io_uring vs epoll ,谁在网络编程领域更胜一筹?
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了io_uring vs epoll ,谁在网络编程领域更胜一筹?相关的知识,希望对你有一定的参考价值。
简介:从定量分析的角度,通过量化 io_uring 和 epoll 两种编程框架下的相关操作的耗时,来分析二者的性能差异。

本文作者:王小光,「高性能存储技术SIG」核心成员。
背景
io_uring 在传统存储 io 场景已经证明其价值,但 io_uring 不仅支持传统存储 io,也支持网络 io。io_uring 社区有众多的开发者尝试将 io_uring 用于网络应用。我们之前也在《你认为 io_uring 只适用于存储 IO?大错特错!》中也探索过 io_uring 在网络场景的应用及其与传统网络编程基石 epoll 的对比,当时我们的测试结果显示在 cpu 漏洞缓解使能的前提下,io_uring 相比于 epoll 可以带来一定的优势,在 cpu 漏铜缓解未使能时,io_uring 相比于 epoll 没有优势,可能还会存在性能下降。
在 io_uring 社区,关于 io_uring 和 epoll 孰优孰劣也一直存在争论,有些开发者宣称 io_uring 可以获得比 epoll 更好的性能,有些开发者则宣称二者性能持平或者 io_uring 甚至不如 epoll。相关的讨论非常多,具体可参见如下两例:
https://github.com/axboe/liburing/issues/189
Wild results, cannot reproduce · Issue #8 · frevib/io_uring-echo-server · GitHub
以上讨论从 2020 年 8 月一直持续到现在,其过程非常长也非常地激烈。可以看出 io_uring 和 epoll 在网络编程领域孰优孰劣目前确实比较难以达成共识。
目前很多业务想将 io_uring 在网络场景应用起来,但 io_uring 是否能比 epoll 带来性能提升,大家或多或少存在些许疑问。为了彻底厘清这个问题,龙蜥社区高性能存储 SIG尝试从定量分析的角度,通过量化 io_uring 和 epoll 两种编程框架下的相关操作的耗时,来分析二者的性能差异。
评估模型
我们仍然选用 echo server 模型进行性能评估,server 端采用单线程模型,同时为公平对比,io_uring 不使用内部的 io-wq 机制(io_uring 在内核态维护的线程池,可以用来执行用户提交的 io 请求)。epoll 采用 send(2) 和 recv(2) 进行数据的读写操作;而 io_uring 采用 IORING_OP_SEND 和 IORING_OP_RECV 进行数据的读写操作。
结合 echo server 的模型,我们分析有四个因素会影响 io_uring 和 epoll 的性能,分别是:
1、系统调用用户态到内核态上下文切换开销,记为 s;
2、系统调用自身内核态工作逻辑开销,记为 w;
3、io_uring 框架本身开销,记为 o;
4、io_uring 的 batch 量,记为 n,epoll 版 echo server 由于直接调用 recv(2) 和 send(2), 其 batch 实际为 1。
同时在本文中我们仅评估 io_uring 和 epoll 请求读写操作的开销,对于 io_uring 和 epoll 本身的事件通知机制本身不做衡量,因为通过 perf 工具分析,读写请求本身开销占据绝大部分。系统调用用户态到内核态上下文切换开销可以通过专门的程序进行测量,因素 2、3、4 等可以通过衡量内核相关函数的执行时间进行测量,用 bpftrace 进行分析。
epoll 版 echo server 开销度量
从用户态视角,send(2) 或者 recv(2) 开销主要包含两个方面,系统调用用户态到内核态上下文切换开销和系统调用自身内核态工作逻辑开销,其中系统调用本身工作逻辑的开销,send(2) 和 recv(2) 分别衡量 sys_sendto(), sys_recvfrom() 即可。
由于 epoll 场景下其系统调用的 batch 为 1,因此 epoll 模型下收发请求的平均耗时为 (s + w)。
io_uring 版 echo server 开销度量
io_uring 中 io_uring_enter(2) 系统调用既可以用来提交 sqe,也可以用来 reap cqe,两种操作混合在一个系统调用中,准确衡量 sqe 的提交收发请求的耗时比较困难。简单起见,我们采用跟踪 io_submit_sqes() 的开销来衡量 IORING_OP_SEND 和 IORING_OP_RECV 的开销,此函数被 io_uring_enter(2) 所调用。io_submit_sqes() 包含send(2) 和 revc(2) 内核侧工作逻辑开销,及 io_uring 框架的开销,记为 t。
同时我们采用 io_uring 的 multi-shot 模式,从而确保 io_submit_sqes() 中的提交的 IORING_OP_SEND 和 IORING_OP_RECV 请求都可以直接完成,而不会用到io_uring的 task-work 机制。
由于 io_uring 场景下可以 batch 系统调用的执行,因此 io_uirng 模型下收发请求的平均耗时为 (s + t) / n。
实际度量
我们测试环境 Intel(R) Xeon(R) CPU E5-2682 v4 @ 2.50GHz,衡量 echo server 单链接性能数据。
用户态内核态系统调用上下文切换开销
cpu 漏洞对系统调用用户态内核态上下文切换的影响比较大,在我们的测试环境中:漏铜缓解使能时,系统调用的上下文切换开销为 700ns 左右;漏铜缓解未使能时,系统调用的上下文切换开销为 230ns 左右。
epoll 模型下 send(2)/recv(2) 内核侧开销
采用bpftrace 脚本分别衡量 sys_sendto(),sys_recvfrom() 即可。 bpftrace 脚本如下:
BEGIN
@start = 0;
@send_time = 0;
@send_count = 0;
kprobe:__sys_sendto
/comm == "epoll_echo_serv"/
@start = nsecs;
kprobe:__sys_recvfrom
/comm == "epoll_echo_serv"/
@start = nsecs;
kretprobe:__sys_sendto
/comm == "epoll_echo_serv"/
if (@start > 0)
@delay = nsecs - @start;
@send_time = @delay + @send_time;
@send_count = @send_count + 1;
kretprobe:__sys_recvfrom
/comm == "epoll_echo_serv"/
if (@start > 0)
@delay = nsecs - @start;
@send_time = @delay + @send_time;
@send_count = @send_count + 1;
interval:s:5
printf("time: %llu\\n", @send_time / @send_count);
@send_time = 0;
@send_count = 0;
在单连接,包大小 16 字节场景下,epoll 版的 echo_server 的 tps 在 1000 左右,其 recv(2) 和 send(2) 的内核侧逻辑平均开销如下:
time: 1489、time: 1492、time: 1484、time: 1491、time: 1499、time: 1505、time: 1512、time: 1528、time: 1493、time: 1509、time: 1495、time: 1499、time: 1544
从上述数据可以看出,send(2) 和 recv(2) 的内核侧平均开销在1500ns左右,因此:
1) cpu 漏洞缓解,send(2) 和 recv(2) 的平均开销为 s=700ns,w=1500ns,总共 (s+w) = 2200ns。
2) cpu 漏洞为缓解,send(2) 和 recv(2) 的平均开销为 s=230ns,w=1500ns,总共 (s+w) = 1730ns。
io_uring 模型下 io_uring_enter(2) 内核侧开销
采用bpftrace 脚本分别衡量 io_submit_sqes() 开销即可。
BEGIN
@start = 0;
@send_time = 0;
@send_count = 0;
kprobe:io_submit_sqes
/comm == "io_uring_echo_s"/
@start = nsecs;
@send_count = @send_count + arg1;
kretprobe:io_submit_sqes
/comm == "io_uring_echo_s"/
if (@start > 0)
@delay = nsecs - @start;
@send_time = @delay + @send_time;
interval:s:5
printf("time: %llu\\n", @send_time / @send_count);
@send_time = 0;
@send_count = 0;
运行类似上述 epoll 同样的测试,数据为:
time: 1892、time: 1901、time: 1901、time: 1882、time: 1890、time: 1936、time: 1960、time: 1907、time: 1896、time: 1897、time: 1911、time: 1897、time: 1891、time: 1893、time: 1918、time: 1895、time: 1885
从上述数据可以看出,io_submit_sqes() 的内核侧平均开销在 1900ns 左右,注意此时的batch n=1,且该开销包括收发请求的内核态工作逻辑开销及 io_uring 框架开销。
1) cpu 漏洞缓解,用户态观察到的 io_uring_enter(2) 平均开销为 t=1900ns,n=1,s=700ns,总共 (t+s) / n = 2600ns。
2) cpu 漏洞未缓解,用户态观察到的 io_uring_enter(2) 的平均开销为 t=1900ns,n=1,s=230ns,总共 (t+s) / n = 2130ns。
注意由于我们实际只 trace io_submit_sqes,而 io_uring_enter(2) 系统调用是调用 io_submit_sqes 的,因此 io_uring_enter(2) 的实际开销是肯定大于 (t+s) / n。
数据量化分析
从上述数据发现,cpu 漏洞确实对系统调用的性能影响较大,尤其对于小数据包的场景,我们分别讨论下:
cpu 漏洞缓解未使能
epoll: s+w, io_uring: (t+s) / n
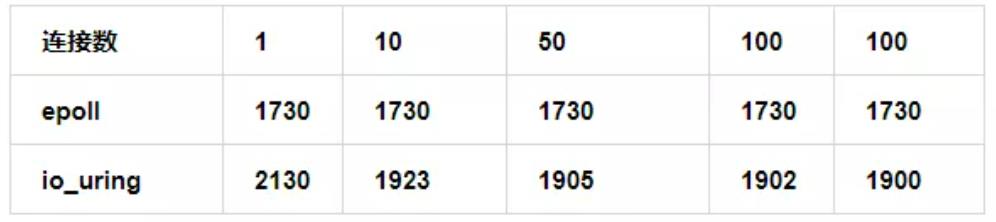
可以看出在此种情况下,由于 t 大于 w, 即使扩大 batch,io_uring 的性能也不如 epoll。
cpu 漏洞缓解使能
epoll: s+w, io_uring: (t+s) / n
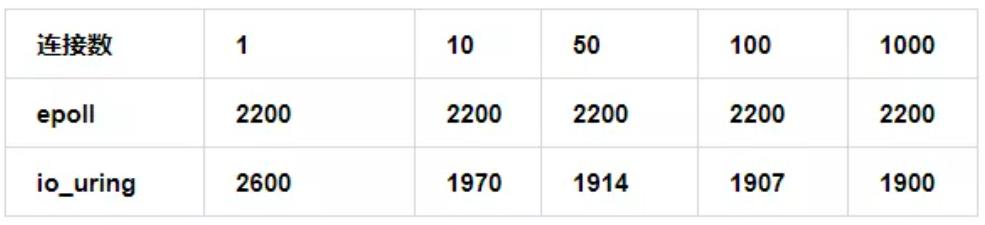
可以看出在此种情况下,由于 s 比较大,当 batch 比较低时,io_uring 不如 epoll,但当 batch 比较大时,io_uring 场景下系统调用上下文切换开销被极大摊薄,此时 io_uring 的性能是优于 epoll。在我们的实际测试中,1000连接时,io_uring 的的吞吐要比 epoll 高 10% 左右,基本符合我们的建模。
结论
从我们的量化分析可以看出 io_uring 与 epoll 孰优孰劣完全由评估模型中定义的 4 个变量决定:
epoll: s + w
io_uring: (t + s) / n
如果某个变量占主导地位,则性能数据会截然不同。举个例子,假设系统调用上下文切换开销 s 很大,而且 io_uring batch n 也很大,则 io_uring 在此种场景下的性能肯定是会比 epoll 好;再比如系统内核侧开销 w 很大,此时 io_uring 和 epoll 性能会接近。
因此 io_uring 和 epoll 孰优孰劣,取决于其应用场景,我们建议的最佳实践是基于业务真实网络模型,将其简化为 echo server 模型,运行我们的度量脚本,从而可以评估二者在真实环境的性能,以指导真实应用开发。同时上述度量数据也为我们的性能优化提供方向,我们可以尽可能的减少某一变量的开销,从而提高性能,比如可以进一步优化 io_uring 框架的开销。
高性能存储技术SIG介绍
高性能存储技术SIG :致力于存储栈性能挖掘化,打造标准的高性能存储技术软件栈,推动软硬件协同发展。
原文链接
本文为阿里云原创内容,未经允许不得转载。
以上是关于io_uring vs epoll ,谁在网络编程领域更胜一筹?的主要内容,如果未能解决你的问题,请参考以下文章
io_uring 新起之秀的linux io模式,是如何媲美epoll的
从经典网络IO模型到新异步IO框架io_uring《重制版》