数据结构链(恋)之修炼手册助你脱单一臂之力
Posted MUSE_X
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构链(恋)之修炼手册助你脱单一臂之力相关的知识,希望对你有一定的参考价值。
零、前言
话不多说,想找对象?赶紧看一看吧!
一、线性表的定义
什么是线性表?
顾名思义,线性表就是数据元素的排列像一条线一样的表!
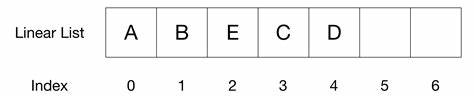
这样看起来,线性表的定义真的是异常的简单,但是它的应用会是怎样的呢?
二、线性表的存储结构与运算
从数据结构的基础中我们直到分析一个数据结构应该是从逻辑结构、存储结构与运算出发的,线性表的逻辑结构如上图所示,浅显易懂,但其在计算机中的存储结构却有多种,下面我们就边了解存储结构边学习其相应的运算!
1.顺序存储结构
1.1什么是顺序存储结构?
顺序存储是线性表最常用的存储方式,它直接将线性表的逻辑结构映射到存储结构上。
用我们自己的话说就是,我们直观看到的什么样子,就在计算机中存储成什么样子,也就是一条线串起了数据,就像一串珍珠手链一样,可见数据在我们程序员心中就如同珍珠一样珍贵!(大家认同吗?)
1.2什么是顺序表?
线性表的顺序存储结构称为顺序表
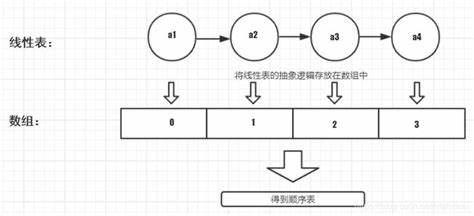
顺序表容量设置代码实现:
class SqList:
def __init__(self):
self.initcapacity=5 #设置初始容量为5
self.capacity=self.initcapacity #容量设置为初始容量
self.data=[None]*self.capacity #设置顺序表的空间
self.size=0 #长度设置为0
1.3顺序表的基本运算算法
0.容量的更新操作
def resize(self,newcapacity): #改变顺序表的容量为newcapacity
olddata=self.data #先将原来的数据保存给olddata
self.data=[None]*newcapacity #建立一个新容量的数据存储的列表
self.capacity=newcapacity
for i in range(self.size): #循环遍历将原列表内的数据依次赋值给新的列表
self.data[i]=olddata[i]
1.建立顺序表
def CreateList(self,a): #由给定的数组a中的元素去建立顺序表
for i in range(0,len(a)): #循环遍历
if self.size==self.capacity: #当元素出现上溢出时,调取resize方法扩大容量
self.resize(2*self.size)
self.data[self.size]=a[i] #添加元素
self.size+=1 #每次添加一个后长度增1
2.将元素e添加到顺序表的末尾
def Add(self,e):
if self.size==self.capacity: #先判断顺序表空间是否已经满了,若满了则加倍容量
self.resize(2*self.size)
self.data[self.size]=e #添加元素e
self.size+=1
3.顺序表的长度
def getsize(self):
return self.size
4.返回顺序表中序号为i的元素值
def __getitem__(self,i):
return self.data[i]
5.设置顺序表中序号为i的元素值
def __setitem__(self,i,x):
self.data[i]=x
6.求顺序表中第一个值为e的元素的索引
def GetNo(self,e):
i=0
while i<self.size and self.data[i]!=e: #查找元素e
i+=1
if (i>=self.size):
return -1 #未找到时返回-1
else:
return i #找到时返回其索引
7.在顺序表中的第i个位置插入e
def Insert(self,i,e):
if self.size==self.capacity:
self.resize(2*self.size)
for j in range(self.size,-1,-1): #将data[i]以及后面的元素后移一个位置
self.data[j]=self.data[j-1]
self.data[i]=e #移完后插入元素e
self.size+=1
8.删除顺序表中第i个数据元素
def Delete(self,i):
for j in range(i,self.size-1):
self.data[j]=self.data[j+1] #将data[i]之后的元素前移一个位置
self.size-=1 #移动后长度-1
9.输出顺序表中的所有元素
def display(self):
for i in range(self.size):
print(self.data[i],end='')
print()
2.链式存储结构
i.链表
1)什么是链表?
线性表的链式存储结构称为链表
链表,顾名思义,将数据以锁链式地连接起来,既然是锁链,便会包含许多的结点,就像锁链不会只连接自己一样,链表中的节点既包含了元素自身的信息,同时又包含了元素之间逻辑关系的信息;
这里便要引进一个指针属性的概念;
2)什么是指针属性?
指针属性就是说一个链表的结点中包含后继结点的地址信息或者前驱结点的地址信息
需要注意的是,Python中没有指针的概念,这里的指针属性实际上存放的是后继节点或者前驱结点的引用,具体的指针的概念和理解,可以翻看C语言!
以下对单链表和双链表的定义也会涉及到指针属性这个概念!
ii.单链表
1)什么是单链表?
每个结点只设置一个指向其后继结点的指针属性,这样的链表称为线性单向链接表,简称单链表。

2)单链表结点类与单链表类
话不多说,直接上代码!
class LinkNode: #单链表结点类
def __init__(self,data=None):
self.data=data #data属性
self.next=None #next属性
class LinkList: #单链表类
def __init__(self):
self.head=LinkNode() #建立头结点head对象
self.head.next=None
3)单链表中插入和删除结点操作
a.在单链表中插入一个结点,需要修改其插入位置前的结点的指针属性,将其指向将要插入的结点即可,再将新插入的结点的指针属性指向插入前结点的后继结点即可。
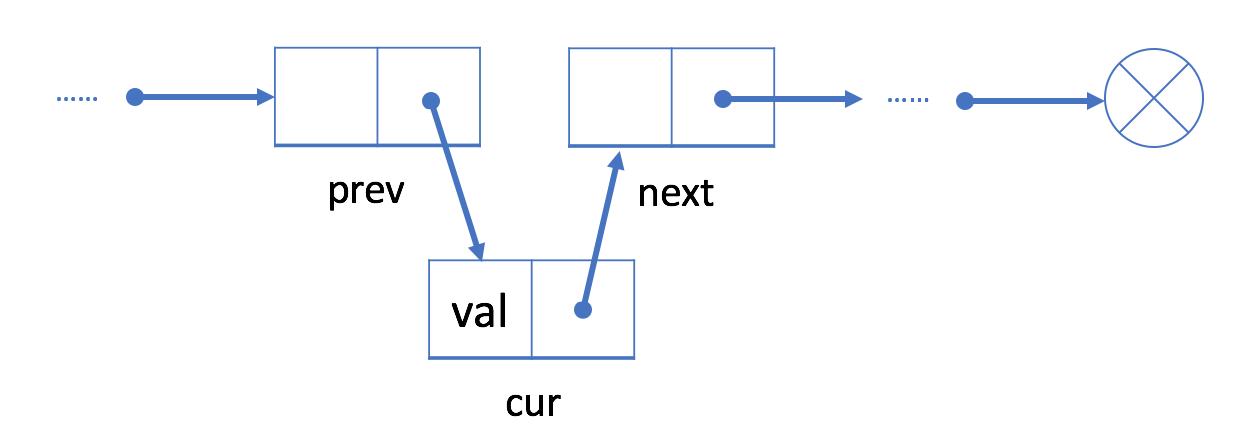
实现插入操作的代码:
s.next=p.next
p.next=s
b. 删除某个结点只需要将被删除结点的前一个结点指向其后一个结点即可。

实现删除操作的代码:
p.next=p.next.next
4)整体建立单链表
a.头插法建表
头插法建表就是从一个空表开始,我们依次读取给定数组内的元素并将其插入在表头,这样的插入会导致新插入的元素在前,插入过的元素在后,也就相当于对给定数组进行了一个倒序排列。

实现代码:
class CreateListF(self,a):
for i in range(0,len(a)): #循环建立数据结点s
s=LinkNode(a[i]) #新建存放a[i]元素的结点s
s.next=self.head.next #将s结点插入开始结点之前、头结点之后
self.head.next=s
b.尾插法建表
知道了头插法的概念,尾插法也就很好理解啦,其实就是每次插入到列表的末端,Python列表里的append方法就是这么个功能;采用尾插法建表较于头插法建表的一个好处就是可以得到与给定数组相同次序的链表!

代码实现:
def CreateListR(self,a):
t=self.head #t始终指向尾结点,开始时指向头结点
for i in range(0,len(a)): #循环建立结点s
s=LinkNode(a[i]) #新建存放a[i]元素的结点
t.next=s #将s结点插入在t结点之后
t=s
t.next=None #尾结点的next置空
5)单链表中的基本运算算法
以下的基本运算算法与顺序表中的运算算法设计思路类似,但是考虑到链表与顺序表还是有差别的,这里我们再详细介绍以下单链表的基本运算算法,之后双链表的可以参照这个,再添加一个指针属性!
0.查找单链表中序号为i的结点
def geti(self,i):
p=self.head
j=-1
while(j<i and p is not None):
j+=1
p=p.next
return p
1.单链表的末尾添加元素e
def Add(self,e):
s=LinkNode(e) #为元素e建立一个新结点
p=self.head #p指向头结点,之后循环寻找尾结点
while p.next is not None: #若p的next属性为空,此时为尾结点3.
p=p.next
p.next=s #在尾结点之后插入结点s
2.单链表的长度
def getsize(self):
count=0 #计数器
p=self.head
while p.next is not None: #找到尾结点之后返回计数器count的值
p=p.next
count+=1
return count
3.单链表中索引为i的元素值
def __getitem__(self,i):
return self.geti(i) #借助0中的方法查找索引为i的值后返回
4.单链表中索引为i的元素值设置为e
def __setitem__(self,i,e):
p=self.geti(i)
p.data=e
5.单链表在索引为i的位置插入元素e
def Insert(self,i,e):
s=LinkNode(e)
p=self.geti(i-1)
s.next=p.next
p.next=s
6.单链表删除索引为i的元素
def Delete(self,i):
p=self.geti(i-1)
p.next=p.next.next
7.单链表的元素输出
def display(self):
p=self.head.next
while p is not None:
print(p.data,end='')
p=p.next
print()
单链表常用的一些运算都放在上面了,这些只是方法体,遇见实际问题时会有不一样的变化,但思路的设计不会改变,融会贯通,是我们都需要的能力!
iii.双链表
其实学习了单链表,就如同我们我们学习了线,现在我们要来二维(不能严格算)了,增加了一个新的指针属性!
1)什么是双链表?
每个结点中设置两个指针属性,分别用于指向其前驱结点和后继结点,这样的链表称为线性双向链接表,简称双链表。
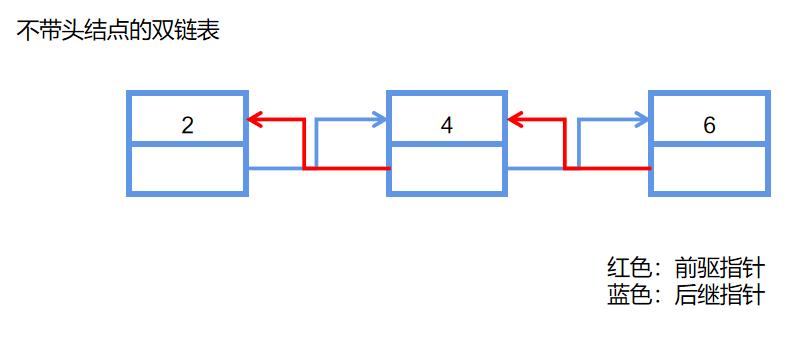
2)双链表的结点类与双链表类
再废话一下,双链表的结点类与单链表的结点类类似,不一样的地方,大家感受以下代码:
class DLinkNode:
def __init__(self,data=None):
self.data=data
self.next=None
self.prior=None #新加的prior属性(新的指针属性)
接下来的就是双链表类:
class DLinkList:
def __init__(self):
self.dhead=DLinkNode()
self.dhead.next=None
self.dhead.prior=None
3)插入与删除结点操作
a.插入结点
在单链表中插入结点只需要修改一个指针属性即可,在双链表需要分别修改前驱结点与后继结点;
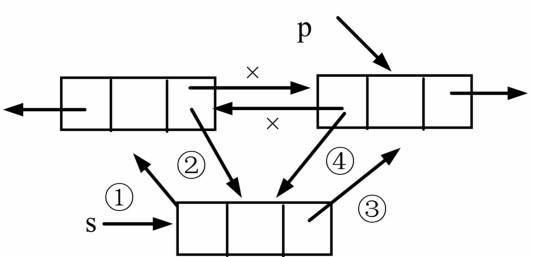
代码实现:
s.next=p.next
p.next.prior=s
s.prior=p
p.next=s
b.删除结点
删除结点的操作也是对两个指针属性的对应操作;

实现代码:
p.next.prior=p.prior
p.prior.next=p.next
4)整体建立双链表
a.头插法建表
类比单链表的头插法建表,每次都将新结点s插入表头即可;
def CreateListF(self,a):
for i in range(len(a)):
s=DLinkNode(a[i])
s.next=self.dhead.next
if self.dhead.next!=None:
self.dhead.next.prior=s
self.dhead.next=s
s.prior=self.dhead
b.尾插法建表
def CreateListR(self,a):
t=self.dhead
for i in range(len(a)):
s=DLinkNode(a[i])
t.next=s
s.prior=t
t=s
t.next=None
双链表的基本运算算法大家可以根据双链表的建立以及单链表中的方法进行类比分析!
iiii.循环链表
1)什么是循环链表?
构成一个环的单链表或双链表就叫作循环链表

循环链表是链式存储结构中的一种特殊情况,但本质上仍属于链表,仍然具有单链表与双链表的特点,参照以上算法设计即可,需要注意的是,循环链表是构成一个环的,这也就是说在链表中的尾结点的后继结点不再指向None,而是指向了头结点继续链表的循环!
三、顺序表和链表的比较
我们了解了顺序表与链表的所有的基本内容,但是在实际应用时我们应该选取哪个存储结构作为我们的首选呢?
其实呢,没有哪个表是绝对的,都需要我们具体问题具体分析(最近在复习马克思主义),既然是具体问题具体分析,那么也就说明了每个存储结构都有其适用的特点;
选取原则如下
基于空间考虑:当线性表的长度变化不大且易于确定时,为了节省存储空间宜采用顺序表;当线性表的长度变化较大且难以估计其存储大小时就需要我们使用链表了。
基于时间考虑:若线性表的运算主要是查找,很少做插入和删除操作,适合采用顺序表;反之,若需要频繁地插入和删除操作则使用链表较好。
总结来看,若一些历史的数据且含量固定时我们用顺序表就可以了,但是经常需要修改的新生事物就需要用链表了!
四、学以致用
学习了线性表之后,我们该怎样去使用呢?
这里简单设计了一个学生成绩管理程序(Python),可以记录每个学生的学号、姓名、课程和分数;
自己实现真的就会有满满的成就感,之后学习算法也就更有动力了!
#方法实现类的设计
import distutils.errors
from operator import itemgetter
class StudList:
def __init__(self):
self.data=[]
def Addstud(self):
print(" 请输入一个学生记录")
no1=int(input(" 学号:"))
name1=input(" 姓名:")
course1=input(" 课程:")
fraction1=int(input(" 分数:"))
self.data.append([no1,name1,course1,fraction1])
def Dispstud(self):
if len(self.data)>0:
print("\\t学号\\t \\t姓名\\t \\t课程\\t \\t分数")
for i in range(len(self.data)):
print("\\t%d\\t\\t%s\\t\\t%s\\t\\t%d"%(self.data[i][0],self.data[i][1],self.data[i][2],self.data[i][3]))
else:
print(" **没有任何学生记录")
def Delstud(self):
no1=int(input(" 删除的学号:"))
course1=input(" 删除的课程:")
find=False
for i in range(len(self.data)):
if self.data[i][0]==no1 and self.data[i][2]==course1:
find=True
break
if find:
st.data.remove(self.data[i])
print(" **成功删除学号为%d的学生记录"%(no1))
else:
print(" **没有找到学号为%d的学生记录"%(no1))
def Sort1(self):
self.data=sorted(self.data,key=itemgetter(0))
self.Dispstud()
def Sort2(self):
self.data.sort(key=lambda s:(s[2],-s[3]))
self.Dispstud()
#测试程序的编写
st=StudList()
while True:
print("1.显示全部记录 2.输入 3.删除 4.学号排序 5.课程排序 其他退出 请选择:",end=' ')
sel=int(input())
if sel==1:
st.Dispstud()
elif sel==2:
st.Addstud()
elif sel==3:
st.Delstud()
elif sel==4:
st.Sort1()
elif sel==5:
st.Sort2()
else:
break
运行结果:

恭喜你,链表学完了,成功修完链(恋)爱宝典,也祝愿大家早日找到自己的归属!
喜欢的话,希望大家可以一键三连,如果点关注的话,那我会更加开心,你的恋爱旅程也会更加顺利!
以上是关于数据结构链(恋)之修炼手册助你脱单一臂之力的主要内容,如果未能解决你的问题,请参考以下文章
快速定位线上慢 SQL 问题,掌握这几个性能排查工具可助你一臂之力
快速定位线上慢 SQL 问题,掌握这几个性能排查工具可助你一臂之力
快速定位线上慢 SQL 问题,掌握这几个性能排查工具可助你一臂之力