JSON数据从OSS迁移到MaxCompute最佳实践
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JSON数据从OSS迁移到MaxCompute最佳实践相关的知识,希望对你有一定的参考价值。
摘要: 本文为您介绍如何利用DataWorks数据集成将JSON数据从OSS迁移到MaxCompute,并使用MaxCompute内置字符串函数GET_JSON_OBJECT提取JSON信息。
本文为您介绍如何利用DataWorks数据集成将JSON数据从OSS迁移到MaxCompute,并使用MaxCompute内置字符串函数GET_JSON_OBJECT提取JSON信息。
数据上传OSS
将您的JSON文件重命名后缀为TXT文件,并上传到OSS。本文中使用的JSON文件示例如下。
{
"store": {
"book": [
{
"category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{
"category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{
"category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
},
"expensive": 10
}
将applog.txt文件上传到OSS,本文中OSS Bucket位于华东2区。 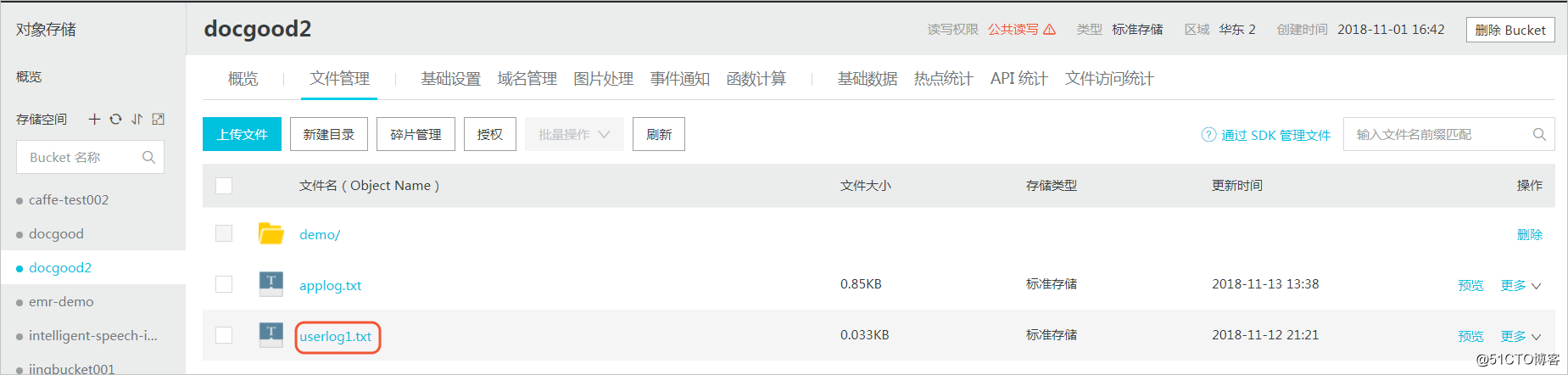
使用DataWorks导入数据到MaxCompute
新增OSS数据源
进入DataWorks数据集成控制台,新增OSS类型数据源。 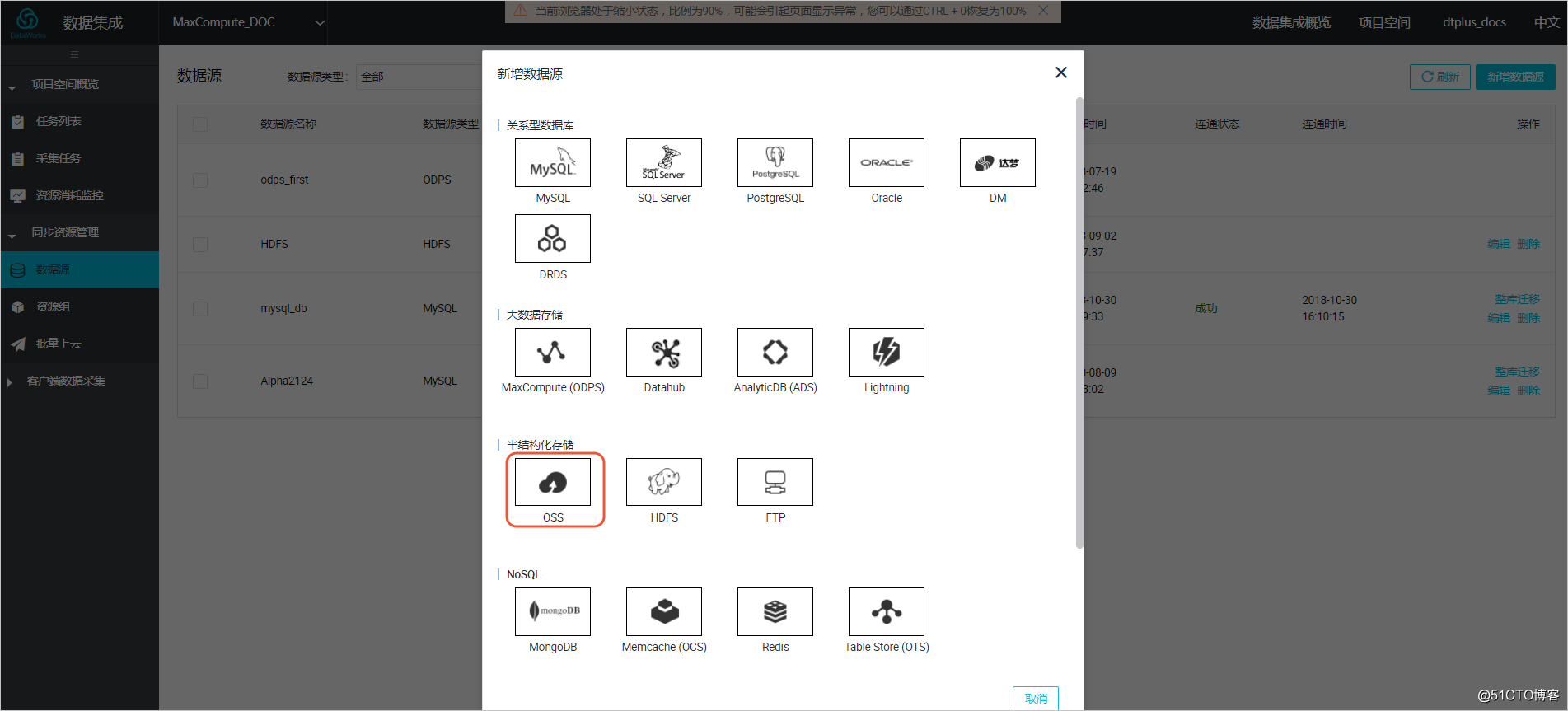
具体参数如下所示,测试数据源连通性通过即可点击完成。Endpoint地址请参见OSS各区域的外网、内网地址,本例中为http://oss-cn-shanghai.aliyuncs.com或 http://oss-cn-shanghai-internal.aliyuncs.com(由于本文中OSS和DataWorks项目处于同一个region中,本文选用后者,通过内网连接)。 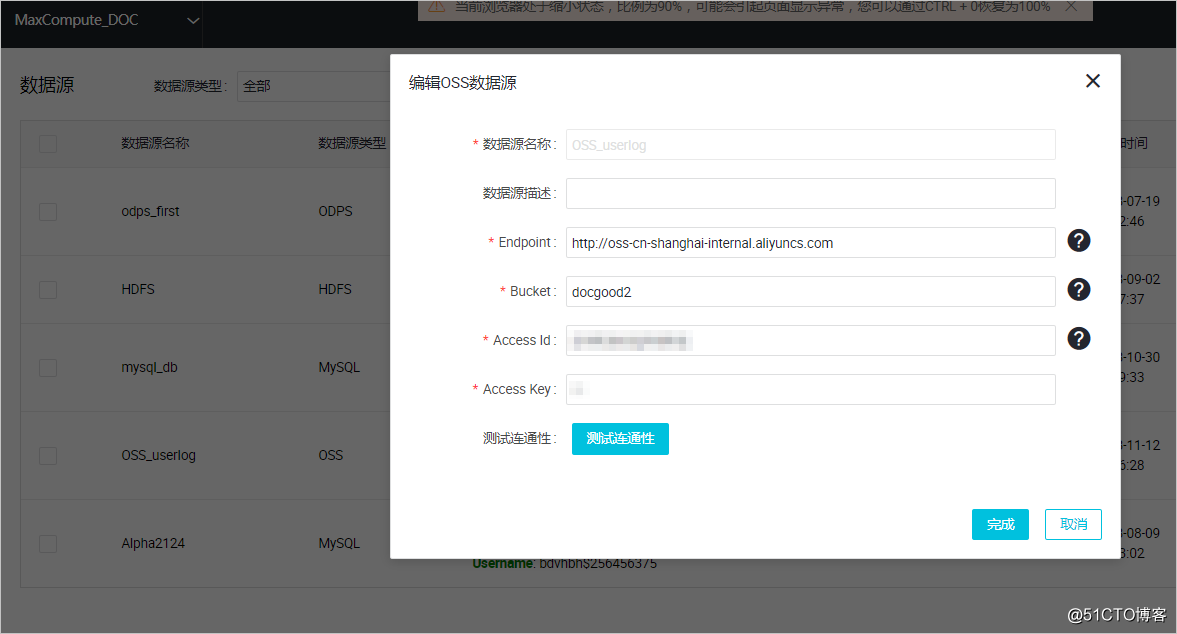
新建数据同步任务
在DataWorks上新建数据同步类型节点。 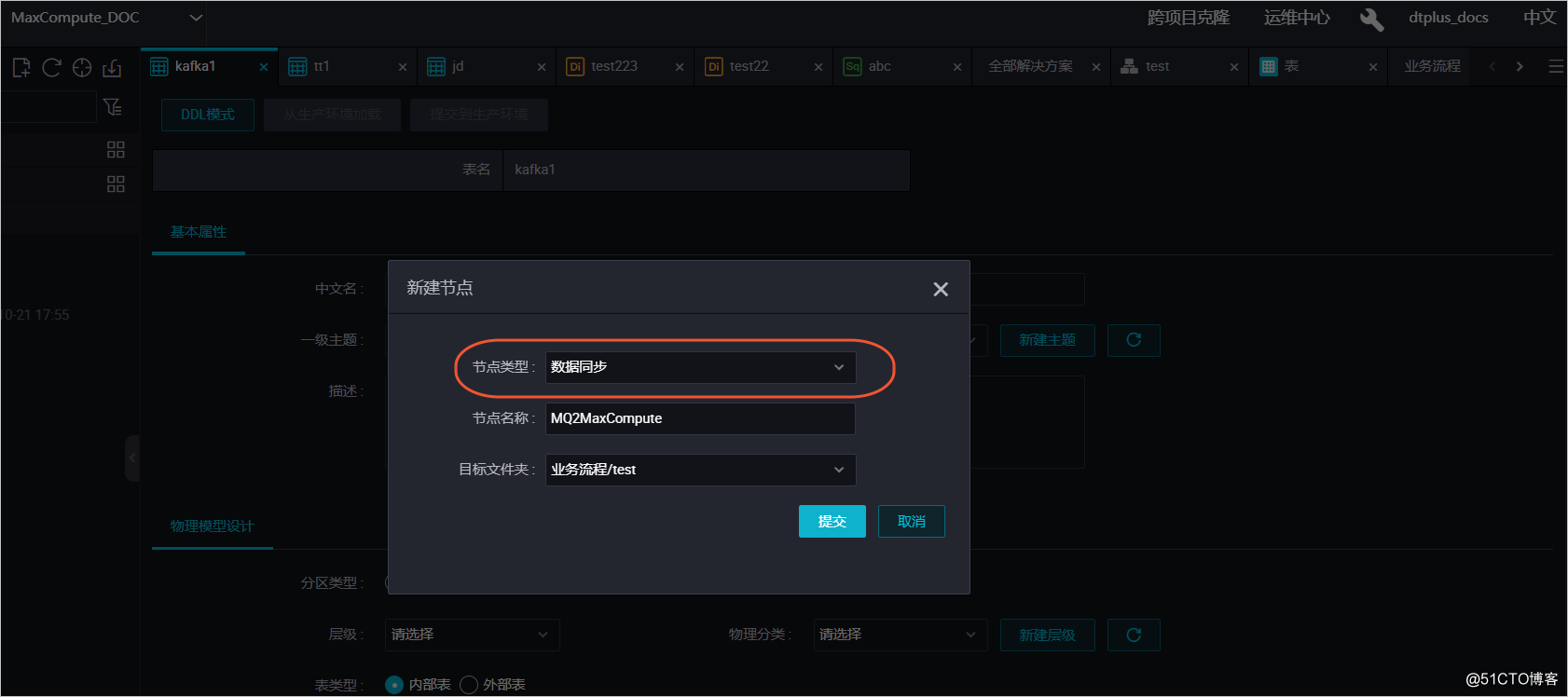
新建的同时,在DataWorks新建一个建表任务,用于存放JSON数据,本例中新建表名为mqdata。 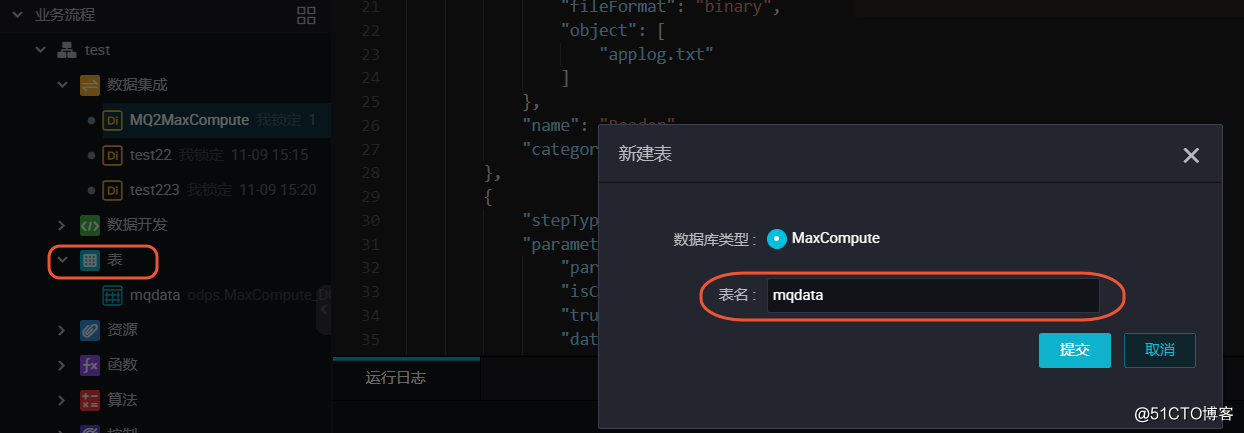
表参数可以通过图形化界面完成。本例中mqdata表仅有一列,类型为string,列名为MQ data。 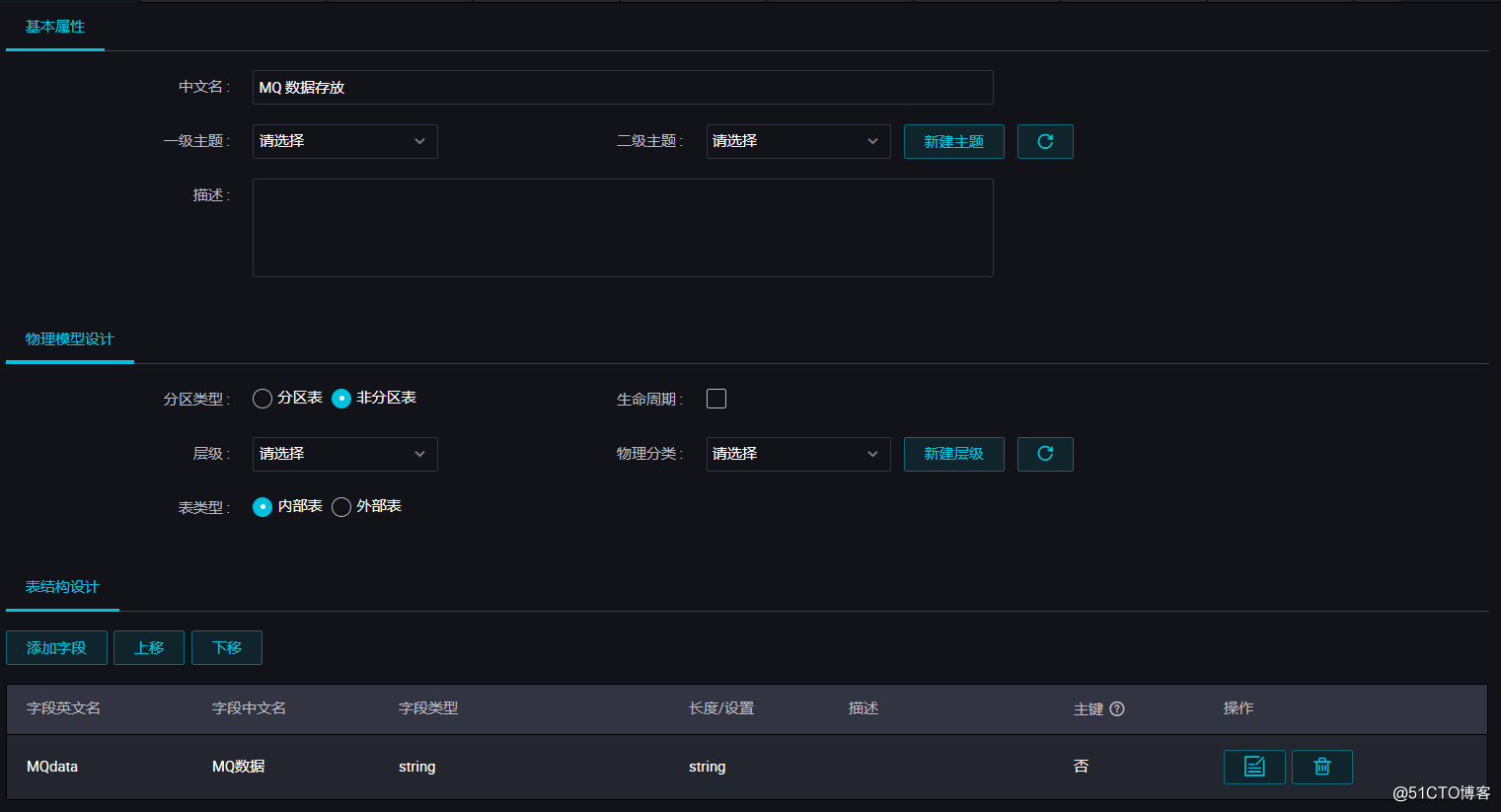
完成上述新建后,您可以在图形化界面配置数据同步任务参数,如下图所示。选择目标数据源名称为odps_first,选择目标表为刚建立的mqdata。数据来源类型为OSS,Object前缀可填写文件路径及名称。列分隔符使用TXT文件中不存在的字符即可,本文中使用 ^(对于OSS中的TXT格式数据源,Dataworks支持多字符分隔符,所以您可以使用例如 %&%#^$$^%这样很难出现的字符作为列分隔符,保证分割为一列)。 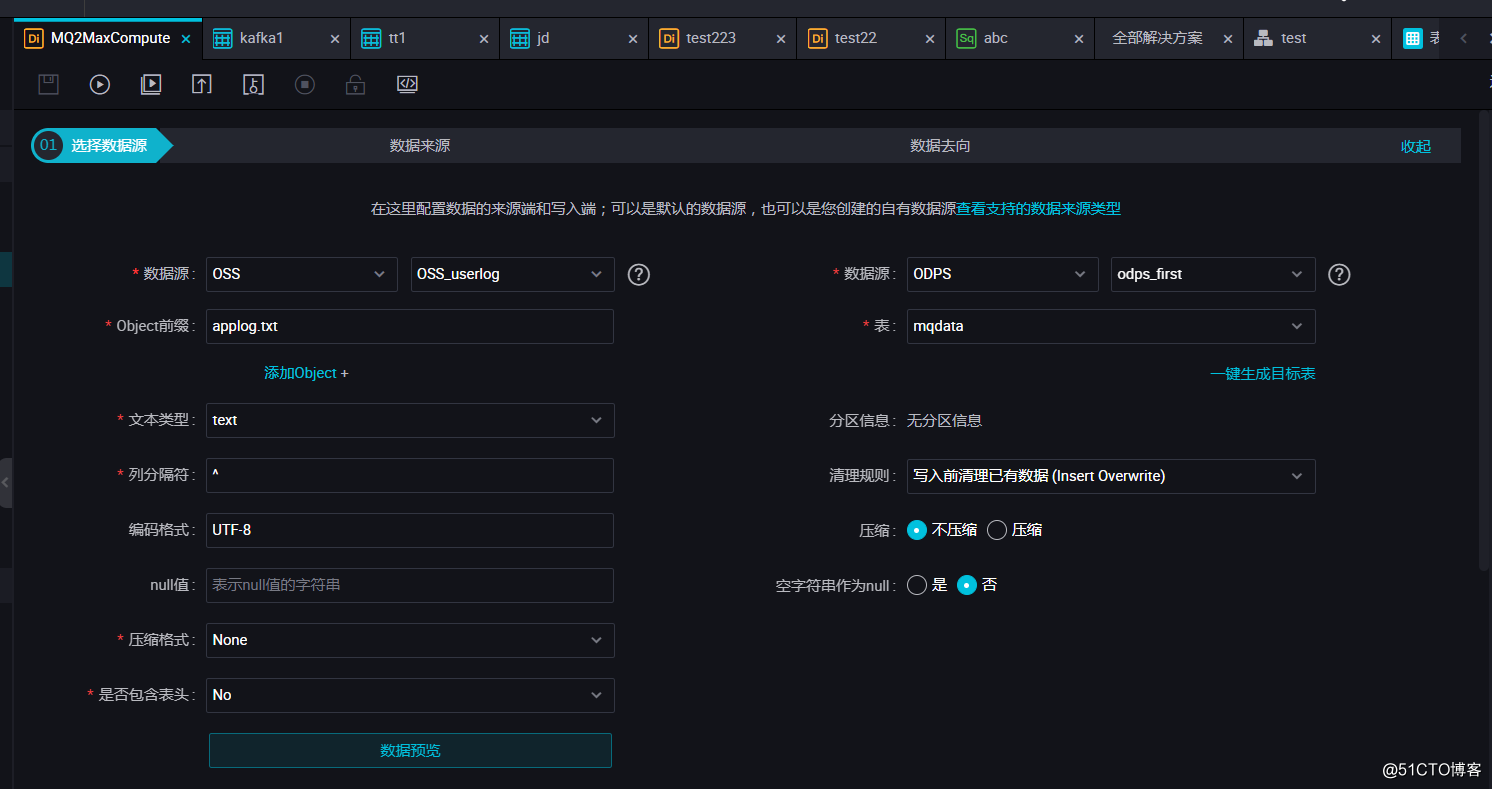
映射方式选择默认的同行映射即可。
154211275531548_zh-CN.png
点击左上方的切换脚本按钮,切换为脚本模式。修改fileFormat参数为: "fileFormat":"binary"。该步骤可以保证OSS中的JSON文件同步到MaxCompute之后存在同一行数据中,即为一个字段。其他参数保持不变,脚本模式代码示例如下。
{
"type": "job",
"steps": [
{
"stepType": "oss",
"parameter": {
"fieldDelimiterOrigin": "^",
"nullFormat": "",
"compress": "",
"datasource": "OSS_userlog",
"column": [
{
"name": 0,
"type": "string",
"index": 0
}
],
"skipHeader": "false",
"encoding": "UTF-8",
"fieldDelimiter": "^",
"fileFormat": "binary",
"object": [
"applog.txt"
]
},
"name": "Reader",
"category": "reader"
},
{
"stepType": "odps",
"parameter": {
"partition": "",
"isCompress": false,
"truncate": true,
"datasource": "odps_first",
"column": [
"mqdata"
],
"emptyAsNull": false,
"table": "mqdata"
},
"name": "Writer",
"category": "writer"
}
],
"version": "2.0",
"order": {
"hops": [
{
"from": "Reader",
"to": "Writer"
}
]
},
"setting": {
"errorLimit": {
"record": ""
},
"speed": {
"concurrent": 2,
"throttle": false,
"dmu": 1
}
}
}
完成上述配置后,点击运行接即可。运行成功日志示例如下所示。 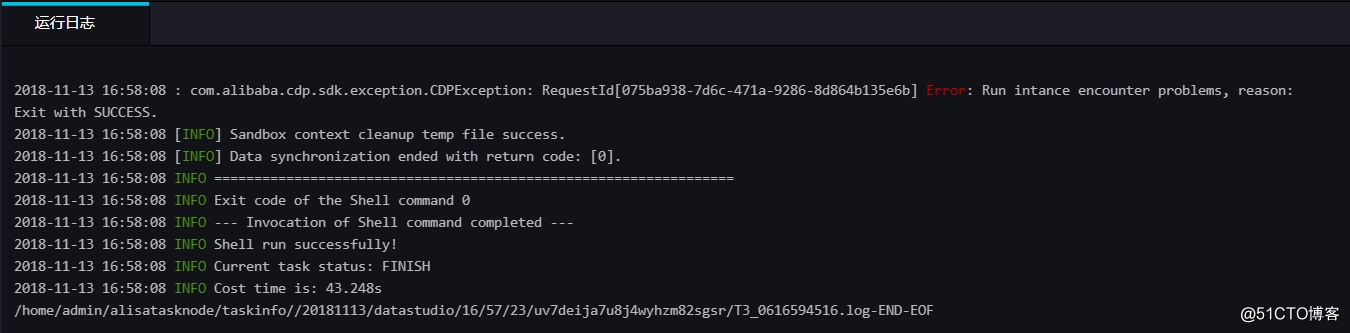
获取JSON字段信息
在您的业务流程中新建一个ODPS SQL节点。 
您可以首先输入 SELECT*from mqdata;语句,查看当前mqdata表中数据。当然这一步及后续步骤,您也可以直接在MaxCompute客户端中输入命令运行。 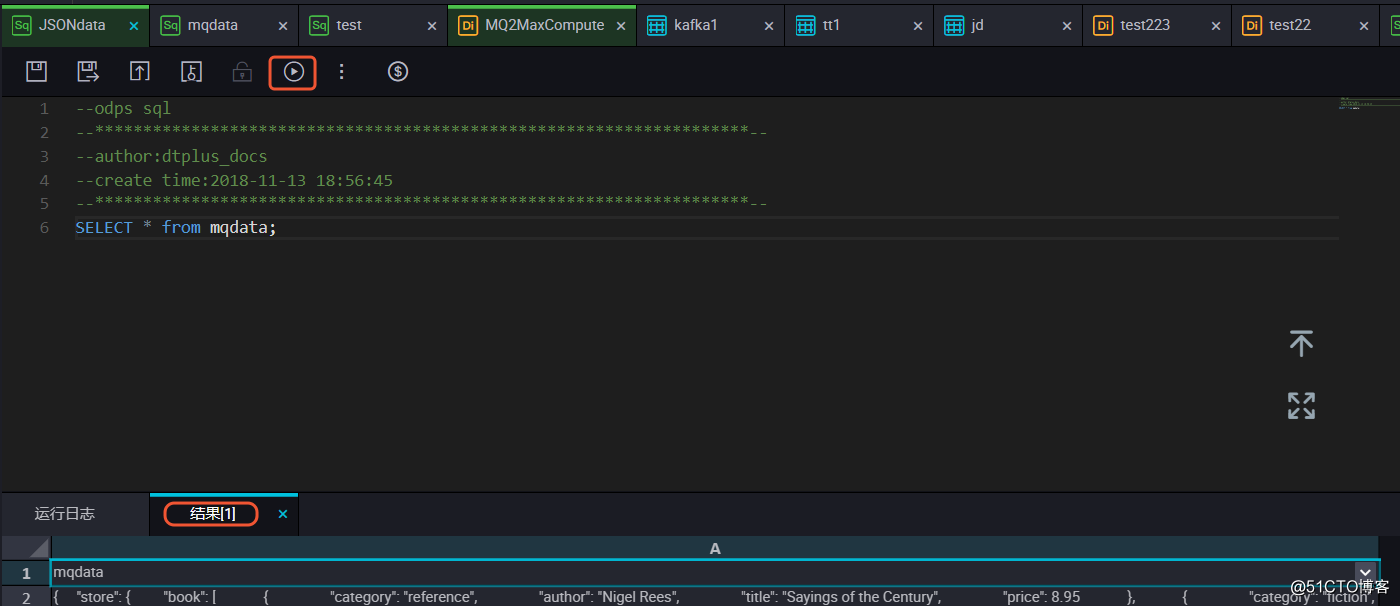
确认导入表中的数据结果无误后,您可以使用MaxCompute内建字符串函数GET_JSON_OBJECT获取您想要的JSON数据。本例中使用 SELECT GET_JSON_OBJECT(mqdata.MQdata,‘$.expensive‘) FROM mqdata;获取JSON文件中的 expensive值。如下图所示,可以看到已成功获取数据。 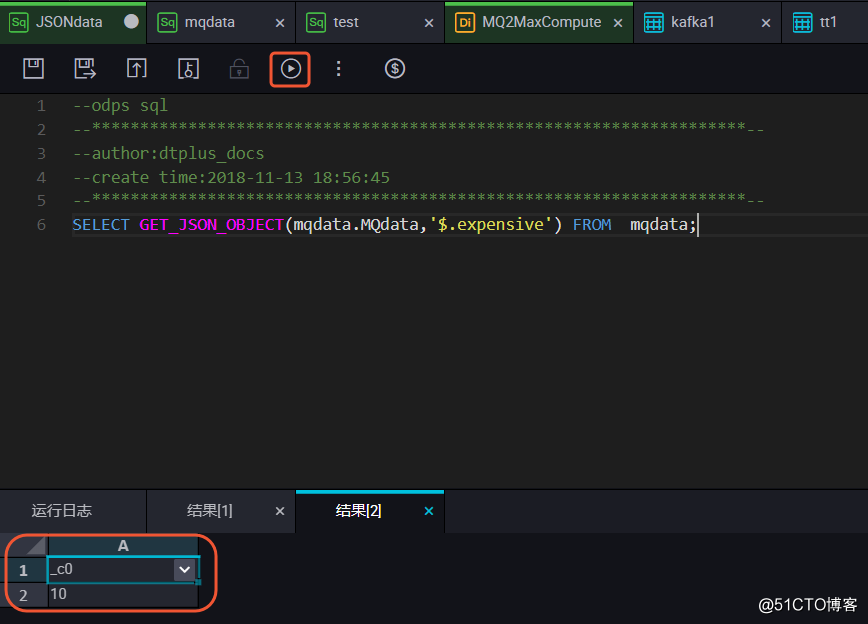
以上是关于JSON数据从OSS迁移到MaxCompute最佳实践的主要内容,如果未能解决你的问题,请参考以下文章
JSON数据从MongoDB迁移到MaxCompute最佳实践