阅读笔记Inverting Gradients -- How easy is it to break privacy in federated learning?
Posted HERODING23
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阅读笔记Inverting Gradients -- How easy is it to break privacy in federated learning?相关的知识,希望对你有一定的参考价值。
Inverting Gradients
- 前言
- 一、论文解析
- Abstract
- 1 Introduction
- 2 Related Work
- 3 Theoretical Analysis: Recovering Images from their Gradients
- 4 A Numerical Reconstruction Method
- 5 Single Image Reconstruction from a Single Gradient
- 6 Distributed Learning with Federated Averaging and Multiple Images
- 7 Conclusions
- Broader Impact - Federated Learning does not guarantee privacy
- A Variations of the threat model
- 二、论文总结
- 三、个人感悟
前言
这是一篇来自arXiv: Computer Vision and Pattern Recognition Mar 2020的文章,所谓arXiv,是一个专门为自己的研究占坑的网站,即为了防止自己的idea在论文被收录前被别人剽窃,我们会将预稿上传到arvix作为预收录,因此这就是个可以证明论文原创性(上传时间戳)的文档收录网站。言归正传,这篇被引用近一百次的文章可以说是FL领域比较不错的文章了,并且该文章提出的Inverting Gradients方法来窃取隐私数据的方法是一个非常新颖且有效的思路,值得PPFL学习者深度挖掘,毕竟战胜对手的最好方法就是了解对手,只有懂得攻击者通过什么样的方法或者原理来从梯度中获取隐私数据,才能更好进行针对性的操作,防止隐私被泄露,话不多说,那么我们就开始吧!
PS:解析看不下去的朋友可以直接跳到论文总结部分~
一、论文解析
Abstract
FL的核心就是多方合作训练一个神经网络模型,每个用户通过在本地数据集训练并和服务器进行中间参数的交换(梯度,权重)达到这个目的。这个方法不仅是为了高效训练神经网络,也是为了保护用户的隐私。但是保护的程度究竟如何呢?以往的攻击测试可以说是“自欺欺人”,都是在人为控制的情况下实施的,在现实复杂环境中并没有测试过。事实上,本文通过利用基于对抗性攻击的幅值不变损失的优化策略,证明了利用图像的梯度参数是可以重建出高分辨率的图像的,并且对训练有素的深层网络也是可能的。最后本文讨论了实践中甚至在几次迭代或几张图像上的平均梯度也不能保护FL中的用户隐私。
1 Introduction
近年来随着数据需求和隐私问题的不断升温,FL获得了极大的关注,基本思想就是训练机器学习模型,比如使用损失函数L来优化神经网络的参数θ,这个过程利用的是实例性的数据集xi和标签yi去解决:
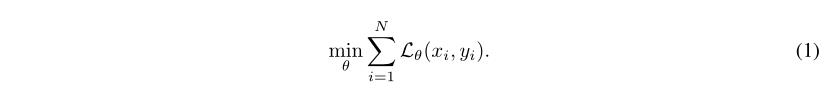
这里设想一个分布式的实现方式,多方用户使用他们的本地数据集,通过与服务器分享梯度,服务器累计梯度信息并更新全局权重,使用梯度下降的方法比如:

更新的参数θk + 1回传给个人用户。(2)中的过程被称为联邦梯度下降(Federated SGD),作为对比,在联邦平均算法中,每个用户在本地计算部分梯度下降,再把更新参数发送回服务器。最终,有关(xi,yi)的信息,会通过部分本地实例的梯度信息聚合后变得模糊,称之为多重图像设置(multi-imagesetting)。这样的FL已经应用在各大应用中,并且被声明为拥有短暂和集中特性的隐私增强的更新:模型的更新携带的信息比原始数据更少,通过数据聚合,原始数据被认为是不可能被恢复的。在这篇文章的工作中,通过分析和经验表明,参数梯度还是会携带关于输入的重要隐私信息。本文的结论是,即使在真实架构下运行多图像联邦平均学习也不能保证所有用户数据的隐私,在每批一百张图像中,仍按会有几张可以恢复。

左图是原始数据,中间图像是从在ImageNet上训练过的ResNet-18进行重建的,右图是从训练过的ResNet-152进行重建的图像。输入数据为中间梯度,两个例子表明图像隐私被泄露。
威胁模型: 本文研究了一个诚实但好奇的服务器,目的是为了恢复用户数据。攻击者允许单独存储处理个别用户的更新,但不能干扰学习算法。攻击者不会修改模型架构,也不会发送恶意的全局参数。并且在参考资料佐证下,这样较弱约束条件下的攻击是微不足道的。
本文首先在学术背景下讨论FL中的隐私限制,再通过图像的梯度反演来说明:
- 对于具有训练参数和未训练参数的真实深度和非光滑的结构,从梯度信息重建输入数据是可能的。
- 只要攻击得当,就不存在“纵深防御”,深层浅层网络一样容易受到攻击。
- 证明了输入到任何全连接层的信息都可以解析地重构,而与剩余的网络体系结构无关。
然后考虑了研究结果对真实情况的影响,发现:
- 在实践中,使用本地的mini-batch,甚至对多达100多张的图像进行局部的梯度平均,可以在多个迭代内,从平均梯度中重建多个独立的输入图像。
2 Related Work
以前研究梯度信息恢复的相关工作仅限于较浅的不切实际的网络,比如单个神经元或者线性层,也有对于四层卷积网络,恢复图像也是可能的,即使有一个非常大的全连接层,他们的工作是首先构建输入图像的“代表”,再用GAN进行改进。后续的研究注意到标签信息可以从最后一层的梯度进行分析计算。这些工作都对模型架构和模型参数进行了强有力的假设,这样使得重构容易,但是违反了我们在此工作中考虑的威胁模型,并且不现实。
PS:笔者理解为你们工作吹的再厉害也不过是过家家,模型都跟你攻击者混的你想要啥他啥不能提供?真要是能够重构出图像还得是在实战中,这才是真本事。
上文所说的工作都讨论了中间恢复机制,这是一个欧几里得匹配项的优化。它的损失函数为:
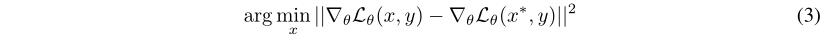
最小化该函数去从传播的梯度∇θLθ(x, y)恢复原始输入数据x,该优化问题由 L-BFGS求解器求解。
一个比完全重建输入图像相比更简单的例子是从本地的更新中恢复输入属性,比如在人脸识别系统中识别出人是否佩戴帽子。甚至与当前任务无关的属性信息也可以被恢复过来。
我们的问题声明进一步与模型反演相关,其中训练图像在训练后从网络参数中恢复。但是如果没有额外信息的提供,模型反演在更深的网络情况下是一个挑战。另一个密切相关的任务是视觉代表中进行反演,给定神经网络的某个中间层的输出,重构合理的输入。这个过程可能会泄露一些信息,例如一般的图像组成、颜色,但是根据给定层,它只重建相似的图像,如果神经网络没有明确被选为可反演的(是不是如果神经网络并不能做到大部分层都能反演,那么最多只能重建到相似的效果)。正如我们稍后所证明的那样,从视觉表示中进行反演比从梯度信息中恢复要困难得多。
3 Theoretical Analysis: Recovering Images from their Gradients
为了从理论的角度理解FL中隐私泄露的问题,首先分析数据x∈Rn是否可以从梯度∇θLθ(x, y)中恢复。
由于x和∇θLθ(x, y)数据维度不同,重建效果肯定与参数数量p和输入像素数量n的问题,p < n,重建难度至少和从不完整数据中恢复图像一样困难,但是如果p > n,对于梯度反演的困难就只在于梯度算子的非线性及其作用条件。
全连接层在本文问题中有很大作用,本文证明了不管在哪一层,理论上对于全连接层的输入总是能从梯度中被推导出来
3.1 Proposition(命题)
考虑到一个神经网络,包含一个有偏的全连接层,在它之前仅有全连接层(可能也是有偏),进一步假设对于任何全连通的层,对应层输出的损失函数L的导数至少包含一个非零项。这样,网络的输入就可以由网络的梯度唯一地重构。
证明: 考虑无偏的全连接层的映射(xi与输出的映射),比如一个非线性的RELU:xl+1 = maxAlxl, 0,矩阵Al的维度是匹配的。假设对于一些索引i来说,
d
L
d
(
x
l
+
1
)
i
≠
0
\\fracdLd(x_l+1)_i\\neq 0
d(xl+1)idL=0,根据链式法则,xl可以由
(
d
L
d
(
x
l
+
1
)
i
)
−
1
⋅
(
d
L
d
(
A
l
)
i
,
:
)
T
(\\fracdLd(x_l+1)_i)^-1\\cdot (\\fracdLd(A_l)_i,:)^T
(d(xl+1)idL)−1⋅(d(Al)i,:dL)T计算得出。只要关于某一层输出的导数是已知的,那么就能允许迭代计算某一层的输入,添加偏差可以解释为xk 向xk+1=xk +bk 的映射,并且
d
L
d
x
k
=
d
L
d
b
k
\\fracdLdx_k=\\fracdLdb_k
dxkdL=dbkdL。
有趣的是许多流行的网络架构使用全连接层作为其最后的预测层,因此可以根据先前层的输出预测那些模块的输入,从而使隐私信息暴露给攻击者。最后还有一个结论,对于以完全连接层结束的任何分类网络,从参数梯度重建输入比从最后一个卷积层反转视觉代表更容易(即全连接层比卷积层的输出更好重建输入)。
4 A Numerical Reconstruction Method
由于图像分类网络很少从完全连接层开始,所以考虑输入数值重建。以往的重建算法依赖于两个组件,公式(3)的欧式成本函数,以及通过L-BFGS优化。但是对于现实体系结构,这并不是最优的。如果把梯度参数分解为范数大小和方向,会发现大小仅仅捕获有关训练状态的信息:测量数据点相对于当前模型的局部最优性。相比之下,梯度的高维方向可以携带重要信息,因为两个数据点之间的角度量化了一个数据点向另一个数据点的梯度步长时预测的变化。所以本文决定用以角度为基础的损失函数,即余弦相似性,l(x, y) = <x, y>/(||x||||y|||),与公式(3)相比不是为了找到与观测梯度最匹配的梯度的图像,但要找到导致模型预测发生类似变化的图像作为标注数据(未观察)。这相当于最小化欧几里得代价函数,如果另外将两个梯度向量正规化的话。
我们进一步将我们的研究空间限制在[0, 1]范围内的图像,仅将总变化作为简单图像添加到总体问题之前,参见:
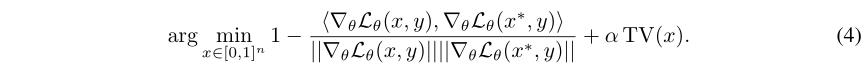
其次,作者的目标是通过最小化依赖(间接的,通过梯度)于中间层输出的量来寻找给定区间内的一些输入x,这与寻找神经网络的对抗性扰动相关。因此作者仅仅根据其梯度的符号来最小化公式(4),使用Adam优化,使其步长具有衰减的效果。注意到有符号的梯度仅仅影响Adam动量的第一和第二阶,根据动量的累计(Adam中的动量),实际的更新仍然是无符号的,所以图像还是可以准确恢复。
应用这些技术可以得到图1中观察到的重建。具体实现见链接。
PS:我们可以假设(4)中的标签y是未知的,因为标签信息是可以在分类问题中解析重建的。所以标签信息也是能知道的。
 图2:网络架构基准比较。显示来自CIFAR-10验证集的前6个图像。
图2:网络架构基准比较。显示来自CIFAR-10验证集的前6个图像。
5 Single Image Reconstruction from a Single Gradient
先来关注从单张图片中重建图像的例子。单个图像重建先前都是基于浅层、平滑未训练的网络进行的,而作者所提出的方法更先进。
Comparison to previous approaches.
第一个对比验证的对象是基于欧几里得损失函数和通过L-BFGS优化的方法。这种方法经常因为错误的初始化而失败,所以作者允许对L-BFGS解算器进行16次重启的慷慨设置。 为了定量比较,作者使用了与第一个对比对象相同的浅层平滑CNN(LeNet(Zhu))以及ResNet架构,测量了通过前100张来自验证集的32 × 32 CIFAR-10图像重建结果的平均PSNR(峰值信噪比),并且都使用了训练后和未训练的参数。
表1:CIFAR-10验证数据集的第一批图像在两个不同网络上的100个实验的峰值信噪比平均值和标准偏差(使用训练过和未经训练的参数)。

表一对比了两种方法在相同的数据集下,运行在两种模型中的测量结果,可以发现前者在未训练、浅层平滑的网络中效果很好,我们的方法如图二所示,提供了可识别的图像,并且在经过训练的ResNet的真实环境中工作得特别好。 有趣的是,尽管PSNR较低,经过训练的ResNet上的重建比未经训练的ResNet上的重建具有更好的视觉质量。这让作者可以在更现实的设置中研究训练的网络参数的效果。
Trained vs. untrained networks.
如果一个网络经过训练,并且有足够的能力使其在不同的输入条件下的损失函数的梯度Lθ为零,那么很明显,它们永远无法与它们的梯度区分开来。但是在实际环境中,由于随机梯度下降、数据增强和训练epochs有限,梯度很少完全为0,虽然我们确实观察到图像梯度在经过训练的网络中比在未经训练的网络中具有小得多的幅度,但是我们在(4)中的方法仍然从经过训练的梯度的方向恢复了重要的视觉信息。
 图3:从训练ResNet-152的参数梯度进行单图像重建。上面:标注图像,下面:重建图像。每张图片泄露的信息量很大程度上取决于图片的内容。
图3:从训练ResNet-152的参数梯度进行单图像重建。上面:标注图像,下面:重建图像。每张图片泄露的信息量很大程度上取决于图片的内容。
作者观察到在训练的网络上两个普遍的影响如图3所示:
- 重建会隐式地偏向训练数据中同类的典型特征。
- 在训练神经网络时使用的数据增强导致训练的网络使对象的定位更加困难。
Translational invariant convolutions(平移不变卷积).
通过测试传统使用zero-padding的CNN和带zero-padding的平移不变CNN结果,传统的结果可以恢复,而平移不变的结果原始对象被分离,所以常见的zero-padding是隐私风险的来源。
 图4:多个ResNet架构的原始图像重建(左)。PSNR值是指显示的图像,而平均PSNR是在前10张CIFAR-10图像上计算的。标准偏差是在给定架构下一个实验的平均标准偏差。ResNet-18体系结构以三种不同的宽度显示。
图4:多个ResNet架构的原始图像重建(左)。PSNR值是指显示的图像,而平均PSNR是在前10张CIFAR-10图像上计算的。标准偏差是在给定架构下一个实验的平均标准偏差。ResNet-18体系结构以三种不同的宽度显示。
Network Depth and Width.
对于分类精度,每层channel的深度和数量是非常重要的参数,所以研究它们对重建的影响。图4可以看出,随着信道数量的增加,重建质量显著提高。然而,网络宽度越大,实验成功的方差也越大。虽然通道越大,攻击者计算量更大,但是还原准确度更高了。(你通道小我还重构不起来,现在虽然累一点但至少我能重构成功了)
观察重构结果,随着网络深度增加,对攻击的衰减是很小的,所以更深的网络如ResNet-152也是可行的。
6 Distributed Learning with Federated Averaging and Multiple Images
联邦平均学习不是仅仅根据本地数据计算网络参数的梯度,而是发送给服务器前对本地数据进行多轮的更新步骤。用户端数据为n个图像,E是epochs的次数,n/B为每epoch需要随机梯度下降的次数,B是mini-batch的大小,所以总共是 E * n/B次本地更新步骤。每个用户将本地更新的参数
Θ
ˉ
i
k
+
1
\\bar\\Theta _i^k+1
Θˉik+1发送给服务器,服务器通过平均所有用户发来的参数更新全局参数
Θ
k
+
1
\\Theta ^k+1
Θk+1。
 图5:说明局部更新步数和学习率对重建的影响。图片上是更新步数和学习率,下面是对应PSNR的值。
图5:说明局部更新步数和学习率对重建的影响。图片上是更新步数和学习率,下面是对应PSNR的值。
经验表明,即使设置FL平均输入n>=1的图像也可能受到攻击。为此作者尝试通过本地更新
Θ
~
i
k
+
1
−
Θ
k
\\tilde\\Theta _i^k+1 - \\Theta ^k
Θ~ik+1−Θk来重建每批为n的图像数据集,并通过选择不同的n,E和B实现。我们所有的实验都使用未经训练的ConvNet。
 图6:每批100张CIFAR-100图像在ResNet32-10模型上的隐私泄露。展示的是五张最容易识别的图像。虽然大部分图像无法识别,但是表明隐私在大批量设置下仍然泄露。
图6:每批100张CIFAR-100图像在ResNet32-10模型上的隐私泄露。展示的是五张最容易识别的图像。虽然大部分图像无法识别,但是表明隐私在大批量设置下仍然泄露。
表2:各种联邦平均设置的PSNR统计数据,对CIFAR-10验证数据集的前100张图像进行了平均实验。
 Multiple gradient descent steps, B = n = 1, E > 1:
Multiple gradient descent steps, B = n = 1, E > 1:
图像5显示了图像为1的情况下在不同的epoch和学习率的重建情况。可以发现即使是100次epochs,重建质量也不受影响。
Multi-Image Recovery, B = n > 1, E = 1:
作者证明了利用提出的方法处理100个平均梯度信息是可以恢复一些信息的,虽然大部分图像是无法识别的,图像6说明了这一点。让人惊讶的是,批处理引起的扭曲是不一致的,有的是高度扭曲,有的只是一定程度上。
General case
作者还考虑了在每个小批量梯度步骤中使用全部局部数据的子集的多个本地更新步骤的一般情况。所进行的实验结果见表2。对于每个设置,作者在CIFAR-10验证集上执行100次实验。对于一个mini-batch中的多幅图像,我们只使用不同标签的图像,避免了同一标签的重建图像的排列歧义。可以预料,单图像重建最容易受到攻击。多图像任务尽管PSNR较低,但是仍有隐私被泄露。所以,多个epoch并不会使重建问题更困难。
7 Conclusions
FL虽然是分布式计算的发展趋势,但是对于隐私的保护并没有很好诠释。作者解释了可能的攻击途径,分析讨论了对不同的架构模型的有效性。本文的实验结果是在现代计算机视觉架构下获得的图像分类。它们清楚地表明,可证明的差分隐私仍然是保证安全的唯一方法,甚至可能对于大批量数据也是这样。
Broader Impact - Federated Learning does not guarantee privacy
这里可以说是总结与展望吧,先是说了先前人们对于FL报以太高的期望了,以为FL就是万能的,殊不知它仍然有很大隐私泄露的风险。本文提出的方法甚至能够在100张批图像的梯度中恢复图像。所以PPFL需要受到更大的重视,现在有基于差分隐私的FL,但是这会显著降低模型准确性。所以对PPFL的进一步研究将会很有意义。
A Variations of the threat model
如Introduction中所讨论的,考虑一种诚实且好奇的模型,要预防这种情况的威胁,主要有两种方法:第一种是改变体系结构,第二种是保持体系结构是无恶意的,但是改变发送的全局参数。
A.1 Dishonest Architectures
服务器在honest-but-curious模型下运行,不会恶意修改模型让重构更容易。如果考虑到修改这一点,可以在第一层放置完全连接层或者直接通过连接将输入连接到网络的末端。稍微不明显的操作可以是修改模型让其可以存储可逆块,这些块允许从输出恢复输入。如果服务器恶意地为每个批处理示例引入单独的权重或子模型,那么这也允许恢复任意大批的数据。
A.2 Dishonest Parameter V ectors
即使服务器固定为诚实方,恶意选择全局参数也会显著影响重构质量。比如在不包含跨度和平坦卷积特征的网络架构中,不诚实的服务器可以设置所有的卷积层来表示身份,将输入不改变就移动到分类层,这样在分类层就可以分析计算输入。
 图7:标签翻转。当最终分类层参数中的两行被排列时,图像可以很容易重建。在每个输入图像下面是梯度幅值,在每个输出图像下面是其PSNR。将这些结果与图9中附加的例子进行比较。
图7:标签翻转。当最终分类层参数中的两行被排列时,图像可以很容易重建。在每个输入图像下面是梯度幅值,在每个输出图像下面是其PSNR。将这些结果与图9中附加的例子进行比较。
这样特定的参数选择是很可能被检测到的,另一个更微妙的方法是优化发送给用户的参数,以便从这些参数获得最大的重构质量。虽然这样的攻击可能很难在用户端检测到,但它也将是非常密集的计算。
Label flipping. 根据第5节,小梯度包含较少信息。提高这些梯度方法是排列分类层中权重矩阵和偏差的两行,可以有效翻转标签的语义含义。这种攻击很难检测,但是可以有效欺骗用户。从图7中可以看出,由于消除了训练模型的影响,该机制可以在提高PSNR分数的情况下进行可靠的重建。
二、论文总结
论文后面还有十页左右的内容,主要描述的是实验的一些细节问题,包括模型选择、参数调节,以及论文中提及的部分公式的证明,本篇笔记主要是以了解梯度反转重建图像的思想,思考如何设计避免梯度反转的方法为目的,故不再继续解析下去(如果日后觉得有必要仍会补充),感兴趣的读者可以继续深入阅读。
回顾一下整篇文章,其实最困难的部分在于理论分析那一部分(即3、4section部分),一共一页多内容就花费了我整整一天时间,究其原因还是在咬文嚼字上下了太大功夫,毕竟这是全篇的关键部分,一旦某个部分理解或者翻译出现偏差,就会造成整篇论文读不通的死局。
最后还是总结一下,毕竟写了那么多废话,一般人可是没有性子耐下心来看的。
FL是一种被世人误解为更高效和保护隐私的分布式机器学习方法,然而这只是FL的学习方式给人带来的一种假象,所谓的梯度传输更新全局参数的方法依然漏洞百出,结合链式法则的方法,在拥有输出梯度的情况下,不难算出输入层的x。
本文作者首先简单介绍了一下FL,接着就构建Threat model,在设定的威胁模型下进行攻击。在相关工作部分,作者介绍了现有的梯度反转攻击方法是基于欧几里得损失函数和通过L-BFGS优化的方法,这种方法是寻找梯度与观测梯度最相近的图像,如果把向量分解为范数和方向的话,这就是寻找范数相近的图像,但是范数仅仅包含测量数据点相对于当前模型的局部最优性,相比之下,高维方向可以携带重要信息,这就是本文提出的用梯度之间的余弦相似性作为损失函数去重构梯度的方法,它可以找到导致模型预测发生类似变化的图像作为标注数据。
在section3作者证明了梯度反转的理论可行性,这对全连接层很有用,但是图像分类网络很少从完全连接层开始,所以在section4中作者提到了数值重建方法,该方法用梯度之间的余弦相似性作为损失函数、使用Adam作为优化器更新参数。
在section5中,考虑是单张图像重构的情况,在两种方法下,现有的方法只能在未训练、浅层网络中有好的效果,而作者提出的方法在训练过、深层的网络表现都要更好些(用PSNR衡量)。
section6是在联邦平均学习环境下的实验,作者使用提出的方法,在控制变量的条件下,观察模型的各个参数变化对重构结果的影响,首先epochs的大小对重构没有明显的影响,学习率的大小会对重构产生明显影响,对于每批次多图像的情况,虽然重构结果大部分无法识别,但是仍然有部分图像重构成功,说明两点:
- mini-batch > 1情况仍有隐私泄露风险;
- 批处理引起的扭曲是不一致的,有的是高度扭曲,有的只是一定程度上。
最后是section7,作者总结本文内容,并提出现有的PPFL隐私保护方法存在计算成本和隐私保护无法平衡的窘境,PPFL仍然需要进一步的研究。
三、个人感悟
读完这篇论文对我最大的感受就是长见识了,原来梯度可以被这样攻击,怪不得要有PPFL的出现,不然我还真的被FL的外表所迷惑住了,当然在之前阅读PPFL的综述的时候,有许多防止梯度被攻击的方法, 比如同态加密、差分隐私、安全多方计算等等,但是这些又面临一系列问题,比如隐私安全和计算效率不平衡(就像是本来让你喊别人来吃饭,你非要发个摩斯代码让别人破译半天),有的隐私真的那么重要吗,真的值得牺牲那么大的计算效率去保护隐私吗?(仅仅是个人的一些想法,欢迎有不同的观点来讨论)还有差分隐私的方法会降低数据的效能,虽然效率高又简单,但是有时候数据真的就不能够差了那一点效能。PPFL方法组合的方法是我认为比较合适的方法去保护数据的隐私,还有在不同的FL应用场景,也要根据实际情况去使用PPFL方法,而不是盲目使用某一种方法。
很遗憾因为时间关系附录部分没有详细去看,里面涉及很多公式推导和方法的设计原理,确实值得一看,希望在日后可以更新本篇博客,力求完整~
以上是关于阅读笔记Inverting Gradients -- How easy is it to break privacy in federated learning?的主要内容,如果未能解决你的问题,请参考以下文章