Python爬虫:微博评论数据分析
Posted 尤尔小屋的猫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫:微博评论数据分析相关的知识,希望对你有一定的参考价值。
公众号:尤而小屋
作者:Peter
编辑:Peter
大家好,我是Peter~
最近王和李的离婚闹得沸沸扬扬,相信大伙们都已经吃了不少的瓜。本文结合李的第一篇文章发文下面的网友们的评论来看看大家到底怎么看待这件事。
网页
爬取字段
- 用户昵称
- 评论时间
- 评论内容
- 点赞数
- 回复数
- 性别
- 城市
数据来自该地址:https://weibo.com/5977512966/L6w2sfDXb#comment

爬取的下面的全部评论:
网页规律
微博的网页属于Ajax渲染,当我们向下滑动的时候会显示的评论,地址栏的URL不变,需要找到实际的请求URL。
1、右击【检查】,找到【Network】
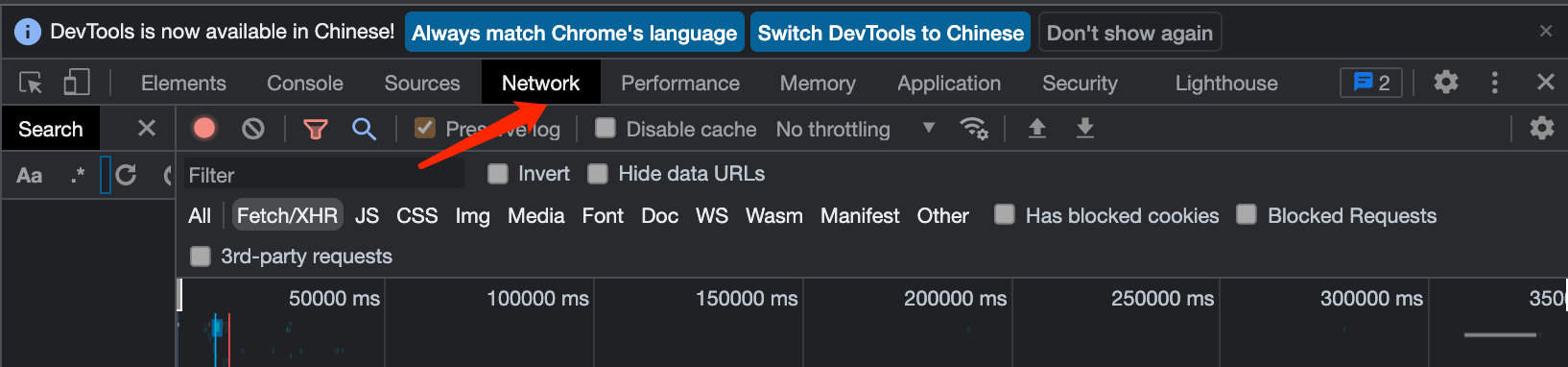
2、确定每页的内容URL
这里是首页部分
滑动之后显示每页内容的URL;
3、每页的URL地址
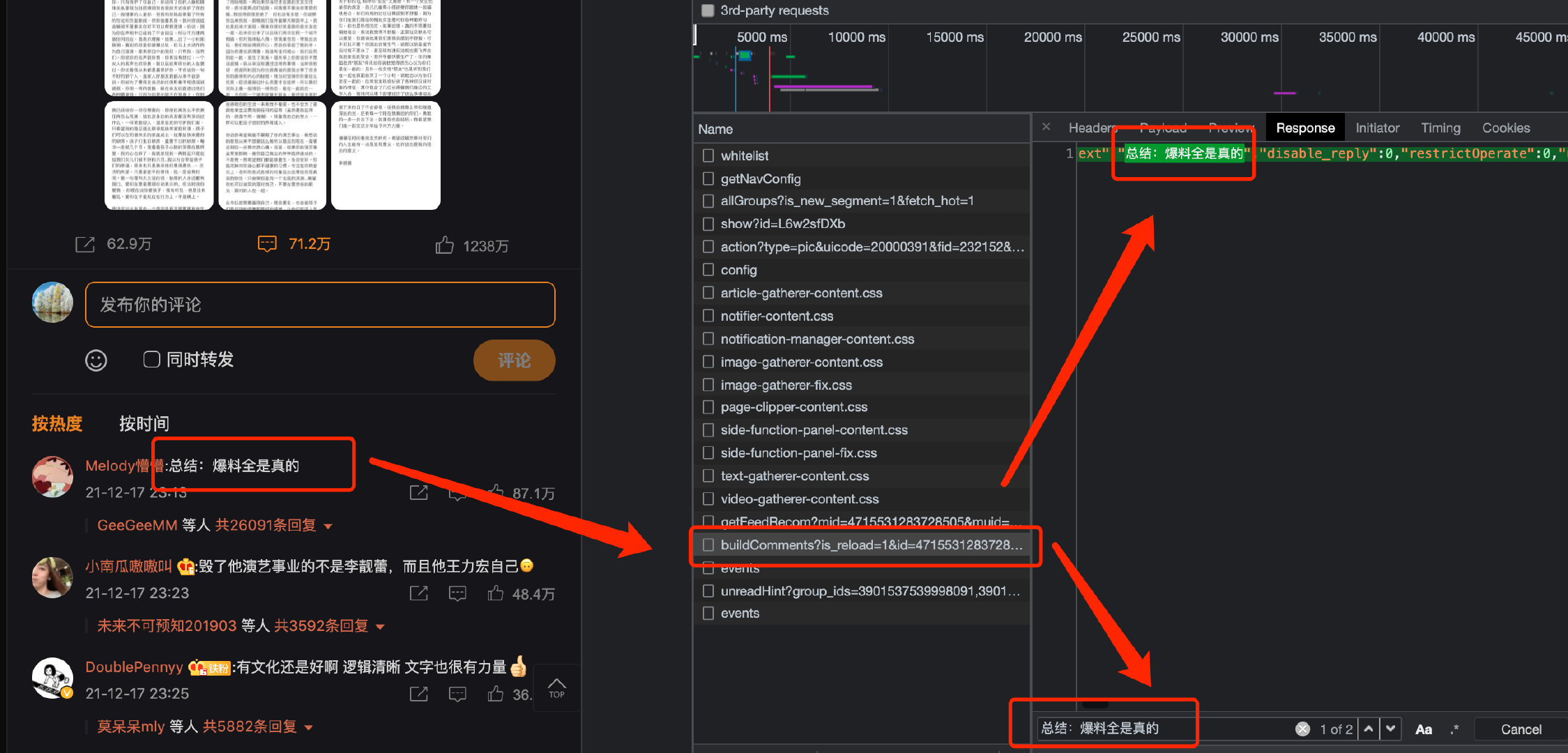
start_url = "https://weibo.com/ajax/statuses/buildComments?is_reload=1&id=4715531283728505&is_show_bulletin=2&is_mix=0&count=10&uid=5977512966"
# 2:用第一页返回的max_id作为参数的取值
url2 = "https://weibo.com/ajax/statuses/buildComments?flow=0&is_reload=1&id=4715531283728505&is_show_bulletin=2&is_mix=0&max_id=22426369418746150&count=20&uid=5977512966"
# 3:用第二页返回的max_id作为参数的取值
url3 = "https://weibo.com/ajax/statuses/buildComments?flow=0&is_reload=1&id=4715531283728505&is_show_bulletin=2&is_mix=0&max_id=2197966808100516&count=20&uid=5977512966"
从第二页开始的URL地址多的部分是max_id,刚好这个参数的值是前一页的返回内容:
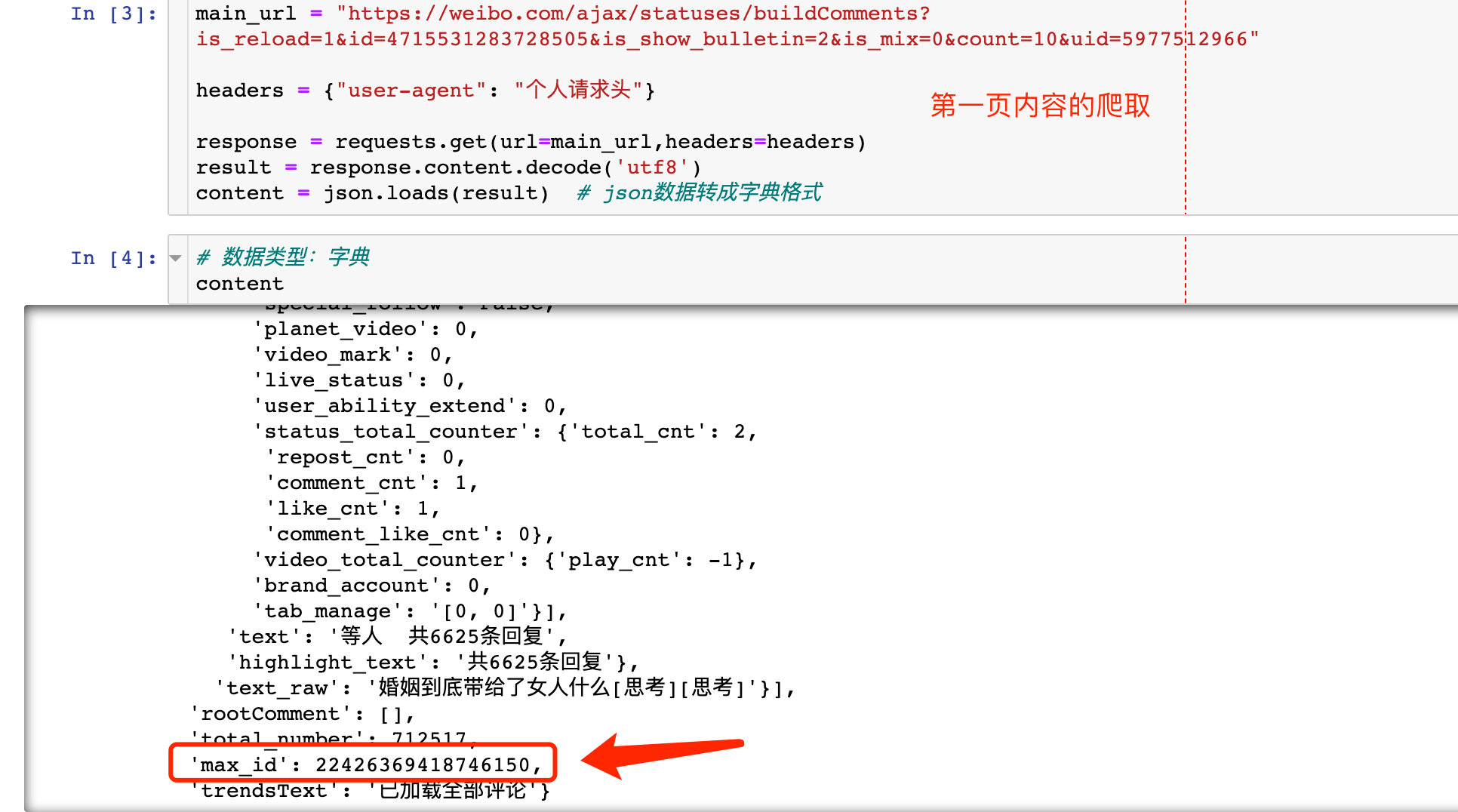
4、介绍第一页的爬取
main_url = "https://weibo.com/ajax/statuses/buildComments?is_reload=1&id=4715531283728505&is_show_bulletin=2&is_mix=0&count=10&uid=5977512966"
headers = "user-agent": "个人请求头"
response = requests.get(url=main_url,headers=headers)
result = response.content.decode('utf8')
content = json.loads(result) # json数据转成字典格式
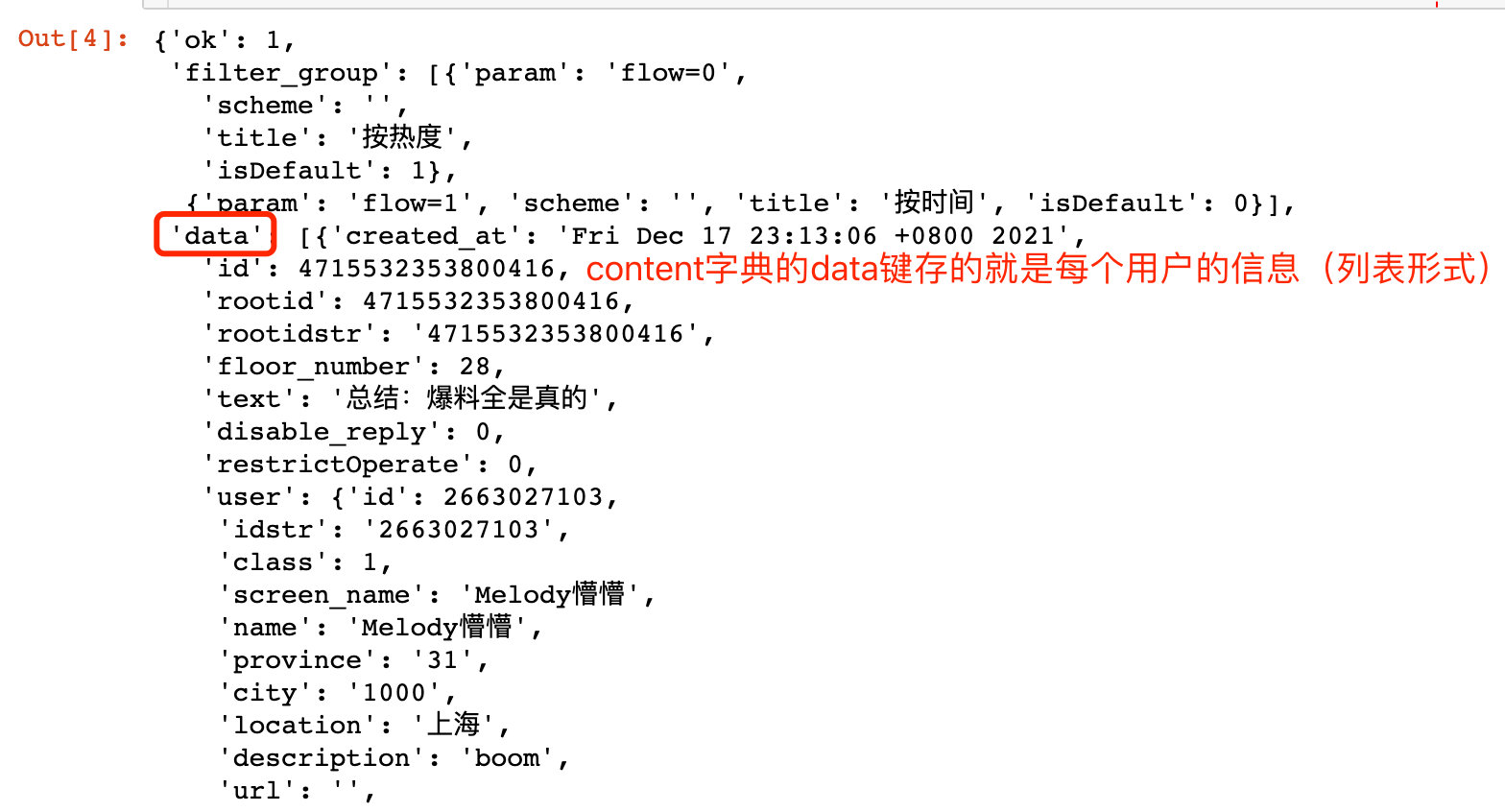
比如我们可以获取第一个用户的相关信息:
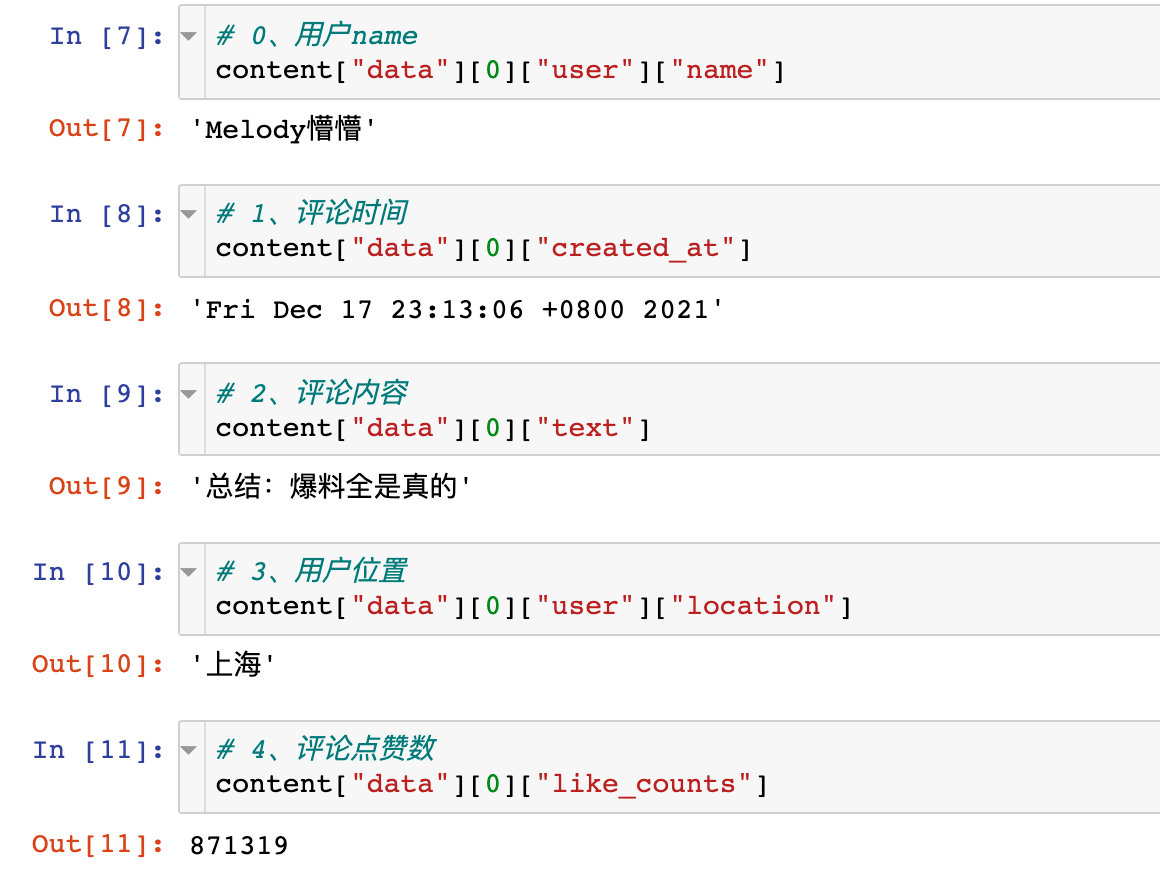
最终我们可以看到第一页爬取的数据展示:
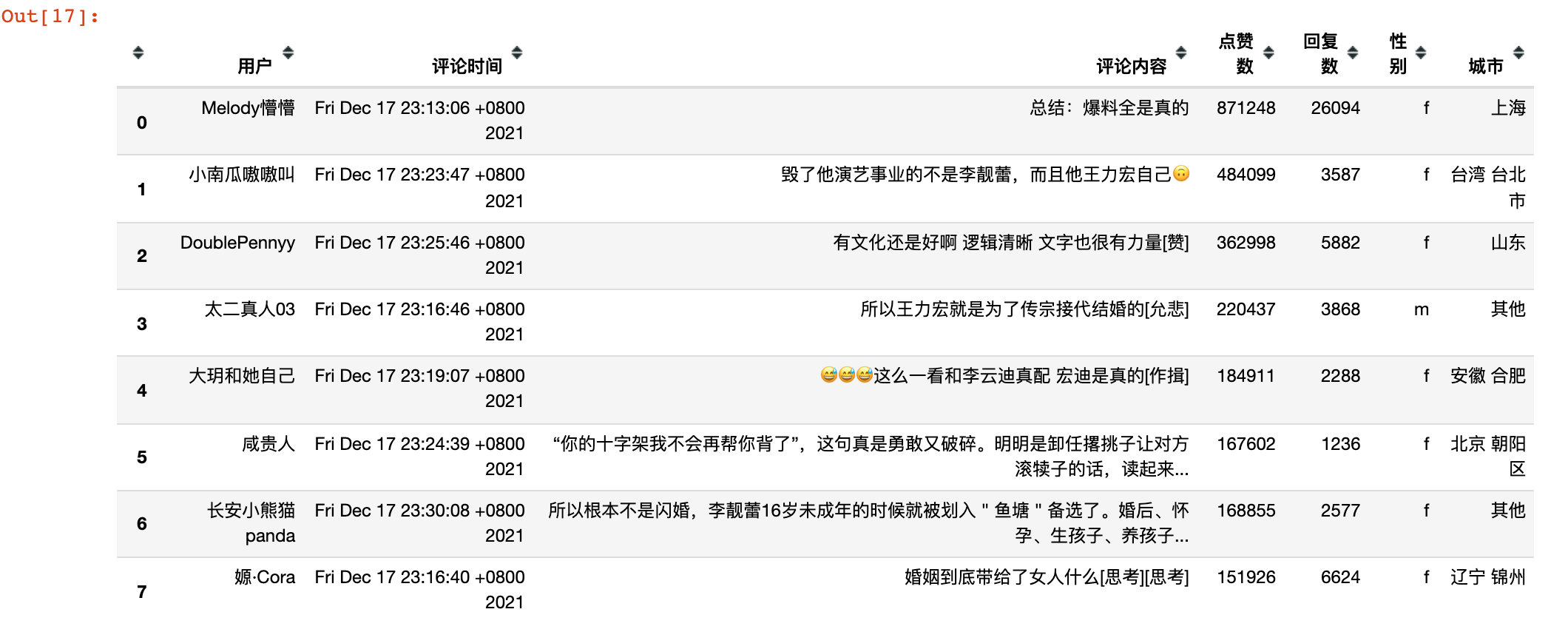
参考上面的逻辑可以爬取到微博下面的全部评论
微博分析
导入库
导入需要的库:
import pandas as pd
import numpy as np
import jieba
from snownlp import SnowNLP
# 显示所有列
# pd.set_option('display.max_columns', None)
# 显示所有行
# pd.set_option('display.max_rows', None)
# 设置value的显示长度为100,默认为50
# pd.set_option('max_colwidth',100)
# 绘图相关
import matplotlib.pyplot as plt
from pyecharts.globals import CurrentConfig, OnlineHostType
from pyecharts import options as opts # 配置项
from pyecharts.charts import Bar, Scatter, Pie, Line,Map, WordCloud, Grid, Page # 各个图形的类
from pyecharts.commons.utils import JsCode
from pyecharts.globals import ThemeType,SymbolType
import plotly.express as px
import plotly.graph_objects as go
from plotly.subplots import make_subplots # 画子图
数据EDA
查看我们爬取到数据的基本信息,我们导入前5行数据:
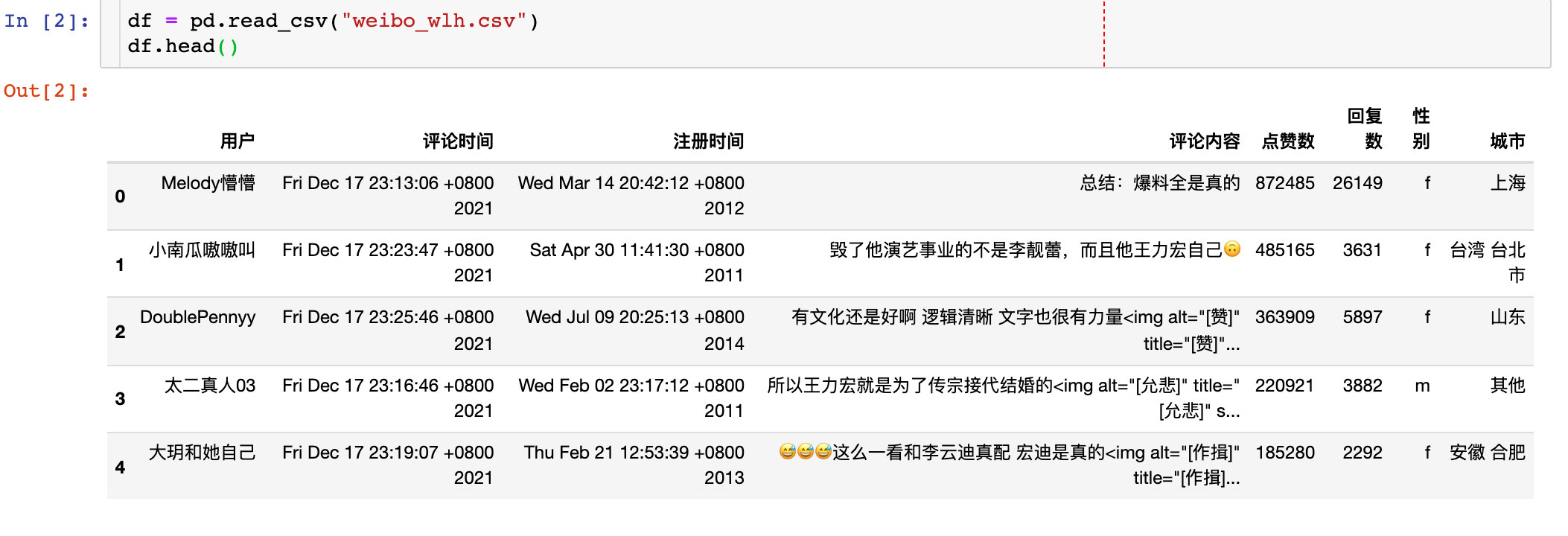
基本信息:查看数据的shape形状,总共是47638行,8个字段,并且不存在缺失值。

时间预处理
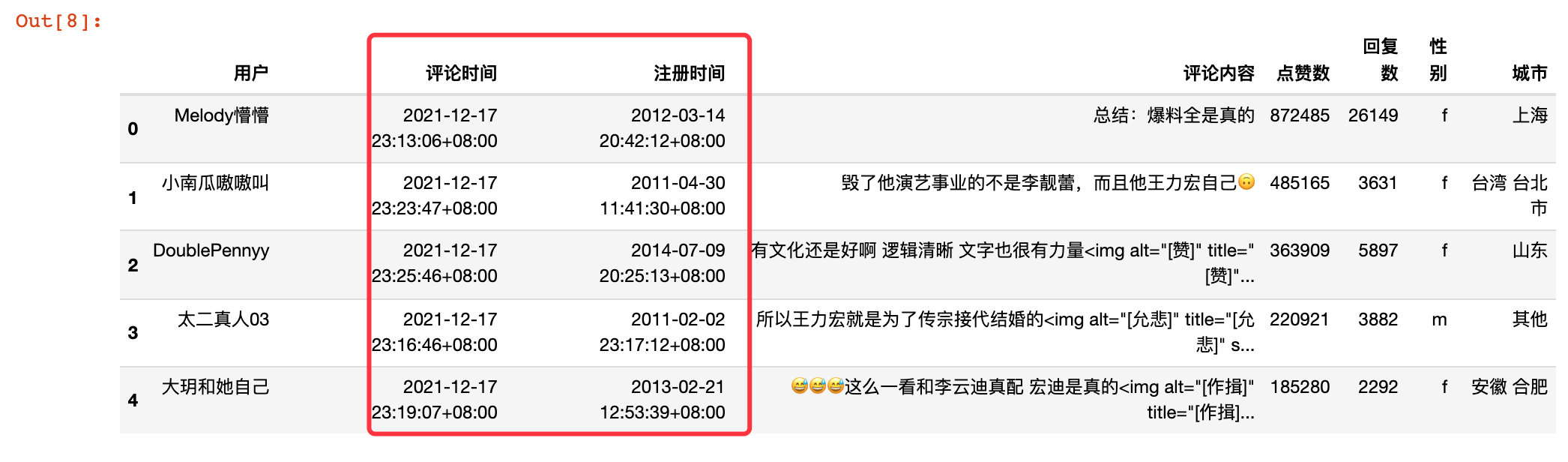
将我们爬取到的格林威治形式的时间转成熟悉的标准化时间形式:
import datetime
def change_time(x):
"""
格林威治时间格式----->指定的时间格式
"""
std_transfer = '%a %b %d %H:%M:%S %z %Y'
std_change_time = datetime.datetime.strptime(x, std_transfer)
return std_change_time
df["评论时间"] = df["评论时间"].apply(change_time)
df["注册时间"] = df["注册时间"].apply(change_time)
df.head()
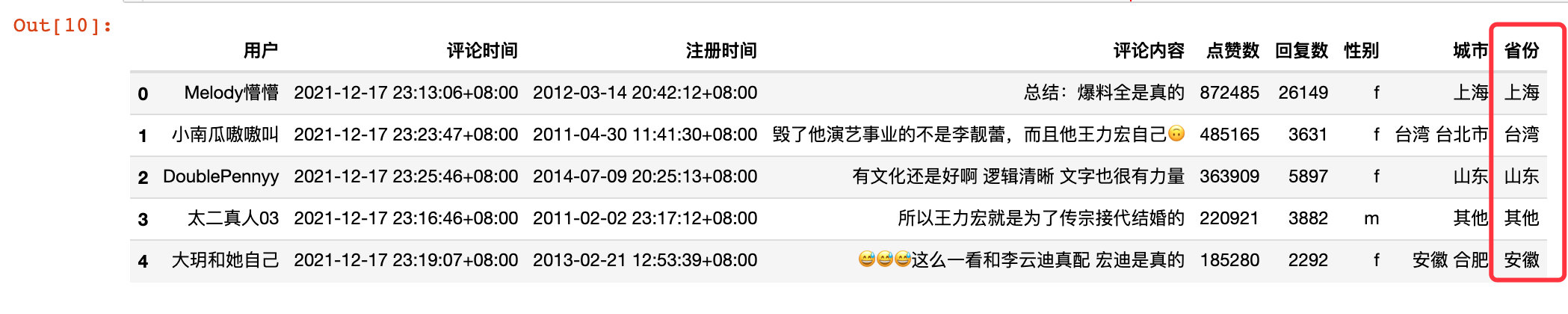
其他处理
- 将评论中的img部分去掉
- 对于爬取的城市我们提取其中的省份或者直辖市,如果是国外直接取值为:海外
df["评论内容"] = df["评论内容"].apply(lambda x:x.split("<img")[0])
df["省份"] = df["城市"].apply(lambda x:x.split(" ")[0])
df.head()
地区吃瓜大比拼
fig = px.bar(df1[::-1],
x="用户",
y="省份",
text="用户",
color="用户",
orientation="h"
)
fig.update_traces(textposition="outside")
fig.update_layout(title="微博评论城市人数分布",width=800,height=600)
fig.show()
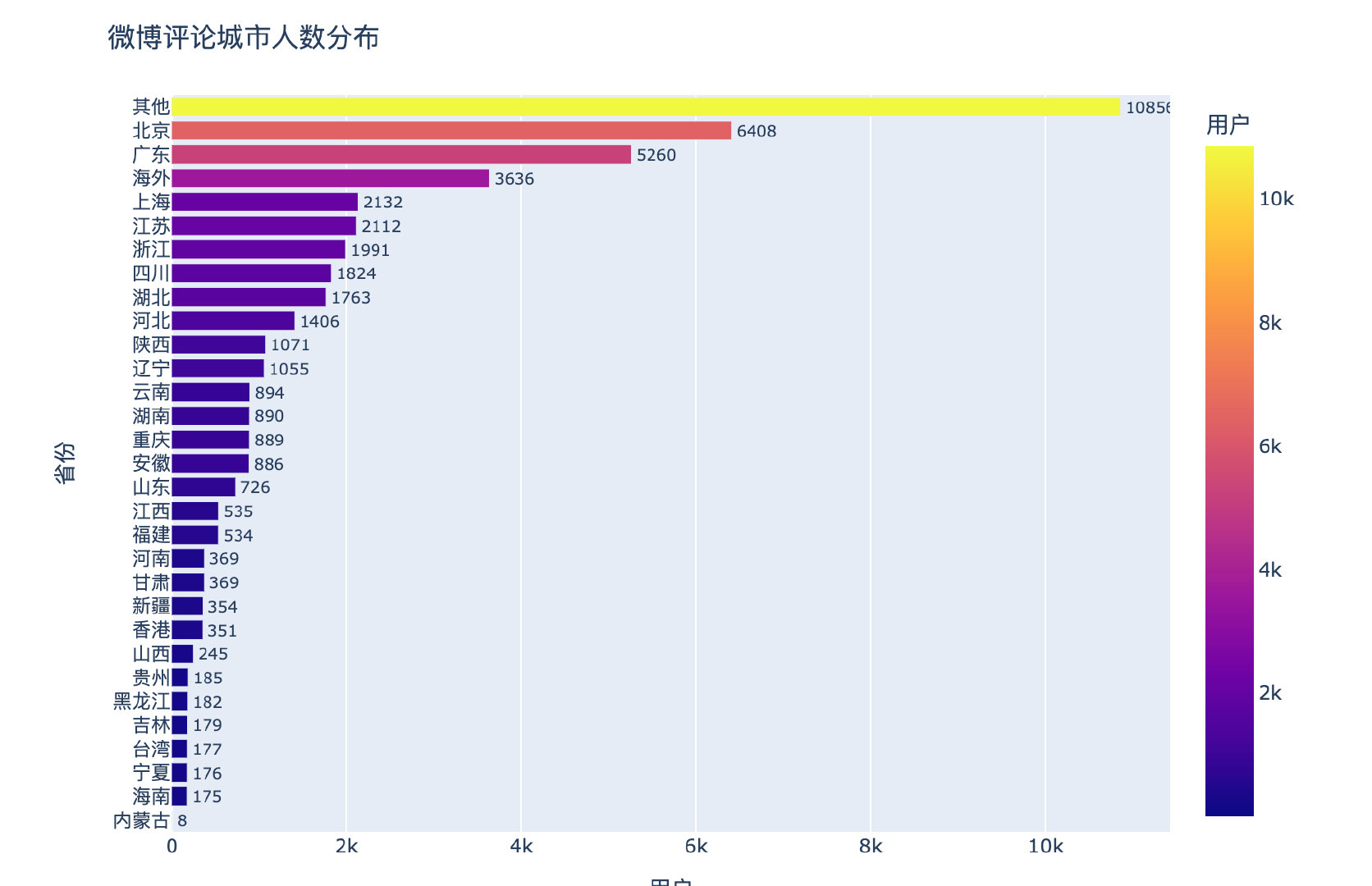
国内的省份中北京、广东、上海、江苏都是吃瓜的大省份!
性别大比拼
df2 = df.groupby("性别")["用户"].count().reset_index()
fig = px.pie(df2,names="性别",values="用户",labels="性别")
fig.update_traces(
# 文本显示位置:['inside', 'outside', 'auto', 'none']
textposition='inside',
textinfo='percent+label'
)
fig.show()
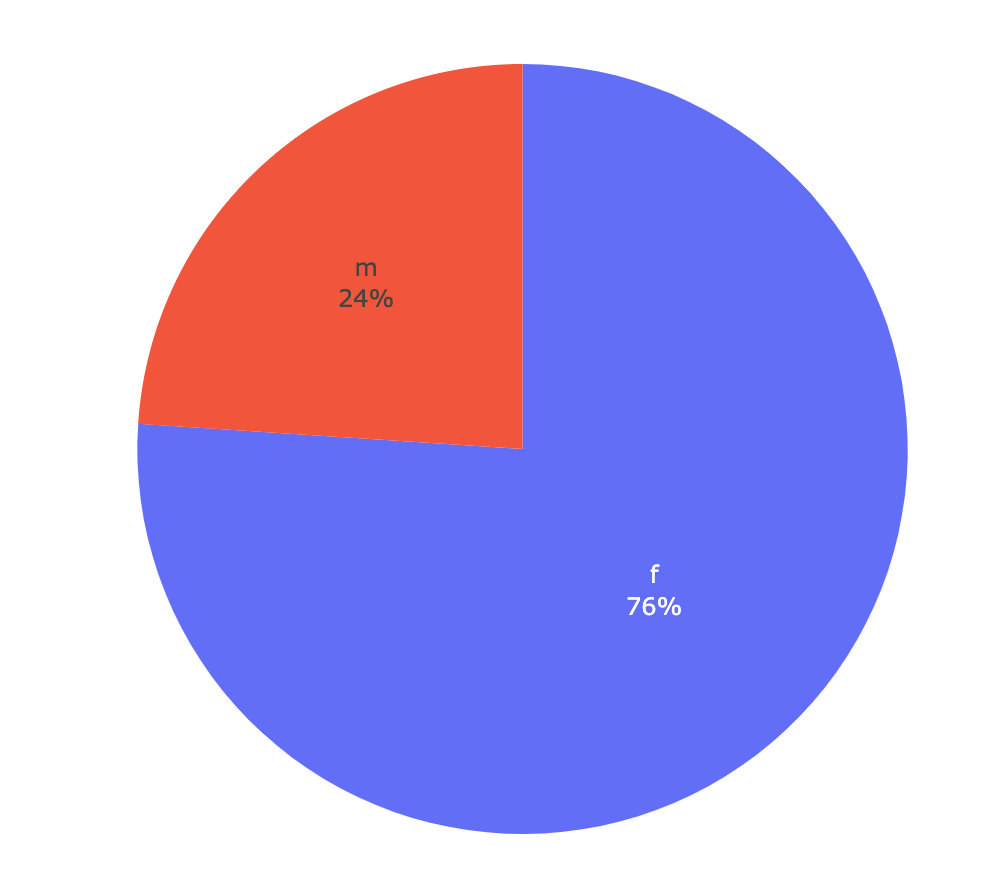
果然:女性真的很爱吃瓜🍉远超男性
火爆评论
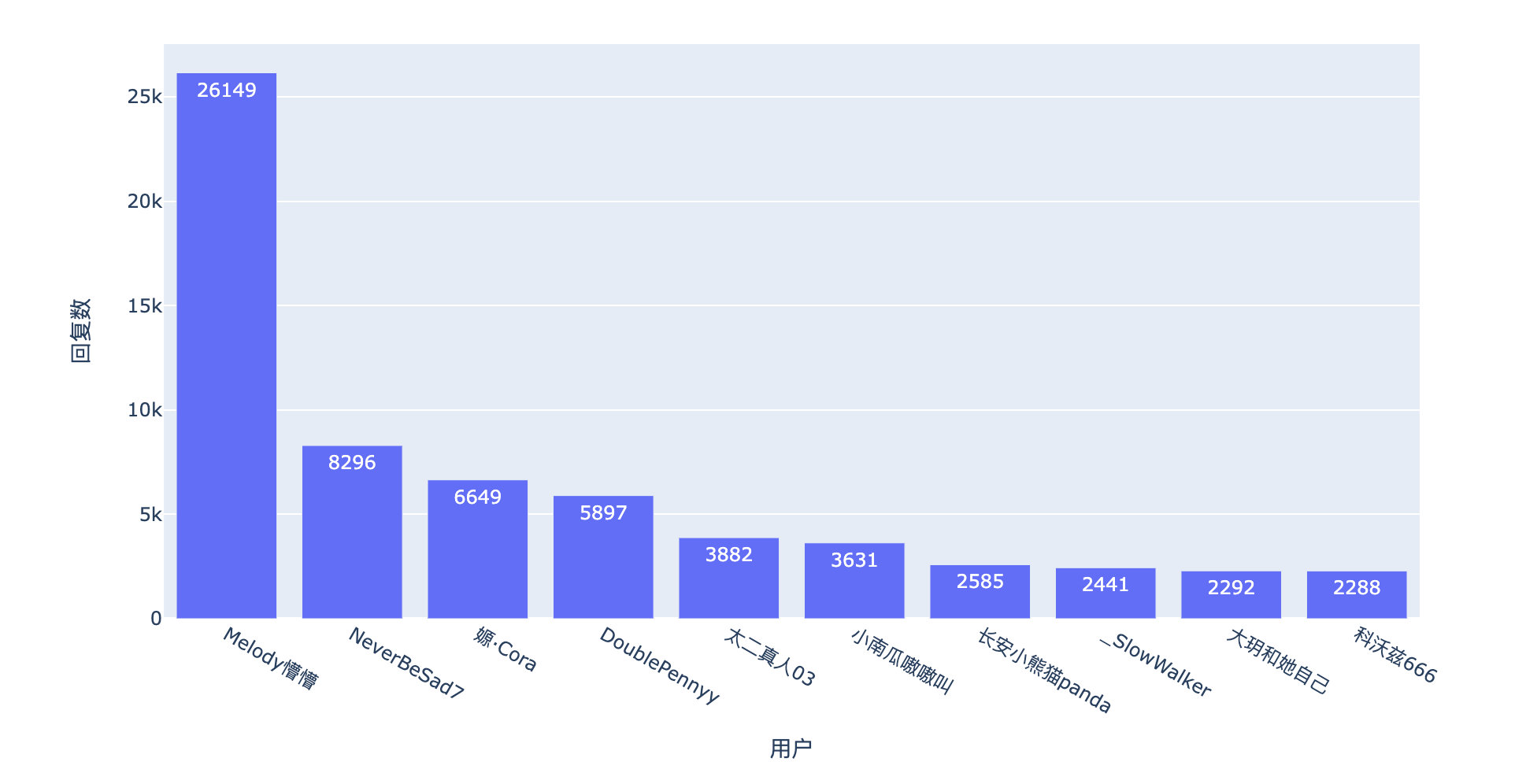
通过点赞数和回复数来看看这篇微博下的火爆评论:
点赞数
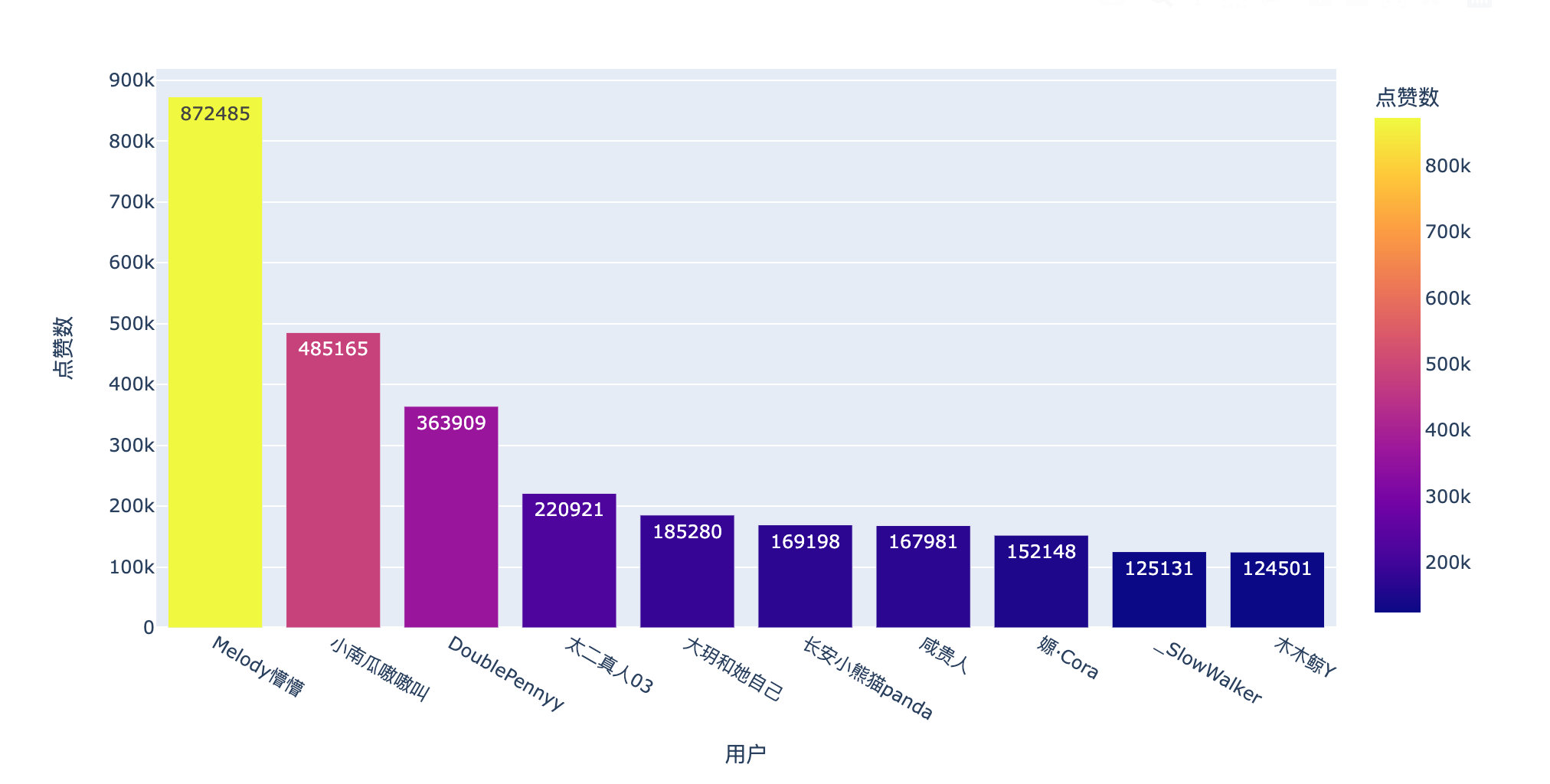
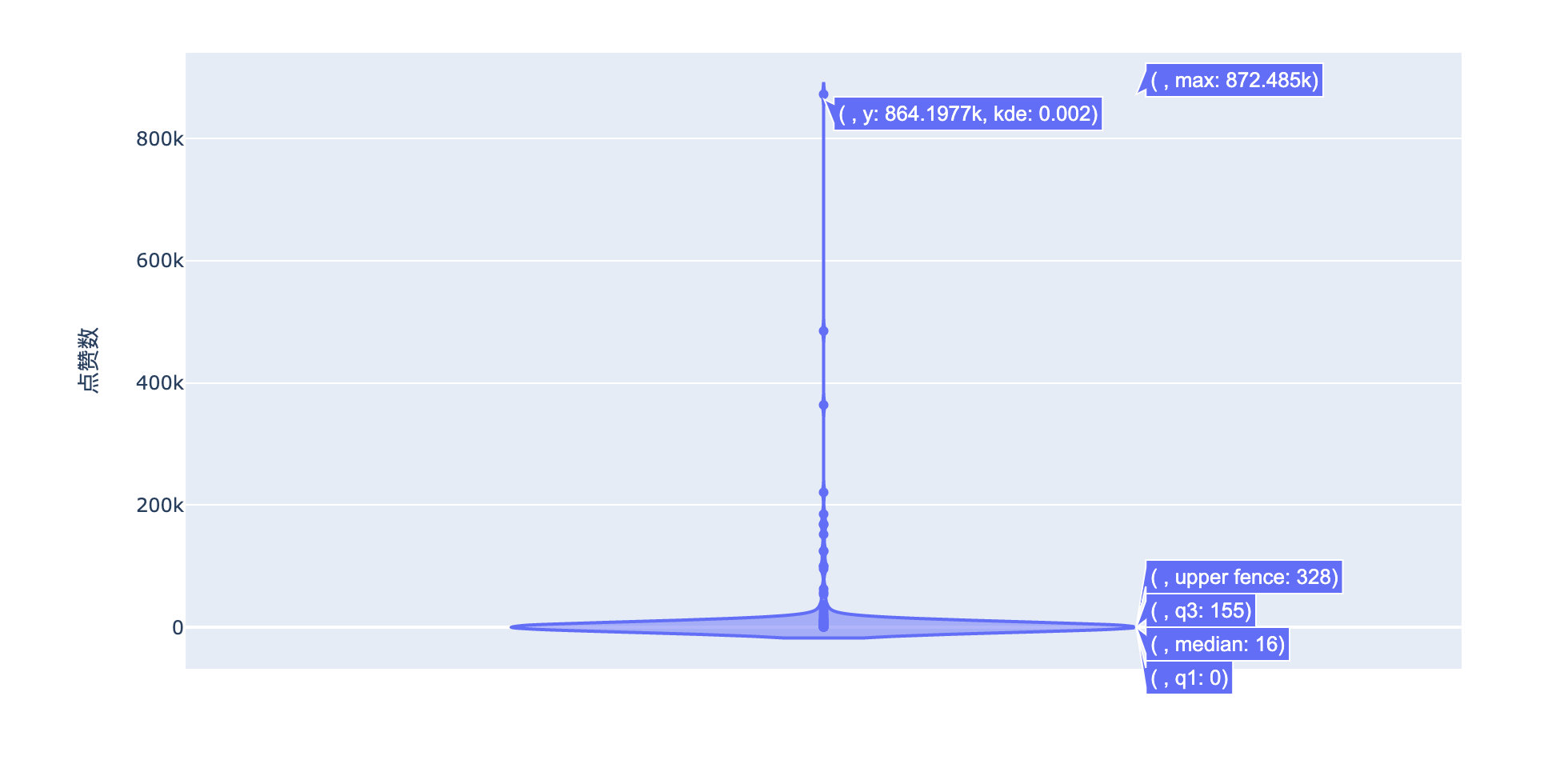
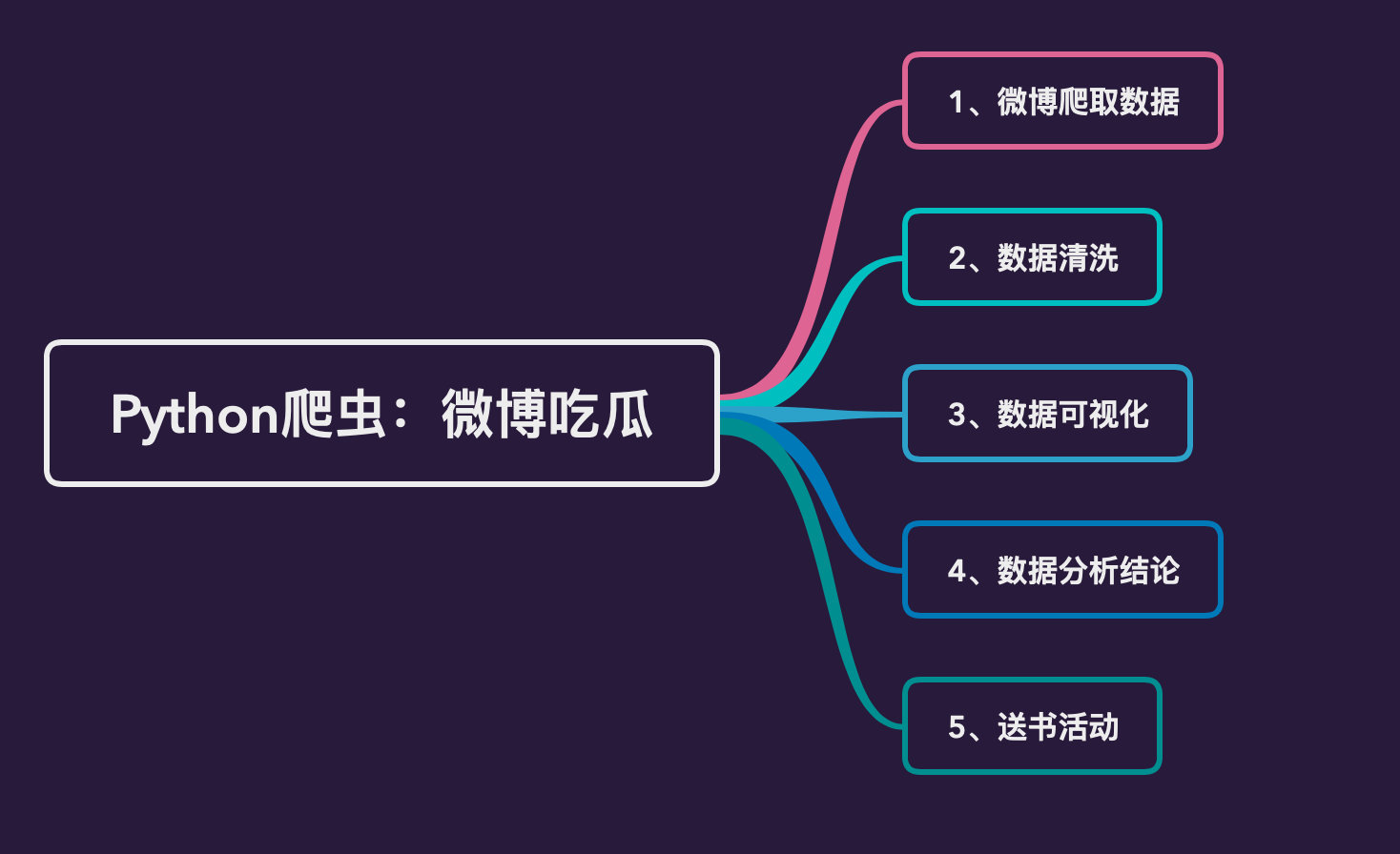
有位网友的评论87万+的点赞数!666
回复数
同样还是这位网友的评论,回复数也是No.1
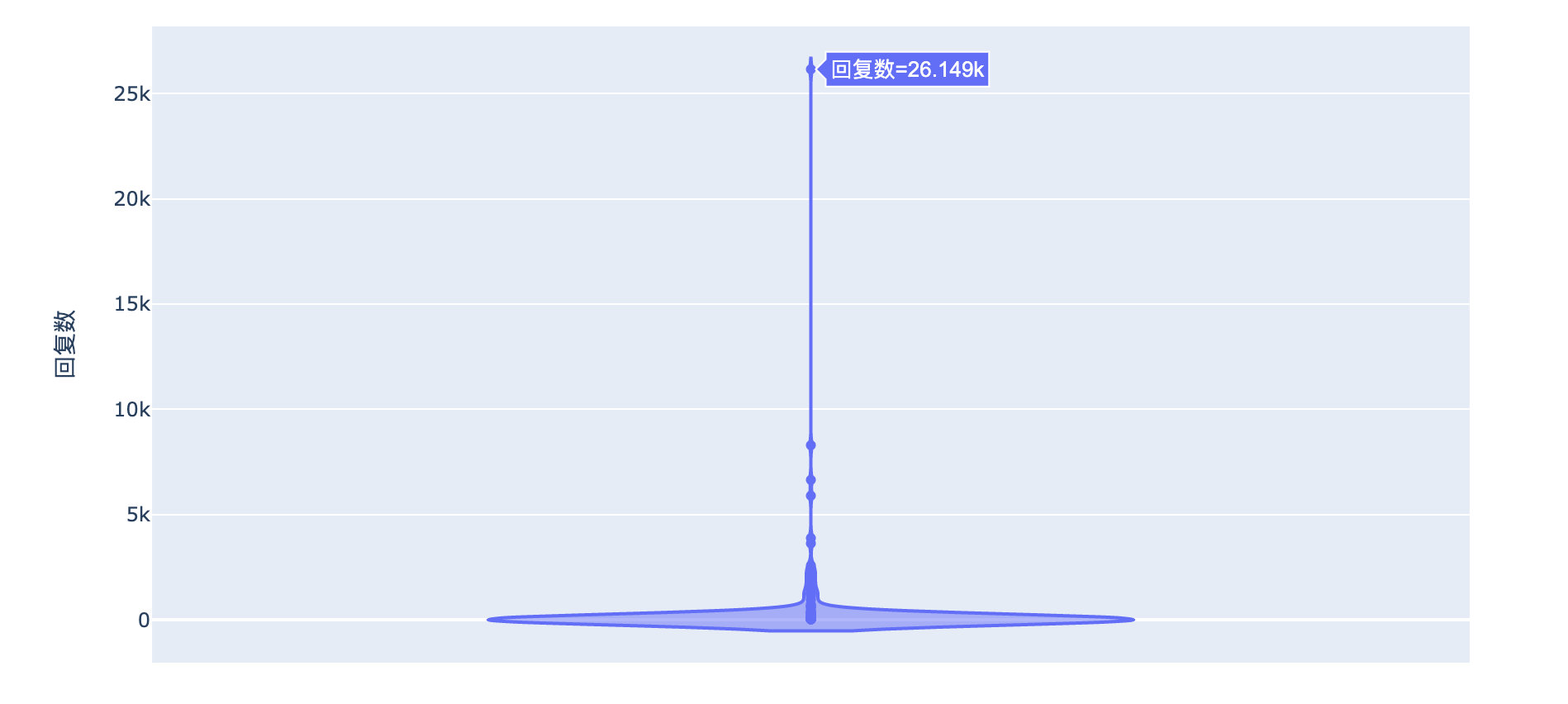
从点赞数和回复数的整体分布来看,这条评论真的是别树一帜!已经完全偏离了其他的数据:
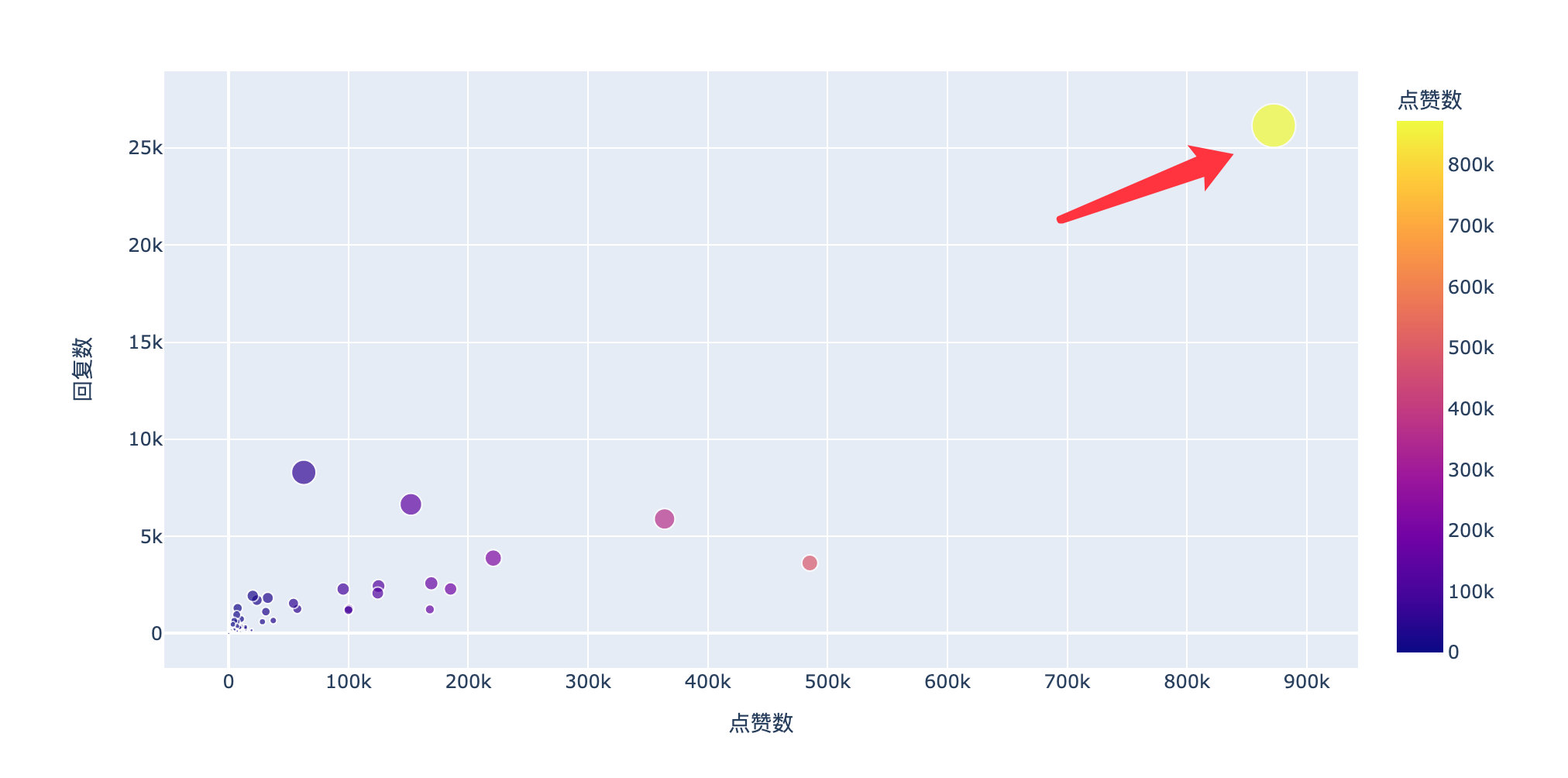
查看原数据我们发现这条评论就是:
总结:爆料全是真的
看来以前的很多爆料都被锤啦!
微博用户年龄
df["间隔"] = df["评论时间"] - df["注册时间"] # 时间间隔
df["天"] = df["间隔"].apply(lambda x:x.days) # timedelta的days属性
df["年"] = df["天"].apply(lambda x:str(int( x / 365)) + "年") # 微博年龄取整;不足一年去掉
px.scatter(df,
x="点赞数",
y="回复数",
size="天",
facet_col="年",
facet_col_wrap=4, # 每行最多4个图形
color="年")
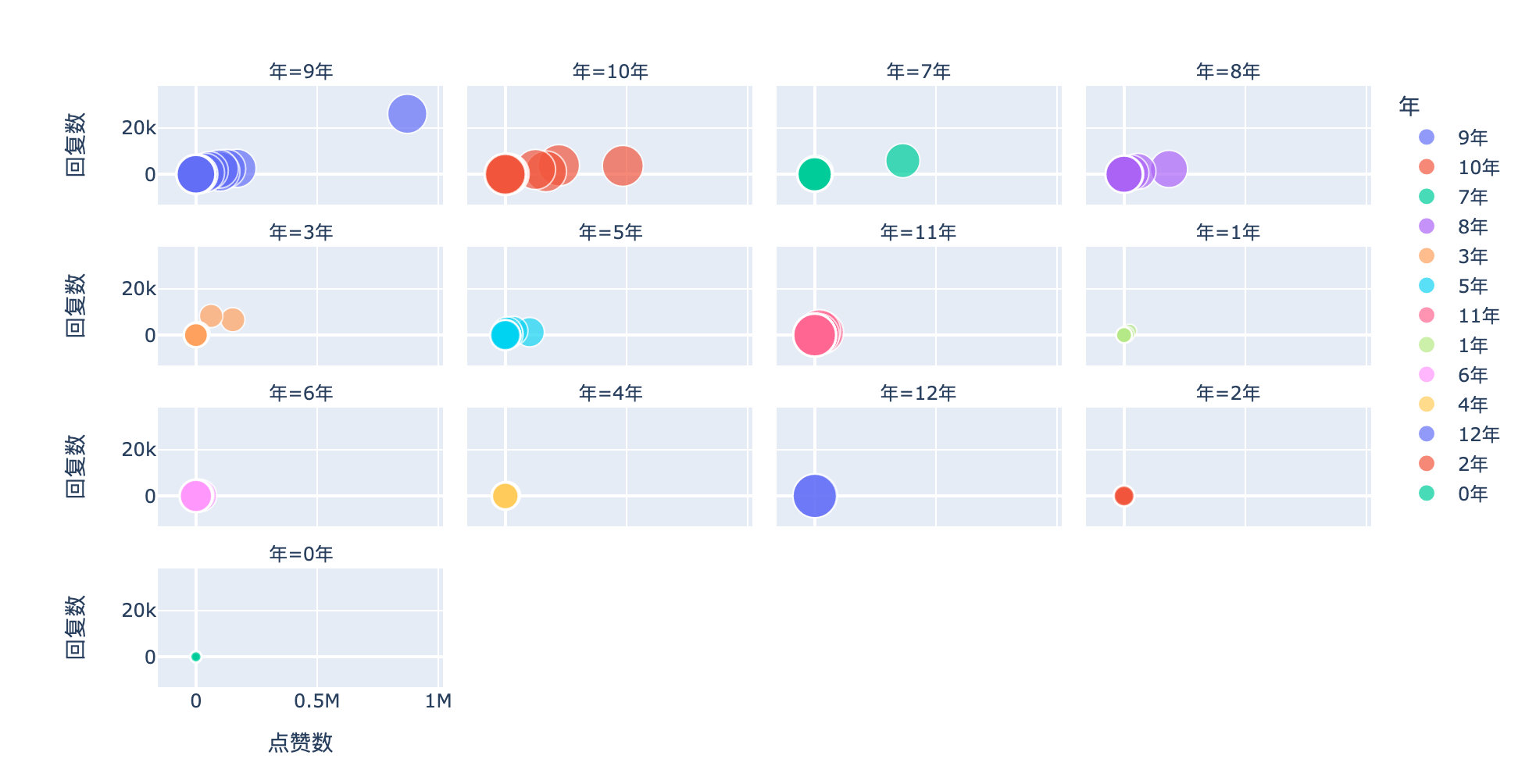
通过用户的年龄和点赞数、回复数来看,用户年龄在7、8、9、10年时的用户更为活跃;年龄偏大或者新生的微博用户的评论较少。
同时点赞数也集中在2000-5000之间的部分
评论时间
px.scatter(df,
x="评论时间",
y="天",
color="年",
size="天")
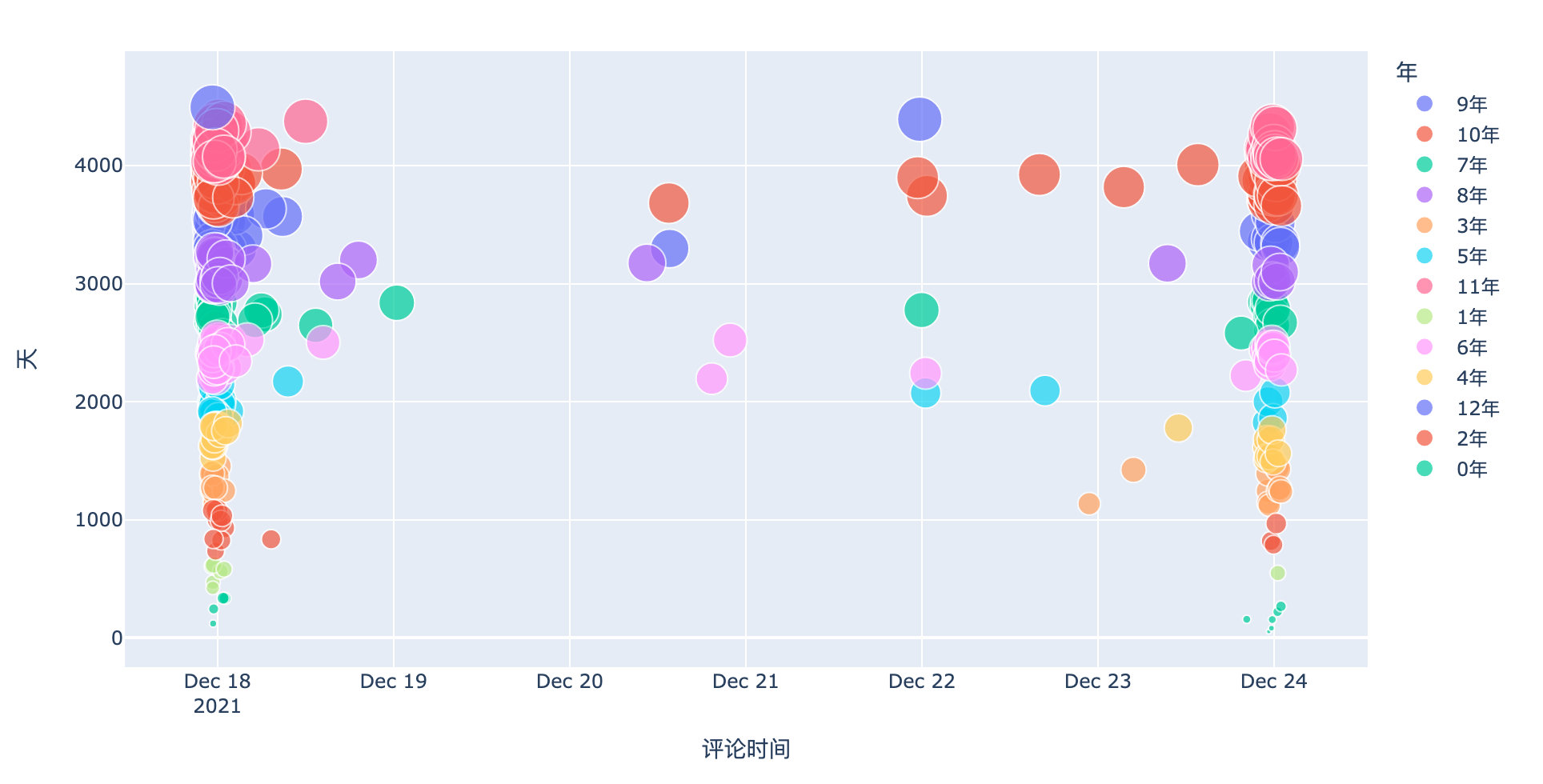
从用户的评论时间点来看,当李发了第一篇文之后,瞬间引爆了评论(左侧密集部分);这条微博沉寂了4天,没有想到23号的晚上又火了
粉丝吃瓜重点
将粉丝的评论内容分词找到他们的重点:
comment_list = df["评论内容"].tolist()
# 分词过程
comment_jieba_list = []
for i in range(len(comment_list)):
# jieba分词
seg_list = jieba.cut(str(comment_list[i]).strip(), cut_all=False)
for each in list(seg_list):
comment_jieba_list.append(each)
# 创建停用词list
def StopWords(filepath):
stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]
return stopwords
# 传入停用词表的路径
stopwords = StopWords("/Users/peter/spider/nlp_stopwords.txt")
useful_comment = []
for col in comment_jieba_list:
if col not in stopwords:
useful_comment.append(col)
information = pd.value_counts(useful_comment).reset_index()[1::]
information.columns=["word","number"]
information_zip = [tuple(z) for z in zip(information["word"].tolist(), information["number"].tolist())]
# 绘图
c = (
WordCloud()
.add("", information_zip, word_size_range=[20, 80], shape=SymbolType.DIAMOND)
.set_global_opts(title_opts=opts.TitleOpts(title="微博评论词云图"))
)
c.render_notebook()

重点关注下前50个词语:

除了两位当事人,粉丝还比较关心他们的孩子。毕竟孩子是无辜的,但是他们的瓜不正是孩子引起的吗?个人的看法。
总之:不管是王还是李,如果真的是渣男或者渣女,请上十字架,阿门!
送书活动
Python爬虫有一个非常厉害的框架Scrapy,小编联系了北京大学出版社送两书:《Python网路爬虫框架Scrapy从入门到精通》。精选两位走心留言的小伙伴

对Python爬虫感兴趣的朋友也可以直接购买喔。
以上是关于Python爬虫:微博评论数据分析的主要内容,如果未能解决你的问题,请参考以下文章
用python爬取微博评论数据,爬虫之路,永无止境。。(附源码)