浅谈Hive
Posted 又菜又爱写 ᥬ᭄ᥬ᭄
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅谈Hive相关的知识,希望对你有一定的参考价值。
是什么
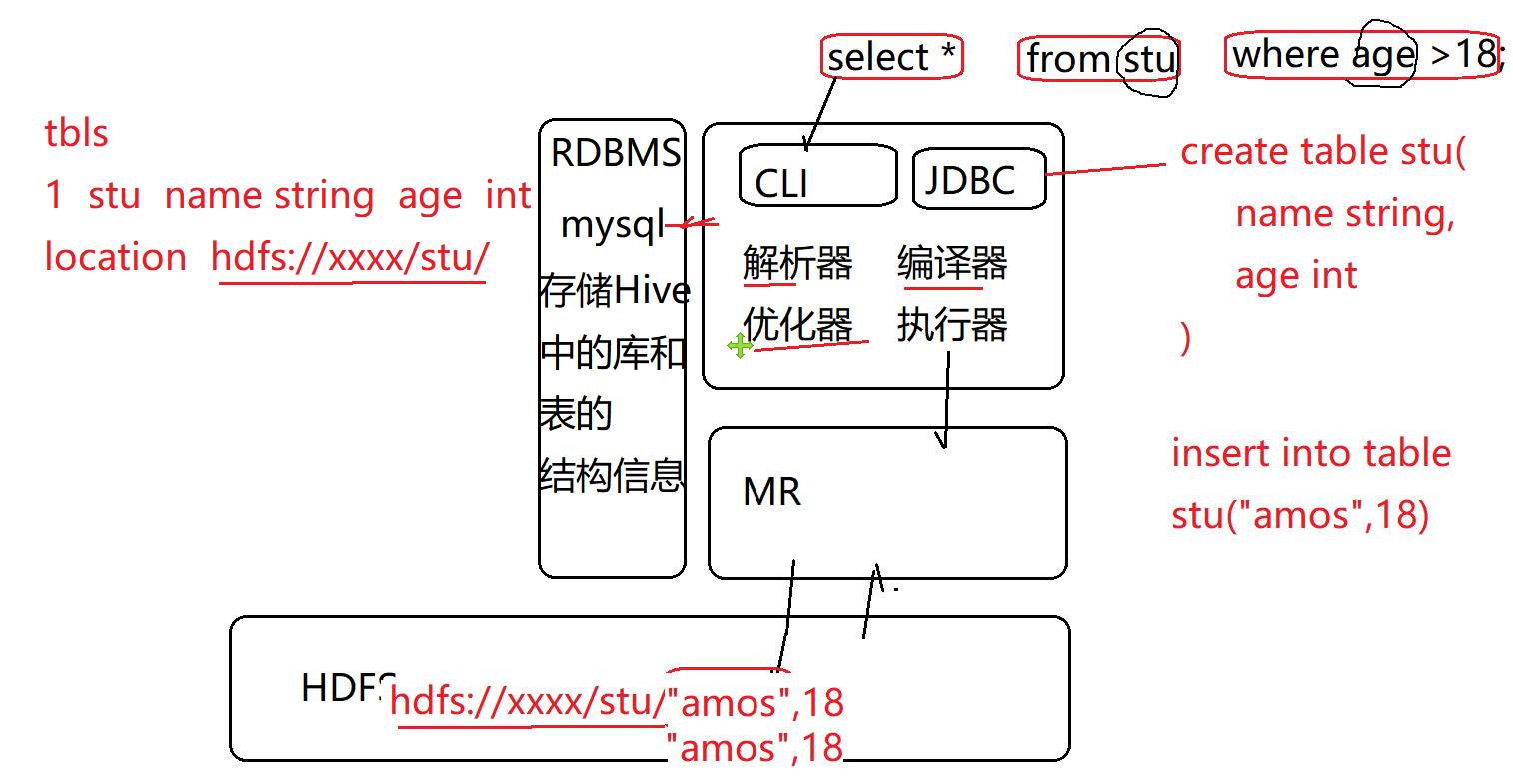
Hive是Hadoop生态的数据仓库工具
Hive将存储在HDFS上的文件映射为关系表
通过解析开发者提交的SQL语句,将SQL转换成MR任务,提交到Hadoop执行
Hive提供了命令行客户端和JDBC
Hive架构
Hive 安装
将Hive的元数据库替换为mysql
- hive自带关系型数据库derby用于存储hive中的库和表的结构信息(metadata)
- 生产环境中通常将derby替换为mysql等性能更好的开源数据库
- yum
yum install mysql-
使用安装包进行离线安装
- 下载mysql安装包
- 使用脚本自动化安装
#!/bin/bash
echo -e "\\033[4;40;31m欢迎使用mysql离线安装自动化脚本 v1.0\\033[0m"
echo -e "\\033[4;40;31m作者:Amos QQ:410507803 E-Mail:amos@amoscloud.com\\033[0m\\n"
read -p "请输入mysql8的zx压缩包文件所在路径(eg:/opt/mysql8.xxx.xz):" FILE_PATH
read -p "请输入想要安装的目录(eg:/usr/local/mysql):" DEST_PATH
rpm -e --nodeps $(rpm -qa | grep mariadb)
echo -e "\\033[40;32m (1/13)正在解压,请耐心等待解压过程约1-3分钟... \\033[0m"
tar Jxf $FILE_PATH -C .
echo -e "\\033[40;32m 解压完成 \\033[0m"
echo -e "\\033[40;32m (2/13)移动加压后的文件到$DEST_PATH \\033[0m"
mv mysql-8*x86_64 $DEST_PATH
echo -e "\\033[40;32m (3/13)添加环境变量$DEST_PATH \\033[0m"
echo "export MYSQL_HOME=$DEST_PATH" >>/etc/profile
echo 'export PATH=.:$MYSQL_HOME/bin:$PATH' >>/etc/profile
source /etc/profile
echo -e "\\033[40;32m (4/13)创建data目录 \\033[0m"
mkdir $DEST_PATH/data
echo -e "\\033[40;32m (5/13)创建my.cnf配置文件 \\033[0m"
rm -rf /etc/my.cnf
echo "
[client]
port=3306
socket=/tmp/mysql.sock
[mysqld]
port=3306
user=mysql
socket=/tmp/mysql.sock
basedir=$DEST_PATH
datadir=$DEST_PATH/data
log-error=$DEST_PATH/error.log
pid-file = $DEST_PATH/mysql.pid
transaction_isolation = READ-COMMITTED
character-set-server = utf8
collation-server = utf8_general_ci
lower_case_table_names = 1
" > /etc/my.cnf
echo 'sql_mode = "STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION,NO_ZERO_DATE,NO_ZERO_IN_DATE,ERROR_FOR_DIVISION_BY_ZERO"' >> /etc/my.cnf
echo -e "\\033[40;32m (6/13)创建mysql组 \\033[0m"
groupadd mysql
echo -e "\\033[40;32m (7/13)创建mysql用户并加入mysql组 \\033[0m"
useradd -g mysql mysql
echo -e "\\033[40;32m (8/13)修改安装目录权限和所有者 \\033[0m"
chown -R mysql:mysql $DEST_PATH
chmod -R 755 $DEST_PATH
echo -e "\\033[40;32m (9/13)初始化mysql \\033[0m"
$DEST_PATH/bin/mysqld --initialize --user=mysql
echo -e "\\033[40;32m (10/13)尝试启动mysql \\033[0m"
$DEST_PATH/support-files/mysql.server start
echo -e "\\033[40;32m (11/13)将mysqld添加为服务并设置开机自启动 \\033[0m"
cp $DEST_PATH/support-files/mysql.server /etc/init.d/mysqld
chmod 755 /etc/init.d/mysqld
chkconfig --add mysqld
chkconfig --level 345 mysqld on
echo -e "\\033[40;32m (12/13)重启mysql \\033[0m"
service mysqld restart
echo -e "\\033[40;32m (13/13)读取临时密码 \\033[0m"
TEMP_PW=$(cat $DEST_PATH/error.log | grep 'password' | awk -F' ' 'print $NF')
echo -e "
\\033[40;32m mysql的初始临时密码为:$TEMP_PW \\033[0m
\\033[40;32m 使用初始密码登录mysql后,您可以使用如下SQL修改初始密码: \\033[0m
\\033[40;33m ALTER user 'root'@'localhost' IDENTIFIED BY 'a123456'; \\033[0m
\\033[40;32m 使用如下SQL添加可远程访问的root用户: \\033[0m
\\033[40;33m CREATE USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY 'a123456'; \\033[0m
\\033[40;33m GRANT ALL ON *.* TO 'root'@'%'; \\033[0m
\\033[40;33m FLUSH PRIVILEGES; \\033[0m
\\033[40;32m 3秒后将使用初始密码登录mysql,感谢您的使用 \\033[0m
"
sleep 3
mysql -uroot -p$TEMP_PW安装Hive
-
上传解压
-
修改配置文件
- hive-env.sh
HADOOP_HOME=/opt/hadoop-2.7.7
HIVE_CONF_DIR=/opt/hive-2.3.9/conf
JAVA_HOME=/opt/jdk1.8- hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://bd0701:3306/metastore</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
</configuration>- 将mysql驱动包上传到hive的lib中
- 初始化metastore./schematool -initSchema -dbType mysql- 配置环境变量
echo 'export HIVE_HOME=/opt/hive-2.3.9' >> /etc/profile
echo 'export PATH=$HIVE_HOME/bin:$PATH' >> /etc/profile
source /etc/profileCOPY-
启动hive
-
hive提供了控制台操作方式
# hive 用于启动终端 hive -
hive提供JDBC服务器的远程连接方式
- 修改hdfs的访问权限
修改hadoop core-site.xml文件<property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> - 分发配置文件,并重启HDFS集群
- 使用hiveserver2 开启hive的JDBC服务器
- hive提供beeline客户端连接hive2服务
- 修改hdfs的访问权限
-
beeline
beeline> !connect jdbc:hive2://hostname:10000
beeline> root
beeline>- 数据库连接工具远程连接 IDEA
Hive操作
DDL
- 表
-- 查看表
show tables;
-- 创建表
-- 创建 外部 表 如果不存在 表名
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
-- (列名 数据类型 字段备注,)
[(col_name data_type [COMMENT col_comment], ...)]
-- 表备注
[COMMENT table_comment]
-- 设置表的分区字段 (字段名 类型)
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
-- 指定分桶 按照 (字段名)
[CLUSTERED BY (col_name, col_name, ...)
-- 在分桶过程中 按照某些字段排序
[SORTED BY (col_name [ASC|DESC], ...)]
-- 设置桶的个数
INTO num_buckets BUCKETS]
-- 行 格式
[ROW FORMAT
-- 受限于
DELIMITED
-- 字段 结束 于 字符
[FIELDS TERMINATED BY ' |- \\u0001']
-- 集合 元素 结束 于
[COLLECTION ITEMS TERMINATED BY ',']
-- 映射结构的kv之间的分隔符
[MAP KEYS TERMINATED BY ':']
-- 设置行结束符
[LINES TERMINATED BY '\\n']]
-- 设置文件的存格式
-- text
-- ORC 是一种列式存储的数据格式,用于海量数据的存储和查询
[STORED AS file_format]
-- 设置当前表读取的HDFS路径
[LOCATION hdfs_path]
-- 查看表详情
desc table_name;
desc extended table_name;
desc formatted table_name;
-- 删除表
drop table table_name;- 截断表
-- 保留表的结构 移除所有的表内容
-- 只有管理表才能进行截断操作
truncateDML
- Hive底层将表的内容保存在HDFS,HDFS不支持文件的随机修改
- 所以Hive也不支持表的字段修改和数据的update操作
数据导入
- load data
-- 加载数据 本地 从某个路径 可以是本地路径或者hdfs路径
load data [local] inpath '/root/data/student.txt'
-- 是否覆盖 加载到 某个表
[overwrite] into table student
-- 添加分区字段
[partition (partcol1=val1,…)];- insert
-- 将后面的查询结果 写入到前表中
insert into table 表名 partition (分区字段) select语句;- as select
-- 通过查询结果创建新表
create table if not exists 表名 as select语句;- hdfs直接上传文件
-- 本质上Hive就是将表结构映射到HDFS文件,所以直接操作底层文件夹可以让Hive读取上传的文件,
-- 分区表 需要检查并修复分区
-- 检查表的行格式与原始数据是否一致,如果不规整的数据通常创建单列的表作为原始表
hdfs dfs -put 文件 表路径数据导出
- insert
-- 不加local则导出到HDFS路径
insert overwrite local directory '/output_t_weblog'
row format delimited fields terminated by '|'
select *
from t_weblog_extracted_orc;-
hdfs get
如果Hive表使用text存储格式,则可以直接从表所在路径读取表的内容文件 -
hive自带的导入导出工具
-- 将表数据导出到hdfs路径
export table default.student to '/user/hive/warehouse/export/student';
import table student2 partition(month='202005') from '/user/hive/warehouse/export/student';Sqoop
DQL
-- 去重 HQL中通常需要使用各种函数对查询的字段进行处理
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
-- 从哪个表查
FROM db_ref.table_ref t1, (select xxx) t2
-- 添加过滤条件
[WHERE where_condition]
-- 分组 MR底层指定分区条件
[GROUP BY col_list]
-- 排序 (全局排序) MR要实现全局排序 就只能启动1个reducer
[ORDER BY col_list]
-- 如果MR分区和排序的字段 是同一个字段,则可以直接使用 CLUSTER by
[CLUSTER BY col_list
-- 指定按某些字段进行分布 (MR分区,自定义partitioner)
| [DISTRIBUTE BY col_list]
-- 指定分区内的排序方式 (MR 中的shuffle排序)
[SORT BY col_list]
]
-- 限制读取原始数据的条数
[LIMIT number]Hive的函数
Hive的内建函数
-- 列出所有可用的函数
show functions;
-- 查看某个函数的用法
desc function substr;
-- 查看函数的详细用法(包含案例)
desc function extended substr;- 函数的学习方法
- 官方文档 LanguageManual UDF - Apache Hive - Apache Software Foundation
- 日期相关和String相关的函数 每个至少操作一遍,留下印象
Hive也提供用户自定义函数的方式 添加函数
-
所有hive函数都放在
org.apache.hadoop.hive.ql.udf包中 -
自定义函数的过程
- 创建maven工程引入依赖
hive-exec - 编写类 继承
org.apache.hadoop.hive.ql.udf.UDF - 编写方法 evaluate ,方法名不能变,但允许重载
- 将工程打成jar上传到HDFS
- 在Hive中创建函数
- 创建maven工程引入依赖
create [temporary] function db_name.func_name as '类的引用' using jar 'hdfsJar路径';Hive的核心原理
外部表和管理表(内部表)
- 区别
创建时 外部表需要添加external
删除时 管理表会删除元数据(mysql)和表的内容数据(HDFS)
外部表仅仅删除元数据(mysql)
表的分区
-- 创建表t_weblog
create external table db_test01.t_weblog
(
line string
);
-- 加载数据 11-01 ~11-05 加载到表中
-- load data inpath 'hdfs路径' into table 表名;
-- hdfs dfs -mv 'hdfs路径' 表名路径
-- load data local inpath 'linux路径' into table 表名;
-- hdfs dfs -put 'linux路径' 表名路径
-- load data [local] inpath '路径' into table 表名
select *
from t_weblog
limit 10;
-- 统计11月2日访问的用户数量
-- 02/Nov/2021
-- [06/Nov/2021:03:37:21 +0800]
select t1.dt, count(*) count
from (select substr(split(line, ' ')[3], 2, 11) dt
from t_weblog) t1
where t1.dt = '02/Nov/2021'
group by t1.dt;
-- 上述方式 将所有历史存量数据直接保存在表中
-- 会导致每次对表的查询都会加载所有的历史存量数据
-- 因为底层MR 会将整个表的hdfs路径作为输入路径
-- FileInputFormat.setInputPath(job,new Path("hdfs/.../t_weblog"))
-- 创建Hive表 以日期作为分区字段
create external table t_weblog_par1
(
line string
)
partitioned by (dt string);
show tables;
desc t_weblog_par1;
line string
dt string
# Partition Information
# col_name data_type comment
dt string
-- 分区字段可以具有与表的列字段相同功能的查询和条件语句
-- select * from t where 分区字段
-- FileInputFormat.setInputPath(
-- job,new Path("hdfs/.../t_weblog/dt=20211102")
-- 指定分区后,查询 会直接加载表中的子目录 避免加载全表数据
create external table t_weblog_par2
(
line string
)
partitioned by (y string, m string, d string);
-- 分区可以支持按照顺序嵌套的多级分区,通产使用年、月、日 年月、日 作为分区字段
-- 如果使用load data将数据加载到表的分区中
-- 则Hive会自动添加分区信息到metastore中
-- 如果使用flume或者手动通过hdfs客户都创建分区目录 并上传文件
-- 则表在使用由于确实metastore中的分区信息,可能导致分区数据无法读取
-- 需要修复分区信息
msck repair table t_weblog_par2;
select m from t_weblog_par2
group by m limit 10;表的分桶操作
-- 数据清洗 提取 ip dt code url up down
create table t_weblog_extracted as
select t1.strs[0] ip,
substr(t1.strs[3], 2, 11) dt,
t1.strs[8] code,
substr(t1.strs[5], 2) type,
t1.strs[6] url,
cast(t1.strs[9] as bigint) up,
cast(t1.strs[size(t1.strs) - 1] as bigint) down
from (select split(line, ' ') strs from t_weblog) t1;
show create table t_weblog_extracted;
-- 创建分桶表 按照响应码 将数据分散到11个桶文件中
CREATE TABLE `t_weblog_extracted_bkt`
(
`ip` string,
`dt` string,
`code` string,
`type` string,
`url` string,
`up` bigint,
`down` bigint
)
clustered by (code)
into 11 buckets;
-- 将非分桶表的数据 查询并插入支持分桶的表t_weblog_extracted_bkt
insert into t_weblog_extracted_bkt
select *
from t_weblog_extracted;
-- 底层MR会根据表设置的桶的个数 自动启动若干个reducer将数据输出到桶个数个文件中
-- 一个桶中可以存放多个key的数据
-- 一个key的数据不会给拆分到多个桶中
-- insert into table t2 select x
-- create table t2 as select x
-- 分桶后 按照分桶字段进行group by查询时,可以直接通过hash值寻找key所在的桶文件提高查询效率
-- 分桶时还可以指定按照哪些字段提前排序,排序可以增加按照key的数据扫描速度,因为在有序集合中 查找目标元素时,可以顺序读取目标元素所在的文件段
select code, count(*) count
from t_weblog_extracted
group by code
order by count desc;
desc t_weblog_extracted;
以上是关于浅谈Hive的主要内容,如果未能解决你的问题,请参考以下文章