细节拉满Hadoop课程设计项目,使用idea编写基于MapReduce的学生成绩分析系统(附带源码项目文件下载地址)
Posted 扎哇太枣糕
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了细节拉满Hadoop课程设计项目,使用idea编写基于MapReduce的学生成绩分析系统(附带源码项目文件下载地址)相关的知识,希望对你有一定的参考价值。
目录
3.4.2 计算每个学生的总分及平均成绩并进行排序(Sas)
本文只是用来分享代码,如果想要学习MapReduce如何去写的请转至下面的参考博客,该篇博客以“”统计每门课程中相同分数分布情况”为模板,从问题分析入手,一步步创建一个mapper、reducer和main(driver)从而组成一整个的MapReduce。
【手把手 脑把脑】教会你使用idea基于MapReduce的统计数据分析(从问题分析到代码编写)_扎哇太枣糕的博客-CSDN博客
不想跟着博客一步步操作的也可以选择直接下载项目文件,并在自己的idea上运行,数据源依旧是以下的学生成绩。
Hadoop-MapReduce项目代码ZIP压缩包+面向小白(注释详细清晰)-Hadoop文档类资源-CSDN下载
1 数据源(学生成绩.csv)
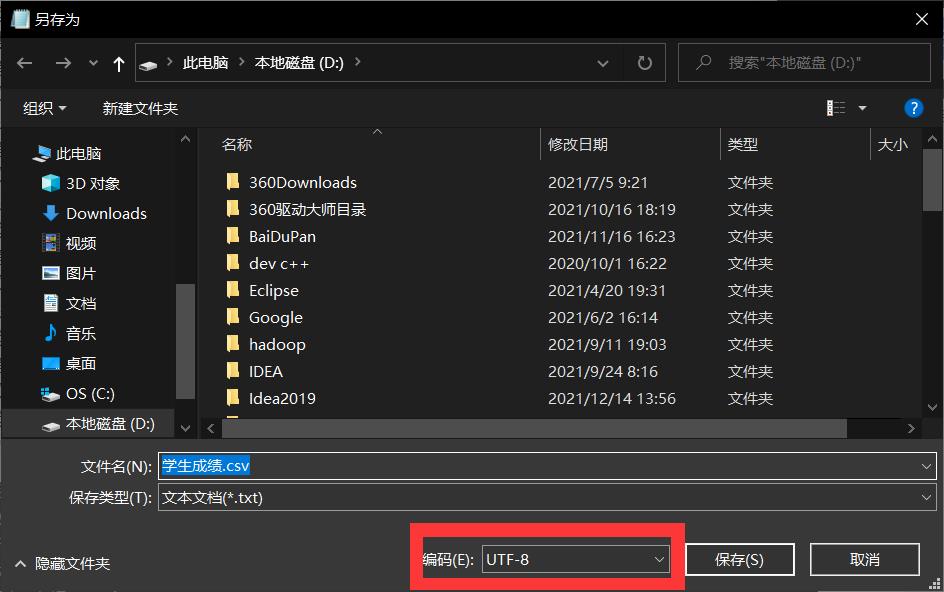
💥 旧坑勿踩:可以复制下面数据,粘贴到txt里把文件拓展格式改为csv,在上传至Hadoop平台之前一定要确保文件的编码方式为utf-8(否则中文会乱码),具体操作为使用记事本打开学生成绩.csv文件,看右下角的编码方式,如果不是utf-8则可以将文件另存为时修改其编码方式。
💥一定一定一定不要为了元数据的好看就在第一行为数据加字段名,看是好看了,到时候运行不出来结果就很难受,不要问我怎么知道的,一个下午的血淋淋的教训。
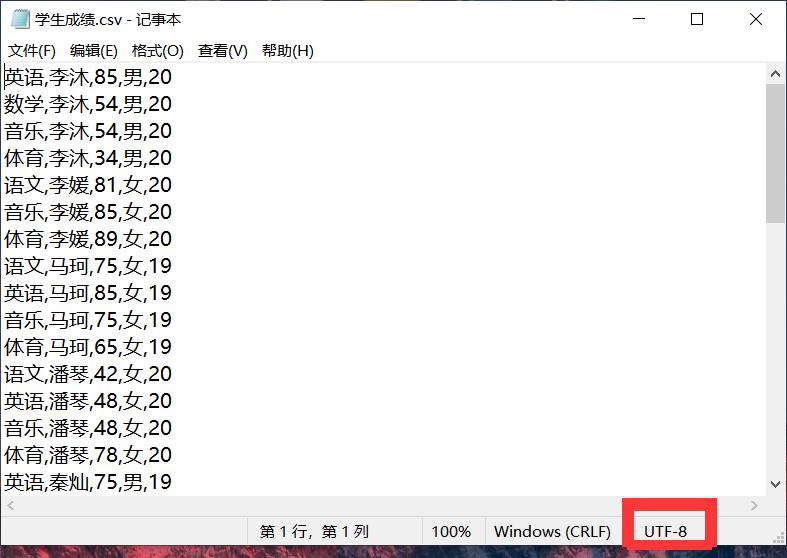
英语,李沐,85,男,20
数学,李沐,54,男,20
音乐,李沐,54,男,20
体育,李沐,34,男,20
语文,李媛,81,女,20
音乐,李媛,85,女,20
体育,李媛,89,女,20
语文,马珂,75,女,19
英语,马珂,85,女,19
音乐,马珂,75,女,19
体育,马珂,65,女,19
语文,潘琴,42,女,20
英语,潘琴,48,女,20
音乐,潘琴,48,女,20
体育,潘琴,78,女,20
英语,秦灿,75,男,19
数学,秦灿,89,男,19
音乐,秦灿,85,男,19
体育,秦灿,99,男,19
语文,王靓,85,女,21
英语,王靓,85,女,21
数学,王靓,48,女,21
音乐,王靓,86,女,21
音乐,王靓,85,女,21
体育,王靓,96,女,21
体育,王靓,87,女,21
英语,吴起,85,男,20
数学,吴起,85,男,20
英语,张翔,96,男,20
数学,张翔,85,男,20
音乐,张翔,85,男,20
体育,张翔,87,男,20
语文,郑虎,85,男,20
数学,郑虎,85,男,20
音乐,郑虎,88,男,20
体育,郑虎,68,男,20
语文,周伟,76,男,19
英语,周伟,85,男,19
数学,周伟,76,男,19
音乐,周伟,99,男,19
体育,周伟,90,男,19
数学,朱鸿,90,男,21
音乐,朱鸿,80,男,21
体育,朱鸿,81,男,21
2 hadoop平台上传数据源
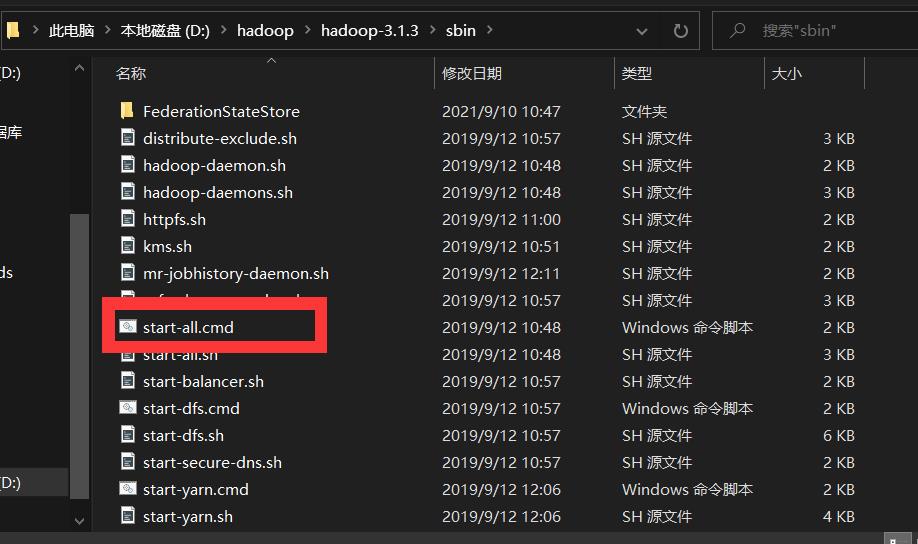
Hadoop平台上传数据,其实也可以理解为向HDFS里存储数据,前提是Hadoop的集群必须搭建好,这里就默认大家都已经搭建完成并可以正常运行。这里可以如下图双击hadoop下的sbin目录下的start-all.cmd启动集群。
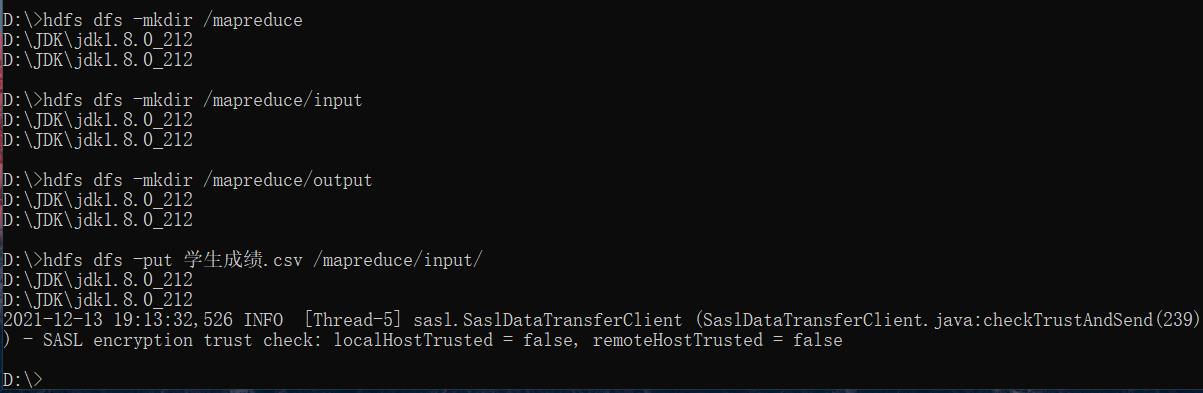
集群启动成功后,在源数据的存储路径下打开DOS窗口,可以在该目录的文件路径框下输入cmd打开,或者直接在桌面打开DOS窗口再cd进源数据的存储路径。按照下图使用命令创建目录并将源数据(学生成绩.csv)上传至hadoop平台
3 idea代码
3.1 工程框架
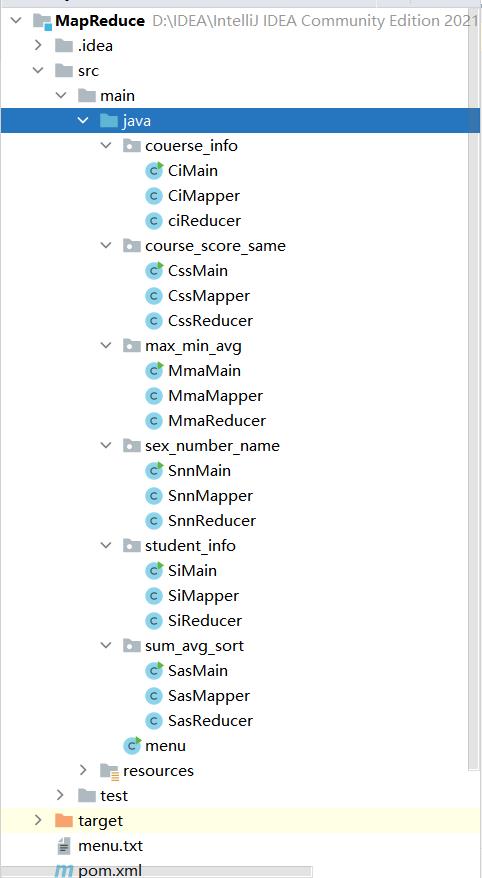
新建一个maven工程,建立如下工程框架 :
3.2 导入依赖
MapReduce需要四个核心依赖,hadoop-client、hadoop-hdfs、hadoop-common、hadoop-mapreduce-client-core,依赖复制粘贴进自己的项目一定要记得刷新依赖,避免依赖还没导入成功就运行导致报错。

<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.3</version>
</dependency>
</dependencies>3.3 系统主入口(menu)
//这里的导包是完成跨package调用其它包里的类
import couerse_info.CiMain;
import course_score_same.CssMain;
import max_min_avg.MmaMain;
import sex_number_name.SnnMain;
import student_info.SiMain;
import sum_avg_sort.SasMain;
import java.lang.reflect.Method;
import java.util.Scanner;
public class menu
public static void main(String[] args)
try
Scanner scanner = new Scanner(System.in);
while(true)
System.out.println("=========基于MapReduce的学生成绩分析=========");
System.out.println("1、计算每门成绩的最高分、最低分、平均分");
System.out.println("2、计算每个学生的总分及平均成绩并进行排序");
System.out.println("3、统计所有学生的信息");
System.out.println("4、统计每门课程中相同分数分布情况");
System.out.println("5、统计各性别的人数及他们的姓名");
System.out.println("6、统计每门课程信息");
System.out.println("7、退出");
System.out.print("请输入你想要选择的功能:");
int option = scanner.nextInt();
Method method = null;
switch(option)
case 1:
method = MmaMain.class.getMethod("main", String[].class);
method.invoke(null, (Object) new String[] );
break;
case 2:
method = SasMain.class.getMethod("main", String[].class);
method.invoke(null, (Object) new String[] );
break;
case 3:
method = SiMain.class.getMethod("main", String[].class);
method.invoke(null, (Object) new String[] );
break;
case 4:
method = CssMain.class.getMethod("main", String[].class);
method.invoke(null, (Object) new String[] );
break;
case 5:
method = SnnMain.class.getMethod("main", String[].class);
method.invoke(null, (Object) new String[] );
break;
case 6:
method = CiMain.class.getMethod("main", String[].class);
method.invoke(null, (Object) new String[] );
break;
case 7:
System.exit(1);
break;
default:
System.out.println("输入正确的功能按键!!");
break;
catch (Exception e)
e.printStackTrace();
3.4 六个mapreduce
3.4.1 计算每门成绩的最高分、最低分、平均分(Mma)
package max_min_avg;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/*
stu[0]:课程名称
stu[1]:学生姓名
stu[2]:成绩
stu[3]:性别
stu[4]:年龄
该功能实现的计算出每门课程中的最高分、最低分、平均分
*/
public class MmaMapper extends Mapper<LongWritable,Text,Text,Text>
@Override
protected void map(LongWritable key1,Text value1,Context context)throws IOException,InterruptedException
//将文件的每一行传递过来,使用split分割后利用字符数组进行接收
String[] splits = value1.toString().split(",");
//向Reducer传递参数-> Key:课程 Value:成绩
context.write(new Text(splits[0]),new Text(splits[2]));
package max_min_avg;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class MmaReducer extends Reducer<Text, Text,Text, Text>
@Override
protected void reduce(Text key,Iterable<Text> value,Context context)throws IOException,InterruptedException
//Arraylist集合储存所有的成绩数据,借用collections的方法求最大值最小值
List<Integer> list = new ArrayList<>();
for(Text v: value)
list.add(Integer.valueOf(v.toString()));
//求max及min
int maxScore = Collections.max(list);
int minScore = Collections.min(list);
// 求平均成绩
int sum = 0;
for(int score: list)
sum += score;
double avg = sum / list.size();
System.out.println("*****************************************");
String result = "的最高分:"+maxScore+" 最低分:"+minScore+" 平均分:"+avg;
System.out.println(key.toString()+result);
context.write(key,new Text(result));
package max_min_avg;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class MmaMain
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException, URISyntaxException
//创建job和“统计相同课程相同分数的人数”任务入口
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(MmaMain.class);
//设置Mapper和Reducer的入口
job.setMapperClass(MmaMapper.class);
job.setReducerClass(MmaReducer.class);
//设置Mapper的输入输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//设置Reducer的输入输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//指定输入输出路径
String inputPath = "hdfs://localhost:9000/mapreduce/input/学生成绩.csv";
String outputPath = "hdfs://localhost:9000/mapreduce/output/最大值最小值平均值.txt";
FileInputFormat.setInputPaths(job,new Path(inputPath));
FileOutputFormat.setOutputPath(job,new Path(outputPath));
//输出路径存在的话就删除,不然就只能手动删除,否则会报该文件已存在的异常
FileSystem fileSystem = FileSystem.get(new URI(outputPath), conf);
if (fileSystem.exists(new Path(outputPath)))
fileSystem.delete(new Path(outputPath), true);
//执行job
job.waitForCompletion(true);
3.4.2 计算每个学生的总分及平均成绩并进行排序(Sas)
package sum_avg_sort;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/*
stu[0]:课程名称
stu[1]:学生姓名
stu[2]:成绩
stu[3]:性别
stu[4]:年龄
该功能实现:统计每个学生总分平均分并对成绩进行排序
*/
public class SasMapper extends Mapper<LongWritable, Text,Text,Text>
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException
//将文件的每一行传递过来,使用split分割后利用字符数组进行接收
String[] stu = value.toString().split(",");
//向Reducer传递参数-> Key:学生姓名 Value:成绩
context.write(new Text(stu[1]),new Text(stu[2]));
package sum_avg_sort;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class SasReducer extends Reducer<Text,Text,Text,Text>
@Override
protected void reduce(Text key, Iterable<Text> values,Context context) throws IOException, InterruptedException
System.out.println("*********************************************************************");
//定义一个ArrayList集合接收该学生的各项成绩
List<Integer> scores = new ArrayList<>();
for(Text value:values)
scores.add(Integer.valueOf(value.toString()));
//对该学生的成绩进行求总分、平均分
int num = 0, sum = 0;
for(Integer score:scores)
sum = sum + score.intValue();
num = num + 1;
float avg = sum / num;
//成绩排序
Collections.sort(scores);
//使用一个字符串拼接排好序的所有成绩
String sort = "的总分:"+sum+" 平均分:"+avg+" 该生的成绩从低到高排序是:";
for(Integer score:scores)
sort = sort + score + " ";
System.out.println(key.toString()+sort);
//输出
context.write(key,new Text(sort));
package sum_avg_sort;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class SasMain
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException, URISyntaxException
//创建一个job和任务的入口
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(SasMain.class);
//设置mapper和reducer的入口
job.setMapperClass(SasMapper.class);
job.setReducerClass(SasReducer.class);
//设置mapper输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//设置reducer的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//指定输入输出路径
String inputPath = "hdfs://localhost:9000/mapreduce/input/学生成绩.csv";
String outputPath = "hdfs://localhost:9000/mapreduce/output/每个学生总分平均分排序.txt";
FileInputFormat.setInputPaths(job,new Path(inputPath));
FileOutputFormat.setOutputPath(job,new Path(outputPath));
//输出路径存在的话就删除,不然就只能手动删除,否则会报该文件已存在的异常
FileSystem fileSystem = FileSystem.get(new URI(outputPath), conf);
if (fileSystem.exists(new Path(outputPath)))
fileSystem.delete(new Path(outputPath), true);
//执行job
job.waitForCompletion(true);
3.4.3 统计所有学生的信息(Si)
package student_info;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/*
stu[0]:课程名称
stu[1]:学生姓名
stu[2]:成绩
stu[3]:性别
stu[4]:年龄
该功能实现:统计所有学生课程考试信息
*/
public class SiMapper extends Mapper<LongWritable,Text,Text,Text>
@Override
protected void map(LongWritable Key1, Text value1,Context context) throws IOException, InterruptedException
//将文件的每一行传递过来,使用split分割后利用字符数组进行接收
String[] splits= value1.toString().split(",");
//拼接姓名+性别+年龄
String name = splits[1];
String sex = splits[3];
String age = splits[4];
String stu_info = name+"-"+sex+"-"+age;
//拼接课程+成绩
String course = splits[0];
String score = splits[2];
String course_info = course+"-"+score;
//向Reducer传递参数-> Key:姓名+性别+年龄 Value:课程+成绩
context.write(new Text(stu_info),new Text(course_info));
package student_info;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class SiReducer extends Reducer<Text, Text,Text, Text>
@Override
protected void reduce(Text key,Iterable<Text> values,Context context)throws IOException,InterruptedException
//拼接学生各科考试成绩信息
String scoreInfo = "";
for(Text value:values)
scoreInfo = scoreInfo + value+" ";
System.out.println("********************************************************");
System.out.println(key.toString()+"\\n"+scoreInfo);
context.write(key,new Text(scoreInfo));
package student_info;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class SiMain
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException, URISyntaxException
//创建job和“统计相同课程相同分数的人数”任务入口
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(SiMain.class);
//设置Mapper和Reducer的入口
job.setMapperClass(SiMapper.class);
job.setReducerClass(SiReducer.class);
//设置Mapper的输入输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//设置Reducer的输入输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//指定输入输出路径
String inputPath = "hdfs://localhost:9000/mapreduce/input/学生成绩.csv";
String outputPath = "hdfs://localhost:9000/mapreduce/output/学生信息.txt";
FileInputFormat.setInputPaths(job,new Path(inputPath));
FileOutputFormat.setOutputPath(job,new Path(outputPath));
//输出路径存在的话就删除,不然就只能手动删除,否则会报该文件已存在的异常
FileSystem fileSystem = FileSystem.get(new URI(outputPath), conf);
if (fileSystem.exists(new Path(outputPath)))
fileSystem.delete(new Path(outputPath), true);
//执行job
job.waitForCompletion(true);
3.4.4 统计每门课程中相同分数分布情况(Css)
package course_score_same;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/*
stu[0]:课程名称
stu[1]:学生姓名
stu[2]:成绩
stu[3]:性别
stu[4]:年龄
该功能实现:统计该课程中成绩相同的学生姓名
*/
public class CssMapper extends Mapper<LongWritable, Text,Text,Text>
@Override
protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException
//将文件的每一行传递过来,使用split分割后利用字符数组进行接收
String[] stu = value.toString().split(",");
//拼接字符串:课程和成绩
String sc = stu[0]+"\\t"+stu[2];
//向Reducer传递参数-> Key:课程+成绩 Value:学生名
context.write(new Text(sc),new Text(stu[1]));
package course_score_same;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class CssReducer extends Reducer <Text,Text,Text,Text>
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException
//创建StringBuffer用来接收该课程中成绩相同的学生的姓名
StringBuffer sb = new StringBuffer();
//num变量用来计数
int num = 0;
//遍历values参数,将所有的value拼接进sb,并统计学生数量
for(Text value:values)
sb.append(value.toString()).append(",");
num++;
//如果num=1,则表明该课程的这个成绩只有一个学生,否则就输出
if(num>1)
String names = "一共有" + num + "名学生,他们的名字是:" +sb.toString();
System.out.println("*************************************************");
System.out.println(key.toString() + names);
context.write(key,new Text(names));
package course_score_same;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class CssMain
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException, URISyntaxException
//创建job和“统计相同课程相同分数的人数”任务入口
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(CssMain.class);
//设置Mapper和Reducer的入口
job.setMapperClass(CssMapper.class);
job.setReducerClass(CssReducer.class);
//设置Mapper的输入输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//设置Reducer的输入输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//指定输入输出路径
String inputPath = "hdfs://localhost:9000/mapreduce/input/学生成绩.csv";
String outputPath = "hdfs://localhost:9000/mapreduce/output/该课程中成绩相同的学生姓名.txt";
FileInputFormat.setInputPaths(job,new Path(inputPath));
FileOutputFormat.setOutputPath(job,new Path(outputPath));
//输出路径存在的话就删除,不然就只能手动删除,否则会报该文件已存在的异常
FileSystem fileSystem = FileSystem.get(new URI(outputPath), conf);
if (fileSystem.exists(new Path(outputPath)))
fileSystem.delete(new Path(outputPath), true);
//执行job
job.waitForCompletion(true);
3.4.5 统计各性别的人数及他们的姓名(Snn)
package sex_number_name;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/*
stu[0]:课程名称
stu[1]:学生姓名
stu[2]:成绩
stu[3]:性别
stu[4]:年龄
该功能实现:各性别人数及他们的姓名
*/
public class SnnMapper extends Mapper<LongWritable, Text,Text,Text>
@Override
protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException
//将文件的每一行传递过来,使用split分割后利用字符数组进行接收
String[] stu = value.toString().split(",");
//向Reducer传递参数-> Key:性别 Value:姓名
context.write(new Text(stu[3]),new Text(stu[1]));
package sex_number_name;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
public class SnnReducer extends Reducer<Text,Text,Text,Text>
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException
//创建集合来去除重复值(HashSet不允许重复值的存在,故可用来去重)
List<String> names= new ArrayList<>();
for (Text value:values)
names.add(value.toString());
HashSet<String> singleNames = new HashSet(names);
//创建StringBuffer用来接收同性别学生的姓名
StringBuffer sb = new StringBuffer();
//拼接学生姓名以及统计人数
int num = 0;
for(String singleName:singleNames)
sb.append(singleName.toString()).append(",");
num++;
//输出
String result = "生一共有" + num + "名,他们的名字是:" +sb.toString();
System.out.println("********************************************");
System.out.println(key.toString() + result);
context.write(key,new Text(result));
package sex_number_name;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class SnnMain
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException, URISyntaxException
//创建job和“统计相同课程相同分数的人数”任务入口
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(SnnMain.class);
//设置Mapper和Reducer的入口
job.setMapperClass(SnnMapper.class);
job.setReducerClass(SnnReducer.class);
//设置Mapper的输入输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//设置Reducer的输入输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//指定输入输出路径
String inputPath = "hdfs://localhost:9000/mapreduce/input/学生成绩.csv";
String outputPath = "hdfs://localhost:9000/mapreduce/output/各性别人数及他们的姓名.txt";
FileInputFormat.setInputPaths(job,new Path(inputPath));
FileOutputFormat.setOutputPath(job,new Path(outputPath));
//输出路径存在的话就删除,不然就只能手动删除,否则会报该文件已存在的异常
FileSystem fileSystem = FileSystem.get(new URI(outputPath), conf);
if (fileSystem.exists(new Path(outputPath)))
fileSystem.delete(new Path(outputPath), true);
//执行job
job.waitForCompletion(true);
3.4.6 统计每门课程信息(Ci)
package couerse_info;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/*
stu[0]:课程名称
stu[1]:学生姓名
stu[2]:成绩
stu[3]:性别
stu[4]:年龄
该功能实现的是:通过指定信息查找学生课程考试信息
*/
public class CiMapper extends Mapper<LongWritable,Text,Text,Text>
@Override
protected void map(LongWritable Key1, Text value1,Context context) throws IOException, InterruptedException
//将文件的每一行传递过来,使用split分割后利用字符数组进行接收
String[] splits= value1.toString().split(",");
//拼接字符串:学生名和成绩
String course = splits[0];
String name = splits[1];
String score = splits[2];
String course_info = name + ":" + score;
//向Reducer传递参数-> Key:课程 Value:学生名+成绩
context.write(new Text(course),new Text(course_info));
package couerse_info;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class ciReducer extends Reducer<Text, Text,Text, Text>
@Override
protected void reduce(Text key,Iterable<Text> values,Context context)throws IOException,InterruptedException
//拼接课程的学生姓名和成绩
String courseInfo = "\\n";
for(Text Info:values)
courseInfo = courseInfo + Info + " ";
System.out.println(key.toString()+":"+courseInfo);
System.out.println("***********************************************************************************************************************");
context.write(key,new Text(courseInfo));
package couerse_info;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class CiMain
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException, URISyntaxException
//创建job和“统计相同课程相同分数的人数”任务入口
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(CiMain.class);
//设置Mapper和Reducer的入口
job.setMapperClass(CiMapper.class);
job.setReducerClass(ciReducer.class);
//设置Mapper的输入输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//设置Reducer的输入输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//指定输入输出路径
String inputPath = "hdfs://localhost:9000/mapreduce/input/学生成绩.csv";
String outputPath = "hdfs://localhost:9000/mapreduce/output/课程信息.txt";
FileInputFormat.setInputPaths(job,new Path(inputPath));
FileOutputFormat.setOutputPath(job,new Path(outputPath));
//输出路径存在的话就删除,不然就只能手动删除,否则会报该文件已存在的异常
FileSystem fileSystem = FileSystem.get(new URI(outputPath), conf);
if (fileSystem.exists(new Path(outputPath)))
fileSystem.delete(new Path(outputPath), true);
//执行job
job.waitForCompletion(true);
4 运行

5 改进
至此一个完整的基于mapreduce的学生成绩分析系统就算是基本完成了,当然完成的功能还是十分的基础。如果想要追求进阶操作,可以尝试使用多重处理,即把一个甚至多个mapreduce处理得到的结果当做是一个数据集,对该结果继续进行mapreduce分析。如果有意愿还可以再进一步分析,反正越分析越详细,这可能就是你课设比别人突出的部分,是一个大大的加分项。
以上是关于细节拉满Hadoop课程设计项目,使用idea编写基于MapReduce的学生成绩分析系统(附带源码项目文件下载地址)的主要内容,如果未能解决你的问题,请参考以下文章