多序列融合召回在新用户冷启动上的应用
Posted 阿里巴巴淘系技术团队官网博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多序列融合召回在新用户冷启动上的应用相关的知识,希望对你有一定的参考价值。

本系列将系统介绍召回技术在内容推荐的实践与总结。
第二篇:CMDM:基于异构序列融合的多兴趣深度召回模型在内容平台的探索和实践
背景
内容推荐是淘宝推荐领域的重要阵地之一,每天会有数以千万计的用户进入内容推荐场景并消费各式各样的内容,其中不乏数量众多的新用户。新用户冷启动是推荐领域的经典问题,我们的召回-粗排-排序-重排推荐链路中,召回模块是新用户冷启动的重要核心优化点。
目前针对新用户的召回模块中,主要包含两类召回。一是Swing I2I类召回,基于用户的实时商品行为和内容行为中的内容id和标签相关的信息,以i2i的形式召回相关的内容,准确性强而多样性不足;二是深度U2I类召回,使用特殊设计的双塔结构学习到用户embedding与内容embedding,通过向量检索技术召回用户embedding相似的topk内容,具有一定的准确性与较强的多样性。其中,由于I2I的trigger数量较少而深度U2I的泛化能力强,因而在新用户召回中深度U2I的pv占比较大(约为60%),深度U2I召回具有很大的优化空间。
行为序列是深度U2I建模中最重要的信息之一,对于新用户而言,逛内容行为序列极其稀疏,而商品行为序列却极其丰富,如何利用丰富的商品行为序列信息辅助稀疏的内容行为序列信息,是新用户冷启动召回中一个重要的探索方向。
Base双塔模型
深度U2I召回的Base模型是传统向量化召回的双塔模型,用户侧塔包含内容行为序列和商品行为序列,模型结构如下图所示:
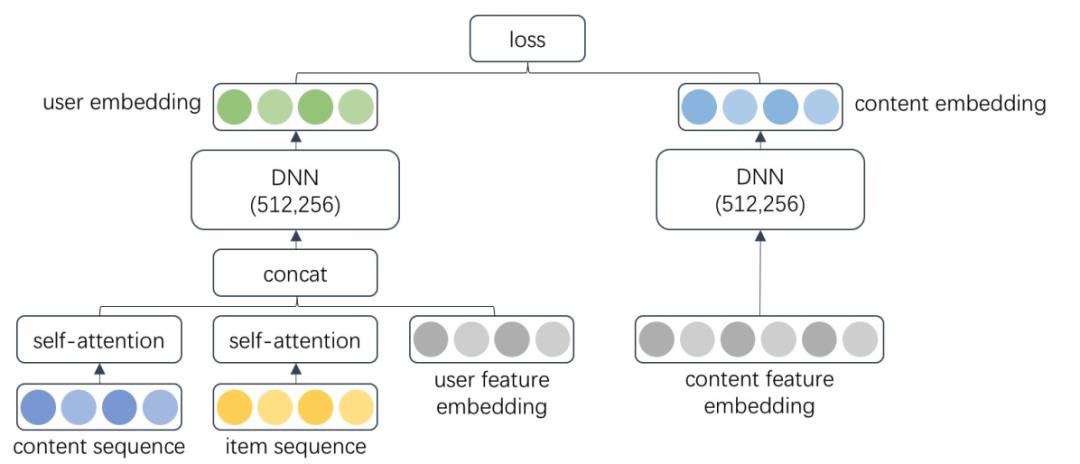
模型会学习到表征用户的user embedding和表征内容的content embedding。在线服务时模型部署在BE上,会为请求的用户实时生成user embedding并通过向量索引快速召回TopN个内容。
DAN双序列融合网络
Base模型将内容序列和商品序列作为两个独立的序列,分别使用self-attention建模成表征两个序列的embedding。然而,在淘宝中用户存在multi-domain behaviors,商品的点击序列和内容点击序列不是独立的,在时间上更接近交叉并存的状态。从用户角度上讲,这些交叉的行为也是用户被种草的路径刻画,比如用户点击了多个商品后,在内容场景被某个相关内容吸引。因此,充分利用不同domain的序列内容信息交叉,有助于更精准的实现千人千面。
▐ 模型结构
为了利用两个序列之间的信息交叉,充分融合商品点击序列和内容点击序列,我们从自然语言处理的VQA任务中得到启发。如下图所示,VQA是用自然语言回答给定图像的问题的任务。常用做法是在图片上应用视觉注意力,在文本上应用文本注意力,再分别将图片、文字多模态向量输入到一个联合的学习空间,通过融合映射到共享语义空间。
而DAN[1]结构是VQA任务中一个十分有效的模型结构,DAN通过设计模块化网络,允许视觉和文本注意力在协作期间相互引导并共享语义信息。在第一版改进的深度U2I模型中,我们使用DAN结构将内容序列和商品序列进行融合,其结构如下:
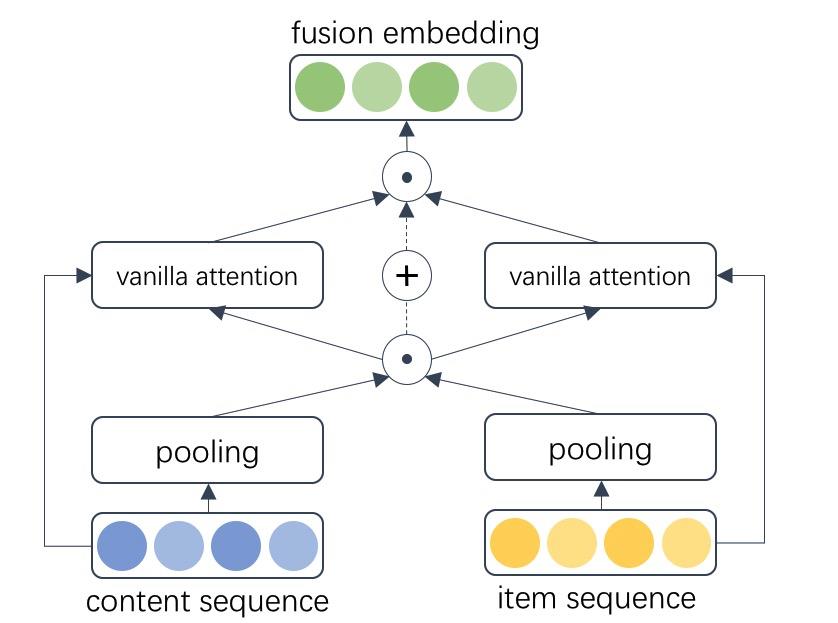
在DAN双序列融合网络中,内容点击序列C=c1,c2,....cn和商品点击序列I=i1,i2,...in(其中cn和in分别表示第n个内容/商品的embedding)分别通过MeanPooling得到内容序列表征Ec1和商品序列表征Ei1,而后Ec和Ei通过点积生成内容和商品的一级融合表征Ef1,而初始的序列C与I进一步通过一级融合表征Ef1产生二级融合表征Ef2,最终生成双序列的融合表征F,其完整公式如下所示:

最终融合表征F与其他user侧特征concat后,进入用户侧塔进行学习。
▐ 离线评估
使用离线向量索引工具[2]对Base深度U2I模型和DAN双序列融合模型的召回效果进行离线评测,结果如下:
实验 | HitRate@100 | HitRate@50 | HitRate@5 |
Base模型 | 0.165 | 0.109 | 0.020 |
DAN | 0.169 | 0.112 | 0.019 |
从离线评测的指标上看,DAN双序列融合模型的HitRate@100和HitRate@50略高于Base模型,指标间的差距不大,从离线结果看DAN双序列融合没有带来很大的收益。
▐ 在线结果
在新用户上:
大盘效果: pctr -0.21% uctr +0.13% 时长+0.37%
单路效果: pvr:+0.74% pctr:-0.85%
从在线效果上看,新用户上大盘的效果基本持平,从单路看召回的效果看,DAN双序列融合模型也基本无收益,pctr略微负向。其主要原因是对新用户而言,内容序列稀疏而商品序列丰富,直接使用DAN将两个序列进行融合,近似于在商品序列中以近似于噪声的形式引入内容序列,对融合表征的学习产生干扰。
Contextual Gate DAN 双序列融合网络
DAN结构为我们提供了一种学习内容序列和商品序列融合表征的思路,但直接融合双序列而不考虑新用户中内容序列稀疏商品序列丰富的特性,反而会影响整个融合序列表征的学习。因此,我们需要对DAN结构进行相应的修改,引入一些有效信息来控制融合过程中内容序列和商品序列的贡献程度。
在内容序列稀疏的情况下,我们希望模型能动态决定是将内容序列的融合权重降至最低,还是提升内容序列的权重以加强其信息贡献度。例如,用户商品序列中类目A的占比较大,在内容序列稀疏且只包含类目B内容的情况下,或许需要降低内容序列的融合权重,相反若内容序列包含类目A内容,则此时更需要加强。
同时,融合过程中,我们希望能在融合时更直接的对序列中的内容进行筛选。例如商品序列中类目A占比较大时,内容序列中类目A相关的内容需要贡献更多的权重,而类目B相关的内容权重需要降低。
总体而言,我们希望改进后的DAN结构具有如下两个特性:
能动态控制序列融合时内容序列与商品序列的参与度
能对各序列中的元素进行动态的筛选,影响其参与融合的权重
▐ 模型结构
我们对DAN结构进行了改进,设计了Contextual Gate DAN 双序列融合网络,其结构如下图所示:
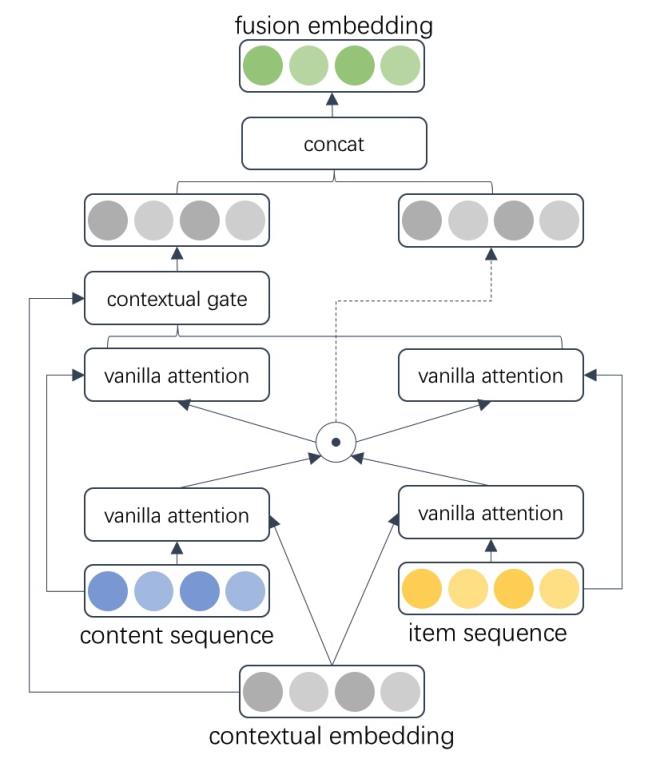
在Contextual Gate DAN结构中,我们引入了Contextual embedding作为主导序列融合程度的关键信息,记为T。Contextual embedding由如下特征的embedding组合而成,包括新用户标识特征、用户场景活跃统计特征、实时Top5商品类目偏好和实时Top5内容类目偏好特征。
我们对生成最终融合表征F的公式(1)和生成二级融合表征Ef2的公司(2)进行调整,通过contextual gate结构动态控制内容序列和商品序列的融合, 完整公式如下所示:
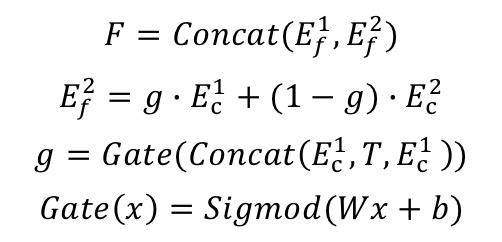
同时,我们也使用Contextual embedding辅助一级融合表征f1的生成,动态对商品和内容序列的元素进行筛选,为每个元素赋予一个动态的融合权重,内容序列表征Ec1和商品序列表征Ei1调整为:

其余部分和DAN结构一致,Contextual Gate DAN结构使用Contextual gate控制了内容序列和商品序列的贡献度,并调整了序列中各元素的权重。
▐ 离线评估
使用离线向量索引工具[2]对DAN双序列融合模型和Contextual Gate DAN融合模型的召回效果进行离线评测,结果如下:
实验 | HitRate@100 | HitRate@50 | HitRate@5 |
DAN | 0.169 | 0.112 | 0.019 |
Contextual Gate DAN | 0.175 | 0.119 | 0.021 |
从离线评测看,Contextual Gate DAN有一定的提升,各项指标均优于DAN。
▐ 在线结果
在新用户上:
大盘效果: pctr +0.38% uctr +2.70% 时长+1.45%
单路效果: pvr:+28.65% pctr:+11.63%
引入Contextual embedding并构造Contextual Gate DAN模型带来了一定的收益,同时在单路效果上pvr提升明显。
总结与展望
内容行为序列稀疏而商品行为序列丰富是我们内容场景新用户的重要特性,而内容序列和商品序列也不能完全作为独立的序列。此次优化中我们将内容序列和商品序列进行融合,利用不同序列之间的信息交叉,充分结合新用户的场景特性,使用改进的DAN结构建模内容序列和商品序列,提升了新用户上的推荐效果。
在后续的优化上,我们考虑尝试如下几个方向:一是尝试更多有效的序列融合方式[3][4],对多序列建模进行进一步的表征;二是将序列融合迁移到全量用户上,进一步从用户在其他域的场景中充分挖掘其兴趣点,并与内容场景的兴趣相结合;三是将序列融合与多兴趣挖掘(如mind[5]、MultCLR[6])相结合,从多序列中挖掘用户兴趣。
参考文献
[1] Nam, H. , J. W. Ha , and J. Kim . "Dual Attention Networks for Multimodal Reasoning and Matching." IEEE Conference on Computer Vision & Pattern Recognition IEEE Computer Society, 2016.
[2] Centauri-批流引擎
[3] Verma, Sunny, et al. "Deep-HOSeq: Deep Higher Order Sequence Fusion for Multimodal Sentiment Analysis." 2020 IEEE International Conference on Data Mining (ICDM). IEEE, 2020.
[4] Yu, Youngjae, Jongseok Kim, and Gunhee Kim. "A joint sequence fusion model for video question answering and retrieval." Proceedings of the European Conference on Computer Vision (ECCV). 2018.
[5] MIND:基于动态路由技术的用户多兴趣表达
[6] MultCLR:多向量召回的Explore与Exploit
团队介绍
我们来自淘宝逛逛算法团队,逛逛是淘宝重要的内容化场景,团队优势有:
业务空间大、基础设施完善:场景海量反馈,在工程团队的支持下,算法工程师可以轻松上线大规模模型,分钟级更新,更加注重算法本身。
团队氛围好、研究与落地深度结合:团队不仅仅解决业务算法问题,还会紧跟学术领域进展。也欢迎有实习想法的同学加入,由资深师兄根据同学优势与兴趣定义好业务问题,辅导研究,给每位同学都有充分的成长空间。
人才需求:有机器学习、深度学习有一定理解,对内容分发和内容理解感兴趣,可以发邮件到邮箱mingyi.ff#alibaba-inc.com或者jinxin.hjx#alibaba-inc.com(发送邮件时,请把#替换成@)
✿ 拓展阅读


作者|橙葉
编辑|橙子君
出品|阿里巴巴新零售淘系技术


以上是关于多序列融合召回在新用户冷启动上的应用的主要内容,如果未能解决你的问题,请参考以下文章
推荐系统[八]:推荐系统常遇到问题和解决方案[物品冷启动问题多目标平衡问题数据实时性问题等]
推荐系统[八]算法实践总结V1:淘宝逛逛and阿里飞猪个性化推荐:召回算法实践总结冷启动召回复购召回用户行为召回等算法实战