浅谈Hive和HBase的区别
Posted Hadoop大数据应用
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅谈Hive和HBase的区别相关的知识,希望对你有一定的参考价值。
Hive和HBase分别是什么?
Apache Hive是一个构建在Hadoop基础设施之上的数据仓库。通过Hive可以使用HQL语言查询存放在HDFS上的数据。HQL是一种类SQL语言,这种语言最终被转化为Map/Reduce. 虽然Hive提供了SQL查询功能,但是Hive不能够进行交互查询--因为它只能够在Haoop上批量的执行Hadoop。
Apache HBase是一种Key/Value系统,它运行在HDFS之上。和Hive不一样,Hbase的能够在它的数据库上实时运行,而不是运行MapReduce任务。Hive被分区为表格,表格又被进一步分割为列簇。列簇必须使用schema定义,列簇将某一类型列集合起来(列不要求schema定义)。例如,“message”列簇可能包含:“to”, ”from” “date”, “subject”, 和”body”. 每一个 key/value对在Hbase中被定义为一个cell,每一个key由row-key,列簇、列和时间戳。在Hbase中,行是key/value映射的集合,这个映射通过row-key来唯一标识。Hbase利用Hadoop的基础设施,可以利用通用的设备进行水平的扩展。
答: Hive 和 Hbase 是两种基于 Hadoop 的不同技术--Hive 是一种类 SQL 的引擎,并且运行 MapReduce 任务, HBase 是一种在 Hadoop 之上的 NoSQL 的 Key/vale 数据库。当然,这两种工具是可以同时使用的。就像用 Google 来搜索,用 FaceBook 进行社交一样, Hive 可以用来进行统计查询, HBase 可以用来进行实时查询,数据也可以从 Hive 写到 Hbase,设置再从 Hbase 写回 Hive。
Hive和HBase的特点
Hive帮助熟悉SQL的人运行MapReduce任务。因为它是JDBC兼容的,同时,它也能够和现存的SQL工具整合在一起。运行Hive查询会花费很长时间,因为它会默认遍历表中所有的数据。虽然有这样的缺点,一次遍历的数据量可以通过Hive的分区机制来控制。分区允许在数据集上运行过滤查询,这些数据集存储在不同的文件夹内,查询的时候只遍历指定文件夹(分区)中的数据。这种机制可以用来,例如,只处理在某一个时间范围内的文件,只要这些文件名中包括了时间格式。
HBase通过存储key/value来工作。它支持四种主要的操作:增加或者更新行,查看一个范围内的cell,获取指定的行,删除指定的行、列或者是列的版本。版本信息用来获取历史数据(每一行的历史数据可以被删除,然后通过Hbase compactions就可以释放出空间)。虽然HBase包括表格,但是schema仅仅被表格和列簇所要求,列不需要schema。Hbase的表格包括增加/计数功能。
Hive和HBase的限制
Hive目前不支持更新操作。另外,由于hive在hadoop上运行批量操作,它需要花费很长的时间,通常是几分钟到几个小时才可以获取到查询的结果。Hive必须提供预先定义好的schema将文件和目录映射到列,并且Hive与ACID不兼容。
HBase查询是通过特定的语言来编写的,这种语言需要重新学习。类SQL的功能可以通过Apache Phonenix实现,但这是以必须提供schema为代价的。另外,Hbase也并不是兼容所有的ACID特性,虽然它支持某些特性。最后但不是最重要的--为了运行Hbase,Zookeeper是必须的,zookeeper是一个用来进行分布式协调的服务,这些服务包括配置服务,维护元信息和命名空间服务。
Hive不提供数据排序和查询cache功能,不提供在线事务处理,也不提供实时的查询和记录级的更新。但Hive能更好地处理不变的大规模数据集(例如网络日志)上的批量任务。所以Hive最大的价值是可扩展性(基于Hadoop平台,可以自动适应机器数目和数据量的动态变化)、可延展性(结合
MapReduce和用户定义的函数库)、良好的容错性和低约束的数据输入格式。
HBase是一个开源的、分布式的、多版本的、面向列的存储模型,能够对大数据提供随机、实时的读写访问功能。
Hive和HBase的应用场景
Hive适合用来对一段时间内的数据进行分析查询,例如,用来计算趋势或者网站的日志。Hive不应该用来进行实时的查询。因为它需要很长时间才可以返回结果。
Hbase非常适合用来进行大数据的实时查询。Facebook用Hbase进行消息和实时的分析。它也可以用来统计Facebook的连接数。
一般,HBase是基于内存的,肯定速度要比Hive快。
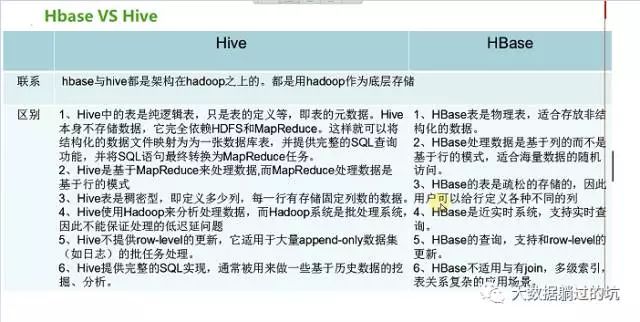
如果你想要有join操作,那你就别用HBase,因为它不支持!
Hadoop大数据应用
你也能懂大数据
以上是关于浅谈Hive和HBase的区别的主要内容,如果未能解决你的问题,请参考以下文章