支持Python 3.10,OpenAI强化学习工具包Gym迎来史上最大更新
Posted 机器之心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了支持Python 3.10,OpenAI强化学习工具包Gym迎来史上最大更新相关的知识,希望对你有一定的参考价值。
机器之心报道
编辑:杜伟
你在用了吗?
env.reset 接受 3 个新的参数(options - 对于无再次初始化环境时控制课程学习等操作有用;seed - 未来环境 seed 可以传递到 reset 参数。老的 .seed() 方法被弃用,但考虑到向后兼容,该方法在 Gym 1.0 发布之前仍继续如常工作;infos - 当设置为 True,reset 将返回 obs, info。当前这种做法默认为 False,但将变成 Gym 1.0 版本的默认行为);
环境名称在注册期间不再需要一个版本,并将智能推荐类似名称;
Vector 环境支持 info 中的 terminal_observation 并支持批处理操作空间。
blackjack 和 frozen lake 示例环境现在使用 PyGame 进行了更好的图形渲染;
机器人环境已移动到 gym-robotics 包中;
bipedal walker 和 lunar lander 环境现在被合并称为一类;
Atari 环境现在使用标准种子 API 了;
修复了 car_racing box2d 环境中的大错误修复,碰撞版本;
重构了所有 box2d 和 classic_control 环境,以使用 PyGame 而不是 Pyglet。因为 pyglet 的问题一直是 gym 项目生命周期中最常见的 GitHub 问题来源之一。
移除 DiscreteEnv 类,内置环境将不再使用;
增加了大数类型提示;
支持 Python 3.10 版;
大量额外的代码重构、清理、错误消息改进和小错误修复;
所有环境文件的描述文件现在都有了明显改进。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
SourceInsight 支持 Python
SourceInsight 支持 Python
步骤一:下载相关的插件
Python.CLF插件
链接如下:
Python.CLF|Python.CLF下载_红软基地
http://www.rsdown.cn/down/166540.html#download
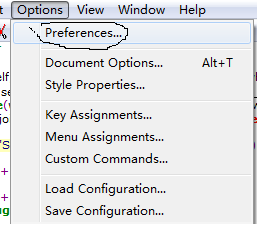
步骤二:
导入插件,在下面的 import 中选中下载好的Python.CLF;
导入成功后,左侧会出现一个 Pyhon Language,前面的红色叉不用管
![]() ?
?
![]() ?
?
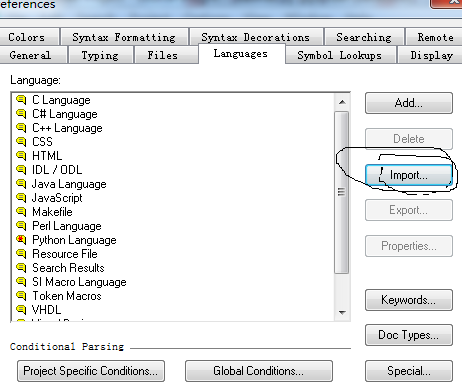
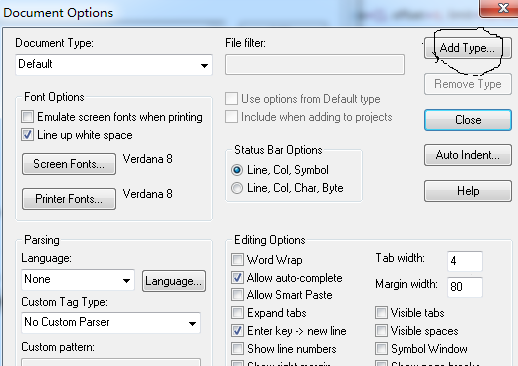
步骤三:
选中左侧的 Pyhon Language,添加类型
![]() ?
?
![]() ?
?
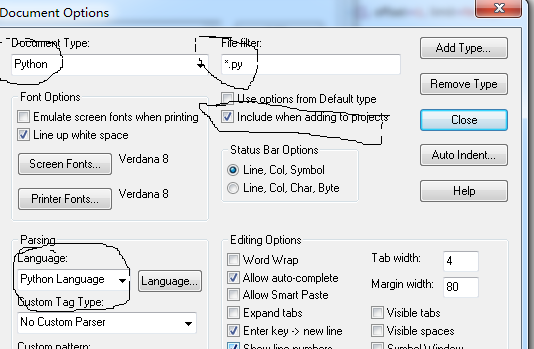
步骤四:
点击 Close 退出,即安装成功。
参考资料:
使SourceInsight支持Python语言的方法 - serapme的专栏 - CSDN博客
https://blog.csdn.net/serapme/article/details/46671387
以上是关于支持Python 3.10,OpenAI强化学习工具包Gym迎来史上最大更新的主要内容,如果未能解决你的问题,请参考以下文章