飞桨AI进阶实战:工业表计读数(记录)
Posted AI浩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了飞桨AI进阶实战:工业表计读数(记录)相关的知识,希望对你有一定的参考价值。
1、项目说明
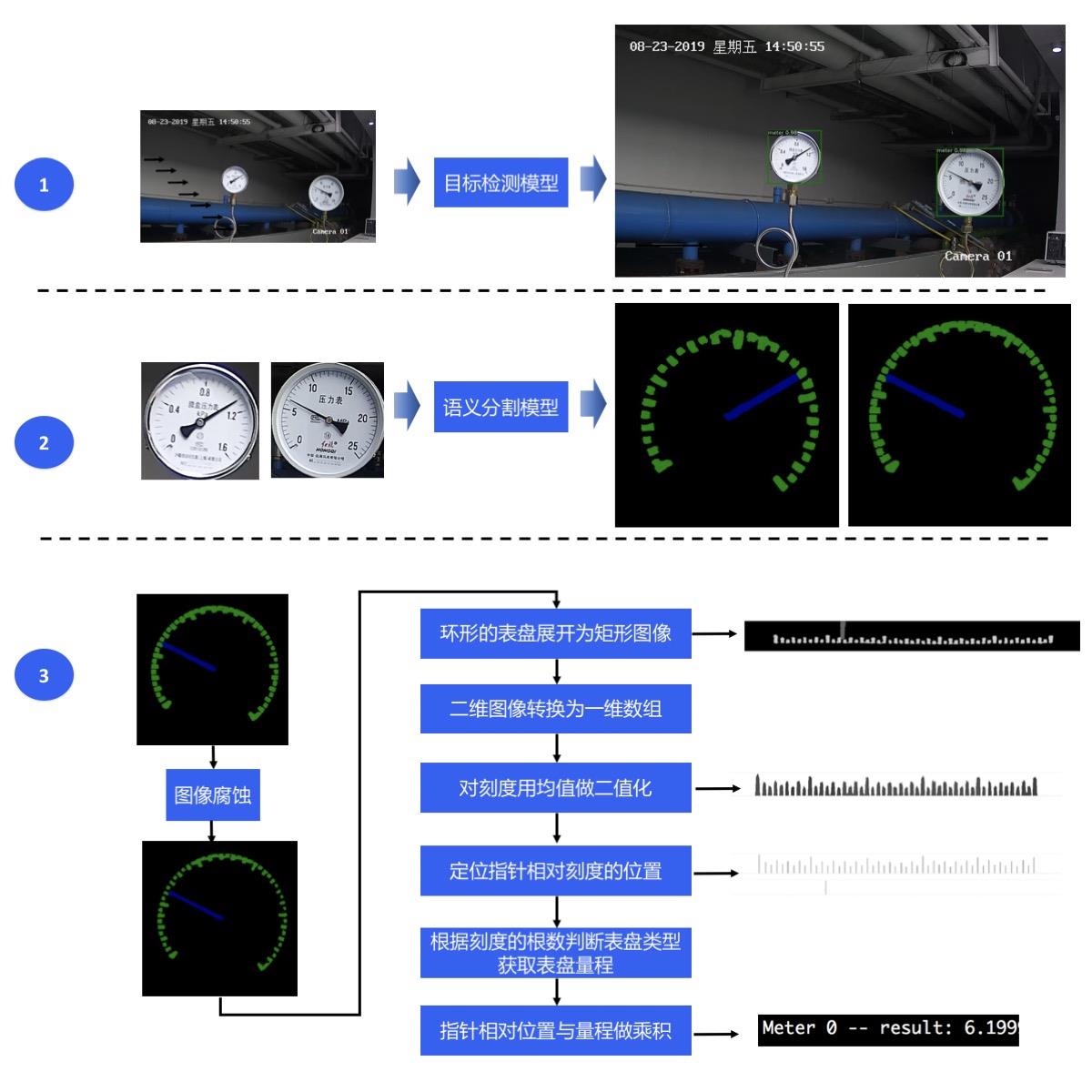
在该项目中,主要向大家介绍如何使用目标检测和语义分割来实现对指针型表计读数。
在电力能源厂区需要定期监测表计读数,以保证设备正常运行及厂区安全。但厂区分布分散,人工巡检耗时长,无法实时监测表计,且部分工作环境危险导致人工巡检无法触达。针对上述问题,希望通过摄像头拍照->智能读数的方式高效地完成此任务。

为实现智能读数,我们采取目标检测->语义分割->读数后处理的方案:
第一步,使用目标检测模型定位出图像中的表计;
第二步,使用语义分割模型将各表计的指针和刻度分割出来;
第三步,根据指针的相对位置和预知的量程计算出各表计的读数。
2、数据准备
本案例开放了表计检测数据集、指针和刻度分割数据集、表计测试图片(只有图片无真值标注),使用这些图片可以完成目标检测模型、语义分割模型的训练、模型预测。点击下表中的链接可下载数据集,提前下载数据集不是必须的,因为在接下来的模型训练部分中提供的训练脚本会自动下载数据集。
表计测试图片 表计检测数据集 指针和刻度分割数据集
meter_test meter_det meter_seg
解压后的表计检测数据集的文件夹内容如下:
训练集有725张图片,测试集有58张图片。
meter_det/
|-- annotations/ # 标注文件所在文件夹
| |-- instance_train.json # 训练集标注文件
| |-- instance_test.json # 测试集标注文件
|-- test/ # 测试图片所在文件夹
| |-- 20190822_105.jpg # 测试集图片
| |-- … …
|-- train/ # 训练图片所在文件夹
| |-- 20190822_101.jpg # 训练集图片
| |-- … …
解压后的指针和刻度分割数据集的文件夹内容如下:
训练集有374张图片,测试集有40张图片。
meter_seg/
|-- annotations/ # 标注文件所在文件夹
| |-- train # 训练集标注图片所在文件夹
| | |-- 105.png
| | |-- … …
| |-- val # 验证集合标注图片所在文件夹
| | |-- 110.png
| | |-- … …
|-- images/ # 图片所在文件夹
| |-- train # 训练集图片
| | |-- 105.jpg
| | |-- … …
| |-- val # 验证集图片
| | |-- 110.jpg
| | |-- … …
|-- labels.txt # 类别名列表
|-- train.txt # 训练集图片列表
|-- val.txt # 验证集图片列表
解压后的表计测试图片的文件夹内容如下:
一共有58张测试图片。
meter_test/
|-- 20190822_105.jpg
|-- 20190822_142.jpg
|-- … …
3、模型选择
PaddleX提供了丰富的视觉模型,在目标检测中提供了RCNN和YOLO系列模型,在语义分割中提供了DeepLabV3P和BiSeNetV2等模型。
因最终部署场景是本地化的服务器GPU端,算力相对充足,因此在本项目中采用精度和预测性能皆优的PPYOLOV2进行表计检测。
考虑到指针和刻度均为细小区域,我们采用精度更优的DeepLabV3P进行指针和刻度的分割。
4、表计检测模型训练
本项目中采用精度和预测性能的PPYOLOV2进行表计检测。
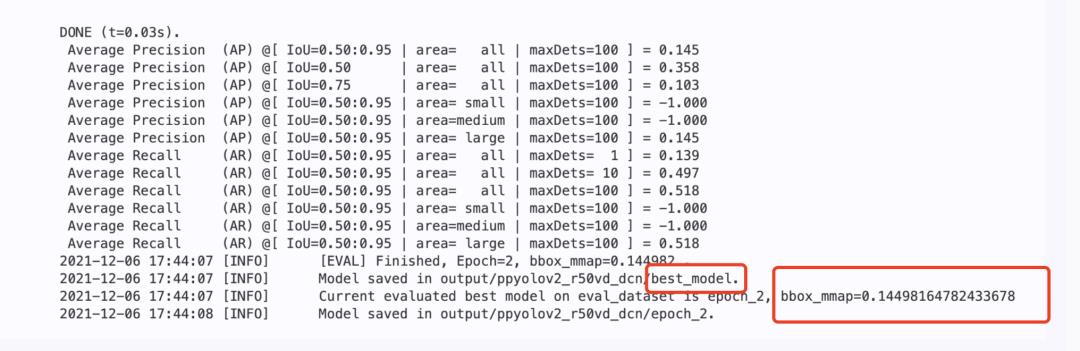
训练结束后,最优模型精度bbox_mmap达到100%。
5、 指针和刻度分割模型训练
本项目中采用精度更优的DeepLabV3P进行指针和刻度的分割。
训练结束后,最优模型精度miou达84.09。
准备阶段
第一步:创建Notebook模型任务
step1:进入BML主页,点击立即使用
🔗:https://ai.baidu.com/bml/

step2:点击Notebook,创建“通用任务”

step3:填写任务信息

第二步:下载任务操作模板
下载链接:https://aistudio.baidu.com/aistudio/datasetdetail/120387

目标检测模型训练
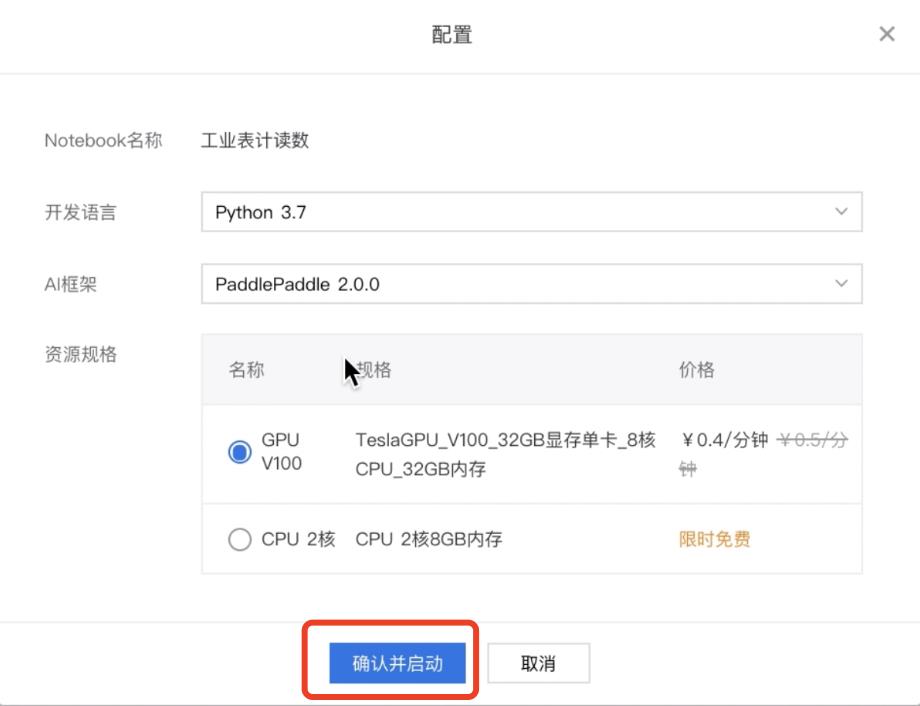
第一步:配置Notebook
1.找到昨天创建的Notebook任务,点击配置

2.配置选择
- 开发语言:Python3.7
- AI框架:PaddlePaddle2.0.0
- 资源规格:GPU V100
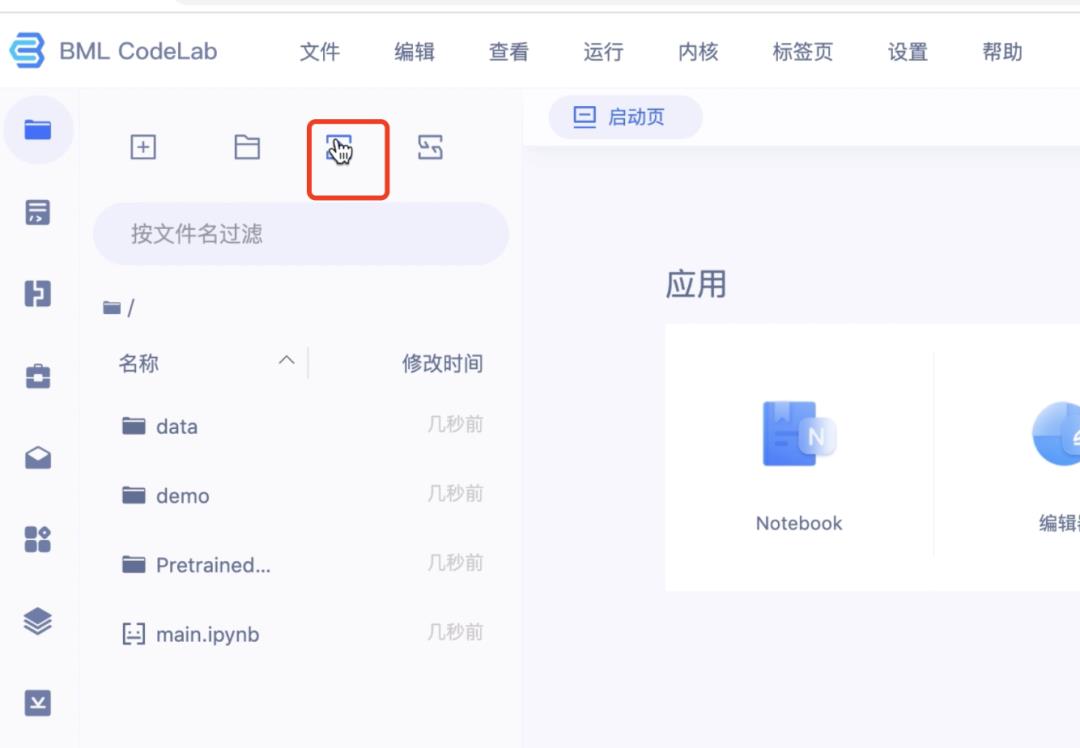
3.打开Notebook

4.上传本次Notebook操作模型
若没来得及下载,请点击链接下载:https://aistudio.baidu.com/aistudio/datasetdetail/120387

第二步:环境准备
1.安装filelock
!pip install filelock


2.安装PaddleX
!pip install paddlex==2.0.0
注意:安装paddlex的时候需要制定版本。


3.升级paddlepaddle-gpu为2.1.3版本
!pip install paddlepaddle-gpu==2.1.3.post101 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html

第三步:目标检测模型训练
训练过程说明:
定义数据预处理 -> 定义数据集路径 -> 初始化模型 -> 模型训练

1.调用PaddleX
import paddlex as pdxfrom paddlex import transforms as T

2.定义训练和验证时的transforms
API详细说明:https://github.com/PaddlePaddle/PaddleX/blob/release/2.0-rc/paddlex/cv/transforms/operators.py
train_transforms = T.Compose([ T.MixupImage(mixup_epoch=250), T.RandomDistort(), T.RandomExpand(im_padding_value=[123.675, 116.28, 103.53]), T.RandomCrop(), T.RandomHorizontalFlip(), T.BatchRandomResize( target_sizes=[320, 352, 384, 416, 448, 480, 512, 544, 576, 608], interp='RANDOM'), T.Normalize( mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])
eval_transforms = T.Compose([ T.Resize( 608, interp='CUBIC'), T.Normalize( mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])

3.下载用于目标检测训练的表计读数数据集
meter_det_dataset = 'https://bj.bcebos.com/paddlex/examples/meter_reader/datasets/meter_det.tar.gz'pdx.utils.download_and_decompress(meter_det_dataset, path='./')

可在左侧文件夹区域查看数据集
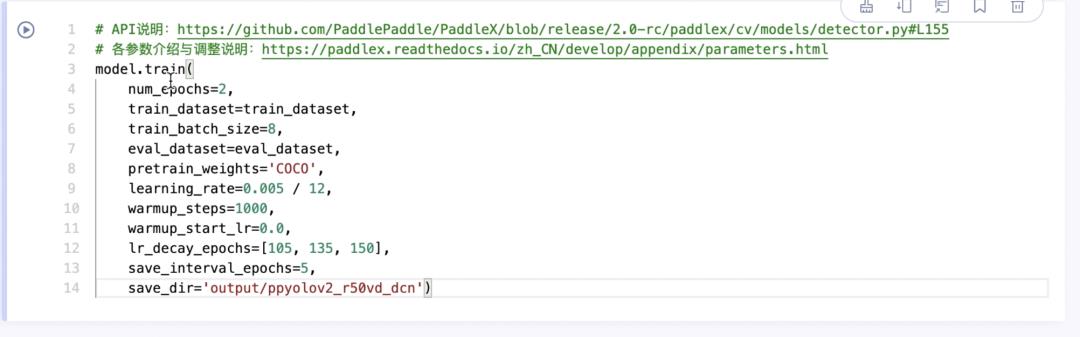
4.设置训练参数
详细API说明:https://github.com/PaddlePaddle/PaddleX/blob/develop/paddlex/cv/datasets/coco.py#L26
train_dataset = pdx.datasets.CocoDetection( data_dir='meter_det/train/', ann_file='meter_det/annotations/instance_train.json', transforms=train_transforms, shuffle=True)eval_dataset = pdx.datasets.CocoDetection( data_dir='meter_det/test/', ann_file='meter_det/annotations/instance_test.json', transforms=eval_transforms)


5.训练结束后查看bestmodel

第四步:保存Notebook并关闭、停止运行
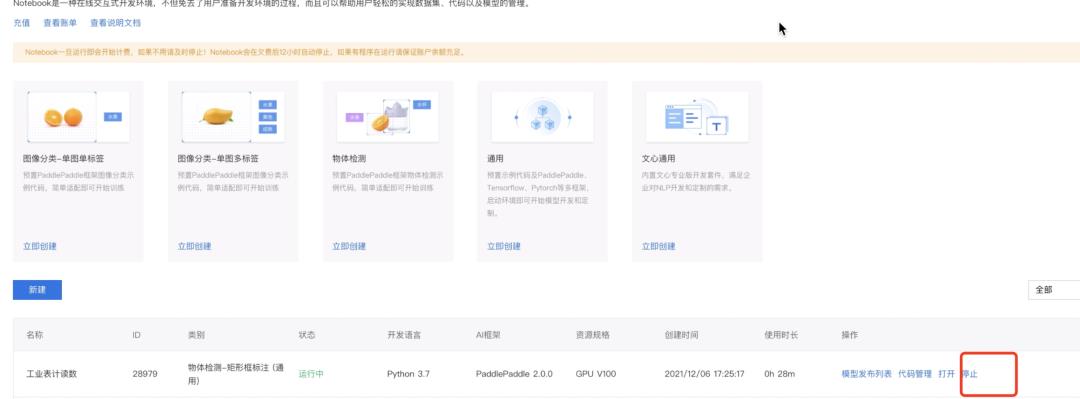
语义分割模型训练
第一步:重新安装环境
1.启动Notebook并打开
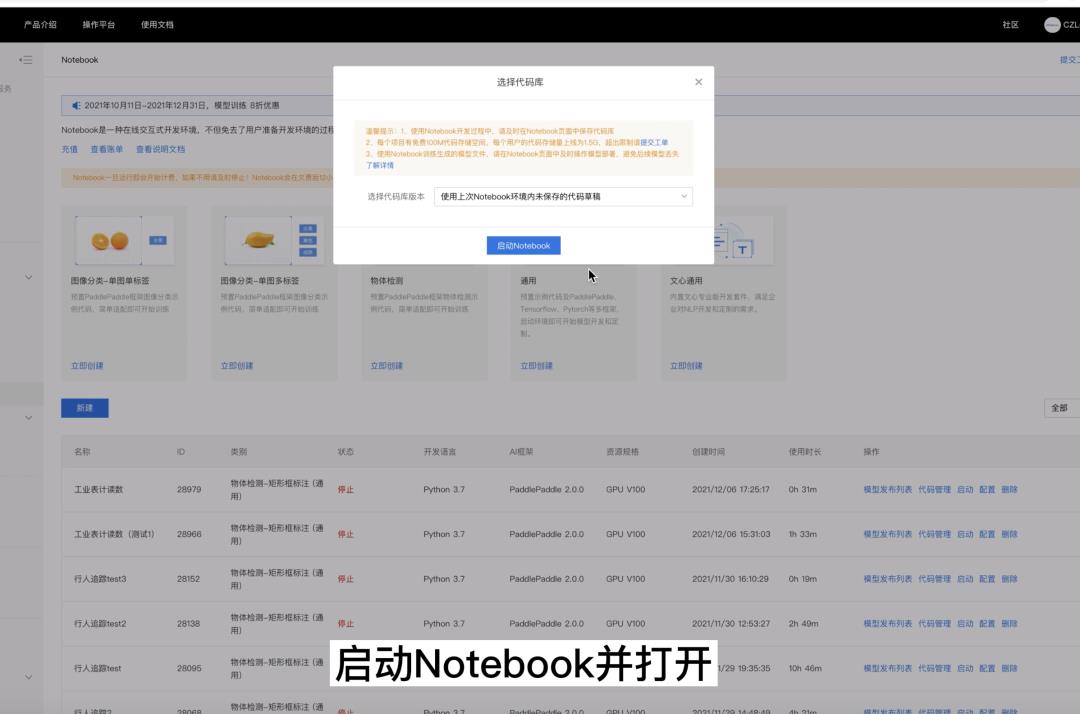
2.重新执行安装的三条命令



第二步:指针和刻度分割模型训练
1.调用paddlex
import paddlex as pdxfrom paddlex import transforms as T

2.定义训练和验证时的transforms
详细API说明参考:https://github.com/PaddlePaddle/PaddleX/blob/release/2.0-rc/paddlex/cv/transforms/operators.py
train_transforms = T.Compose([ T.Resize(target_size=512), T.RandomHorizontalFlip(), T.Normalize( mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),])
eval_transforms = T.Compose([ T.Resize(target_size=512), T.Normalize( mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),])

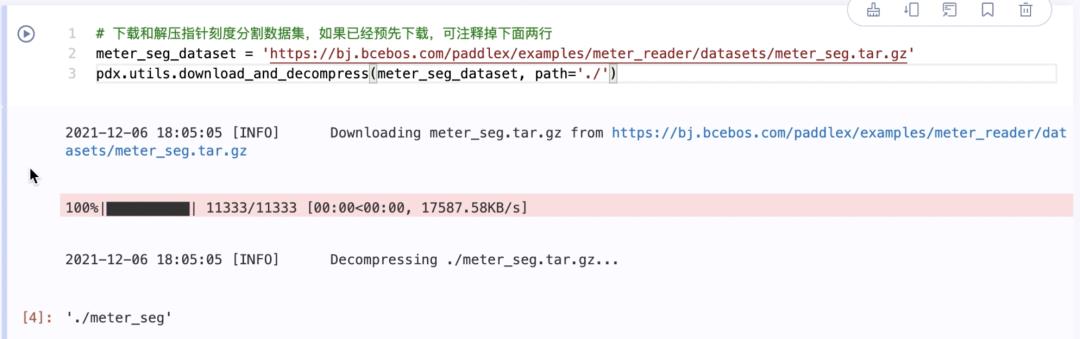
3.下载和解压指针刻度分割数据集
meter_seg_dataset = 'https://bj.bcebos.com/paddlex/examples/meter_reader/datasets/meter_seg.tar.gz'pdx.utils.download_and_decompress(meter_seg_dataset, path='./')
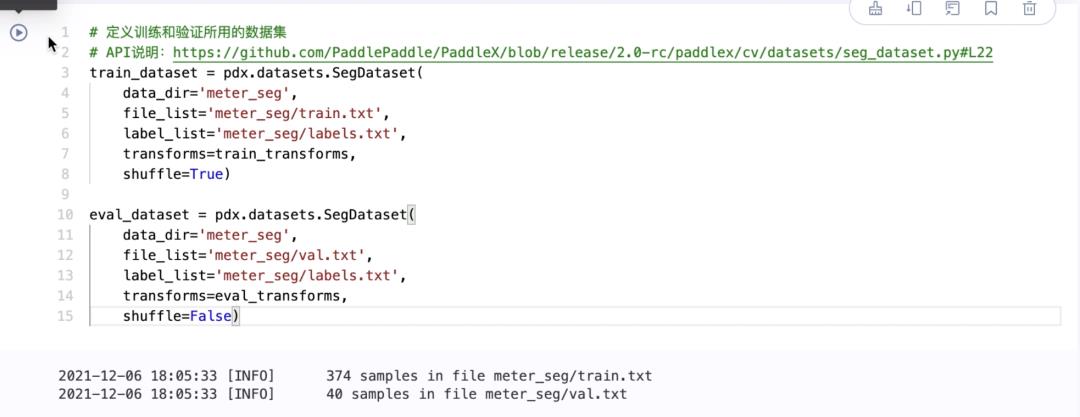
4.定义训练和验证所用的数据集,配置相应路径
详细API说明参考:https://github.com/PaddlePaddle/PaddleX/blob/release/2.0-rc/paddlex/cv/datasets/seg_dataset.py#L22
train_dataset = pdx.datasets.SegDataset( data_dir='meter_seg', file_list='meter_seg/train.txt', label_list='meter_seg/labels.txt', transforms=train_transforms, shuffle=True)
eval_dataset = pdx.datasets.SegDataset( data_dir='meter_seg', file_list='meter_seg/val.txt', label_list='meter_seg/labels.txt', transforms=eval_transforms, shuffle=False)
5.选择PaddleX内置的DeepLabV3P模型进行训练
API说明:https://github.com/PaddlePaddle/PaddleX/blob/release/2.0-rc/paddlex/cv/models/segmenter.py#L150
num_classes = len(train_dataset.labels)model = pdx.seg.DeepLabV3P( num_classes=num_classes, backbone='ResNet50_vd', use_mixed_loss=True)

6.设置训练时的参数
各参数介绍与调整说明:https://paddlex.readthedocs.io/zh_CN/develop/appendix/parameters.html
model.train( num_epochs=2, train_dataset=train_dataset, train_batch_size=4, eval_dataset=eval_dataset, pretrain_weights='IMAGENET', learning_rate=0.1, save_dir='output/deeplabv3p_r50vd')
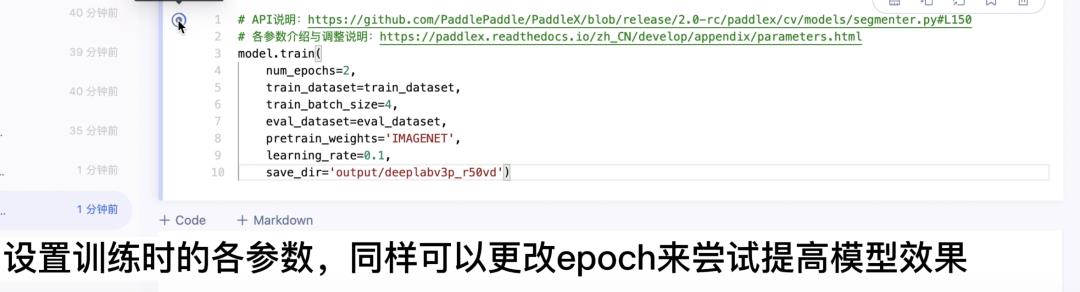

7.训练结束后查看bestmodel

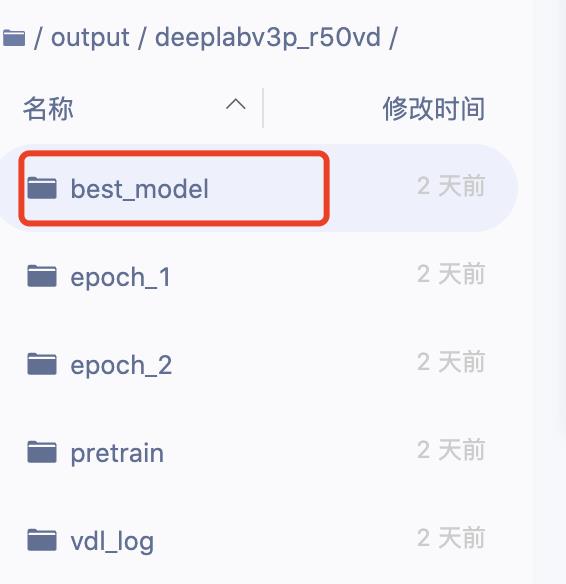
第三步:保存Notebook并关闭、停止运行


提示:Notebook一旦运行即会开始计费,如果不用请及时停止!以免浪费免费额度
模型预测
第一步:重新安装环境
1.启动Notebook并打开
2.重新执行安装的三条命令
第二步:上传预测的py文件
1.点击下方链接将py文件下载至本地
https://aistudio.baidu.com/aistudio/datasetdetail/120795
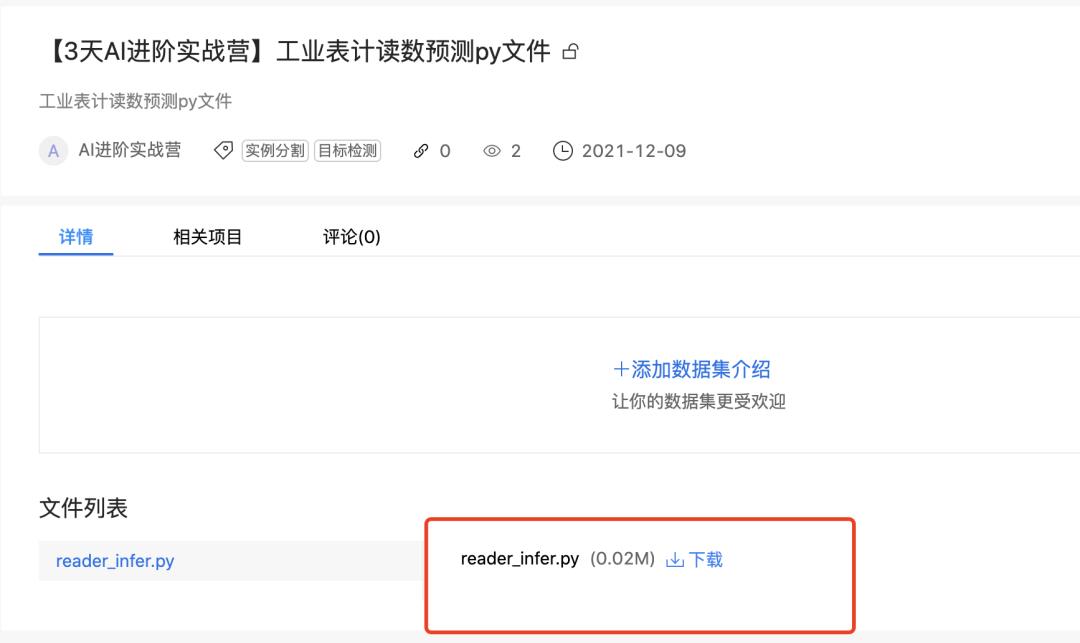
2.上传至Notebook中

第三步:模型预测

1.上传reader_infer.py文件后,执行一下命令进行模型预测
!python work/meter_reader/reader_infer.py --det_model_dir output/ppyolov2_r50vd_dcn/best_model --seg_model_dir output/deeplabv3p_r50vd/best_model/ --image meter_det/test/20190822_105.jpg


2.打开output/result查看预测结果

第四步:保存Notebook并关闭、停止运行
推理代码:
# coding: utf8
# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import os.path as osp
import numpy as np
import math
import cv2
import argparse
from paddlex import transforms as T
import paddlex as pdx
# 读数后处理中有把圆形表盘转成矩形的操作,矩形的宽即为圆形的外周长
# 因此要求表盘图像大小为固定大小,这里设置为[512, 512]
METER_SHAPE = [512, 512] # 高x宽
# 圆形表盘的中心点
CIRCLE_CENTER = [256, 256] # 高x宽
# 圆形表盘的半径
CIRCLE_RADIUS = 250
# 圆周率
PI = 3.1415926536
# 在把圆形表盘转成矩形后矩形的高
# 当前设置值约为半径的一半,原因是:圆形表盘的中心区域除了指针根部就是背景了
# 我们只需要把外围的刻度、指针的尖部保存下来就可以定位出指针指向的刻度
RECTANGLE_HEIGHT = 120
# 矩形表盘的宽,即圆形表盘的外周长
RECTANGLE_WIDTH = 1570
# 当前案例中只使用了两种类型的表盘,第一种表盘的刻度根数为50
# 第二种表盘的刻度根数为32。因此,我们通过预测的刻度根数来判断表盘类型
# 刻度根数超过阈值的即为第一种,否则是第二种
TYPE_THRESHOLD = 40
# 两种表盘的配置信息,包含每根刻度的值,量程,单位
METER_CONFIG = [
'scale_interval_value': 25.0 / 50.0,
'range': 25.0,
'unit': "(MPa)"
,
'scale_interval_value': 1.6 / 32.0,
'range': 1.6,
'unit': "(MPa)"
]
# 分割模型预测类别id与类别名的对应关系
SEG_CNAME2CLSID = 'background': 0, 'pointer': 1, 'scale': 2
def parse_args():
parser = argparse.ArgumentParser(description='Meter Reader Infering')
parser.add_argument(
'--det_model_dir',
dest='det_model_dir',
help='The directory of the detection model',
type=str)
parser.add_argument(
'--seg_model_dir',
dest='seg_model_dir',
help='The directory of the segmentation model',
type=str)
parser.add_argument(
'--image_dir',
dest='image_dir',
help='The directory of images to be inferred',
type=str,
default=None)
parser.add_argument(
'--image',
dest='image',
help='The image to be inferred',
type=str,
default=None)
parser.add_argument(
'--use_erode',
dest='use_erode',
help='Whether erode the lable map predicted from a segmentation model',
action='store_true')
parser.add_argument(
'--erode_kernel',
dest='erode_kernel',
help='Erode kernel size',
type=int,
default=4)
parser.add_argument(
'--save_dir',
dest='save_dir',
help='The directory for saving the predicted results',
type=str,
default='./output/result')
parser.add_argument(
'--score_threshold',
dest='score_threshold',
help="Predicted bounding boxes whose scores are lower than this threshlod are filtered",
type=float,
default=0.5)
parser.add_argument(
'--seg_batch_size',
dest='seg_batch_size',
help="The number of images fed into the segmentation model during one forward propagation",
type=int,
default=2)
return parser.parse_args()
def is_pic(img_name):
"""判断是否是图片
参数:
img_name (str): 图片路径
返回:
flag (bool): 判断值。
"""
valid_suffix = ['JPEG', 'jpeg', 'JPG', 'jpg', 'BMP', 'bmp', 'PNG', 'png']
suffix = img_name.split('.')[-1]
flag = True
if suffix not in valid_suffix:
flag = False
return flag
class MeterReader:
"""检测表盘的位置,分割各表盘内刻度和指针的位置,并根据分割结果计算出各表盘的读数
参数:
det_model_dir (str): 用于定位表盘的检测模型所在路径。
seg_model_dir (str): 用于分割刻度和指针的分割模型所在路径。
"""
def __init__(self, det_model_dir, seg_model_dir):
if not osp.exists(det_model_dir):
raise Exception("Model path does not exist".format(
det_model_dir))
if not osp.exists(seg_model_dir):
raise Exception("Model path does not exist".format(
seg_model_dir))
self.detector = pdx.load_model(det_model_dir)
self.segmenter = pdx.load_model(seg_model_dir)
def decode(self, img_file):
"""图像解码
参数:
img_file (str|np.array): 图像路径,或者是已解码的BGR图像数组。
返回:
img (np.array): BGR图像数组。
"""
if isinstance(img_file, str):
img = cv2.imread(img_file).astype('float32')
else:
img = img_file.copy()
return img
def filter_bboxes(self, det_results, score_threshold):
"""过滤置信度低于阈值的检测框
参数:
det_results (list[dict]): 检测模型预测接口的返回值。
score_threshold (float):置信度阈值。
返回:
filtered_results (list[dict]): 过滤后的检测狂。
"""
filtered_results = list()
for res in det_results:
if res['score'] > score_threshold:
filtered_results.append(res)
return filtered_results
def roi_crop(self, img, det_results):
"""抠取图像上各检测框的图像区域
参数:
img (np.array):BRG图像数组。
det_results (list[dict]): 检测模型预测接口的返回值。
返回:
sub_imgs (list[np.array]): 各检测框的图像区域。
"""
sub_imgs = []
for res in det_results:
# Crop the bbox area
xmin, ymin, w, h = res['bbox']
xmin = max(0, int(xmin))
ymin = max(0, int(ymin))
xmax = min(img.shape[1], int(xmin + w - 1))
ymax = min(img.shape[0], int(ymin + h - 1))
sub_img = img[ymin:(ymax + 1), xmin:(xmax + 1), :]
sub_imgs.append(sub_img)
return sub_imgs
def resize(self, imgs, target_size, interp=cv2.INTER_LINEAR):
"""图像缩放至固定大小
参数:
imgs (list[np.array]):批量BGR图像数组。
target_size (list|tuple):缩放后的图像大小,格式为[高, 宽]。
interp (int):图像差值方法。默认值为cv2.INTER_LINEAR。
返回:
resized_imgs (list[np.array]):缩放后的批量BGR图像数组。
"""
resized_imgs = list()
for img in imgs:
img_shape = img.shape
scale_x = float(target_size[1]) / float(img_shape[1])
scale_y = float(target_size[0]) / float(img_shape[0])
resize_img = cv2.resize(
img, None, None, fx=scale_x, fy=scale_y, interpolation=interp)
resized_imgs.append(resize_img)
return resized_imgs
def seg_predict(self, segmenter, imgs, batch_size):
"""分割模型完成预测
参数:
segmenter (pdx.seg.model):加载后的分割模型。
imgs (list[np.array]):待预测的输入BGR图像数组。
batch_size (int): 分割模型前向预测一次时输入图像的批量大小。
返回:
seg_results (list[dict]): 输入图像的预测结果。
"""
seg_results = list()
num_imgs = len(imgs)
for i in range(0, num_imgs, batch_size):
batch = imgs[i:min(num_imgs, i + batch_size)]
result = segmenter.predict(batch)
seg_results.extend(result)
return seg_results
def erode(self, seg_results, erode_kernel):
"""对分割模型预测结果中label_map做图像腐蚀操作
参数:
seg_results (list[dict]):分割模型的预测结果。
erode_kernel (int): 图像腐蚀的卷积核的大小。
返回:
eroded_results (list[dict]):对label_map进行腐蚀后的分割模型预测结果。
"""
kernel = np.ones((erode_kernel, erode_kernel), np.uint8)
eroded_results = seg_results
for i in range(len(seg_results)):
test_resulte = seg_results[i]['label_map']
# print('***********************************',type(test_resulte))
# eroded_results[i]['label_map'] = cv2.erode(
# seg_results[i]['label_map'], kernel)
eroded_results[i]['label_map'] = cv2.erode(
test_resulte.astype('uint8'), kernel)
return eroded_results
def circle_to_rectangle(self, seg_results):
"""将圆形表盘的预测结果label_map转换成矩形
圆形到矩形的计算方法:
因本案例中两种表盘的刻度起始值都在左下方,故以圆形的中心点为坐标原点,
从-y轴开始逆时针计算极坐标到x-y坐标的对应关系:
x = r + r * cos(theta)
y = r - r * sin(theta)
注意:
1. 因为是从-y轴开始逆时针计算,所以r * sin(theta)前有负号。
2. 还是因为从-y轴开始逆时针计算,所以矩形从上往下对应圆形从外到内,
可以想象把圆形从-y轴切开再往左右拉平时,圆形的外围是上面,內围在下面。
参数:
seg_results (list[dict]):分割模型的预测结果。
返回值:
rectangle_meters (list[np.array]):矩形表盘的预测结果label_map。
"""
rectangle_meters = list()
for i, seg_result in enumerate(seg_results):
label_map = seg_result['label_map']
# rectangle_meter的大小已经由预先设置的全局变量RECTANGLE_HEIGHT, RECTANGLE_WIDTH决定
rectangle_meter = np.zeros(
(RECTANGLE_HEIGHT, RECTANGLE_WIDTH), dtype=np.uint8)
for row in range(RECTANGLE_HEIGHT):
for col in range(RECTANGLE_WIDTH):
theta = PI * 2 * (col + 1) / RECTANGLE_WIDTH
# 矩形从上往下对应圆形从外到内
rho = CIRCLE_RADIUS - row - 1
y = int(CIRCLE_CENTER[0] + rho * math.cos(theta) + 0.5)
x = int(CIRCLE_CENTER[1] - rho * math.sin(theta) + 0.5)
rectangle_meter[row, col] = label_map[y, x]
rectangle_meters.append(rectangle_meter)
return rectangle_meters
def rectangle_to_line(self, rectangle_meters):
"""从矩形表盘的预测结果中提取指针和刻度预测结果并沿高度方向压缩成线状格式。
参数:
rectangle_meters (list[np.array]):矩形表盘的预测结果label_map。
返回:
line_scales (list[np.array]):刻度的线状预测结果。
line_pointers (list[np.array]):指针的线状预测结果。
"""
line_scales = list()
line_pointers = list()
for rectangle_meter in rectangle_meters:
height, width = rectangle_meter.shape[0:2]
line_scale = np.zeros((width), dtype=np.uint8)
line_pointer = np.zeros((width), dtype=np.uint8)
for col in range(width):
for row in range(height):
if rectangle_meter[row, col] == SEG_CNAME2CLSID['pointer']:
line_pointer[col] += 1
elif rectangle_meter[row, col] == SEG_CNAME2CLSID['scale']:
line_scale[col] += 1
line_scales.append(line_scale)
line_pointers.append(line_pointer)
return line_scales, line_pointers
def mean_binarization(self, data_list):
"""对图像进行均值二值化操作
参数:
data_list (list[np.array]):待二值化的批量数组。
返回:
binaried_data_list (list[np.array]):二值化后的批量数组。
"""
batch_size = len(data_list)
binaried_data_list = data_list
for i in range(batch_size):
mean_data = np.mean(data_list[i])
width = data_list[i].shape[0]
for col in range(width):
if data_list[i][col] < mean_data:
binaried_data_list[i][col] = 0
else:
binaried_data_list[i][col] = 1
return binaried_data_list
def locate_scale(self, line_scales):
"""在线状预测结果中找到每根刻度的中心位置
参数:
line_scales (list[np.array]):批量的二值化后的刻度线状预测结果。
返回:
scale_locations (list[list]):各图像中每根刻度的中心位置。
"""
batch_size = len(line_scales)
scale_locations = list()
for i in range(batch_size):
line_scale = line_scales[i]
width = line_scale.shape[0]
find_start = False
one_scale_start = 0
one_scale_end = 0
locations = list()
for j in range(width - 1):
if line_scale[j] > 0 and line_scale[j + 1] > 0:
if find_start == False:
one_scale_start = j
find_start = True
if find_start:
if line_scale[j] == 0 and line_scale[j + 1] == 0:
one_scale_end = j - 1
one_scale_location = (
one_scale_start + one_scale_end) / 2
locations.append(one_scale_location)
one_scale_start = 0
one_scale_end = 0
find_start = False
scale_locations.append(locations)
return scale_locations
def locate_pointer(self, line_pointers):
"""在线状预测结果中找到指针的中心位置
参数:
line_scales (list[np.array]):批量的指针线状预测结果。
返回:
scale_locations (list[list]):各图像中指针的中心位置。
"""
batch_size = len(line_pointers)
pointer_locations = list()
for i in range(batch_size):
line_pointer = line_pointers[i]
find_start = False
pointer_start = 0
pointer_end = 0
location = 0
width = line_pointer.shape[0]
for j in range(width - 1):
if line_pointer[j] > 0 and line_pointer[j + 1] > 0:
if find_start == False:
pointer_start = j
find_start = True
if find_start:
if line_pointer[j] == 0 and line_pointer[j + 1] == 0:
pointer_end = j - 1
location = (pointer_start + pointer_end) / 2
find_start = False
break
pointer_locations.append(location)
return pointer_locations
def get_relative_location(self, scale_locations, pointer_locations):
"""找到指针指向了第几根刻度
参数:
scale_locations (list[list]):批量的每根刻度的中心点位置。
pointer_locations (list[list]):批量的指针的中心点位置。
返回:
pointed_scales (list[dict]):每个表的结果组成的list。每个表的结果由字典表示,
字典有两个关键词:'num_scales'、'pointed_scale',分别表示预测的刻度根数、
预测的指针指向了第几根刻度。
"""
pointed_scales = list()
for scale_location, pointer_location in zip(scale_locations,
pointer_locations):
num_scales = len(scale_location)
pointed_scale = -1
if num_scales > 0:
for i in range(num_scales - 1):
if scale_location[
i] <= pointer_location and pointer_location < scale_location[
i + 1]:
pointed_scale = i + (
pointer_location - scale_location[i]
) / (scale_location[i + 1] - scale_location[i] + 1e-05
) + 1
result = 'num_scales': num_scales, 'pointed_scale': pointed_scale
pointed_scales.append(result)
return pointed_scales
def calculate_reading(self, pointed_scales):
"""根据刻度的间隔值和指针指向的刻度根数计算表盘的读数
"""
readings = list()
batch_size = len(pointed_scales)
for i in range(batch_size):
pointed_scale = pointed_scales[i]
# 刻度根数大于阈值的为第一种表盘
if pointed_scale['num_scales'] > TYPE_THRESHOLD:
reading = pointed_scale['pointed_scale'] * METER_CONFIG[0][
'scale_interval_value']
else:
reading = pointed_scale['pointed_scale'] * METER_CONFIG[1][
'scale_interval_value']
readings.append(reading)
return readings
def get_meter_reading(self, seg_results):
"""对分割结果进行读数后处理得到各表盘的读数
参数:
seg_results (list[dict]): 分割模型的预测结果。
返回:
meter_readings (list[dcit]): 各表盘的读数。
"""
rectangle_meters = self.circle_to_rectangle(seg_results)
line_scales, line_pointers = self.rectangle_to_line(rectangle_meters)
binaried_scales = self.mean_binarization(line_scales)
binaried_pointers = self.mean_binarization(line_pointers)
scale_locations = self.locate_scale(binaried_scales)
pointer_locations = self.locate_pointer(binaried_pointers)
pointed_scales = self.get_relative_location(scale_locations,
pointer_locations)
meter_readings = self.calculate_reading(pointed_scales)
return meter_readings
def print_meter_readings(self, meter_readings):
"""打印各表盘的读数
参数:
meter_readings (list[dict]):各表盘的读数
"""
for i in range(len(meter_readings)):
print("Meter : ".format(i + 1, meter_readings[i]))
def visualize(self, img, det_results, meter_readings, save_dir="./"):
"""可视化图像中各表盘的位置和读数
参数:
img (str|np.array): 图像路径,或者是已解码的BGR图像数组。
det_results (dict): 检测模型的预测结果。
meter_readings (list): 各表盘的读数。
save_dir (str):可视化后的图片保存路径。
"""
vis_results = list()
for i, res in enumerate(det_results):
# 将检测结果中的关键词`score`替换成读数,就可以调用pdx.det.visualize画图了
res['score'] = meter_readings[i]
vis_results.append(res)
# 检测结果可视化时会滤除score低于threshold的框,这里读数都是>=-1的,所以设置thresh=-1
pdx.det.visualize(img, vis_results, threshold=-1, save_dir=save_dir)
def predict(self,
img_file,
save_dir='./',
use_erode=True,
erode_kernel=4,
score_threshold=0.5,
seg_batch_size=2):
"""检测图像中的表盘,而后分割出各表盘中的指针和刻度,对分割结果进行读数后处理后得到各表盘的读数。
参数:
img_file (str):待预测的图片路径。
save_dir (str): 可视化结果的保存路径。
use_erode (bool, optional): 是否对分割预测结果做图像腐蚀。默认值:True。
erode_kernel (int, optional): 图像腐蚀的卷积核大小。默认值: 4。
score_threshold (float, optional): 用于滤除检测框的置信度阈值。默认值:0.5。
seg_batch_size (int, optional):分割模型前向推理一次时输入表盘图像的批量大小。默认值为:2。
"""
img = self.decode(img_file)
det_results = self.detector.predict(img)
filtered_results = self.filter_bboxes(det_results, score_threshold)
sub_imgs = self.roi_crop(img, filtered_results)
sub_imgs = self.resize(sub_imgs, METER_SHAPE)
seg_results = self.seg_predict(self.segmenter, sub_imgs,
seg_batch_size)
seg_results = self.erode(seg_results, erode_kernel)
meter_readings = self.get_meter_reading(seg_results)
self.print_meter_readings(meter_readings)
self.visualize(img, filtered_results, meter_readings, save_dir)
def infer(args):
image_lists = list()
if args.image is not None:
if not osp.exists(args.image):
raise Exception("Image does not exist.".format(args.image))
if not is_pic(args.image):
raise Exception(" is not a picture.".format(args.image))
image_lists.append(args.image)
elif args.image_dir is not None:
if not osp.exists(args.image_dir):
raise Exception("Directory does not exist.".format(
args.image_dir))
for im_file in os.listdir(args.image_dir):
if not is_pic(im_file):
continue
im_file = osp.join(args.image_dir, im_file)
image_lists.append(im_file)
meter_reader = MeterReader(args.det_model_dir, args.seg_model_dir)
if len(image_lists) > 0:
for image in image_lists:
meter_reader.predict(image, args.save_dir, args.use_erode,
args.erode_kernel, args.score_threshold,
args.seg_batch_size)
if __name__ == '__main__':
args = parse_args()
infer(args)
以上是关于飞桨AI进阶实战:工业表计读数(记录)的主要内容,如果未能解决你的问题,请参考以下文章
助力培养高端复合型AI人才 飞桨首席AI架构师培养计划再启航
320万开发者在用的飞桨,全新发布推理部署导航图:打通AI应用最后一公里