Python 计算机视觉(十七)—— 基于KNN的图像分类
Posted 一马归一码
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 计算机视觉(十七)—— 基于KNN的图像分类相关的知识,希望对你有一定的参考价值。
参考的一些文章以及论文我都会给大家分享出来 —— 链接就贴在原文,论文我上传到资源中去,大家可以免费下载学习,如果当天资源区找不到论文,那就等等,可能正在审核,审核完后就可以下载了。大家一起学习,一起进步!加油!!
目录
1. 图像分类概述
此处参考:《基于特征学习和机器学习的图像分类识别算法研究_李 青》
(1)背景及意义
在互联网和数据及其发达的今天,我们每时每刻都要面对海量的图像数据,其内容和形式呈现出复杂多样化。试图通过人工辨识的方法来处理这些图片是不可能的,因为人工辨识需要消耗大量的人力时间和经验去分析和判断图片,这是非常复杂并且费时耗力的工作。因此,利用计算机辅助自动将图片按照人们理解的方式,划分到不同的类别属性的图像分类和识别技术已成为近些年的研究热点。而图像分类识别技术正是解决这个问题的关键技术。
(2)概念及任务
图像分类是从给定的分类集合中给输入的图像匹配一个标签,即输入一个图像,那么输出的是计算机通过判断给这个图像贴上的标签。
图像分类和识别主要任务是学习和判断图像中是否包含某种特定的目标内容(物体或者场景等),并依据其内容信息进行多类单标签或者多类多标签的分类和识别。由于图像分类识别的数据集种类不同,根据输入数据标签对应注释比例的情况主要分为三种,有监督学习、半监督学习和无监督学习。针对不同标签类型的数据集,则需要设计不同的图像分类识别算法。
a. 有监督学习
输入的数据集内的所有样本都被标注了标签,计算机通过对这些图像的特征进行观察和学习,对它们进行分类,当再次输入一幅图像时它就会对该输入进行判断并输出相应的标签。简单来说就像是给计算机标准答案然后让它作同一种类型的题目。
b. 半监督学习
跟有监督学习进行类比,该学习方式是给部分的样本标注了标签,首先计算机通过对数据集的观察得到样本的特征,然后根据部分样本的标签为它们进行分类,也对后续输入进行判别。
c. 无监督学习
数据集中的所有样本都是没有标注标签的,而计算机要做的是通过观察这些样本的特征将它们进行分类聚合,将它认为是一类的样本(相似特征较为明显)进行聚类。
2. 基于KNN的图像分类
基本概念参考:《基于传统机器学习与深度学习的图像分类算法对比分析_刘华祠》
代码实现参考自下面这位博主的文章: Eastmount
大家如果想要深入学习可以进行参考
(1). 基本概念
KNN 算法是通过计算待测样本与已知样本之间的数据点的相似度进行样本点的分类,对于相似度的判定该算法通常使用的是欧氏距离:

简单来说,该算法就是寻找最近的样本点并将其归为一类,也就是物以类聚、人以群分。
一般该算法的判别步骤如下:
step one: 计算测试集特征向量与训练集特征向量之间的距离。
step two: 按照距离的远近进行排序。
step three: 选取距离最近的 K 个点。
step four: 计算前 K 个点所在类别的出现频率。
step five: 统计前 K 个点中出现频率最高的类别,作为测试集的分类类别。
(2). 代码实现
若是直接想手撸这个算法可以参考博主的这篇文章:机器学习实战(一)—— K-近邻算法(KNN)
下面咱们使用 Python 中提供的分类器进行图像的分类,其中使用的训练数据集可以到博主的网盘中下载:
链接:https://pan.baidu.com/s/1MoSYo3bt35UM0I7Vx0popg
提取码:jmh3
我们知道,Python的一大优势就是提供了大量的第三方库,在本文中我们也是调用分类器进行图像的识别,在这之前我们需要对待训练的图像进行一些操作来使它们满足K近邻算法的运算方式,基本步骤以及代码实现如下:
StepOne.切分训练集和数据集
os.listdir(path):path为需要列出的目录的路径,该函数返回指定文件和文件夹目录。 append():向列表的尾部添加一个新的元素。 split():通过指定的分隔符对字符串进行切片。
"""
Author:XiaoMa
date:2021/12/14
"""
#调用第三方库
import os
import cv2
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, classification_report
# 第一步 切分训练集和测试集
X = [] #定义图像名称
Y = [] #定义图像分类类标
Z = [] #定义图像像素
for i in range(0, 10):
#遍历文件夹,读取图片,本例中的图像文件可以在上面分享的链接中提取
for f in os.listdir("E:\\Python\\Study\\\\venv\\Lib\\photo/%s" % i):
#获取图像名称
X.append("photo//" +str(i) + "//" + str(f))
#获取图像类标即为文件夹名称
Y.append(i)
X = np.array(X)
Y = np.array(Y)
#随机率为100% 选取其中的30%作为测试集
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.3, random_state = 1)
print(len(X_train), len(X_test), len(y_train), len(y_test))得到的输出如下:
 数据集提供了一共一千张图像,并将它们分为了十类,大家下载下来就可以查看:
数据集提供了一共一千张图像,并将它们分为了十类,大家下载下来就可以查看:
StepTwo.图像的读取及处理
# 第二步 图像读取及转换为像素直方图
#训练集
XX_train = []
for i in X_train:
#读取图像
image = cv2.imread(i)
#图像像素大小一致
img = cv2.resize(image, (256, 256), interpolation=cv2.INTER_CUBIC)
#计算图像直方图并存储至X数组
hist = cv2.calcHist([img], [0, 1], None, [256, 256], [0.0, 255.0, 0.0, 255.0])
XX_train.append(((hist/255).flatten()))
#测试集
XX_test = []
for i in X_test:
#读取图像
#print i
image = cv2.imread(i)
#图像像素大小一致
img = cv2.resize(image, (256, 256), interpolation=cv2.INTER_CUBIC)
#计算图像直方图并存储至X数组
hist = cv2.calcHist([img], [0, 1], None, [256, 256], [0.0, 255.0, 0.0, 255.0])
XX_test.append(((hist/255).flatten()))StepThree.KNN算法分类
# 第三步 基于KNN的图像分类处理
from sklearn.neighbors import KNeighborsClassifier #调用分类器
clf = KNeighborsClassifier(n_neighbors=11).fit(XX_train, y_train)
predictions_labels = clf.predict(XX_test)
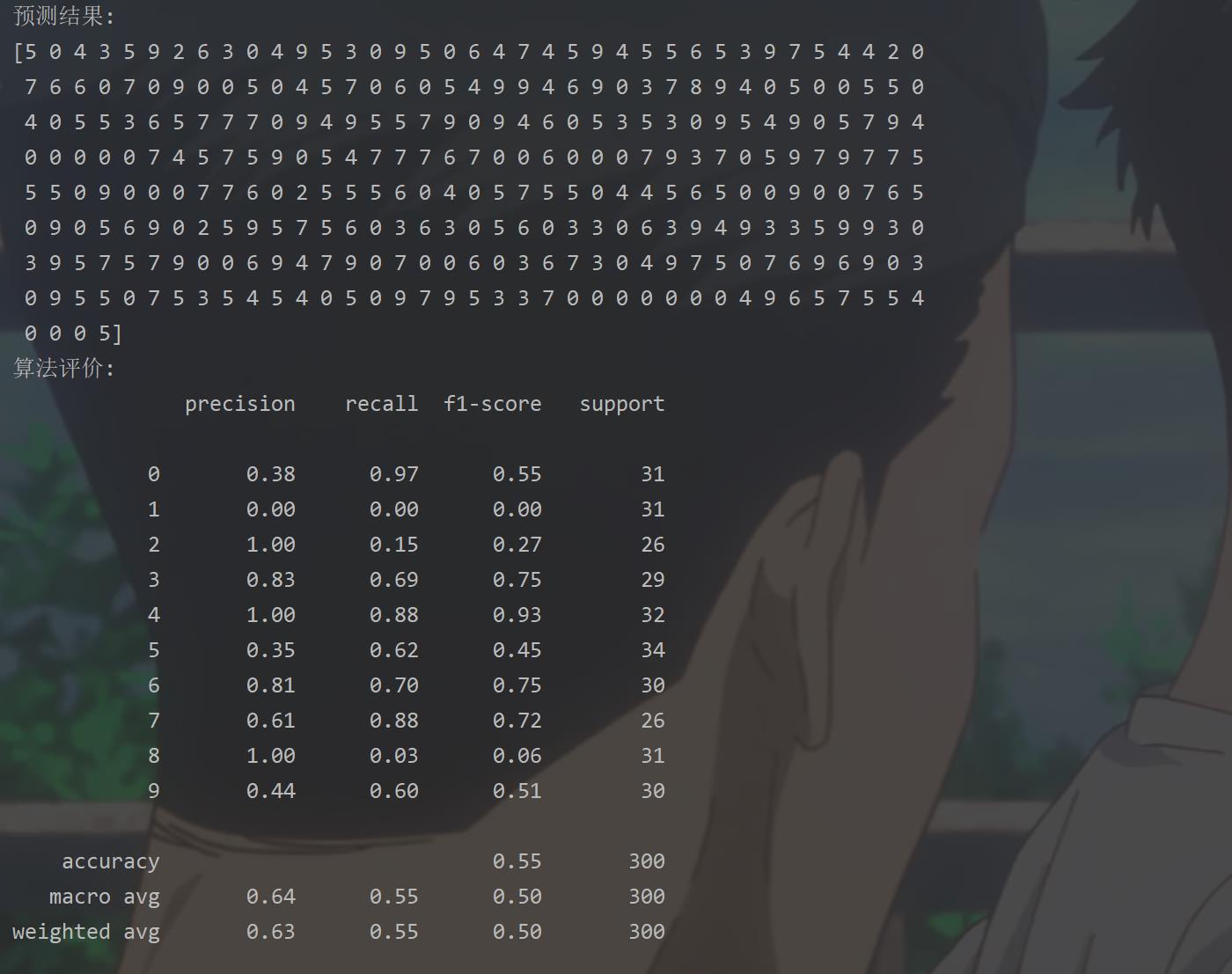
print('预测结果:')
print(predictions_labels)
print('算法评价:')
print((classification_report(y_test, predictions_labels)))
#输出前10张图片及预测结果
k = 0
while k < 10:
#读取图像
print(X_test[k])
image = cv2.imread(X_test[k])
print(predictions_labels[k])
#显示图像
cv2.imshow("img", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
k = k + 1预测结果以及算法评价如下:
下面只展示部分图像的分类结果:
第一张图像选择的是大象并且判断正确
 因为在原数据集中大象就是在第五个文件夹中:
因为在原数据集中大象就是在第五个文件夹中:

但也会有一些判断出现错误,如下:

就因为图像中出现了1人就将该图像分类到了第一类人类的部分中了。
3. 结束语
本篇文章主要介绍了机器学习的一些基本概念以及基于KNN的图像分类,主要参考的是论文以及前面提到的博主 Eastmount的文章,大家如果想深入了解可以去跟他们学习。这几天忙于各种ddl,其他的一些方法寒假再更,加油!
4. 参考论文




以上是关于Python 计算机视觉(十七)—— 基于KNN的图像分类的主要内容,如果未能解决你的问题,请参考以下文章
人脸识别基于HOG特征KNN算法实现人脸识别matlab源码
基于python Knn 算法识别手写数字,计算准确率 ——第二弹
Python沃罗诺伊图 | KNN 最邻近算法 | Voronoi 函数
全球名校课程作业分享系列--斯坦福计算机视觉与深度学习CS231n之KNN