本硕非科班,单模型获得亚军!
Posted Datawhale
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了本硕非科班,单模型获得亚军!相关的知识,希望对你有一定的参考价值。
Datawhale干货
作者:周远哲,斯特拉斯堡大学硕士
我的本科与硕士都是非科班,几乎没有相关的基础。 接触机器学习竞赛的半年左右的时候参加了去年kaggle规模最大的jane street量化大赛,比赛前期屠榜了几次,最终也拿到了冠军。与此同时也拿了一些其他比赛的top名次。本次比赛的主要目的还是学习,通过比赛学习一些CTR建模方面的基础知识。这一次比赛的队友很强,有幸再次拿到了好名次。
本次参加了微信大数据挑战赛,比赛中我只用到了一个模型(DCNv1),其他的时间更多是在探索和验证一些奇特的想法,初赛的方案没有构造任何手工特征,因此上分的速度相对于别的队伍要慢上很多。读者最关注的应该是模型的效果。这个方案的分数在复赛a榜,做bagging后可达到0.724+的成绩,在比赛中拿到亚军。下面具体介绍一下赛题及我的方案。后台回复 211209 可获取完整代码。
代码地址:
https://aistudio.baidu.com/aistudio/projectdetail/2536106
实践背景
赛题背景
本次比赛基于脱敏和采样后的数据信息,对于给定的一定数量到访过微信视频号“热门推荐”的用户, 根据这些用户在视频号内的历史n天的行为数据,通过算法在测试集上预测出这些用户对于不同视频内容的互动行为(包括点赞、点击头像、收藏、转发等)的发生概率。本次比赛以多个行为预测结果的加权uAUC值进行评分
比赛提供训练集用于训练模型,测试集用于评估模型效果,提交结果demo文件用于展示提交结果的格式。所有数据文件格式都是带表头的.csv格式,不同字段列之间用英文逗号分隔。初赛与复赛的数据分布一致,数据规模不同。初赛提供百万级训练数据,复赛提供千万级训练数据。
赛题地址:https://algo.weixin.qq.com/
评价指标
本次比赛采用uAUC作为单个行为预测结果的评估指标,uAUC定义为不同用户下AUC的平均值,计算公式如下: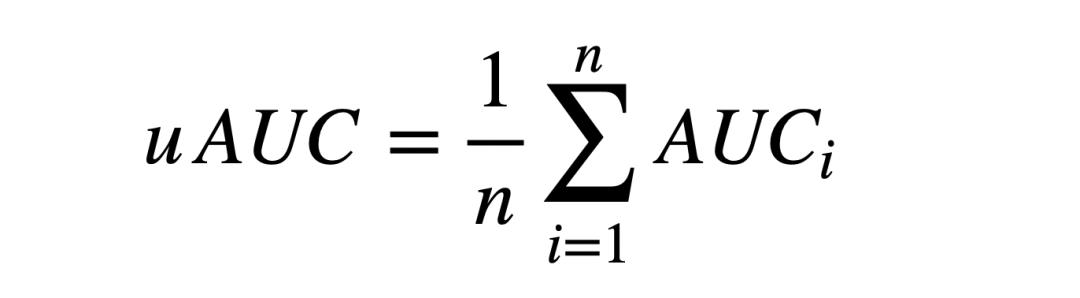
其中,n为测试集中的有效用户数,有效用户指的是对于某个待预测的行为,过滤掉测试集中全是正样本或全是负样本的用户后剩下的用户。AUCi为第i个有效用户的预测结果的AUC(Area Under Curve)。AUC的定义和计算方法可参考维基百科。
初赛的最终分数为4个行为(查看评论、点赞、点击头像、转发)的uAUC值的加权平均。复赛的最终分数为7个行为(查看评论、点赞、点击头像、转发、收藏、评论和关注)的uAUC值的加权平均。分数越高,排名越靠前。
性能要求
出于性能评估的可操作性考虑,本次比赛只要求晋级决赛的Top6队伍需满足最低性能标准,晋级空缺名额后补。组委会届时将对队伍提交的代码和模型进行性能评估。关于性能评估的具体说明如下:性能评估方法:
在组委会指定的机器上(2卡P40 48G显存 14核CPU 112G内存),预测给定测试数据集7个目标行为的概率,记录预测时长(只统计模型推理部分耗时,不包含数据处理、特征提取等部分耗时),并计算单个目标行为2000条样本的平均预测时长(单位:毫秒)。
最低性能要求:单个目标行为2000条样本的预测时长不超过200毫秒。
赛题难点
如何利用多模态向量。
如何加速训练,提高迭代效率,同时节省内存。
如何做采样?
预训练向量存在信息泄漏,导致训练过程中过拟合训练集怎么办?
赛事总结
以往的大数据挑战赛只允许在校学生参与,这一次的大数据挑战赛在职人员也可以参加,竞争更加激烈,参与数达到了惊人的6768支队伍,比赛第一天的有效提交队伍数便突破了1000,国内很多推荐算法相关的从业人员都或多或少会了解或参与,可能是今年参与人数最多的比赛了,同时也是数据挖掘爱好者证明自己实力最好的舞台。
本次大数据挑战赛的赛事方对于比赛的公平公正做了许多努力,同时提供了大量充足的算力支持(有了112G内存,写代码不需要那么抠抠搜搜了)。赛事方针对部分队伍可能利用b榜测试集数据的泄漏信息进行特征工程的情况,采取许多必要的措施。最终的比赛b榜,选手只允许使用训练好的数据进行预测,测试集的时间信息被去除,同时ab榜采用了完全不同的用户集合,既考验了选手的工程能力,也考验了选手的的建模能力。
代码实践
读取数据
比赛时能用到的有效数据越多越好,多多益善。这里我们把初赛数据也用上,用于预训练词向量。
这次分享不提供比赛数据集,使用生成的dummy数据代替。代码按照复赛的格式实现。
!pip install gensim
import pandas as pd
import numpy as np
from gensim.models import Word2Vec
from gensim.models import KeyedVectors
# notebook掉线的话会无法监测进度,因此把训练进度打印进一个文件。当然这里也可以用nohup挂起运行。
# !pip install loguru -i http://mirrors.tencentyun.com/pypi/simple
# from loguru import logger
import os
import gc
import time
import traceback
from collections import defaultdict
from sklearn.metrics import roc_auc_score
from paddle.io import Dataset
from paddle.static import InputSpec
import paddle
import paddle.fluid as fluid
from paddle.fluid.dygraph import Linear
from paddle.fluid.dygraph import Layer, to_variable
import paddle.fluid.dygraph as dygraph
# paddle.enable_static()
# 读取测试集
test_a = pd.read_csv('./test_a.csv')
# 读取初赛数据
test_pre_a = pd.read_csv('wbdc2021/data/wedata/wechat_algo_data1/test_a.csv')
test_pre_b = pd.read_csv('wbdc2021/data/wedata/wechat_algo_data1/test_b.csv')
test_pre_a = test_pre_a.append(test_pre_b)
# 读取多模态向量
feed_embedding = pd.read_csv('./feed_embeddings.csv')
# 读取初赛、复赛训练集
user_action = pd.read_csv('./user_action.csv')
user_action_prelimi = pd.read_csv('wbdc2021/data/wedata/wechat_algo_data1/user_action.csv')
user_action = user_action.append(user_action_prelimi)
# 读取feed信息
feed_info = pd.read_csv('./feed_info.csv')
N_test = test_a.shape[0]
# 读取多模态词向量为词典
feed_id_embedding_dict =
# 使用词典存储多模态向量
for id, emb in feed_embedding.values:
feed_id_embedding_dict[id] = np.array(emb.split(' ')[:512]).astype('float32')
del feed_embedding
# uAUC评测函数
def uAUC(labels, preds, user_id_list):
"""Calculate user AUC"""
user_pred = defaultdict(lambda: [])
user_truth = defaultdict(lambda: [])
for idx, truth in enumerate(labels):
user_id = user_id_list[idx]
pred = preds[idx]
truth = labels[idx]
user_pred[user_id].append(pred)
user_truth[user_id].append(truth)
user_flag = defaultdict(lambda: False)
for user_id in set(user_id_list):
truths = user_truth[user_id]
flag = False
# 若全是正样本或全是负样本,则flag为False
for i in range(len(truths) - 1):
if truths[i] != truths[i + 1]:
flag = True
break
user_flag[user_id] = flag
total_auc = 0.0
size = 0.0
for user_id in user_flag:
if user_flag[user_id]:
auc = roc_auc_score(np.asarray(user_truth[user_id]), np.asarray(user_pred[user_id]))
total_auc += auc
size += 1.0
user_auc = float(total_auc)/size
return user_auc
# 统一设置一些超参数
N_USERID = 250250
N_FEEDID = 112871 # feedid个数
N_AUTHORSONGSINGER = 30000
EMBEDDING_SIZE_FEEDID_PRETRAINED = 256 # 预训练feedid的维度
N_duomo = 64 # 多模态向量降维
PCA_DIM = 64 # 文本类向量降维
EMBEDDING_SIZE_AUTHORID = 128
EMBEDDING_SIZE_SONGSINGERID = 32
EMBEDDING_SIZE_KEYWORDTAG = 20
BATCH_SIZE = 8000
EPOCHS = 2预训练词向量
# 预训练feedid词向量
# 这里没有对id的顺序进行处理,按默认的顺序训练词向量。
if os.path.exists('./feedmodel_cbow.model'):
model_sg = Word2Vec.load('./feedmodel_cbow.model')
else:
feedid_seq_list = np.concatenate([
user_action.groupby('userid').feedid.apply(lambda x: [str(id) for id in x] ).values,
test_a.groupby('userid').feedid.apply(lambda x: [str(id) for id in x] ).values,
test_pre_a.groupby('userid').feedid.apply(lambda x: [str(id) for id in x] ).values
])
# 比赛中使用的原始参数
model_sg = Word2Vec(feedid_seq_list, vector_size=EMBEDDING_SIZE_FEEDID_PRETRAINED, window=32, min_count=1, sg=0, sample=1e-3, negative=15, workers=32, seed=1, epochs=10)
model_sg.save('./feedmodel_cbow.model')
# 处理一下缺失值,这里的处理比较粗糙
user_id_a = set(list(test_a.userid.values))
user_id_train = set(list(user_action.userid.values))
feed_id_a = set(list(test_a.feedid.values))
feed_id_train = set(list(user_action.feedid.values))
feed_info['authorid'].fillna(feed_info['authorid'].max()+1, inplace=True)
feed_info['bgm_song_id'].fillna(feed_info['bgm_song_id'].max()+1, inplace=True)
feed_info['bgm_singer_id'].fillna(feed_info['bgm_singer_id'].max()+1, inplace=True)
feedid_authorid_dict = dict(zip(list(feed_info['feedid'].values), list(feed_info['authorid'].values)))
feedid_bgm_song_id_dict = dict(zip(list(feed_info['feedid'].values), list(feed_info['bgm_song_id'].values)))
feedid_bgm_singer_id_dict = dict(zip(list(feed_info['feedid'].values), list(feed_info['bgm_singer_id'].values)))
feedid_vps_dict = dict(zip(list(feed_info['feedid'].values), list(feed_info['videoplayseconds'].values)))
# 将其他的id类特征拼接入训练数据。这里没有使用pandas自带的merge函数,而是使用词典映射,避免了OOM的问题。
# 这里实际上可以用embedding layer来做映射处理,但是比赛中遇到了一个bug没有调试通,因此保留了这些id特征作为输入。
user_action['authorid'] = user_action['feedid'].map(dict(zip(feed_info.feedid.values, feed_info.authorid.values)))
user_action['bgm_song_id'] = user_action['feedid'].map(dict(zip(feed_info.feedid.values, feed_info.bgm_song_id.values)))
user_action['bgm_singer_id'] = user_action['feedid'].map(dict(zip(feed_info.feedid.values, feed_info.bgm_singer_id.values)))
user_action['vps'] = user_action['feedid'].map(feedid_vps_dict).astype('float32')
user_action['stay/vps'] = user_action['stay']/1000/user_action['vps']
# 对测试集数据用相同的方式处理
test_a['authorid'] = test_a['feedid'].map(dict(zip(feed_info.feedid.values, feed_info.authorid.values)))
test_a['bgm_song_id'] = test_a['feedid'].map(dict(zip(feed_info.feedid.values, feed_info.bgm_song_id.values)))
test_a['bgm_singer_id'] = test_a['feedid'].map(dict(zip(feed_info.feedid.values, feed_info.bgm_singer_id.values)))
test_pre_a['authorid'] = test_pre_a['feedid'].map(dict(zip(feed_info.feedid.values, feed_info.authorid.values)))
test_pre_a['bgm_song_id'] = test_pre_a['feedid'].map(dict(zip(feed_info.feedid.values, feed_info.bgm_song_id.values)))
test_pre_a['bgm_singer_id'] = test_pre_a['feedid'].map(dict(zip(feed_info.feedid.values, feed_info.bgm_singer_id.values)))
# 文本类向量使用PCA进行处理
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer, TfidfVectorizer
from sklearn.feature_extraction.text import CountVectorizer
import os
from sklearn.decomposition import PCA
feed_info['description'].fillna('0', inplace=True)
feed_info['ocr'].fillna('0', inplace=True)
feed_info['asr'].fillna('0', inplace=True)
if os.path.exists('./tfidf_pca.npy'):
tfidf_pca = np.load('tfidf_pca.npy')
else:
vectorizer = CountVectorizer()
transformer = TfidfVectorizer(
min_df=3, max_df=0.9, use_idf=1,
smooth_idf=1, sublinear_tf=1)
corpus= feed_info[~feed_info.description.isna()].description.values
tfidf = transformer.fit_transform(corpus)
Nrow = tfidf.shape[0]
from sklearn.decomposition import TruncatedSVD
clf = TruncatedSVD(PCA_DIM)
tfidf_pca = clf.fit_transform(tfidf)
np.save('tfidf_pca.npy', tfidf_pca)
# 将降低维度后的文本类向量保存入array
embedding_matrix5 = np.zeros((N_FEEDID + 2, PCA_DIM))
for i, id in enumerate(feed_info.feedid.values):
try:
embedding_matrix5[id+1] = tfidf_pca[i].astype('float32')
except:
pass构建embedding层
# 将降低多模态向量保存入array
embedding_matrix3 = np.zeros((N_FEEDID + 2, 512))
for i in range(N_FEEDID):
try:
embedding_matrix3[i+1] = feed_id_embedding_dict[i].astype('float32')
except:
pass
# 使用PCA对多模态向量降维。
if N_duomo!=512:
pca = PCA(n_components=N_duomo)
embedding_matrix3 = pca.fit_transform(embedding_matrix3)
# 拼接两组向量
embedding_matrix3 = np.hstack([embedding_matrix3, embedding_matrix5])
# 构建embedding layer
embedding_layer_fid_multimodal = paddle.nn.Embedding(
num_embeddings=N_FEEDID+2,
embedding_dim=N_duomo + PCA_DIM,
padding_idx=0,
)
embedding_layer_fid_multimodal.weight.set_value(embedding_matrix3.astype('float32'))
# 将预训练的feedid向量保存入array
embedding_matrix = np.zeros((N_FEEDID + 2, EMBEDDING_SIZE_FEEDID_PRETRAINED))
for i in range(N_FEEDID):
try:
embedding_matrix[i+1] = model_sg.wv[str(i)].astype('float32')
except:
pass
# 构建embedding layer
embedding_layer_fid_pretrained = paddle.nn.Embedding(
num_embeddings=N_FEEDID+2,
embedding_dim=EMBEDDING_SIZE_FEEDID_PRETRAINED,
padding_idx=0,
)
embedding_layer_fid_pretrained.weight.set_value(embedding_matrix.astype('float32'))构建模型输入
# 训练集数据
X_train = user_action.sort_values(by=['date_', 'userid'])[['userid', 'feedid']].copy()
X_train['authorid'] = X_train['feedid'].map(feedid_authorid_dict).astype('float32')
X_train['songid'] = X_train['feedid'].map(feedid_bgm_song_id_dict).astype('float32')
X_train['singerid'] = X_train['feedid'].map(feedid_bgm_singer_id_dict).astype('float32')
X_train['vps'] = X_train['feedid'].map(feedid_vps_dict).astype('float32')
X_train['device'] = user_action.sort_values(by=['date_', 'userid'])['device'].astype('float32')
y_train = user_action.sort_values(by=['date_', 'userid'])[['read_comment', 'like', 'click_avatar', 'forward', 'favorite', 'comment', 'follow', ]].copy()
# 测试集
X_test = test_a[['userid', 'feedid']].copy()
X_test['authorid'] = X_test['feedid'].map(feedid_authorid_dict).astype('float32')
X_test['songid'] = X_test['feedid'].map(feedid_bgm_song_id_dict).astype('float32')
X_test['singerid'] = X_test['feedid'].map(feedid_bgm_singer_id_dict).astype('float32')
X_test['vps'] = X_test['feedid'].map(feedid_vps_dict).astype('float32')
X_test['device'] = test_a['device'].astype('float32')
X_train = X_train.values
X_test = X_test.values构建feedid与tag/keyword的映射
# 构建keyword的embedding层
def operate(X):
xl = X.split(';')
xl = [int(x.split(' ')[0]) for x in xl if float(x.split(' ')[1])>0.5 ]
return xl
# 将tag key word进行拼接
manual_tag_list = feed_info.manual_tag_list.fillna('0;0').apply(lambda x: [int(i) for i in (x).split(';')]).values
machine_tag_list_ = feed_info.machine_tag_list.fillna('0 0;0 0').apply(lambda x: operate(x)).values
machine_keyword_list = feed_info.machine_keyword_list.fillna('0;0').apply(lambda x: [int(i) for i in (x).split(';')]).values
manual_keyword_list = feed_info.manual_keyword_list.fillna('0;0').apply(lambda x: [int(i) for i in (x).split(';')]).values
def padding(x, N=EMBEDDING_SIZE_KEYWORDTAG):
if len(x)>N:
return x[:N]
else:
return x+[0 for i in range(N-len(x))]
key_list = []
for l1, l2, l3, l4 in zip(machine_keyword_list, manual_keyword_list, manual_tag_list, machine_tag_list_):
tmp = l2
tmp2 = l3
key_list.append(padding(tmp, EMBEDDING_SIZE_KEYWORDTAG)+padding(tmp2, EMBEDDING_SIZE_KEYWORDTAG))
feedid_keyword_list_dict = dict(zip(list(feed_info.feedid.values), key_list))
embedding_matrix_exex = np.zeros((N_FEEDID + 2, EMBEDDING_SIZE_KEYWORDTAG*2))
for i in range(N_FEEDID):
try:
embedding_matrix_exex[i+1] = np.array(feedid_keyword_list_dict[i]).astype('int32')
except:
pass
# 使用embedding层来映射id
embedding_layer_fid_keytag = paddle.nn.Embedding(
num_embeddings=N_FEEDID+2,
embedding_dim=EMBEDDING_SIZE_KEYWORDTAG*2,
padding_idx=0,
)
embedding_layer_fid_keytag.weight.set_value(embedding_matrix_exex.astype('float32'))
import gc
gc.collect()author、song、singer的预训练embedding
# 以 userid 维度聚类,训练authour、song、singer id 的词向量。
# 这里给予authorid的词向量维度更高一些,是实验得出的结论。
if os.path.exists('./author_cbow.model'):
model_author_cbow = Word2Vec.load('./author_cbow.model')
else:
tmp = user_action.groupby('userid').authorid.apply(lambda x: [str(id) for id in x] ).values
tmp_ = test_a.groupby('userid').authorid.apply(lambda x: [str(id) for id in x] ).values
tmp = np.concatenate([tmp, tmp_])
tmp_ = test_pre_a.groupby('userid').authorid.apply(lambda x: [str(id) for id in x] ).values
tmp = np.concatenate([tmp, tmp_])
model_author_cbow = Word2Vec(tmp, vector_size=EMBEDDING_SIZE_AUTHORID, window=32, min_count=1, sg=0, sample=1e-3, negative=15, workers=32, seed=1, epochs=10)
model_author_cbow.save('./author_cbow.model')
# 映射词表
embedding_matrix_author = np.zeros((N_AUTHORSONGSINGER + 2, EMBEDDING_SIZE_AUTHORID))
for i in range(N_AUTHORSONGSINGER):
try:
embedding_matrix_author[i+1] = model_author_cbow.wv[str(i)].astype('float32')
except:
pass
# 构建embedding层
embedding_layer_author = paddle.nn.Embedding(
num_embeddings=N_AUTHORSONGSINGER + 2,
embedding_dim=EMBEDDING_SIZE_AUTHORID,
padding_idx=0,
weight_attr=paddle.ParamAttr(
initializer=paddle.nn.initializer.Assign(embedding_matrix_author),
trainable=False
)
)
embedding_layer_author.weight.set_value(embedding_matrix_author.astype('float32'))
if os.path.exists('./bgm_song_id_cbow.model'):
model_bgm_song_id_cbow = Word2Vec.load('./bgm_song_id_cbow.model')
else:
tmp = user_action.groupby('userid').bgm_song_id.apply(lambda x: [str(id) for id in x] ).values
tmp_ = test_a.groupby('userid').bgm_song_id.apply(lambda x: [str(id) for id in x] ).values
tmp = np.concatenate([tmp, tmp_])
tmp_ = test_pre_a.groupby('userid').bgm_song_id.apply(lambda x: [str(id) for id in x] ).values
tmp = np.concatenate([tmp, tmp_])
model_bgm_song_id_cbow = Word2Vec(tmp, vector_size=EMBEDDING_SIZE_SONGSINGERID, window=32, min_count=1, sg=0, sample=1e-3, negative=15, workers=32, seed=1, epochs=10)
model_bgm_song_id_cbow.save('./bgm_song_id_cbow.model')
# 映射词表
embedding_matrix_bgm_song_id = np.zeros((N_AUTHORSONGSINGER + 2, EMBEDDING_SIZE_SONGSINGERID))
for i in range(N_AUTHORSONGSINGER):
try:
embedding_matrix_bgm_song_id[i+1] = model_bgm_song_id_cbow.wv[str(float(i))].astype('float32')
except:
pass
# 构建embedding层
embedding_layer_song = paddle.nn.Embedding(
num_embeddings=N_AUTHORSONGSINGER + 2,
embedding_dim=EMBEDDING_SIZE_SONGSINGERID,
padding_idx=0,
)
embedding_layer_song.weight.set_value(embedding_matrix_bgm_song_id.astype('float32'))
if os.path.exists('./bgm_singer_id_cbow.model'):
model_bgm_singer_id_cbow = Word2Vec.load('./bgm_singer_id_cbow.model')
else:
tmp = user_action.groupby('userid').bgm_singer_id.apply(lambda x: [str(id) for id in x] ).values
tmp_ = test_a.groupby('userid').bgm_singer_id.apply(lambda x: [str(id) for id in x] ).values
tmp = np.concatenate([tmp, tmp_])
tmp_ = test_pre_a.groupby('userid').bgm_singer_id.apply(lambda x: [str(id) for id in x] ).values
tmp = np.concatenate([tmp, tmp_])
model_bgm_singer_id_cbow = Word2Vec(tmp, vector_size=EMBEDDING_SIZE_SONGSINGERID, window=32, min_count=1, sg=0, sample=1e-3, negative=15, workers=32, seed=1, epochs=10)
model_bgm_singer_id_cbow.save('./bgm_singer_id_cbow.model')
# 映射词表
embedding_matrix_bgm_singer_id = np.zeros((N_AUTHORSONGSINGER + 2, EMBEDDING_SIZE_SONGSINGERID))
for i in range(N_AUTHORSONGSINGER):
try:
embedding_matrix_bgm_singer_id[i+1] = model_bgm_singer_id_cbow.wv[str(float(i))].astype('float32')
except:
pass
# 构建embedding层
embedding_layer_singer = paddle.nn.Embedding(
num_embeddings=N_AUTHORSONGSINGER + 2,
embedding_dim=EMBEDDING_SIZE_SONGSINGERID,
padding_idx=0,
)
embedding_layer_singer.weight.set_value(embedding_matrix_bgm_singer_id.astype('float32'))TF-IDF
之前我们构筑了很多feedid的词向量特征,现在我们为userid构建tf-idf向量作为特征。
# 构建tf-idf向量作为特征。
# 词向量作为特征偏向于提升模糊泛化的效果,而tfidf则属于更加精准的匹配。
# 这里同样给予authorid更高的向量维度
import os
if os.path.exists('./tfidf_user.npy'):
tfidf_userid_feat = np.load('tfidf_user.npy')
else:
from tqdm import tqdm
tfidf_userid_feat = []
for group in tqdm(['authorid', 'bgm_song_id', 'bgm_singer_id',]):
tmp = user_action[['userid', group]].sort_values(by='userid').groupby('userid')[group].apply(lambda x: ' '.join(map(str, x)))
vectorizer = CountVectorizer()
transformer = TfidfTransformer(sublinear_tf=True)
from sklearn.decomposition import TruncatedSVD
tfidf = transformer.fit_transform(vectorizer.fit_transform(tmp))
if group =='authorid':
clf = TruncatedSVD(EMBEDDING_SIZE_AUTHORID)
else:
clf = TruncatedSVD(EMBEDDING_SIZE_SONGSINGERID)
tfidf_pca_author = clf.fit_transform(tfidf)
tfidf_userid_feat.append(tfidf_pca_author)
tfidf_userid_feat = np.hstack(tfidf_userid_feat)
np.save('tfidf_user.npy', tfidf_userid_feat)
# 映射词表
embedding_matrix_userid_tfidf = np.zeros((N_USERID+2, EMBEDDING_SIZE_AUTHORID+EMBEDDING_SIZE_SONGSINGERID*2))
for index, i in enumerate(sorted(user_action.userid.unique())):
try:
embedding_matrix_userid_tfidf[i+1] = tfidf_userid_feat[index].astype('float32')
except:
pass
# 构建embedding层
embedding_layer_userid_tfidf = paddle.nn.Embedding(
num_embeddings=N_USERID + 2,
embedding_dim=EMBEDDING_SIZE_AUTHORID+EMBEDDING_SIZE_SONGSINGERID*2,
padding_idx=0,
)
embedding_layer_userid_tfidf.weight.set_value(embedding_matrix_userid_tfidf.astype('float32'))模型结构与训练
模型结构_DCN模型
https://arxiv.org/abs/1708.05123
DCN 的全称是Deep & Cross Network,网络架构如下:
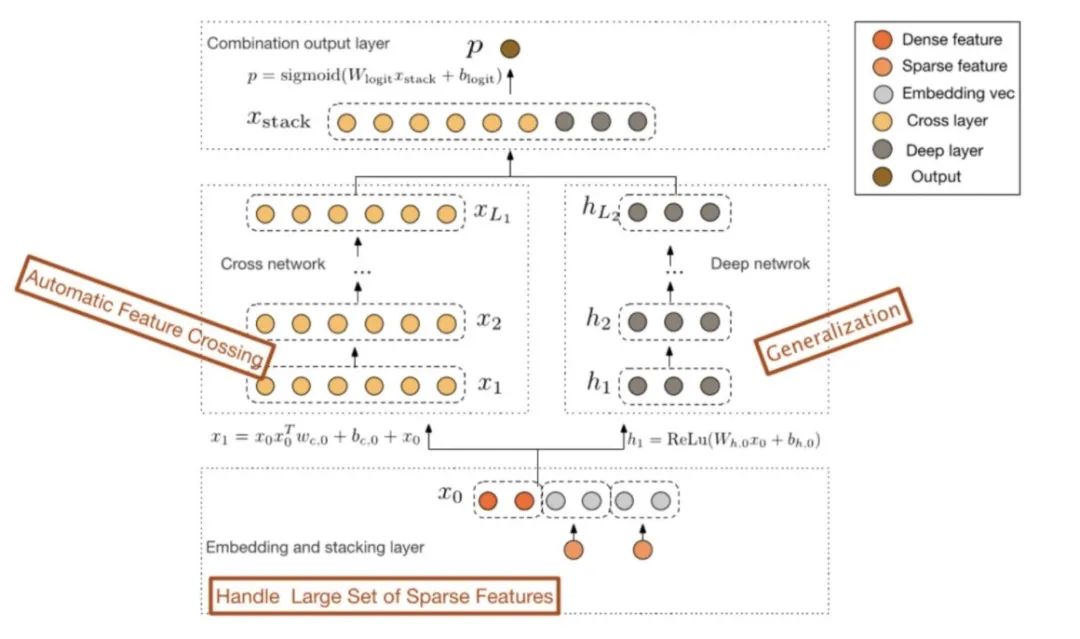
使用DCNv1的弊端也十分明显,模型本身17年就发表了,调参成本低,但是模型性能上限偏低。
模型结构_词向量
模型中使用的词向量种类包括了:
按照userid聚合的feedid的预训练词向量。
feedid的文本类、多模态特征向量。
按照userid聚合的authorid预训练词向量。
按照userid聚合的songid预训练词向量。
按照userid聚合的singerid预训练词向量。
使用authorid、songid、singerid的tfidf表示的userid词向量。
可训练的feedid向量。
可训练的userid向量。
可训练的tag、keyword向量。
可训练的authorid、songid、singerid向量。
模型中没有使用点击率等统计类型的特征。
import numpy as np
import pandas as pd
from numba import njit
from scipy.stats import rankdata
from joblib import Parallel, delayed
import warnings
warnings.filterwarnings("ignore", category=FutureWarning)
paddle.disable_static()
@njit
def _auc(actual, pred_ranks):
actual = np.asarray(actual)
pred_ranks = np.asarray(pred_ranks)
n_pos = np.sum(actual)
n_neg = len(actual) - n_pos
return (np.sum(pred_ranks[actual == 1]) - n_pos*(n_pos+1)/2) / (n_pos*n_neg)
def auc(actual, predicted):
pred_ranks = rankdata(predicted)
return _auc(actual, pred_ranks)
class network(fluid.dygraph.Layer):
def __init__(self, name_scope='baseline'):
super(network, self).__init__(name_scope)
name_scope = self.full_name()
# 定义三层全连接层,输入维度是最终选取的特征数量,输出维度是1,激活函数为relu
self.embedding_layer_feedid_trainable = paddle.nn.Embedding(N_FEEDID + 2, 64)
self.embedding_layer_userid_trainable = paddle.nn.Embedding(N_USERID + 2, 128)
self.embedding_layer_author_trainable = paddle.nn.Embedding(N_AUTHORSONGSINGER+2, 64)
self.embedding_layer_song_trainable = paddle.nn.Embedding(N_AUTHORSONGSINGER+2, 16)
self.embedding_layer_singer_trainable = paddle.nn.Embedding(N_AUTHORSONGSINGER+2, 16)
self.embedding_layer_author = embedding_layer_author # 128
self.embedding_layer_song = embedding_layer_song # 32
self.embedding_layer_singer = embedding_layer_singer # 32
self.embedding_layer_userid_tfidf = embedding_layer_userid_tfidf # 128 + 32 + 32
self.embedding_layer_fid_pretrained = embedding_layer_fid_pretrained # 256
self.embedding_layer_fid_multimodal = embedding_layer_fid_multimodal # 128
self.embedding_layer_fid_keytag = embedding_layer_fid_keytag # ...
self.embedding_layer_tag = paddle.nn.Embedding(N_AUTHORSONGSINGER+2, 32)
self.embedding_layer_keyword = paddle.nn.Embedding(N_AUTHORSONGSINGER+2, 32)
self.x0_size = 128+64+64+16+16+128+32+32+128+32+32+256+128+32+32+2
self.mlp1 = paddle.fluid.dygraph.Linear(self.x0_size, 256, act='relu')
self.mlp_bn1 = paddle.nn.BatchNorm(256)
self.mlp2 = paddle.fluid.dygraph.Linear(256, 256, act='relu')
self.mlp_bn2 = paddle.nn.BatchNorm(256)
self.cross1 = paddle.fluid.dygraph.Linear(self.x0_size, self.x0_size, )
self.cross2 = paddle.fluid.dygraph.Linear(self.x0_size, self.x0_size, )
self.cross3 = paddle.fluid.dygraph.Linear(self.x0_size, self.x0_size, )
self.cross4 = paddle.fluid.dygraph.Linear(self.x0_size, self.x0_size, )
self.cross5 = paddle.fluid.dygraph.Linear(self.x0_size, self.x0_size, )
self.bn_output = paddle.nn.BatchNorm(256+self.x0_size)
self.output = paddle.fluid.dygraph.Linear(self.x0_size+256, 7, )
self.sigmoid = paddle.nn.Sigmoid()
# 网络的前向计算函数
def forward(self, inputs):
input_userid = paddle.cast(inputs[:,0]+1, dtype='int64')
input_feedid = paddle.cast(inputs[:,1]+1, dtype='int64')
input_authorid = paddle.cast(inputs[:,2]+1, dtype='int64')
input_songid = paddle.cast(inputs[:,3]+1, dtype='int64')
input_singerid = paddle.cast(inputs[:,4]+1, dtype='int64')
embedding_userid_trainable = self.embedding_layer_userid_trainable(input_userid)
embedding_userid_tfidf = self.embedding_layer_userid_tfidf(input_userid)
embedding_userid_tfidf.stop_gradient=False
embedding_feedid_trainable = self.embedding_layer_feedid_trainable(input_feedid)
embedding_fid_multimodal = self.embedding_layer_fid_multimodal(input_feedid)
embedding_fid_pretrained = self.embedding_layer_fid_pretrained(input_feedid)
embedding_fid_multimodal.stop_gradient=False
embedding_fid_pretrained.stop_gradient=False
embedding_author = self.embedding_layer_author(input_authorid+1)
embedding_song = self.embedding_layer_song(input_songid+1)
embedding_singer = self.embedding_layer_singer(input_singerid+1)
embedding_author_trainable = self.embedding_layer_author_trainable(input_authorid+1)
embedding_song_trainable = self.embedding_layer_song_trainable(input_songid+1)
embedding_singer_trainable = self.embedding_layer_singer_trainable(input_singerid+1)
input_tag_keyword = paddle.cast(self.embedding_layer_fid_keytag(input_feedid), dtype='int64')
tag_embedding = paddle.sum(self.embedding_layer_tag(input_tag_keyword[:,20:]), axis=1)/20.
keyword_embedding = paddle.sum(self.embedding_layer_keyword(input_tag_keyword[:,:20]), axis=1)/20.
embedding_author.stop_gradient=False
embedding_song.stop_gradient=False
embedding_singer.stop_gradient=False
input_tag_keyword.stop_gradient=False
dense_input = inputs[:,5:]
x0 = paddle.fluid.layers.concat([
embedding_userid_trainable,
embedding_userid_tfidf,
embedding_feedid_trainable,
embedding_fid_multimodal,
embedding_fid_pretrained,
embedding_author,
embedding_song,
embedding_singer,
embedding_author_trainable,
embedding_song_trainable,
embedding_singer_trainable,
tag_embedding,
keyword_embedding,
dense_input
], axis=-1)
x0 = paddle.cast(x0, dtype='float32')
x_mlp = self.mlp1(paddle.fluid.layers.dropout(x0, dropout_prob=0.4))
x_mlp = self.mlp_bn1(x_mlp)
x_mlp = self.mlp2(paddle.fluid.layers.dropout(x_mlp, dropout_prob=0.4))
x_mlp = self.mlp_bn2(x_mlp)
cross = x0
cross = cross + x0 * self.cross1( paddle.fluid.layers.dropout(cross, dropout_prob=0.15) )
cross = cross + x0 * self.cross2( paddle.fluid.layers.dropout(cross, dropout_prob=0.15) )
cross = cross + x0 * self.cross3( paddle.fluid.layers.dropout(cross, dropout_prob=0.15) )
cross = cross + x0 * self.cross4( paddle.fluid.layers.dropout(cross, dropout_prob=0.15) )
cross = cross + x0 * self.cross5( paddle.fluid.layers.dropout(cross, dropout_prob=0.15) )
x = paddle.fluid.layers.concat([cross, x_mlp],axis=-1)
x = self.bn_output(x)
x = self.output(paddle.fluid.layers.dropout(x, dropout_prob=0.5))
output = self.sigmoid(x)
output = paddle.cast(output, dtype='float32')
return output
class TrainDataset(Dataset):
def __init__(self, x_train_array, y_train_array):
# 样本数量
self.training_data, self.training_label = x_train_array.astype('float32'), y_train_array.astype('float32')
self.num_samples = self.training_data.shape[0]
def __getitem__(self, idx):
data = self.training_data[idx]
label = self.training_label[idx]
return data, label
def __len__(self):
# 返回样本总数量
return self.num_samples
for i in range(14):
try:
import gc
del x_train, x_valid
gc.collect()
del y_train_, y_valid_
gc.collect()
except:
pass
# 这里没有使用验证集,只是将第i天的负样本去掉了
index_val = (user_action.date_==i).values
index_train = (~index_val)
x_train, x_valid = X_train[index_train], X_train[index_val]
y_train_, y_valid_ = y_train.values[index_train].astype('float32'), y_train.values[index_val].astype('float32')
train_dataset = TrainDataset(x_train, y_train_)
train_loader = paddle.io.DataLoader(train_dataset, batch_size=1024*8, shuffle=True)
valid_dataset = TrainDataset(x_valid, y_valid_)
valid_loader = paddle.io.DataLoader(valid_dataset, batch_size=1024*8, shuffle=False)
input = [InputSpec(shape=[None, 7], dtype='float32',name='inputs')]
model = paddle.Model(network(), input)
model.prepare(optimizer=paddle.optimizer.Adam(learning_rate=0.002, parameters=model.parameters()),
loss=paddle.nn.BCELoss(),
)
model.fit(
train_data=train_loader,
eval_data=valid_loader,
epochs=2,
verbose=1,
)
model.save('./model_weight_'.format(i), False)
del train_dataset
del train_loader
del model
gc.collect()
y_test_preds = []
for i in range(14):
model = paddle.jit.load('./model_weight_'.format(i)).eval()
preds = model(X_test.astype('float32'))
y_test_preds.append(preds)
test_prediction = np.mean(y_test_preds, axis=0)
整理不易,点赞三连↓
以上是关于本硕非科班,单模型获得亚军!的主要内容,如果未能解决你的问题,请参考以下文章