OpenCV-Python实战(番外篇)——利用 KNN 算法识别手写数字
Posted 盼小辉丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OpenCV-Python实战(番外篇)——利用 KNN 算法识别手写数字相关的知识,希望对你有一定的参考价值。
OpenCV-Python实战(番外篇)——利用 KNN 算法识别手写数字
前言
K-最近邻 (k-nearest neighbours, KNN) 是监督学习中最简单的算法之一,KNN 可用于分类和回归问题,在博文《OpenCV-Python实战(13)——OpenCV与机器学习的碰撞》中,我们已经学习了如何在 OpenCV 中实现和训练 KNN 聚类算法,同时通过简单的示例了解了 KNN 算法的用法。在本文中,我们将学习如何使用 KNN 分类器执行手写数字识别,同时我们将从基础程序开始,并通过对其进行改进以提高其性能。
手写数字数据集 MNIST 介绍
为了保证完整性,从算法所用的训练数据讲起,训练数据是由 MNIST 手写数字组成的,MNIST 数据集来自美国国家标准与技术研究所,由来自 250 个不同人手写的数字构成,其中训练集包含 60000 张图片,测试集包含 10000 张图片,每个图片都有其标签,图片大小为 28*28。许多机器学习库提供了加载 MNIST 数据集的方法,这里使用 keras 库进行加载:
# 导入 keras 库
import keras
# 加载数据
(train_dataset, train_labels), (test_dataset, test_labels) = keras.datasets.mnist.load_data()
train_labels = np.array(train_labels, dtype=np.int32)
# 打印数据集形状
print(train_dataset.shape, test_dataset.shape)
# 图像预览
for i in range(40):
plt.subplot(4, 10, i+1)
plt.imshow(train_dataset[i], cmap='gray')
plt.title(train_labels[i], fontsize=10)
plt.axis('off')
plt.show()

基准模型——利用 KNN 算法识别手写数字
加载数据集后,我们尝试使用 KNN 分类器识别数字,在原始方法中,我们首先使用原始像素值作为特征,因此图像描述符的大小为 28 × 28 = 784。
首先利用 keras 加载所有数字图像,为了了解数据训练的全部流程,我们将加载的训练数据集划分为 训练数据集 + 测试数据集,每部分占比 50%:
# 加载数据集
(train_dataset, train_labels), (test_dataset, test_labels) = keras.datasets.mnist.load_data()
train_labels = np.array(train_labels, dtype=np.int32)
# 将原始图像作为描述符
def raw_pixels(img):
return img.flatten()
# 数据打散
shuffle = np.random.permutation(len(train_dataset))
train_dataset, train_labels = train_dataset[shuffle], train_labels[shuffle]
# 计算每个图像的描述符,这里特征描述符是原始像素
raw_descriptors = []
for img in train_dataset:
raw_descriptors.append(np.float32(raw_pixels(img)))
raw_descriptors = np.squeeze(raw_descriptors)
# 将数据拆分为训练和测试数据(各占 50%)
# 因此,使用 30000 个数字来训练分类器,30000 位数字来测试训练后的分类器
partition = int(0.5 * len(raw_descriptors))
raw_descriptors_train, raw_descriptors_test = np.split(raw_descriptors, [partition])
labels_train, labels_test = np.split(train_labels, [partition])
现在,我们就可以使用 knn.train() 方法训练 KNN 模型并使用 get_accuracy() 函数对其进行测试:
# 训练 KNN 模型
knn = cv2.ml.KNearest_create()
knn.train(raw_descriptors_train, cv2.ml.ROW_SAMPLE, labels_train)
# 测试 kNN 模型
k = 5
ret, result, neighbours, dist = knn.findNearest(raw_descriptors_test, k)
# 根据真实值和预测值计算准确率
def get_accuracy(predictions, labels):
acc = (np.squeeze(predictions) == labels).mean()
return acc * 100
acc = get_accuracy(result, labels_test)
print("Accuracy: ".format(acc))
我们可以看到当 K = 5 时,KNN 模型可以获得 96.48% 的准确率,但我们仍然可以对其进行改进,以获取更高性能。
改进模型1——参数 K 对识别手写数字精确度的影响
我们已经知道在 KNN 算法中,一个影响算法性能的重要参数就是 K,因此,我们可以首先尝试使用不同的 K 值,查看其对识别手写数字精确度的影响。
为了比较不同 K 值时模型的准确率,我们首先需要创建一个字典来存储测试不同 K 值时的准确率:
from collections import defaultdict
results = defaultdict(list)
接下来,计算 knn.findNearest() 方法,改变 K 参数,并将结果存储在字典中:
# K 取值范围为 (1, 9)
for k in range(1, 10):
ret, result, neighbours, dist = knn.findNearest(raw_descriptors_test, k)
acc = get_accuracy(result, labels_test)
print(" ".format("%.2f" % acc))
results['50'].append(acc)
最后,绘制结果:
ax = plt.subplot(1, 1, 1)
ax.set_xlim(0, 10)
dim = np.arange(1, 10)
for key in results:
ax.plot(dim, results[key], linestyle='--', marker='o', label="50%")
plt.legend(loc='upper left', title="% training")
plt.title('Accuracy of the K-NN model varying k')
plt.xlabel("number of k")
plt.ylabel("accuracy")
plt.show()
程序运行结果如下图所示:

如上图所示,改变 K 参数获得的准确率也是不同的,因此,在应用程序用可以通过调整 K 参数来获取最佳性能。
改进模型2——训练数据量对识别手写数字精确度的影响
在机器学习中,使用更多的数据训练分类器通常会提高模型的性能,这是由于分类器可以更好地学习特征的结构。在 KNN 分类器中,增加训练数也会增加在特征空间中找到测试数据正确匹配的概率。
接下来,我们就修改=用于训练和测试模型的图像百分比,来观察训练数据量对识别手写数字精确度的影响:
# 划分训练数据集和测试数据集
split_values = np.arange(0.1, 1, 0.1)
# 存储结果准确率
results = defaultdict(list)
# 创建模型
knn = cv2.ml.KNearest_create()
# 不同训练数据量对识别手写数字精确度的影响
for split_value in split_values:
# 将数据集划分为训练和测试数据集
partition = int(split_value * len(raw_descriptors))
raw_descriptors_train, raw_descriptors_test = np.split(raw_descriptors, [partition])
labels_train, labels_test = np.split(train_labels, [partition])
# 训练 KNN 模型
print('Training KNN model - raw pixels as features')
knn.train(raw_descriptors_train, cv2.ml.ROW_SAMPLE, labels_train)
# 同时对于每种划分测试不同 K 值影响
for k in range(1, 10):
ret, result, neighbours, dist = knn.findNearest(raw_descriptors_test, k)
acc = get_accuracy(result, labels_test)
print("".format("%.2f" % acc))
results[int(split_value * 100)].append(acc)
训练算法的数字图像的百分比为10%、20%、…、90%,测试算法的数字百分比为90%、80%、…、10%,最后,绘制结果:
ax = plt.subplot(1, 1, 1)
ax.set_xlim(0, 10)
dim = np.arange(1, 10)
for key in results:
ax.plot(dim, results[key], linestyle='--', marker='o', label=str(key) + "%")
plt.legend(loc='upper left', title="% training")
plt.title('Accuracy of the KNN model varying both k and the percentage of images to train/test')
plt.xlabel("number of k")
plt.ylabel("accuracy")
plt.show()
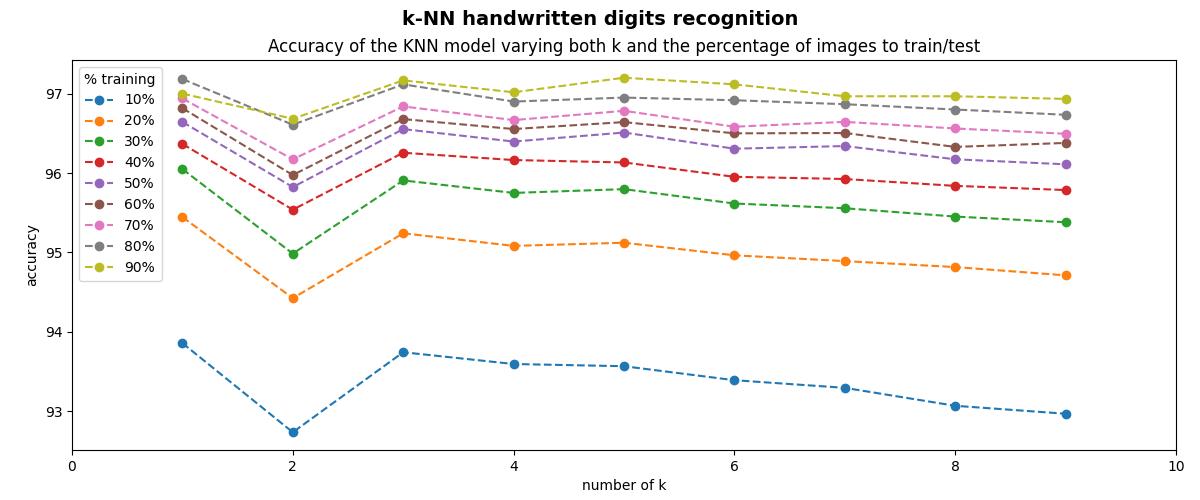
从上图可以看出,随着训练图像数量的增加,准确率也会增加。因此当条件允许的情况下,可以通过增加训练数据量来提高模型性能。
虽然可以看到准确率虽然已经可以到达97%以上,但是我们不能就此止步。
改进模型3——预处理对识别手写数字精确度的影响
在以上示例中,我们均使用原始像素值作为特征来训练分类器。在机器学习中,训练分类器之前的一个通常可以对输入数据进行某种预处理,用以提高分类器训练性能,因此,接下来我们应用预处理以查看其对识别手写数字精确度的影响。
预处理函数 desew() 如下:
def deskew(img):
m = cv2.moments(img)
if abs(m['mu02']) < 1e-2:
return img.copy()
skew = m['mu11'] / m['mu02']
M = np.float32([[1, skew, -0.5 * SIZE_IMAGE * skew], [0, 1, 0]])
img = cv2.warpAffine(img, M, (SIZE_IMAGE, SIZE_IMAGE), flags=cv2.WARP_INVERSE_MAP | cv2.INTER_LINEAR)
return img
desew() 函数通过使用其二阶矩对数字进行去歪斜。更具体地说,可以通过两个中心矩的比值 (mu11/mu02) 计算偏斜的度量。计算出的偏斜用于计算仿射变换,从而消除数字的偏斜。接下来对比预处理的前后图片效果:
for i in range(10):
plt.subplot(2, 10, i+1)
plt.imshow(train_dataset[i], cmap='gray')
plt.title(train_labels[i], fontsize=10)
plt.axis('off')
plt.subplot(2, 10, i+11)
plt.imshow(deskew(train_dataset[i]), cmap='gray')
plt.axis('off')
plt.show()
在下图的第一行显示了原始数字图像,第二行显示了预处理后的数字图像:

通过应用此预处理,识别的准确率得到提高,准确率曲线如下图所示:
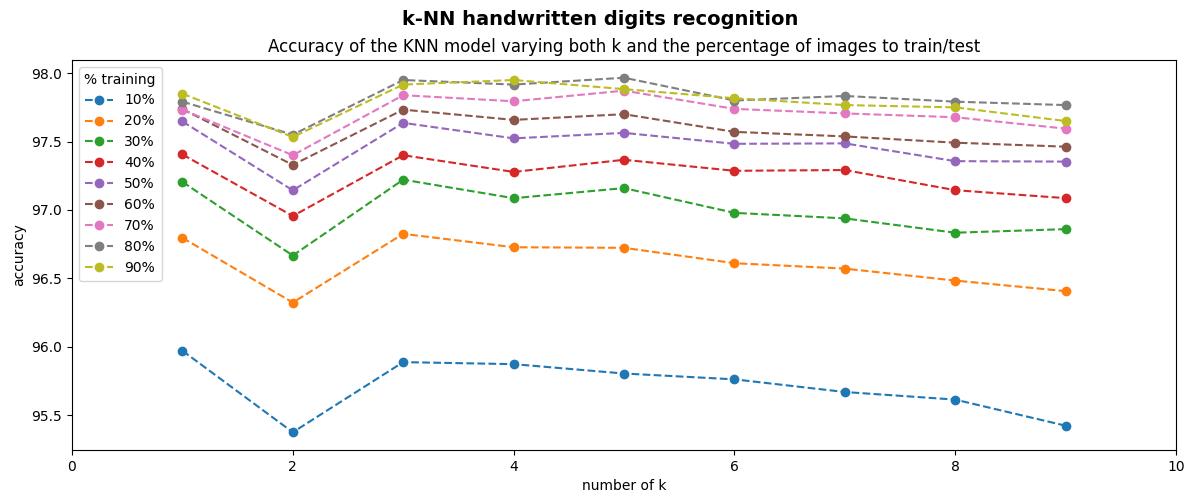
可以看到经过预处理的分类器准确率甚至可以接近98%,考虑到我们仅仅是使用了简单的 KNN 模型,效果已经很不错了,但是我们还可以进一步提高模型性能。
改进模型4——使用高级描述符作为图像特征提高 KNN 算法准确率
在以上示例中,我们一直使用原始像素值作为特征描述符。在机器学习中,一种常见的方法是使用更高级的描述符,接下来将使用定向梯度直方图 (Histogram of Oriented Gradients, HOG) 作为图像特征用以提高 KNN 算法准确率。
特征描述符是图像的一种表示,它通过提取描述基本特征(例如形状、颜色或纹理等)的有用信息来简化图像。通常,特征描述符将图像转换为长度为 n 的特征向量,HOG 是一种用于计算机视觉的流行特征描述符。
接下来定义 get_hog() 函数获取 HOG 描述符:
(train_dataset, train_labels), (test_dataset, test_labels) = keras.datasets.mnist.load_data()
SIZE_IMAGE = train_dataset.shape[1]
train_labels = np.array(train_labels, dtype=np.int32)
def get_hog():
hog = cv2.HOGDescriptor((SIZE_IMAGE, SIZE_IMAGE), (8, 8), (4, 4), (8, 8), 9, 1, -1, 0, 0.2, 1, 64, True)
print("hog descriptor size: ".format(hog.getDescriptorSize()))
return hog
然后使用 HOG 特征训练 KNN 模型
hog = get_hog()
hog_descriptors = []
for img in train_dataset:
hog_descriptors.append(hog.compute(deskew(img)))
hog_descriptors = np.squeeze(hog_descriptors)
训练完成的模型的准确率,如下图所示:

通过上述改进过程,可以看到编写机器学习模型时的一个好方法是从解决问题的基本基线模型开始,然后通过添加更好的预处理、更高级的特征描述符或其他机器学习技术来迭代改进模型。最后,如果条件允许,可以收集更多数据用于训练和测试模型。
完整代码
最终完整代码如下所示,改进过程中的其他代码可以根据上述讲解对以下代码进行简单修改获得:
import cv2
import numpy as np
import matplotlib.pyplot as plt
from collections import defaultdict
import keras
(train_dataset, train_labels), (test_dataset, test_labels) = keras.datasets.mnist.load_data()
SIZE_IMAGE = train_dataset.shape[1]
train_labels = np.array(train_labels, dtype=np.int32)
def get_accuracy(predictions, labels):
acc = (np.squeeze(predictions) == labels).mean()
return acc * 100
def raw_pixels(img):
return img.flatten()
def deskew(img):
m = cv2.moments(img)
if abs(m['mu02']) < 1e-2:
return img.copy()
skew = m['mu11'] / m['mu02']
M = np.float32([[1, skew, -0.5 * SIZE_IMAGE * skew], [0, 1, 0]])
img = cv2.warpAffine(img, M, (SIZE_IMAGE, SIZE_IMAGE), flags=cv2.WARP_INVERSE_MAP | cv2.INTER_LINEAR)
return img
def get_hog():
hog = cv2.HOGDescriptor((SIZE_IMAGE, SIZE_IMAGE), (8, 8), (4, 4), (8, 8), 9, 1, -1, 0, 0.2, 1, 64, True)
print("hog descriptor size: ".format(hog.getDescriptorSize()))
return hog
shuffle = np.random.permutation(len(train_dataset))
train_dataset, train_labels = train_dataset[shuffle], train_labels[shuffle]
# 高级图像描述符
hog = get_hog()
hog_descriptors = []
for img in train_dataset:
hog_descriptors.append(hog.compute(deskew(img)))
hog_descriptors = np.squeeze(hog_descriptors)
# 数据划分
split_values = np.arange(0.1, 1, 0.1)
# 创建字典用于存储准确率
results = defaultdict(list)
# 创建 KNN 模型
knn = cv2.ml.KNearest_create()
for split_value in split_values:
partition = int(split_value * len(hog_descriptors))
hog_descriptors_train, hog_descriptors_test = np.split(hog_descriptors, [partition])
labels_train, labels_test = np.split(train_labels, [partition])
print('Training KNN model - HOG features')
knn.train(hog_descriptors_train, cv2.ml.ROW_SAMPLE, labels_train)
# 存储准确率
for k in np.arange(1, 10):
ret, result, neighbours, dist = knn.findNearest(hog_descriptors_test, k)
acc = get_accuracy(result, labels_test)
print(" ".format("%.2f" % acc))
results[int(split_value * 100)].append(acc)
fig = plt.figure(figsize=(12, 5))
plt.suptitle("k-NN handwritten digits recognition", fontsize=14, fontweight='bold')
ax = plt.subplot(1, 1, 1)
ax.set_xlim(0, 10)
dim = np.arange(1, 10)
for key in results:
ax.plot(dim, results[key], linestyle='--', marker='o', label=str(key) + "%")
plt.legend(loc='upper left', title="% training")
plt.title('Accuracy of the k-NN model varying both k and the percentage of images to train/test with pre-processing '
'and HoG features')
plt.xlabel("number of k")
plt.ylabel("accuracy")
plt.show()
相关链接
以上是关于OpenCV-Python实战(番外篇)——利用 KNN 算法识别手写数字的主要内容,如果未能解决你的问题,请参考以下文章
OpenCV-Python实战(番外篇)——利用 KNN 算法识别手写数字
OpenCV-Python实战(番外篇)——利用 SVM 算法识别手写数字
OpenCV-Python实战(番外篇)——利用 K-Means 聚类进行色彩量化
OpenCV-Python实战(番外篇)——利用增强现实制作美颜挂件,让你的照片与众不同