RedShift到MaxCompute迁移实践指导
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RedShift到MaxCompute迁移实践指导相关的知识,希望对你有一定的参考价值。
简介: 本文主要介绍Amazon Redshift如何迁移到MaxCompute,主要从语法对比和数据迁移两方面介绍,由于Amazon Redshift和MaxCompute存在语法差异,这篇文章讲解了一下语法差异
1.概要
本文档详细介绍了Redshift和MaxCompute之间SQL语法的异同。这篇文档有助于加快sql任务迁移到MaxCompute。由于Redshift和MaxCompute之间语法存在很多差异,因此我们需要修改Redshift上编写的脚本,然后才能在MaxCompute中使用,因为服务之间的SQL方言不同。
2.迁移前RedShift于MaxCompute的各项对比差异
2.1.1数据类型对比及类型转化
| 类别 | MaxCompute | 建议转化成MaxCompute类型 | Redshift | |
| 数值类型 | smallint | Y | Y | Y |
| integer | N | int | Y | |
| bigint | Y | int | Y | |
| decimal | Y | Y | Y | |
| numeric | N | decimal | Y | |
| real | N | float | Y | |
| double | Y | Y | Y | |
| float | Y | float | Y | |
| TINYINT | Y | smallint | N | |
| 字符类型 | varchar(n) | Y | Y | Y |
| char(n) | Y | Y | Y | |
| STRING | Y | |||
| text | N | string | Y | |
| 日期 | TIMESTAMP | Y | Y | Y |
| TIMESTAMPTZ | N | Y | ||
| DATE | Y | Y | Y | |
| TIME | N | Y | ||
| DateTime | Y | N | ||
| boolean 数据类型 | boolean | Y | Y | Y |
| 复杂数据类型 | ARRAY | Y | Y | N |
| MAP | Y | Y | N | |
| STRUCT | Y | Y | N | |
| HLLSketch | N | Y |
MaxCompoute数据类型参考2.0数据类型版本 - MaxCompute - 阿里云
2.1.2语法对比
MaxCompute没有schenma、group、库、存储过程的概念。只有project、表、分区,MaxCompute建表时没有自增序列 外键等,不支持指定编码默认utf-8,内部表不支持指定存储格式默认Aliorc
| 主要区别 | |
| 表结构 | 不能修改分区列列名,只能修改分区列对应的值。 |
| 支持增加列,但是不支持删除列以及修改列的数据类 型。 | |
| SQL 常见问题 | INSERT 语法上最直观的区别是:Insert into/overwrite 后面 有个关键字 Table。 |
| 数据插入表的字段映射不是根据 Select 的别名做的,而 是根据 Select 的字段的顺序和表里的字段的顺序 | |
| UPDATE/DELETE | 只有事务表支持UPDATE/DELETE |
| join | Join 必须要用 on 设置关联条件,不支持笛卡尔积 |
| 触发器 | 不支持触发器、 |
| 创建外部函数 | maxCompute没有外部函数 |
| 精度 | DOUBLE 类型存在精度问题。 不建议在关联时候进行直接等号关联两 个 DOUBLE字段,建议把两个数做减 法,如果差距小于一个预设的值就认为 是相同,例如 abs(a1- a2) < 0.000000001。 目前产品上已经支持高精度的类型 DECIMAL。 |
| 日期 | MaxCompute主要的日期类型是datetime(格式yyyy-mm-dd hh:mi:ss) timestamp date,datetime支持的内建函数更加丰富,建议日期转成datetime做运算,日期函数链接 |
| 存储过程 | 使用MaxCompute的pyodps修改 |
| 物化视图 | 要更新物化化视图中的数据,MaxCompute只能手动更新,不支持自动更新 |
| redshift 支持在select语句中引用别名如 select money/100 as a ,round(money/100,3) from table | MaxCompute修改 select money/100 as a ,round(a,3) from table |
2.1.3复合表达式
| MaxCompute | REDAHIFT | |
| +、- | Y | Y |
| ^、|/、||/ | Y | Y |
| *、/、% | Y | Y |
| @ | N | Y |
| &、|、 | Y | Y |
| || | Y | Y |
| #、~、<<、>> | 使用shift函数替换 | Y |
2.1.4条件比较
| MaxCompute | REDAHIFT | |
| <> 或 != | Y | Y |
| like | Y | Y |
| BETWEEN expression AND | Y | Y |
| IS [ NOT ] NULL | Y | Y |
| EXISTS | Y | Y |
| POSIX 运算符 | N | Y |
| SIMILAR TO | N | Y |
| IN | Y | Y |
| 正则 ~ | Rlike | Y |
| ~~ | like | Y |
2.1.5DDL语法
主要差异:
1.MaxCompute不支持主键自增和PRIMARY KEY
2.指定默认值default]不支持使用函数
3.decimal指定默认值不支持-1
| 语法 | MaxCompute | REDSHIFT |
| CREATE TABLE—PRIMARY KEY | N | Y |
| CREATE TABLE—NOT NULL | Y | Y |
| CREATE TABLE—CLUSTER BY | Y | N |
| CREATE TABLE—EXTERNAL TABLE | Y(OSS, OTS, TDDL) | N |
| CREATE TABLE—TEMPORARY TABLE | N | Y |
| table_attributes | N(Mc内部表不需要添加属性) | Y |
| CREATE TABLE—AS | Y | Y |
| create materialized view | Y | Y |
2.1.6DML语法差异
| 语法 | MaxCompute | REDSHIFT |
| CTE | Y | Y |
| SELECT—into | N | Y |
| SELECT—recursive CTE | N | Y |
| SELECT—GROUP BY ROLL UP | Y | N |
| SELECT—GROUPING SET | Y | Y |
| SELECT—IMPLICT JOIN | Y | Y |
| SEMI JOIN | Y | N |
| SELEC TRANSFROM | Y | N |
| SELECT—corelated subquery | Y | Y |
| LATERAL VIEW | Y | Y |
| SET OPERATOR—UNION (disintct) | Y | Y |
| SET OPERATOR—INTERSECT | Y | Y |
| SET OPERATOR—MINUS/EXCEPT | Y | Y |
| INSERT INTO ... VALUES | Y | Y |
| INSERT INTO (ColumnList) | Y | Y |
| UPDATE … WHERE | Y(事务表支持) | Y |
| DELETE … WHERE | Y(事务表支持) | Y |
| ANALYTIC—reusable WINDOWING CLUSUE | Y | Y |
| ANALYTIC—CURRENT ROW | Y | Y |
| ANALYTIC—UNBOUNDED | Y | Y |
| ANALYTIC—RANGE … | Y | Y |
| WHILE DO | N | Y |
| Y | N | |
| select * into | N | Y |
2.1.7内建函数对比
其他未列出的redshift函数不支持。
| 函数类型 | MaxCompute | POSTGRESQL | 在MaxCompute SQL中是否支持分区剪裁 |
| 无 | ADD_MES | ||
| 无 | CONVERT_TIMEZONE | ||
| 无 | DATE_CMP_TIMESTAMP | ||
| 无 | DATE_CMP_TIMESTAMPTZ | ||
| 无 | DATE_PART_YEAR | ||
| 无 | DATE_CMP | ||
| 无 | INTERVAL_CMP | ||
| 无 | + | ||
| 无 | SYSDATE | ||
| 无 | TIMEOFDAY | ||
| 无 | TIMESTAMP_CMP | ||
| 无 | TIMESTAMP_CMP_DATE | ||
| 无 | TIMESTAMP_CMP_TIMESTAMPTZ | ||
| 无 | TIMESTAMPTZ_CMP | ||
| 无 | TIMESTAMPTZ_CMP_DATE | ||
| 无 | TIMESTAMPTZ_CMP_TIMESTAMP | ||
| 无 | to_timestamp | ||
| 无 | TIMEZONE | ||
| DATEDIFF |
| ||
| DATEADD |
| ||
| date_part |
| ||
| date_trunc |
| ||
| 无 |
| ||
| CURRENT_DATE |
| ||
| 无 |
| ||
| 无 |
| ||
| TO_DATE |
| ||
| to_char |
| ||
| extract |
| ||
| 无 |
| ||
| 无 |
| ||
| extract |
| ||
| EXTRACT |
| ||
| EXTRACT |
| ||
| EXTRACT |
| ||
| 无 |
| ||
| EXTRACT |
| ||
| EXTRACT |
| ||
| CURRENT_TIMESTAMP |
| ||
| 运算符+ |
| ||
| LAST_DAY |
| ||
| NEXT_DAY |
| ||
| MONTHS_BETWEEN |
| ||
| 无 | exp | ||
| 无 | ATAN2 | ||
| 无 | DEXP | ||
| 无 | DLOG1 | ||
| 无 | DLOG10 | ||
| ABS |
| ||
| ACOS |
| ||
| ASIN |
| ||
| ATAN |
| ||
| CEIL |
| ||
| convert |
| ||
| COS |
| ||
| ACOS |
| ||
| COT |
| ||
| EXP |
| ||
| FLOOR |
| ||
| LN |
| ||
| LOG |
| ||
| power |
| ||
| random |
| ||
| ROUND |
| ||
| SIN |
| ||
| asin |
| ||
| SQRT |
| ||
| TAN |
| ||
| atan |
| ||
| TRUNC |
| ||
| LOG |
| ||
| LOG |
| ||
| 无 |
| ||
| 无 |
| ||
| 无 |
| ||
| RADIANS |
| ||
| DEGREES |
| ||
| SIGN |
| ||
| 无 |
| ||
| PI |
| ||
| 无 |
| ||
| CBRT |
| ||
| << |
| ||
| >> |
| ||
| >>> |
| ||
| 无 | CUME_DIST | ||
| 无 | FIRST_VALUE/LAST_VALUE | ||
| 无 | LISTAGG | ||
| 无 | NTH_VALUE | ||
| 无 | PERCENTILE_CONT | ||
| 无 | PERCENTILE_DISC | ||
| 无 | RATIO_TO_REPORT ( ratio_expression ) OVER ( [ PARTITION BY partition_expression ] ) | ||
| 无 | STDDEV_SAMP | ||
| 无 | VAR_SAMP | VARIANCE | VAR_POP | ||
| 无 | PERCENT_RANK | ||
| DENSE_RANK |
| ||
| RANK |
| ||
| LAG |
| ||
| LEAD |
| ||
| PERCENT_RANK |
| ||
| |||
| 无 |
| ||
| |||
| APPROXIMATE PERCENTILE_DISC | |||
| 无 | LISTAGG | ||
| 无 | PERCENTILE_CONT | ||
| ANY_VALUE | ANY_VALUE | ||
| COUNT |
| ||
| AVG |
| ||
| MAX |
| ||
| MIN |
| ||
| PERCENTILE_disc |
| ||
| STDDEV |
| ||
| STDDEV_SAMP |
| ||
| SUM |
| ||
| string_agg |
| ||
| 无 |
| ||
| 无 |
| ||
| VARIANCE/VAR_POP |
| ||
| VAR_SAMP |
| ||
| COVAR_POP |
| ||
| COVAR_SAMP |
| ||
| PERCENTILE_disc |
| ||
| 无 | || |
| |
| 无 | BPCHARCMP | ||
| 无 | BTRIM | ||
| 无 | CHAR_LENGTH | ||
| 无 | CHARACTER_LENGTH | ||
| 无 | CHARINDEX | ||
| 无 | COLLATE | ||
| 无 | CRC32 | ||
| 无 | DIFFERENCE | ||
| 无 | INITCAP | ||
| 无 | OCTETINDEX | ||
| 无 | OCTET_LENGTH | ||
| 无 | QUOTE_IDENT | ||
| 无 | QUOTE_LITERAL | ||
| 无 | POSITION | ||
| 无 | REPEAT | ||
| 无 | LEFT /RIGHT | ||
| 无 | STRPOS | ||
| 无 | STRTOL | ||
| 无 |
| ||
| CHR |
| ||
| CONCAT|array_concat |
| ||
| 无 |
| ||
| 无 |
| ||
| 无 |
| ||
| 无 |
| ||
| LENGTH |
| ||
| LEN |
| ||
| 无 |
| ||
| 无 |
| ||
| REGEXP_INSTR |
| ||
| REGEXP_REPLACE |
| ||
| REGEXP_SUBSTR |
| ||
| REGEXP_COUNT |
| ||
| SPLIT_PART |
| ||
| SUBSTR |
| ||
| SUBSTRING |
| ||
| LOWER |
| ||
| UPPER |
| ||
| TRIM |
| ||
| LTRIM |
| ||
| RTRIM |
| ||
| REVERSE |
| ||
| REPEAT |
| ||
| ASCII |
| ||
| CONCAT_WS |
| ||
| LPAD |
| ||
| RPAD |
| ||
| |||
| |||
| |||
| TRANSLATE |
| ||
| 无 |
| ||
| 无 |
| ||
| CRC32 | 无 |
| |
| CAST |
| ||
| COALESCE |
| ||
| DECODE |
| ||
| 无 |
| ||
| 无 |
| ||
| 无 |
| ||
| GREATEST |
| ||
| 无 |
| ||
| LEAST |
| ||
| 无 |
| ||
| uuid_generate_v1 |
| ||
| 无 |
| ||
| IF |
| ||
| CASE WHEN |
| ||
| SPLIT |
| ||
| 无 |
| ||
| split_to_array |
| ||
| 无 |
| ||
| 无 |
| ||
| 无 |
| ||
| NVL |
| ||
| ARRAY |
| ||
| get_array_length |
| ||
| @> |
| ||
| 无 |
| ||
| 无 |
| ||
| 无 |
| ||
| 无 |
| ||
| 无 | SUBARRAY |
2.1.8 MaxCompute 产品特性
| 功能 | MaxCompute 产品组件 | 特性介绍 |
| 数据存储 | MaxCompute 表 (基于盘古 分布式存储) | MaxCompute 支持大规模计算存储,适用于 TB 以上规模的存 储及计算需求,最大可达 EB 级别。同一个 MaxCompute 项 目支持企业从 创业团队发展到独角兽的数据规模需求; 数据 分布式存储,多副本冗余,数据存储对外仅开放 表的 操作接口,不提供文件系统访问接口 MaxCompute 支持大规模计算存储,适用于 TB 以上规模的存 储及计算需求,最大可达 EB 级别。同一个 MaxCompute 项目支持企业从 创业团队发展到独角兽的数据规模需求; 数据分布式存储,多副本冗余,数据存储对外仅 开放表的操作接口,不提供文件系统访问接口; 自研数据存储结构,表数据列式存储,默认高度 压缩,后续将提供兼容 ORC的Ali-ORC存储格 式; 支持外表,将存储在OSS 对象存储、OTS表格 存储的数据映射为二维表; 支持Partition、Bucket 的分区、分桶存储; 更底层不是 HDFS,是阿里自研的盘古文件系 统,但可借助 HDFS 理解对应的表之下文件的 体系结构、任务并发机制使用时,存储与计算解 耦,不需要仅仅为了存储扩大不必要的计算资 源; |
| 存储 | Pangu | 阿里自研分布式存储服务,类似 HDFS。 MaxCompute 对外目前只暴露表接口,不能直 接访问文件系统。 |
| 资源调度 | Fuxi | 阿里自研的资源调度系统,类似 Yarn |
| 数据上传下载 | Tunnel Streaming Tunnel | 不暴露文件系统,通过 Tunnel 进行批量数据上传下载 |
| 开发&诊断 | Dataworks/Studio/Logview | 配套的数据同步、作业开发、工作流编排调度、 作业运维及诊断工具。开源社区常见的 Sqoop、Kettle、Ozzie 等实现数据同步和调度 |
| 用户接口 | CLT/SDK | 统一的命令行工具和 JAVA/PYTHON SDK |
| SQL | MaxCompute SQL | TPC-DS 100%支持,同时语法高度兼容 Hive, 有Hive 背景,开发者直接上手,特别在大数据 规模下性能强大。 * 完全自主开发的 compiler,语言功能开发更 灵活,迭代快,语法语义检查更加灵活高效 * 基于代价的优化器,更智能,更强大,更适合 复杂的查询 * 基于LLVM 的代码生成,让执行过程更高效 * 支持复杂数据类型(array,map,struct) * 支持Java、Python语言的UDF/UDAF/UDTF * 语法:Values、CTE、SEMIJOIN、FROM倒 装、Subquery Operations 、 Set Operations(UNION /INTERSECT /MINUS)、 SELECT TRANSFORM 、User Defined Type、 GROUPING SET(CUBE/rollup/GROUPING SET)、脚本运行模式、参数化视图 * 支持外表(外部数据源+StorageHandler,支 持非结构化数据) |
| Spark | MaxCompute Spark | MaxCompute提供了Spark on MaxCompute 的解决方案,使 MaxCompute 提供兼容开源的 Spark 计算服务,让它在统一的计算资源和数据 集权限体系之上,提供 Spark 计算框架,支持用 户以熟悉的开发使用方式提交运行 Spark 作 业。 * 支持原生多版本 Spark 作业: Spark1.x/Spark2.x作业都可运行; * 开源系统的使用体验:Spark-submit 提交方 式,提供原生的 Spark WebUI供用户查看; * 通过访问OSS、OTS、database 等外部数据 源,实现更复杂的 ETL 处理,支持对 OSS 非结 构化进行处理; * 使用 Spark 面向 MaxCompute 内外部数据 开展机器学习, 扩展应用场景 |
| 机器学习 | PAI | MaxCompute 内建支持的上百种机器学习算 法,目前 MaxCompute 的机器学习能力由 PAI 产品进行统一提供服务,同时 PAI提供了深度学 习框架、Notebook 开发环境、GPU计算资源、 模型在线部署的弹性预测服务。MaxCompute 的数据对PAI产品无缝集成。 |
| 数据接入 | 目前支撑通过 DTS或者 DataWorks数据集成功能 | 数据集成是稳定高效、弹性伸缩的数据同步平台,丰富的异构数据源之间高速稳定的数据移动及同步能力。支持实时任务和批任务写入MaxCompute |
| 整体 | 不是孤立的功能,完整的企业 服务 | 不需要多组件集成、调优、定制,开箱即用 |
3、RedShift到MaxCompute迁移工具介绍
从数据库表导入到 Amazon S3
在线迁移上云服务
将数据从OSS迁移至同区域的MaxCompute项目load命令
语法校验工具二选一
MaxCompute studio
认识MaxCompute Studio - MaxCompute - 阿里云
DataWorks sql节点
创建ODPS SQL节点 - DataWorks - 阿里云
4、迁移整体方案
数据库迁移主要包含以下内容
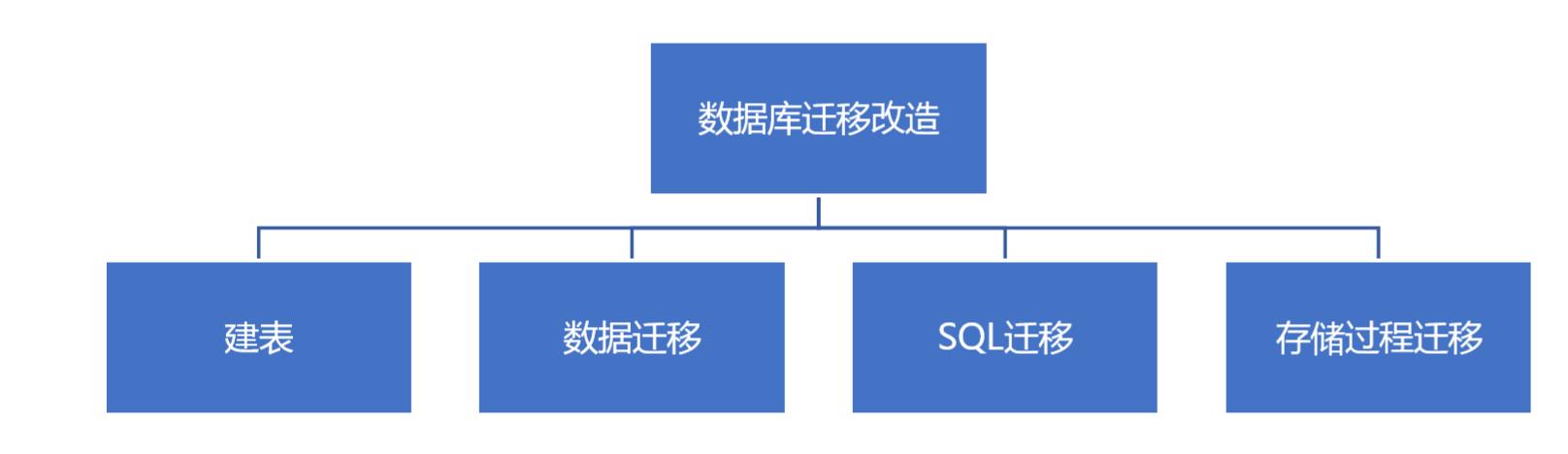
迁移实施计划:
| 序号 | 项目 | 预估时间 |
| 1 | 调研评估 | 1~2周 |
| 2 | 方案设计 | 1~2周 |
| 3 | 资源规划 | 1周 |
| 4 | 改造与测试验证 | 5~7周,需要根据复杂度评估 |
| 5 | 生成割接 | 1~2周 |
5、迁移详细方案
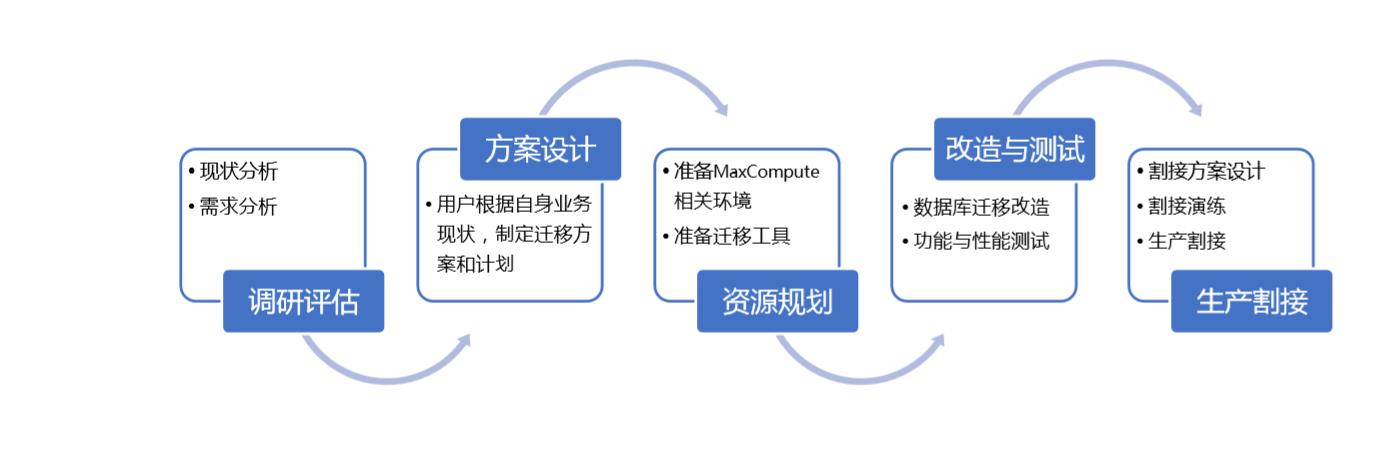
5.1. 现状分析及需求分析
5.2. 迁移方案设计
用户根据自身现有 RedShift数据
以上是关于RedShift到MaxCompute迁移实践指导的主要内容,如果未能解决你的问题,请参考以下文章