io_uring异步io简介
Posted rayylee
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了io_uring异步io简介相关的知识,希望对你有一定的参考价值。
1. io_uring:免系统调用的 I/O
我们的应用程序通常会对磁盘和网络进行操作,而这些 I/O 操作都需要操作系统的配合才能完成,这就需要应用程序去调用操作系统的相应接口,而这类调用就叫做系统调用(syscall),比如用 read() 来读取文件,或者用 send() 来发送网络数据。
不管你用的什么编程语言,这些操作在底层基本上都是要做系统调用的。以 Linux 为例,如果仔细观察进程 CPU 的占用率,就能看到每个进程都有 user 占比和 system 占比,这个 system 占比就是该进程花在系统调用上的时间。
centos@localhost:~# time curl https://github.com > /dev/null
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed100 35991 0 35991 0 0 23711 0 --:--:-- 0:00:01 --:--:-- 23709real 0m1.527suser 0m0.070ssys 0m0.005s

虽然系统调用可能会非常频繁,但这种调用并不是没有性能开销的 —— 除了操作系统花在实际执行一次系统调用所需的时间外,在 user 和 system 模式之间切换也是需要时间的。
这个开销虽然单次仅有约几百到上千纳秒,但架不住多啊 —— 比如 asyncio 的事件循环每一次至少要 epoll() 一次吧,有进展的 socket 各自又有一次读或写,万一没成功下回还得重试。高并发下,一秒几百次的事件循环,每次循环几十上百次 I/O,光系统调用的额外开销就要占到毫秒级别了。
epoll() 是 Linux 上的高性能事件通知设施,可以同时监视多个文件描述符(比如 socket)的事件状态,如某个 TCP 连接成功了,或者某个 socket 收到消息了等等。
如果能把这些系统调用都放在操作系统里一并完成,不仅能够省去 user 和 system 来回切换的时间,更是抛开了接口封装的枷锁,在内核中直接完成许多之前不好搞的骚操作(比如异步磁盘 I/O),岂不美哉?这就是 io_uring 诞生的原因。
io_uring 是facebook开发的,从 5.1 就进 Linux 内核主线了,但陆续改进到 5.11 才有了 kLoop 需要的全部功能,并且仍在持续改进中。

笼统来讲,应用程序用内存映射(mmap)的方式拿到两条与内核共享的环状队列,通过其中一条队列(SQ)给内核源源不断的布置任务,然后从另外一条队列(CQ)获取结果;内核则按需进行 epoll(),并在一个线程池中执行就绪的任务。
一些常见的系统调用,如打开文件、读写文件、socket 操作等等,都可以通过 io_uring 来完成。而应用程序所需要做的,只是一些内存操作,告诉内核要做什么,读写缓冲区在哪里。这里仍然有少量的一些系统调用来控制 io_uring 本身,但都是实现细节了。一些初步的测评显示,io_uring 能比普通 epoll 快出 5% 至 40%。
2. io_uring在网卡上的应用
自 Linux 4.13 起,部分对称加密运算可以在内核中直接完成。这又是facebook的作品,并且在硬件支持的情况下,可以直接把运算工作扔给网卡来做,彻底解放 CPU。这个功能官方叫做 Kernel TLS,我们随大众的叫法,简称为 kTLS。常见 Linux 发行版似乎都构建了这一模块,就叫 tls,只需 modprobe 加载后即可使用。
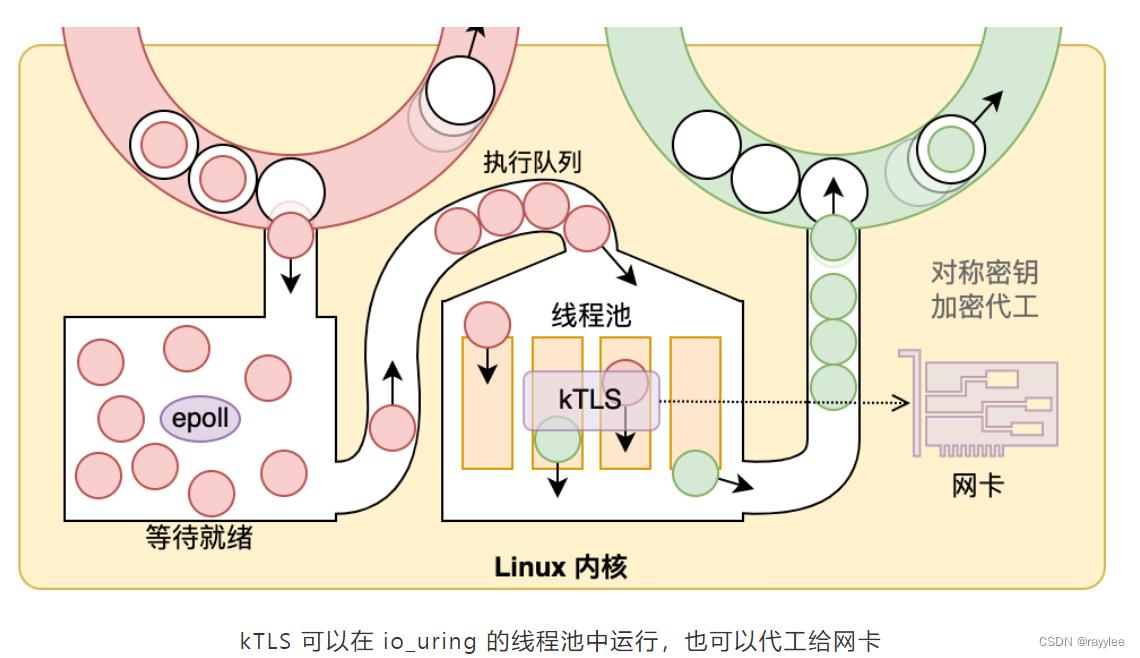
从这张图就能看出来,为什么 io_uring 和 kTLS 是天生一对了 —— 如果网卡不支持加密运算,那么 io_uring 的线程池正好可以给 kTLS 用来做运算池!这就意味着,你的应用程序哪怕只有一个线程,理论上也可以去抢多核 CPU 的资源。
以上是关于io_uring异步io简介的主要内容,如果未能解决你的问题,请参考以下文章