阅读笔记Federated Learning for Privacy-Preserving AI
Posted HERODING23
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阅读笔记Federated Learning for Privacy-Preserving AI相关的知识,希望对你有一定的参考价值。
Federated Learning for Privacy-Preserving AI
前言
一篇来自 Communications of ACM 的文章,这类期刊相当于magazine性质的文章,所以大多很短。之前阅读了PPFL的综述,对PPFL有了更深刻的认识,这篇文章的作者也是《联邦学习》的作者,所以我认为这篇会是《联邦学习》的精简版,阅读起来应该没什么瓶颈,那么就当做小说一样过一遍吧~
一、论文解析
如今在人工智能领域存在两大挑战:
- 数据孤岛;
- PPAL的需求日益增长。
传统的基于集中数据收集的人工智能方法无法应对这些挑战。如何在遵循隐私保护法律法规同时解决数据孤岛和碎片化问题,是当今人工智能领域的重大挑战。
法律层面的法律法规在不断完善,旨在保护用户的隐私不被泄露。在这样法律环境下,收集共享数据变得更加困难,一些敏感数据如医疗、金融数据更不允许获取。这也很自然联想到构建不依赖于将数据集中收集进行训练的模型。一个有吸引力的想法是使用本地数据集训练子模型,然后多方共享子模型构建全局模型。为了保护用户隐私和数据机密性,通信过程经过精心设计防止其他节点的反向重构,这就是FL(federated machine learning)背后的核心。
Definition
FL可以应用在B2C(企业->消费者),如谷歌的输入预测模型,所有的移动设备共享相同的数据特征训练ML模型。此外FL在B2B模式下可以支持“打破数据孤岛”场景,每个参与方有不同的数据特征。总之,FL通过安全的方式传输模型参数使各方不能访问他人的数据,FL的特征如下:
- 多个参与方共建模型;
- 每个参与方持有训练的数据集;
- 模型训练过程中本地数据不会离开;
- 模型在加密方案下从一方转移到另一方;
- FL的性能接近集中式数据集构建的理想模型。
PPFL已经得到广泛研究,如:
- 差分隐私
- 安全多方计算
差分隐私是在训练数据中加入噪声,涉及到准确性和隐私性的权衡。
Categorization
根据数据在特征空间和样本空间的分布情况,FL可以分为横向联邦学习(HFL),纵向联邦学习(VFL)以及联邦迁移学习(FTL)。
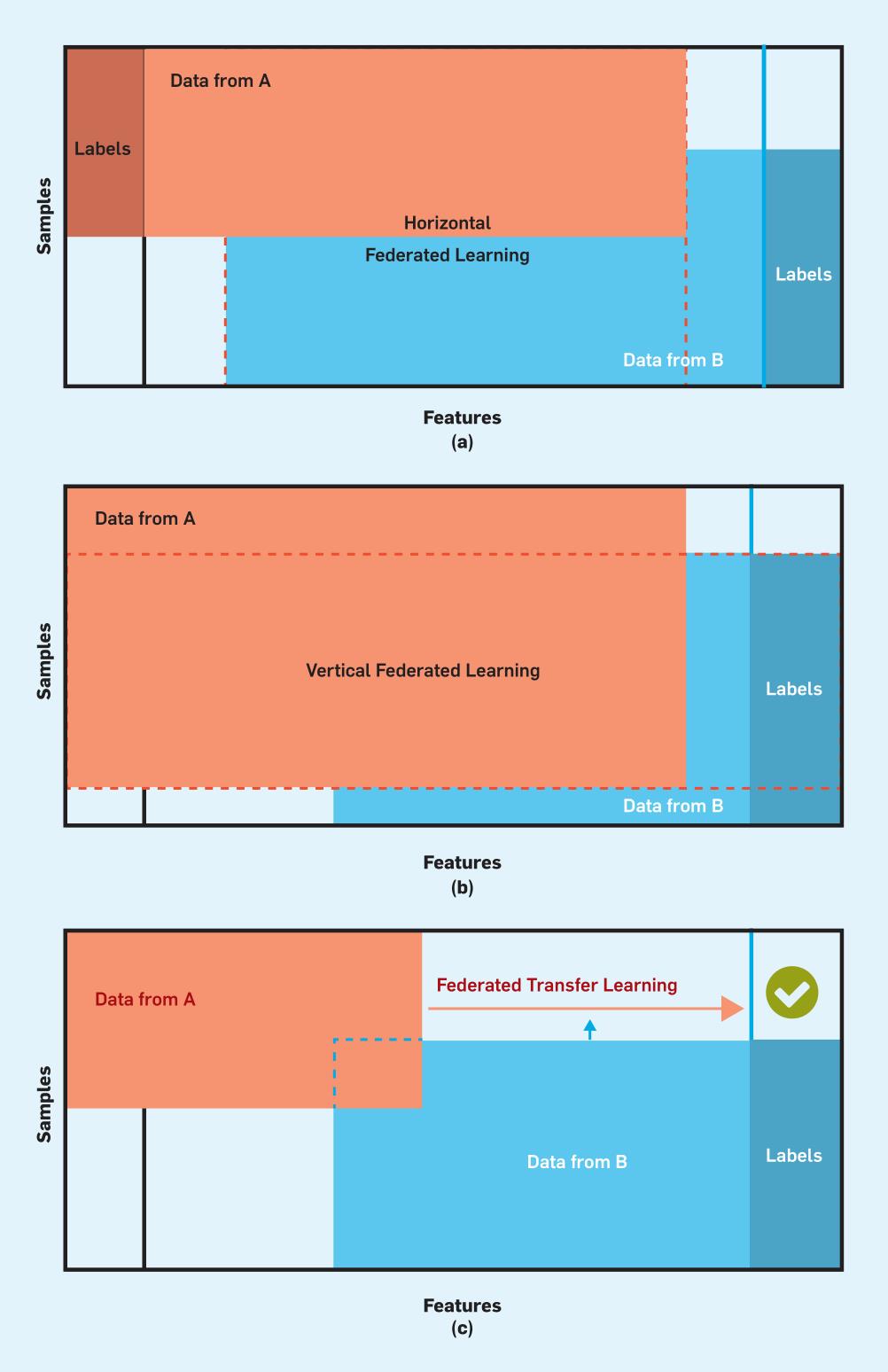 HFL应用在双方数据特征空间重叠样本空间不重叠的场景,VFL适用于双方样本空间重叠但数据特征不重叠的场景,FTL适用于数据样本和特性重叠较少的场景。
HFL应用在双方数据特征空间重叠样本空间不重叠的场景,VFL适用于双方样本空间重叠但数据特征不重叠的场景,FTL适用于数据样本和特性重叠较少的场景。
Architecture
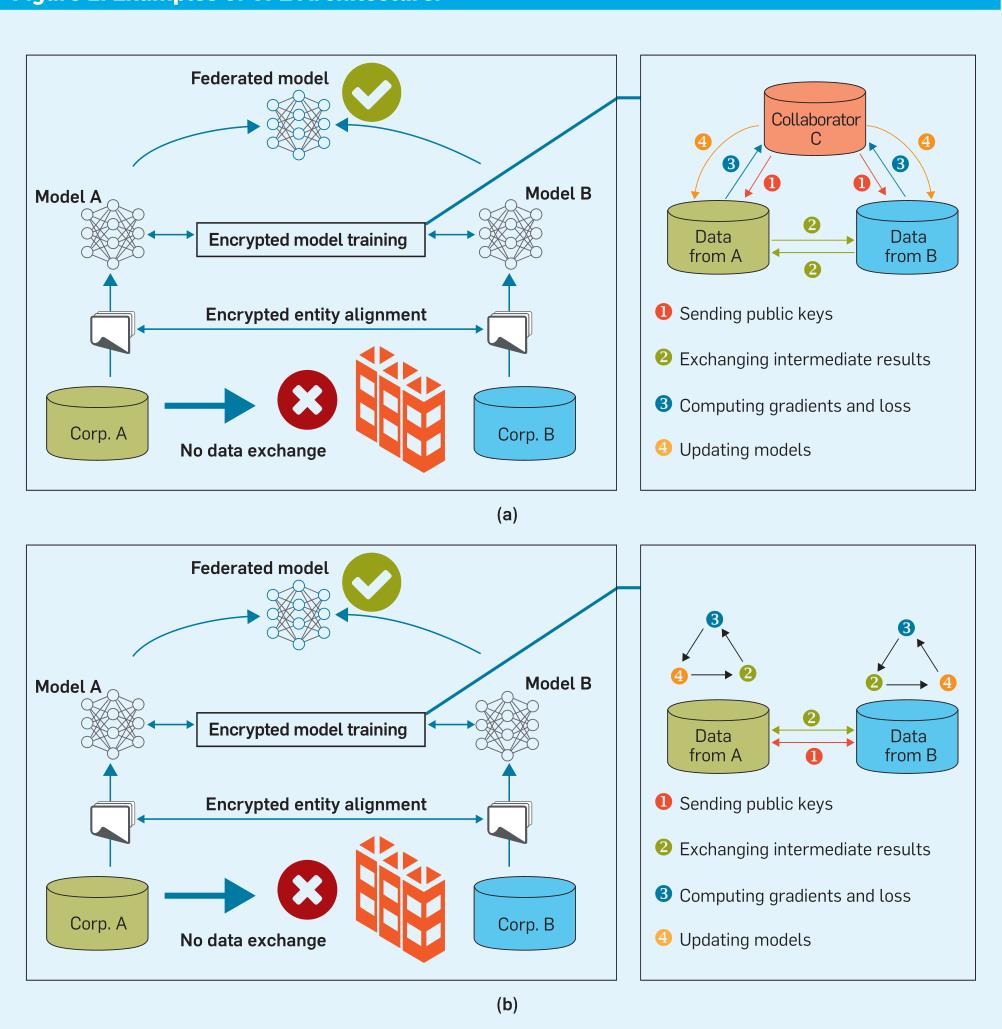
FL系统体系结构可以采用client-server模型,如图2(a)所示,协调者C可以是权威机构(如政府)扮演,或者是安全计算节点。C与A,B之间的通信可以进一步加密(同态加密)防止传输过程中隐私被泄露,当然,协调者C也可以是逻辑实体位于A和B中。FL架构也可以采用对等模型,如图2(b)所示,数据所有者不需要第三方的协助。
以client-server模型为例,在将两个数据集数据样本对齐后,使用VFL加密和安全训练的步骤如下:
- 协调者C创建加密秘钥对分发给A,B;
- A和B加密并交换中间计算结果(梯度、权重);
- A和B各自计算加密的梯度并添加掩码,B同时计算被加密的损失,A和B把加密结果发送给C;
- C解密梯度和损失,把相应结果发送回A和B。A和B去除掩码并更新各自模型参数。
Application Examples
FL可以在符合法律法规的前提下构建跨企业、跨数据、跨领域的AI应用。它在金融、保险、医疗、教育、智慧城市和边缘计算等领域有潜在的应用前景,这里介绍已经在实际中部署的两个案例。
Use Case 1:FedRiskCtrl
第一个例子是FL应用在金融领域。这是微众银行对于小型贷款企业(SME)实施的风控例子。一家发票代理公司A和银行B,A有许多相关的数据特征,如对于第k个SME有
X
m
(
k
)
m
=
1
M
\\left \\X_m^(k)\\right \\_m=1^M
Xm(k)m=1M,银行B有与信贷相关的数据特征,比如对于第k个SME有
X
n
(
k
)
n
=
M
+
1
N
\\left \\X_n^(k)\\right \\_n=M+1^N
Xn(k)n=M+1N以及Y(k),其中N > M。A和B利用VFL合作构建了SME的风控模型。
在训练之前,需要对A和B的SME数据进行对齐(安全实体对齐),之后可以按照图2的训练步骤进行训练。
模型的训练结果接近集中式数据集训练结果,并且由于仅仅由B银行数据建立的模型。
Use Case 2:FedVision
第二个用例是边缘计算中FL的运用。这是微众银行部署的目标检测联邦计算机视觉(federvision)的一个例子。
由于隐私方面的考虑和视频数据传输成本较高,在实践中很难集中采集监控视频数据进行模型训练。使用FedVision,不需要将每个监控公司的边缘云采集到的视频数据上传到中央云进行集中式模型训练。在FedVision中,最初的目标检测模型从FL服务器发送到每个边缘云,然后边缘云使用本地数据进行训练。经过几次本地训练后每个边缘云的模型再加密发送回FL服务器,FL服务器聚合多方模型参数成一个全局模型,并发送回每个边缘云。此过程不断迭代直到满足停止条件。
最终的模型会被分发给参与FL的监控公司,用于目标检测。
Outlook
FL是AI的发展方向,可以帮助AI爆发更大的潜能。虽然现在仍有一系列问题,比如数据所有者和协调器之间通信缓慢或者不稳定、不同数据所有者数据分布不一致等等,此外,为了激励更多参与方参与到FL中来,以及保证公平性和可持续性,还需要对FL的激励机制进行设计。
二、论文总结
本篇论文从需求出发,指出了当今AI遇到的一系列问题,接着简单介绍了FL,说明了FL的优势,最后列举两个实际应用的例子,总结一下,正如文中所说:FL can overcome the challenges of data silos, small data,privacy issues, and lead us toward privacy-preserving AI.(FL可以克服数据孤岛、小数据、隐私问题的挑战,并引领我们走向面向隐私保护的AI。)
三、个人感悟
正如前言预测,这篇论文确实是《联邦学习》的精简版,甚至配图都一样,但是这也只是简单介绍了《联邦学习》的前几章内容,对于激励机制部分只是一笔带过,应用部分举了两个实例,确实很典型,也很有应用前景。总而言之,这篇文章可以说是一篇科普文,文章简短干练,适合对FL感兴趣的初学者阅读,如果已经对FL有所了解可以直接跳过了。
以上是关于阅读笔记Federated Learning for Privacy-Preserving AI的主要内容,如果未能解决你的问题,请参考以下文章
阅读笔记 Pain-FL: Personalized Privacy-Preserving Incentive for Federated Learning
阅读笔记Inverting Gradients -- How easy is it to break privacy in federated learning?
Federated Meta-Learning with Fast Convergence and Efficient Communication 论文阅读笔记+关键代码解读
联邦学习笔记-《Federated Machine Learning: Concept and Applications》论文翻译个人笔记
联邦学习笔记-《A Blockchain-based Decentralized Federated Learning Framework with Committee Consensus》论文翻译
联邦学习笔记-《A Blockchain-based Decentralized Federated Learning Framework with Committee Consensus》论文翻译