innodb冷热LRU链表原理
Posted wen-pan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了innodb冷热LRU链表原理相关的知识,希望对你有一定的参考价值。
一、冷热LRU链表引入
我们知道mysql是将数据存放在磁盘上的并且以页的形式来管理这些磁盘上的数据。磁盘的读写涉及到很多io操作,所以磁盘的访问是一个很慢的操作。为了提高数据的读写效率innodb会将一些数据缓存到内存中(buffer pool),在访问数据的时候首先查找内存,如果内存中有则直接访问,如果内存中没有,则按照一定的规则将数据加载到内存中。
但是内存一般是比较昂贵的,一般不会将所有的数据都缓存到内存中(buffer pool),我们希望将一些热点数据缓存到内存中,将内存中那些不经常访问的数据逐渐淘汰以提高缓存的命中率。所以innodb存储引擎提供了[冷热LRU链表]来管理和区分这些热数据和冷数据。
二、普通LRU链表
我们知道innodb引擎是以page为最小单位来管理数据的,一个页面中包含多条数据。每当要使用到某个页面中的数据就会将该条数据对应的page加载到内存中。那么数据页加载到内存中以后是如何进行管理的呢?如何知道这个页面最近是否有被访问过呢?在内存紧张的时候如何知道这个页面是否可以被淘汰呢?innodb使用链表来将这些数据页串联起来。
1、普通LRU链表工作流程介绍
我们先来看一下使用不区分冷热数据的普通LRU链表来管理数据页的流程以及存在的问题:
- 假如我们执行SQL语句
select * from tbl where id = 1,这条语句会将id = 1这条数据对应的page加载到buffer pool中,并且将该页添加到LRU链表的头节点。 - 又执行SQL语句
select * from tbl where id = 100,这条语句会将id = 100这条数据对应的page加载到buffer pool中,并且将该页添加到LRU链表的头节点 - 又执行SQL语句
select * from tbl where id = 200,这条语句会将id = 200这条数据对应的page加载到buffer pool中,并且将该页添加到LRU链表的头节点 - 又执行SQL语句
select * from tbl where id = 300,这条语句会将id = 300这条数据对应的page加载到buffer pool中,并且将该页添加到LRU链表的头节点

按照上述流程我们知道每次访问一个数据页我们就将这个数据页重新添加到LRU链表的头部。越靠近链表头部的page节点则说明该节点最近被访问到过,越靠近LRU链表尾部的节点,越说明该节点已经很久没有访问了。所以当内存吃紧的时候我们采用从LRU链表尾部淘汰法,将链表尾部的page给淘汰掉,保留链表靠近头部的那些最近被访问过的page。这个方案看上去没有问题,但实际上仔细琢磨就会发现有很大的漏洞。
2、普通LRU链表缺点分析
按上述使用普通LRU链表来管理buffer pool中的page页面会有很大的漏洞,下面是一些漏洞分析
①、预读
innodb为了提高效率,在满足某些条件的情况下innodb预测某些页面可能会被用到,会预先读取某些页面到buffer pool中。
- 线性预读:innodb规定,如果顺序访问某个区的页面数量超过了系统变量
innodb_read_ahead_threshold的值,那么就会触发一次异步读取,读取下一个区的所有page并放入到buffer pool中 - 随机预读:innodb规定,如果某个区中的连续13个page都被加载到buffer pool中(不管是否是连续的page),那么innodb认为这个区中的其他page有很大的概率也会被用到,所以也会触发一次
异步读取,将这些page读取到buffer pool中。默认关闭,可使用innodb_random_read_ahead参数开启随机预读。
预读本来是好事儿,为了提高效率而设计,但是也会造成一些问题,比如:这些预读的界面有可能不会被使用到,但是当这些page被读取到buffer pool中的时候会添加到LRU链表的头部节点,就会将原来LRU链表头部节点的某些热点page挤到LRU链表尾部。在内存回收的时候便会将那些热点page回收掉。造成了缓存命中率大大降低。
②、全表扫描
在某些情况下我们可能需要编写全表扫描的SQL语句来查询数据,在全表扫描的时候便会将表中所有的数据页都加载到buffer pool中,并且添加到LRU链表。但是这些被全表扫描添加到LRU链表中的page有可能很少被使用到(也有可能就只使用这么一次),但同样也会将原来LRU链表头部节点的某些热点page挤到LRU链表尾部。在内存回收的时候便会将那些热点page回收掉。造成了缓存命中率大大降低。
③、普通LRU链表缺点总结
- 加载到buffer pool中的page不一定被用到
- 如果有非常多使用频率偏低的page被同时加载到buffer pool中,则可能会把那些使用频率非常高的page从buffer pool中淘汰掉,降低缓存命中率。
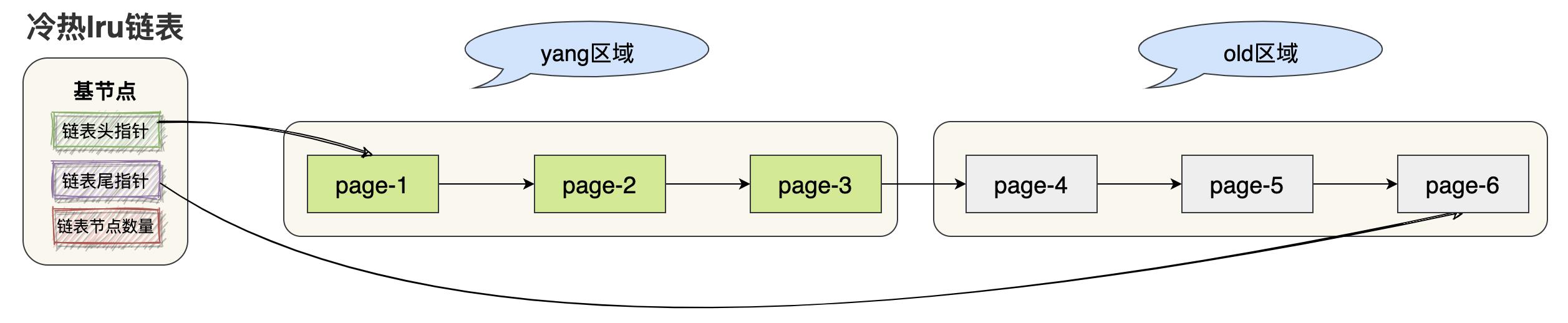
三、冷热LRU链表
①、冷热LRU链表概念介绍
既然普通LRU链表有很明显的[预读]和[全表扫描]缺点,那么能不能采取一些优化方案来提高缓存的命中率呢?这就是[冷热LRU链表]!!!innodb将普通的LRU链表划分为两部分
- 一部分存储使用频率非常高的缓冲页,这一部分链表也称为热点数据,或者称为yong区域。
- 另一部分存储使用频率不是很高的缓冲页,这一部分链表也称为冷数据,或者称为old区域。
- 需要注意的是:是按照一定的比例将LRU链表划分为两部分的,而不是某些节点固定位于yong区域,某些节点固定位于old区域。随着程序的运行某些节点的所属区域也可能发生变化。
- 默认是old区域占LRU链表的37%
- 可以通过
innodb_old_blocks_pct参数来调整old区域占LRU链表的比例大小。
②、针对于预读
innodb规定,针对于第一次由磁盘读取到buffer pool中的页面,该page会被放到old区域的头节点。这样一来预读到buffer pool中而不进行后续访问的页面就会逐渐从old区域逐出,而不会影响到yong区域中使用比较频繁的缓冲页(page)
③、针对于全表扫描
对于全表扫描,虽然首次加载到buffer pool中的页面会被放到old区头部,但后续会被马上访问到,每次进行访问时又会将该页面放到yang区头部,这样仍然会被哪些使用频率比较高的page给排挤下去。
那么我们可不可以当第一次访问某个page的时候不将他一定到yong区域头部,后面两次及其以上访问时才移动到yong区域头部呢?
其实是行不通的,因为一个page中包含了很多条数据,每次去读取page中的数据都算一次访问。比如全表扫描一个page时,该page中有1000条数据,那么该page就会被访问1000次。这种情况下全表扫描时该page仍然会被移动到yong区域头部。
如何解决
innodb规定,在对old区域中的某个page第一次访问时,就记录下这个访问时间,如果后续访问这个page的时间与第一次访问的时间在某个时间间隔内,那么该page就不会从old区移动到yang区头部,否则就将他移动到yang区域头部。该时间间隔由参数innodb_old_blocks_time控制,默认是1秒,可自己更改。
也就是说old区的某个page如果第一次访问和最后一次访问的时间间隔小于1秒,那么该page是不会加入到yang区域的。很明显全表扫描时,多次访问一个page(也就是读取同一个page中的多条记录)的时间不会超过1秒。
以上是关于innodb冷热LRU链表原理的主要内容,如果未能解决你的问题,请参考以下文章
MySQL: 15 MySQL是如何基于冷热数据分离的方案去优化LRU算法的
Mysql原理篇之Innodb如何调整磁盘与CPU之间的矛盾--07