HashMap的put()方法的再理解
Posted 小写丶H
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HashMap的put()方法的再理解相关的知识,希望对你有一定的参考价值。
一.创建
这个相信大家也都知道怎么使用。今天就深入理解一下这里的底层原理。
首先HashMap在java中,创建出来是一个数组,然后数组上存放的元素是一个链表。
二.put()
进入底层源码看一下。

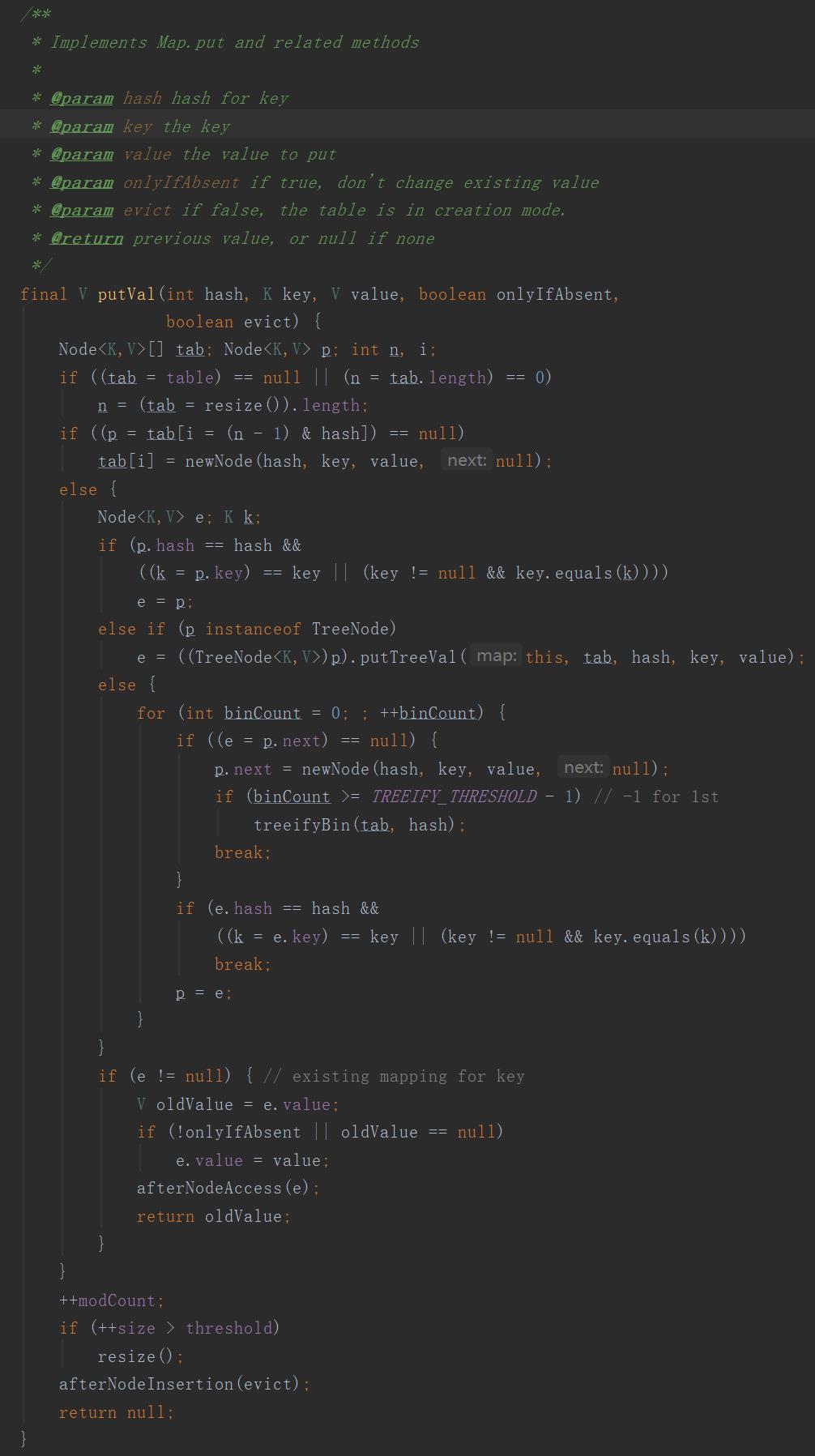
HashMap,在添加第一个元素的时候创建一个默认2的幂的数组。也就是16,这个参数也可以你自己设置。但是一定是2的幂,假如new HashMap(30),那么只会创建一个32大小的数组。

计算出元素的hashcode,放到指定位置,看数组中是否有元素,无元素直接放到数组元素上,有元素的话则进行(jdk1.8)尾插。
当一个数组元素下的链表长度超过8,就会触发treeifyBin(),

但是必须满足,数组的长度大于64,否则,只是就行resize()扩容,重新hash。
如果满足链表长度大于8,并且数组长度大于64,此时就把链表转换成红黑树(一种比较平衡的二叉搜索树)。
着里再讲一个设计remove()删除元素,当红黑树里的元素被删除到小于8的时候怎么办?其实这里有个过渡,不是8,而是如果红黑树里的元素删除的小于6的时候就会触发收缩检测。

此时就会红黑树收缩回链表了。
三.数组初始化
前面 put里提到过,初始new HashMap() 默认大小是16,可以指定数组大小,但是一定是2的幂。如 new HashMap(30),那么数组的大小就为32了。这个都很好理解。
四.扩容

负载因子 = 添加的元素 / hash表的长度
这个值默认是 0.75 ( jdk1.8)(可以根据实际需求调整,当值越大hash冲突概率就高,查询效率低,节省了空间,反之相反),当超过0.75,就会触发resize(),进行数组的扩容。
以上是关于HashMap的put()方法的再理解的主要内容,如果未能解决你的问题,请参考以下文章