什么是 Flink (流处理框架)
Posted 夏初夏那
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么是 Flink (流处理框架)相关的知识,希望对你有一定的参考价值。
Flink 入门

什么是Flink
-
Apache Flink 是为
分布式、高性能、随时可用以及准确的流处理应用程序打造的开源流处理框架
Flink 的发展历史d
Flink 诞生于欧洲的一个大数据研究项目 StratoSphere。该项目是柏林工业大学的一个研究性项目。早期,Flink 是做 Batch 计算的,但是在 2014 年, StratoSphere 里面的核心成员孵化出 Flink,同年将 Flink 捐赠 Apache,并在后来成为 Apache 的顶级大数据项目,同时 Flink 计算的主流方向被定位为 Streaming,即用流式计算来做所有大数据的计算,这就是 Flink 技术诞生的背景。
2014 年 Flink 作为主攻流计算的大数据引擎开始在开源大数据行业内崭露头角
Flink 与 Storm 及 Spark Streaming 等计算引擎的区别?
-
1、Flink 是一个
高吞吐、低延迟的计算引擎 -
2、提供了
有状态的计算,支持状态管理,支持强一致性的数据语义 -
3、支持基于Event Time的WaterMark对延迟或乱序的数据进行处理等
大数据计算引擎发展
第一代: MapReducer
- 批处理:Mapper, Reducer
- Hadoop的MapReducer将计算分为两个阶段, 分别为Map和Reducer
第二代: DAG框架 (Tez) + MapReducer
- 批处理 1个Tez = MR (1) + MR (2) + … + MR (n) 相比MR效率有所提升
第三代: Spark
- 批处理,
流处理, SQL高层API支持 自带DAG ,内存迭代计算, 性能较之前大幅提升
第四代: Flink
- 批处理,
流处理, SQL高层API支持 自带DAG ,流式计算性能更高,可靠性更高
Flink 的特点
图解
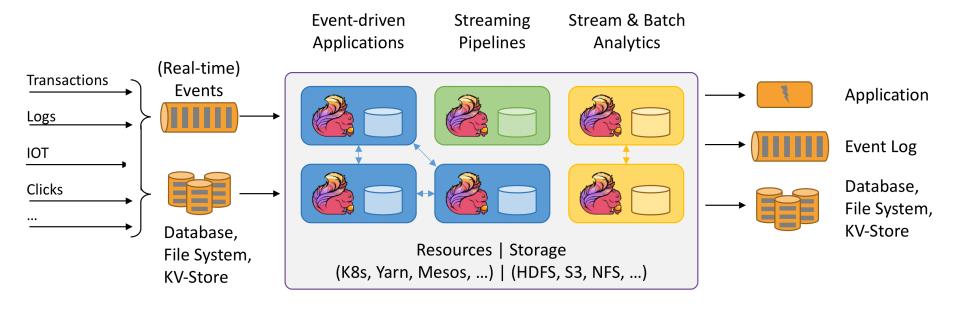
Flink 项目的理念
- Apache Flink 是为分布式、高性能、随时可用以及准确的流处理应用程序打造的开源
流处理框架
描述
- Apache Flink 是一个
框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。 - Flink 被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来(流,批)执行计算。
Flink流处理的特点
1、同时支持高吞吐,低延迟,高性能
低延迟,状态保存在内存中,很快计算完
2、支持事件时间(Event Time) 概念
Process TIme,大多数框架窗口计算采用的都是系统时间(process time),也是事件传输到计算框架处理时,系统主机的当前时间。Event Time,Flink支持基于事件时间(Event Time)语义进行窗口计算,也就是使用事件产生的时间,这种基于事件驱动的机制使得事件即使乱序到达,流系统也能够计算出精确的结果,保持了事件原本产生时的时序性,尽可能避免网络传输或硬件系统的影响。
3、支持有状态计算
4、支持高度灵活的窗口(Window)操作
- Flink中除了滚动窗口,滑动窗口还有基于数量的窗口Count,基于会话的窗口Session。
5、基于轻量级的分布式快照(CheckPoint)来实现容错
6、基于JVM实现独立的内存管理
7、Save Point保存点
CheckPoint是自动的,做容错。SavePoint是手动的,处理程序升级
到底了。。。
以上是关于什么是 Flink (流处理框架)的主要内容,如果未能解决你的问题,请参考以下文章