Flink计算框架概述
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink计算框架概述相关的知识,希望对你有一定的参考价值。
Flink 是一个针对流数据和批数据的分布式处理引擎,主要用 Java 代码实现。目前,Flink主要还是依靠开源社区的贡献来发展的。对于 Flink ,其处理的数据主要是流数据,批数据只是流数据的一个极限特例而已。Flink的批处理方式采用的是流式计算原理,这一点跟Spark的设计思想正好相反(Spark Streaming本质上是批处理,只是将计算分成了很小的单元,近似成流计算),这也是Flink的最大特点。Flink支持本地快速迭代,以及一些环形的迭代任务。
1、基本概念
- 数据集
数据集(DataSet)分为有界数据集和无界数据集。无界数据集的数据会源源不断地流入,有界数据集的数据是不可变的。许多传统上被认为是有界或“批”数据的真实数据集实际上是无界数据集。无界数据集包括但不限于:与移动或Web应用程序交互的最终用户、提供测量的物理传感器、金融市场、机器的日志数据。
- 执行模型
实时处理是指当数据正在生成时连续执行的数据的处理过程。批处理是指在有限的时间内执行有限的数据的处理过程。不管采用哪种类型的执行模型来处理数据都是可以的,但却不一定是最优的。例如,批处理一直被应用于无界数据集的处理上,尽管它存在窗口、状态管理和次序错误等潜在问题。Flink采用实时处理的执行模型,在数据处理精度和计算性能方面都有更大的优势。
- Flink程序模块
Flink程序包含的主要模块有:Data Source、Transformations和Data Sink,其中,Data Source(数据源)就是要进入Flink处理的数据,如HDFS、Kafka中的数据等。Transformations根据实际业务进行计算和转换。Data Sink是Flink处理完的数据,即输出数据。

2、主要特点
Flink 是一个开源的分布式实时计算框架。Flink 是有状态的和容错的,可以在维护一次应用程序状态的同时无缝地从故障中恢复;它支持大规模计算能力,能够在数千个节点上并发运行;它具有很好的吞吐量和延迟特性。同时,Flink提供了多种灵活的窗口函数。
- 状态管理机制
Flink检查点机制能保持exactly-once语义的计算。状态保持意味着应用能够保存已经处理的数据集结果和状态。

- 事件机制
Flink支持流处理和窗口事件时间语义。事件时间可以很容易地通过事件到达的顺序和事件可能的到达延迟流中计算出准确的结果。

- 窗口机制
Flink 支持基于时间、数目以及会话的非常灵活的窗口机制(window)。可以定制 window的触发条件来支持更加复杂的流模式。

- 容错机制
Flink高效的容错机制允许系统在高吞吐量的情况下支持exactly-once语义的计算。Flink可以准确、快速地做到从故障中以零数据丢失的效果进行恢复。

- 高吞吐量、低延迟
Flink 具有高吞吐量和低延迟(能快速处理大量数据)特性。下图展示了 Apache Flink和Apache Storm完成分布式项目计数任务的性能对比。

- 部署
可以通过Yarn和Mesos等资源管理软件来管理和部署Flink。
3、运行原理
- 链操作任务
分布式执行 Flink 的链操作任务,每个任务都由一个线程执行。将操作符链接到任务中是一个有用的优化,其减少了线程间切换和缓冲的开销,并且在降低延迟的同时提高了总体吞吐量,可以配置链接行为。

- 任务提交
Job Tracker:协调分布式执行—安排任务、协调检查点、协调故障恢复等。为了具有高可用性,设置了多个JobManager,其中一个是领导者,其他的作为备用。
Task Tracker:执行任务(更具体地说,是一个数据流任务)、和缓冲区交换数据流。
Client:客户端用来进行任务调度前期的准备(数据、环境变量等),然后提交计算任务到JobManager。任务提交之后,客户端可以断开连接,也可以继续保持连接以接收进度报告。
- 运行
当Flink集群启动后,首先会启动一个JobManager和一个或多个TaskManager。由客户端提交任务给JobManager,JobManager再调度任务到各个TaskManager来执行,然后TaskManager将心跳和统计信息汇报给JobManager。TaskManager之间以流的形式进行数据传输。

- 任务槽和资源
每个Worker(TaskManager)都是一个JVM进程,并且可以在单独的线程中执行一个或多个子任务。为了控制Worker可以接收多少个任务,Worker有所谓的任务槽(至少一个)。
每个任务槽都代表TaskManager的一个固定资源子集。例如,具有三个插槽的TaskManager将为每个插槽分配1/3隔离的内存资源,这意味着子任务不会与其他作业中的子任务来竞争内存。请注意,目前插槽仅分离托管的任务内存,不会进行CPU的隔离。
通过调整任务槽的数量,用户可以定义子任务如何彼此隔离。每个TaskManager都拥有一个插槽,这意味着每个任务组都可以在单独的JVM中运行(例如,可以在单独的容器中启动);而拥有多个插槽,则意味着更多的子任务共享相同的JVM。同一个JVM中的任务共享TCP连接(通过多路复用)和心跳消息,它们也可能共享数据集和数据结构,从而减少每个任务的开销。

Flink学习笔记概述
一、什么是Flink
1.Flink是一个分布式流处理框架,它能够在大规模的数据流上进行实时计算和批处理。Flink支持丰富的API,包括DataStream API和DataSet API,可以在多种计算场景中使用,例如实时数据处理、批处理、图形计算和机器学习等。Flink还具有高可用性、低延迟、高吞吐量和高扩展性等特点,是近年来非常流行的数据处理框架之一。
二、flink的使用场景有哪些
-
实时数据处理:Flink可用于处理来自各种来源的实时数据,包括传感器、移动设备、日志数据、交易数据等。
-
流式数据分析:Flink能够实时地对数据进行分析和计算,支持各种数据分析算法和模型,包括机器学习、实时推荐等。
-
实时报警和监控:Flink可以实时地对数据进行监控和报警,通过实时分析数据来检测异常和错误,及时采取行动。
-
实时数仓:Flink能够将实时数据转化为有价值的信息,可以将数据流转化为数据仓库,并进行OLAP操作,支持实时报表和可视化分析。
5.金融行业:Flink可用于处理金融交易数据,实现实时交易风险监控、实时交易报告生成等。
6.物联网:Flink可用于处理来自物联网设备的实时数据,支持设备状态监控、实时控制等
三、flink架构分析:
·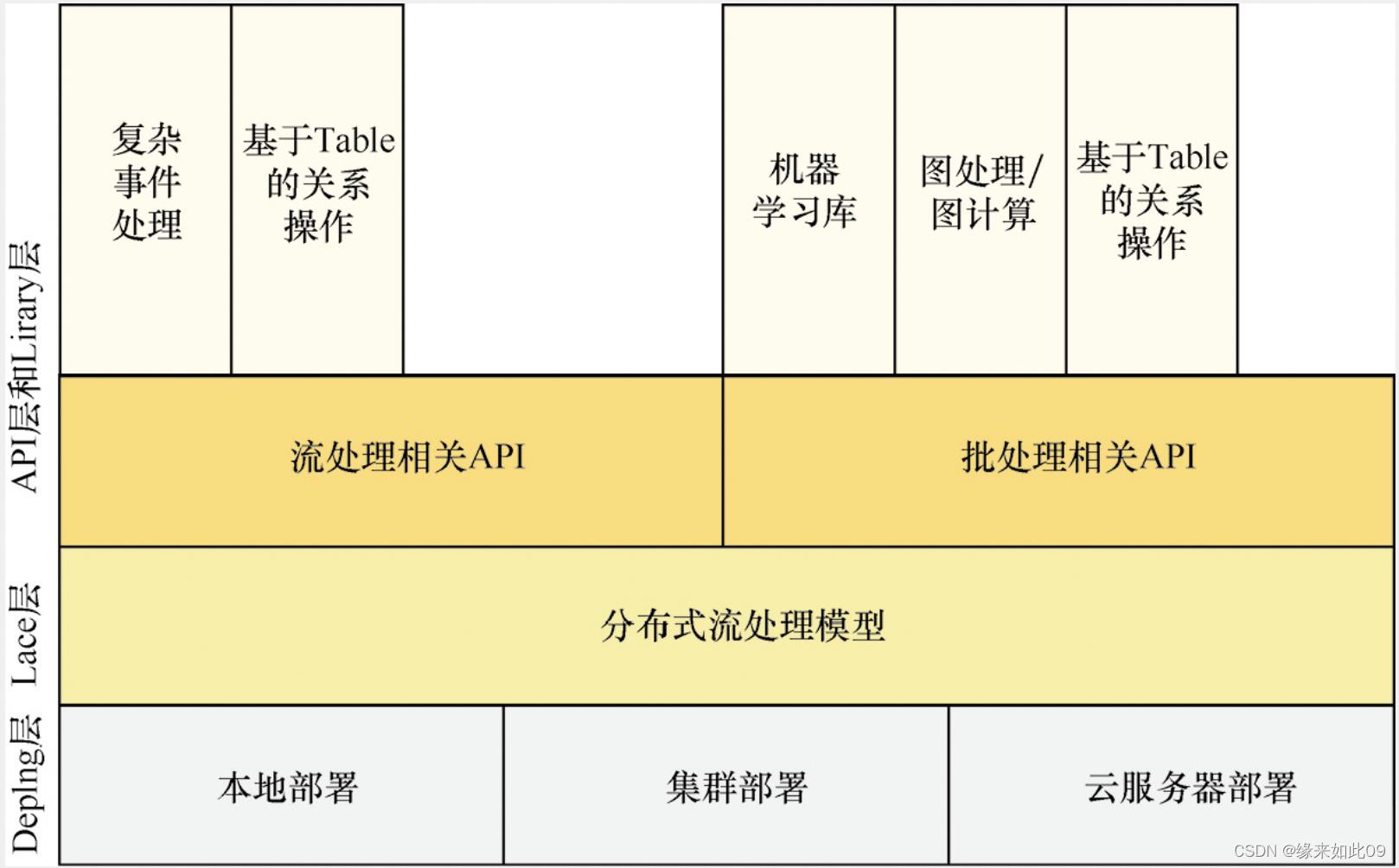
flink分为四层架构,包括:应用层、API层、运行时层和物理层。
-
Deploy层:该层主要涉及Flink的部署模式,Flink支持多种部署模式——本地、集群(Standalone/YARN)和云服务器(GCE/EC2)
-
运行时层(lace):负责执行应用程序,包括任务管理、资源管理、状态管理和容错机制等。
-
API层:提供批处理和流处理的API,包括DataSet API、DataStream API和Table API等。
-
library层:该层也被称为Flink应用框架层,根据API层的划分,在API层之上构建的满足特定应用的实现计算框架,也分别对应于面向流处理和面向批处理两类。面向流处理支持CEP(复杂事件处理)、基于SQL-like的操作(基于Table的关系操作);面向批处理支持FlinkML(机器学习库)、Gelly(图处理)、Table 操作。
四、flink的基本组件:
Flink中提供了3个组件,包括DataSource、Transformation和DataSink
1.DataSource:表示数据源组件,主要用来接收数据,目前官网提供了readTextFile、socketTextStream、fromCollection以及一些第三方的Source。
2.Transformation:表示算子,主要用来对数据进行处理,可以将数据流转换成另一个数据流或者聚合成一个数据流,转换算子可以将一个数据流转换成另一个数据流,聚合算子则可以将多个数据流聚合成一个数据流。常用的算子有map、filter、flatMap、keyBy、reduce、window等。这些算子可以被组合在一起形成复杂的数据处理任务
3.DataSink:表示输出组件,主要用来把计算的结果输出到其他存储介质中,比如writeAsText以及Kafka、Redis、Elasticsearch等第三方Sink组件。
因此,想要组装一个Flink Job,至少需要这3个组件。
Flink Job=DataSource+Transformation+DataSin
五、与其他流式计算框架对比:
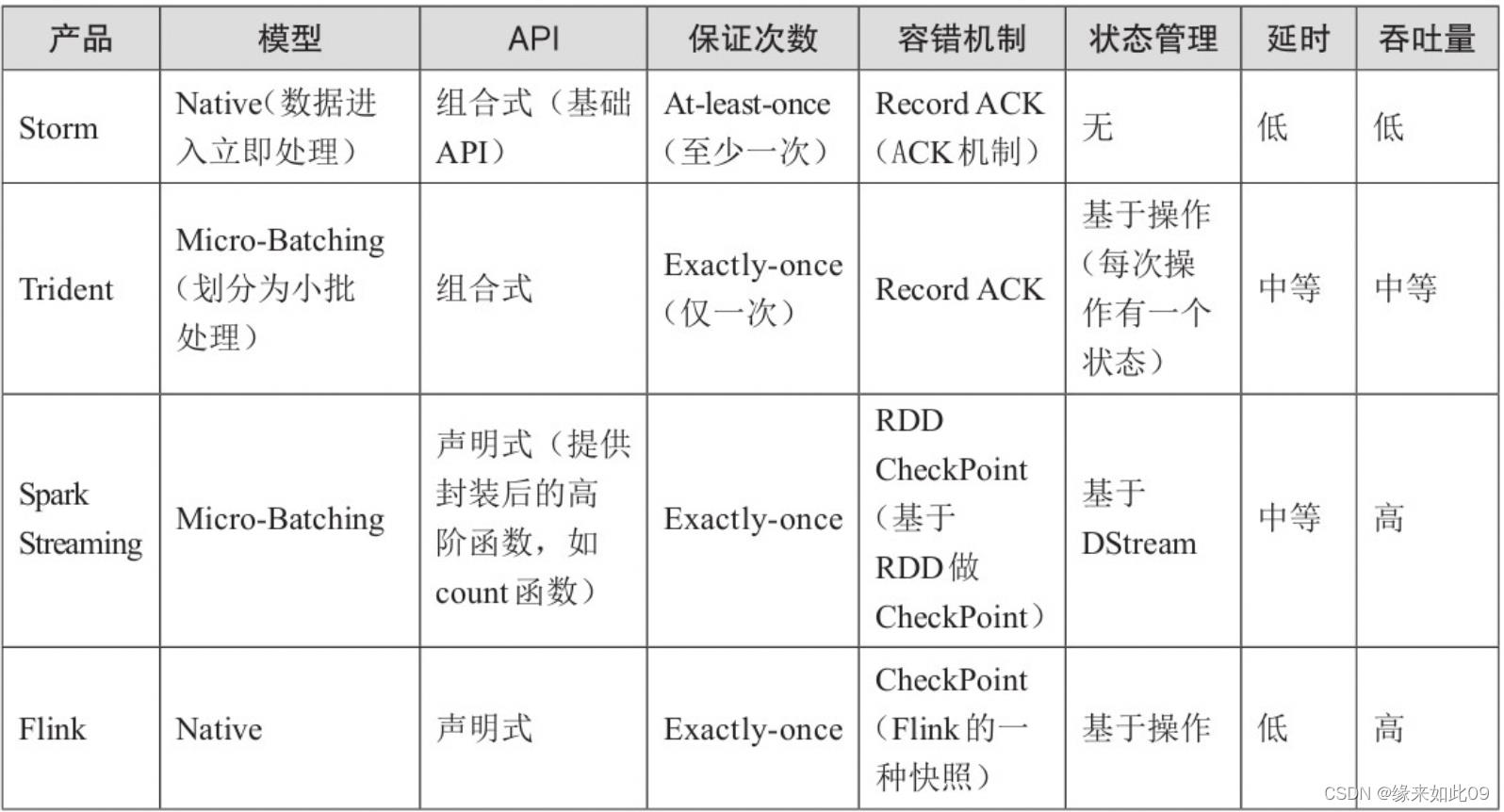 1.Flink的优点:
1.Flink的优点:
1.低延迟和高吞吐量:Flink的批处理和流处理都可以实现低延迟和高吞吐量,而且能够处理大规模数据。
2.内存管理:Flink通过内存管理来优化性能,可以在处理大量数据时减少GC负担。
3.稳定性:Flink的容错机制非常强大,可以处理各种故障和错误。
4.扩展性:Flink可以扩展到数千个节点,以处理大规模数据。
5.丰富的API:Flink提供了丰富的API,包括流处理和批处理API,可以满足各种场景的需求。
2.Flink的缺点:
-
学习曲线较陡峭:Flink相对于其他流式计算框架来说,学习曲线较陡峭,需要花费更多的时间来学习和理解。
-
集群配置较复杂:Flink的集群配置较复杂,需要更多的经验和技术支持。
-
运行环境要求较高:Flink需要较高的硬件要求和运行环境,对于一些小规模的项目来说可能有些过度设计。
3.如何选择实时计算框架
需要关注流数据是否需要进行状态管理,如果是,那么只能在Trident、SparkStreaming和Flink中选择一个。
需要考虑项目对At-least-once(至少一次)或者Exactly-once(仅一次)消息投递模式是否有特殊要求,如果必须要保证仅一次,也不能选择Storm。
对于小型独立的项目,并且需要低延迟的场景,建议使用Storm,这样比较简单。
如果你的项目已经使用了Spark,并且秒级别的实时处理可以满足需求的话,建议使用Spark Streaming
要求消息投递语义为Exactly-once;数据量较大,要求高吞吐低延迟;需要进行状态管理或窗口统计,这时建议使用Flink。
以上是关于Flink计算框架概述的主要内容,如果未能解决你的问题,请参考以下文章