只占据整个模型的0.1%,无需大内存,主要是一些计算密集型的工作。
虽然性能好了,但随着模型规模的不断扩大,模型的训练也是越来越难!

而想要训练好一个推荐系统,主要看这5个关键步骤:
准备训练样例的embedding
神经网络的前向传播(forward propagation)
神经网络的反向传播(backward propagation)
神经网络参数需要同步更新(Synchronization)
根据相应的梯度对embedding进行更新
由于embedding层和推荐任务是相关联的,所以上述五个任务必须顺序执行,而这种串行机制也导致了模型训练的硬件效率很低。
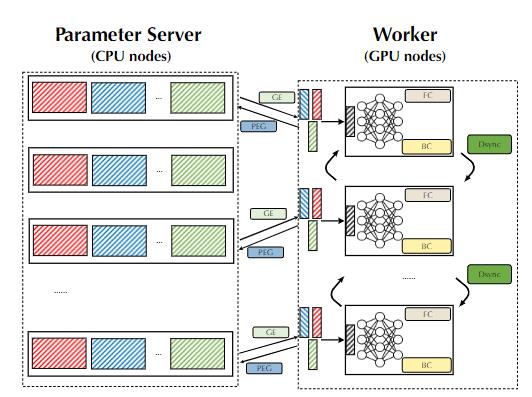
如果不严格顺序执行这五步,而是采用异步分布式训练(Asynchronous distributed training)方式的话,就能显著提升训练速度。
目前业界对神经网络的异步分布式训练主要有两个观察结论:
异步更新(Asynchronous update)对于稀疏访问(sparse access)来说是有效的。例如SGD每次更新只会影响到模型参数的一小部分,所以就算并行SGD优化,参数覆盖(overwrite)情况也是很少见的,几乎对模型不会产生影响。
滞后性(staleness)限制了异步SGD的可扩展性和收敛。对于稠密的(dense)的神经网络,SGD覆盖更新的情况下可能会非常多,对模型的最终效果有影响。
在不考虑模型结构的时候,肯定全异步的硬件效率最高,但在实际情况中,全异步优化会降低模型的性能,对于商用推荐模型来说是不能接受的,所以「同步、异步两手抓」才是最终解决方案!

文中提出的混合训练算法(Hybrid training)对模型的embedding层和dense层分别使用不同的优化机制来提升硬件效率。
因为embedding层更大、更稀疏,采用异步训练的方式。
而dense层更稠密,就采用同步训练的方式。
有了思路,下一步就是系统实现了!
Persia实现细节
Persia系统的设计上主要有两个难点:
在异构集群上部署训练工作流(training workflow)
在混合基础架构上部署对应的训练过程(training procedure)
对于第一个难题,研究人员为了支持基于深度学习的推荐模型的分布式训练,就直接使用了Tensforflow框架提供的PS范式,同时将embedding和神经网络参数的存储和更新放在一组PS节点(即CPU机器)中,将前向和后向传播的计算放在一组工作节点(即GPU机器)中。
但只使用这种方式还远远不够高效,甚至在实际情况中可能根本没法完成部署。

例如推荐模型太大,GPU的RAM很容易就不够用了,而且将embedding和神经网络模块进行统一视图管理可能还会引入大量不必要的网络流量。
虽然之前的研究也提出过一些PS范式优化、带缓存的colocated PS framework来减少通信开销等等,但这些方法根本无法支撑百万亿级模型的训练。

Persia的研究人员分解出4大模块来解决这个问题:
使用一个data loader专门从分布式的存储如Hadoop, Kafka中取训练数据;
专门建立一个embedding参数服务器(PS)来管理embedding层参数的存储和更新;
使用一组embedding workers运行优化算法从embedding PS中获取参数更新;并把embedding向量聚合后放回到embedding PS中;
使用一组NN workers运行dense神经网络的前向和反向传播。
还没完!上面还提到了第二个难点就是分布式的训练过程,研究人员又来了一个「七步走」解决了这个难题:
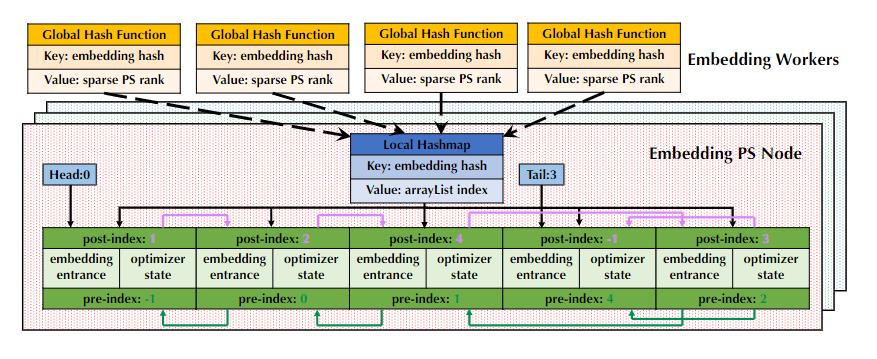
data loader会对ID类型特征进行调度分配给embedding worker,然后embedding worker会生成一个独一无二的训练样例,将样例的ID在本地缓存起来后返回给data loader,最后data loader会将该样例的Non-ID类型特征和标签与生成的ID绑定起来;
data loader会把这个Non-ID类型特征和标签分配给一个NN worker;
NN worker接收到不完整的训练样例后,会发起一个请求从embedding worker处pull回ID类型特征的embedding,同时进行前向传播;
embedding worker会对原始的embedding向量进行一些potential aggregation,然后将聚合后的向量发起pull request传送给NN worker;
上面四步完成后,NN网络就成功接收到一组完整的输入了,然后建立mini-batch进行训练。此时计算的参数结果都是放在内存中的,NN网络后续会采用AllReduce范式对梯度进行同步;
NN worker将计算好的梯度送回到embedding worker;
embedding worker根据样例ID找到缓存的ID类型特征,然后计算embedding参数的梯度,并将梯度送回到embedding PS中。至此完成全部参数的更新。

最后的训练结果也可以看到,Persia的训练速度相比其他大规模模型来说要快了很多,从而能够支撑百万亿级模型的训练。
参考资料:
https://arxiv.org/pdf/2111.05897.pdf
---------♥---------
声明:本内容来源网络,版权属于原作者
图片来源网络,不代表本公众号立场。如有侵权,联系删除
AI博士私人微信,还有少量空位


点个在看支持一下吧

以上是关于华人团队开源史上最大的推荐训练系统的主要内容,如果未能解决你的问题,请参考以下文章
「AMD史上最大芯片」炸场CES:1460亿晶体管,可大幅压缩ChatGPT训练时间