Oracle数据到MaxCompute乱码问题详解
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Oracle数据到MaxCompute乱码问题详解相关的知识,希望对你有一定的参考价值。
简介:集成Oracle数据到MaxCompute,乱码问题分析; 为什么,在oracle数据不乱码,集成到MaxCompute就乱码了? 问题在哪里?
1.1 乱码现象
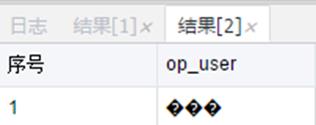
DataWorks的数据离线集成(DataX)集成Oracle数据到MaxCompute的数据有乱码,但是看源库不是乱码,这是什么原因?
现象:【Oracle;工具:plsql-dev】

【MaxCompute;工具:DataWorks】
select OP_USER from test.mdtsb where
uuid='161A45E75BC88040E053441074848040';
1.2 问题分析
使用两个 oracle 函数:
【DUMP; CONVERT; 】
为了避免转码正确是因为刚好乱码的列的真实字符集与操作系统字符集相同而导致显示正常,选择了使用 linux 环境,客户端字符集设置为 UTF8,使用 SQLplus 进行查询分析问题。
1.客户端环境:
SQL> select userenv('language') from dual;
USERENV('LANGUAGE')
----------------------------------------------------
SIMPLIFIED CHINESE_CHINA.AL32UTF8
2.使用 dump 函数把文本对应的编码输出出来:
SQL> select dump(OP_USER,1016) from test.mdtsb where
uuid='161A45E75BC88040E053441074848040' ;
DUMP(OP_USER,1016)
----------------------------------------------------
Typ=1 Len=6CharacterSet=AL32UTF8: c0,ee,be,b0,ea,bb
这个函数输出的信息有三个
- 长度是 6 字节
- 字符集是 AL32UTF8
- 字符编码是 c0,ee,be,b0,ea,bb
通过这些信息,我们猜测原来的字符集可能是 GBK 或者 GB18030、GB2312 这几个字符集的编码。因为三个汉字,如果是 UTF8 的话他们的编码大部分都是一个汉字对应三字节。而 GBK字符集对应的编码是双字节。
3.查看c0,ee,be,b0,ea,bb 对应的 GBK 字符
c0,ee

be,b0

ea,bb

所以,可以认定这个字符编码属于 GBK 类。
4.对应汉子的 GBK 类编码
汉字字符集编码查询;中文字符集编码:GB2312、BIG5、GBK、GB18030、Unicode
李
GB2312 编码:C0EE
BIG5 编码:A7F5
GBK 编码:C0EE
GB18030 编码:C0EE
Unicode 编码:674E
景
GB2312 编码:BEB0
BIG5 编码:B4BA
GBK 编码:BEB0
GB18030 编码:BEB0
Unicode 编码:666F
昊
GB2312 编码:EABB
BIG5 编码:A9FE
GBK 编码:EABB
GB18030 编码:EABB
Unicode 编码:660A
可以看到,这三个汉字可能的编码是:GB2312、GB18030、GBK。
5.使用 convert 函数转换字符串编码为 AL32UTF8
SQL> select convert(OP_USER,'AL32UTF8','ZHS16GBK') from test.mdtsb where
uuid='161A45E75BC88040E053441074848040' ;
CONVERT(OP_USER,' AL32UTF8','ZHS16GBK')
-------------------------------------------------------
李景昊
这个结果验证了我们的猜测,这个字符集应该是 GBK 类的字符集,但是因为 GBK 和 GB18030、GB2312 并不是完全父子集关系,所以,这个只能是其中的一种。只不过 GBK 字符集从当前角度来看,更为常用。
SQL> select convert(OP_USER,'AL32UTF8','ZHS16GBK') from test.mdtsb where
uuid='161A45E75BC88040E053441074848040' ;
CONVERT(OP_USER,' AL32UTF8','ZHS16CGB231280')
-------------------------------------------------------
李景昊
SQL> select convert(OP_USER,'AL32UTF8','ZHS16GBK') from test.mdtsb where
uuid='161A45E75BC88040E053441074848040' ;
CONVERT(OP_USER,' AL32UTF8','ZHS32GB18030')
-------------------------------------------------------
李景昊
6.查询这三个汉字对应的UTF8 的字符串编码
网址:Unicode编码转换,UTF编码转换(UTF-8、UTF-16、UTF-32)
李
Unicode 编码:0000674E
UTF8 编码:E69D8E
UTF16 编码:FEFF674E
UTF32 编码:0000FEFF0000674E
景
Unicode 编码:0000666F
UTF8 编码:E699AF
UTF16 编码:FEFF666F
UTF32 编码:0000FEFF0000666F
昊
Unicode 编码:0000660A
UTF8 编码:E6988A
UTF16 编码:FEFF660A
UTF32 编码:0000FEFF0000660A
所以,如果原来字符串编码是 UTF8,理论上我们通过 dump 函数获取的字符串编码应该为:e6,9d,8e,e6,99,af,e6,98,8a
1.3 问题解决
通过 convert 函数转换:
SQL> select dump(convert(OP_USER,'AL32UTF8','ZHS16GBK'),1016) from test.mdtsb
where uuid='161A45E75BC88040E053441074848040' ;
DUMP(CONVERT(OP_USER,' AL32UTF8','ZHS16GBK'),1016)
-------------------------------------------------------
Typ=1 Len=9CharacterSet=AL32UTF8: e6,9d,8e,e6,99,af,e6,98,8a
这个结果验证了我们之前的查询结果,UTF8 字符集显示的编码应该是:
e6,9d,8e,e6,99,af,e6,98,8a。
结论:
Oracle 数据库存储的该列的实际编码是GBK 类的字符集,因为与客户端环境的字符编码相同,所以,刚好能显示出来。但是因为 Oracle 存储的字符集设置为 UTF8,实际上存储的字符集应该是 UTF8。所以导致标注的编码和实际的编码不一致-乱码。
应对:
在数据同步任务的对应的列上通过测试字符集获取到的真实字符集,使用 convert 函数(convert(OP_USER,'AL32UTF8','ZHS16GBK'))进行转换,转换到 ODPS 后的数据就不会再是乱码。
例如:SELECT convert(KEY1,'ZHS16GBK','UTF8') FROM MATDOC;
【MaxCompute;工具:DataWorks】
select OP_USER from MaxCompute.MDTSB where uuid='161A45E75BC88040E053441074848040';

1.4 目标端识别方法
其实在MaxCompute也有相关的函数可以对字符编码进行分析和转换,只是我们在MaxCompute只能存储一种字符集“UTF-8”,所以,最好是在源端或者在传输过程中转换编码为UTF-8。下面两个函数是MaxCompute的字符编码相关函数。
· ENCODE
命令格式
binary encode(string <str>, string )
命令说明
将str按照charset格式进行编码。
参数说明
str:必填。STRING类型。待重新编码的字符串。
charset:必填。STRING类型。编码格式。取值范围为:UTF-8、UTF-16、UTF-16LE、UTF-16BE、ISO-8859-1、US-ASCII。
返回值说明
返回BINARY类型。任一输入参数为NULL时,返回结果为NULL。
示例
示例1:将字符串abc按照UTF-8格式编码。命令示例如下。
select encode("abc", "UTF-8");
--返回abc。
· IS_ENCODING
命令格式
boolean is_encoding(string <str>, string , string )
命令说明
判断输入的字符串str是否可以从指定的一个字符集from_encoding转为另一个字符集to_encoding。也可以用于判断输入是否为乱码,通常您可以将from_encoding设为UTF-8,to_encoding设为GBK。
参数说明
str:必填。STRING类型。空字符串可以被认为属于任何字符集。
from_encoding、to_encoding:必填。STRING类型,源及目标字符集。
返回值说明
返回BOOLEAN类型。如果str能够成功转换,则返回True,否则返回False。如果任一输入参数为NULL,则返回NULL。
示例
示例1:判断字符测试或測試是否可以从utf-8字符集转为gbk字符集。命令示例如下。
select is_encoding('测试', 'utf-8', 'gbk');
--返回true。
select is_encoding('測試', 'utf-8', 'gbk');
--返回true。
字符串函数 - 云原生大数据计算服务 MaxCompute - 阿里云
1.5 附录
Convert函数

Purpose
CONVERT converts a character string from one character set to another. The datatype of the returned value is VARCHAR2.
- The char argument is the value to be converted. It can be any of the datatypes CHAR, VARCHAR2, NCHAR, NVARCHAR2, CLOB, or NCLOB.
- The dest_char_set argument is the name of the character set to which char is converted.
- The source_char_set argument is the name of the character set in which char is stored in the database. The default value is the database character set.
Both the destination and source character set arguments can be either literals or columns containing the name of the character set.
For complete correspondence in character conversion, it is essential that the destination character set contains a representation of all the characters defined in the source character set. Where a character does not exist in the destination character set, a replacement character appears. Replacement characters can be defined as part of a character set definition.
Examples
The following example illustrates character set conversion by converting a Latin-1 string to ASCII. The result is the same as importing the same string from a WE8ISO8859P1 database to a US7ASCII database.
SELECT CONVERT('Ä Ê Í Ó Ø A B C D E ', 'US7ASCII', 'WE8ISO8859P1')
FROM DUAL;
CONVERT('ÄÊÍÓØABCDE'
---------------------
A E I ? ? A B C D E ?
【'US7ASCII'是当前oracle数据库的字符集,'WE8ISO8859P1'是被转换后的字符集】
Common character sets include:
· US7ASCII: US 7-bit ASCII character set
· WE8DEC: West European 8-bit character set
· F7DEC: DEC French 7-bit character set
· WE8EBCDIC500: IBM West European EBCDIC Code Page 500
· WE8ISO8859P1: ISO 8859-1 West European 8-bit character set
· UTF8: Unicode 4.0 UTF-8 Universal character set, CESU-8 compliant
· AL32UTF8: Unicode 4.0 UTF-8 Universal character set
原文链接
本文为阿里云原创内容,未经允许不得转载。
以上是关于Oracle数据到MaxCompute乱码问题详解的主要内容,如果未能解决你的问题,请参考以下文章