日志与可视化方案:从ELK到EFK,再到ClickHouse
Posted 富贵007
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了日志与可视化方案:从ELK到EFK,再到ClickHouse相关的知识,希望对你有一定的参考价值。
EFK方案
从ELK谈起
ELK是三个开源软件的缩写,分别表示:Elasticsearch,Logstash,Kibana。新增了一个FlieBeat,它是一个轻量级的日志收集处理工具,FlieBeat占用资源少,适用于在各个服务器上搜集日之后,传输给Logstash。
Elasticsearch:开源分布式搜索引擎,提供搜集,分析,缓存数据三大功能,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负 载等。
Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构, client 端安装在需要收集日志的主机上, server 端负责将收到的各节点日志进行过
滤、修改等操作在一并发往 elasticsearch 上去。
Kibana 也是一个开源和免费的工具, Kibana 可以为 Logstash 和 ElasticSearch 提供的日志分析友
好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
从ELK挑战到EFK日志方案
ELK挑战
日志流量的增长导致了平台部署规模巨大,用户需求也发生了显著变化。两者都给基于 ELK 的平台带来了许多挑战,而这些挑战在较小的规模下是看不到的:
- 日志模式:我们的日志是半结构化的。ES(Elasticsearch)会自动推导模式,在整个集群中保持一致,并在后续日志中强制执行。如果字段类型不兼容,将导致 ES 出现类型冲突错误,从而丢弃违规日志。尽管对具有明确定义结构的业务事件实施一致的模式是合理的,但是对日志记录而言,这将导致开发人员的生产力大大下降,因为日志模式会随着时间的推移有机地演化。举例来说,一个大型的 API 平台可能会有数百名工程师进行更新,在 ES 索引映射中累积了数千个字段,而且不同的工程师很可能使用相同的字段名,但是不同的字段值是不同的类型,从而导致 ES 的类型冲突。这会迫使工程师学习已有的模式,并保持它们的一致性,仅仅打印一些服务日志,效率很低。理想情况下,平台应该将模式更改作为一个规范,并且能够为用户处理多种类型的字段。
- 运营成本:如果一个集群受到大量查询或映射爆炸的不利影响,我们必须在每个区域运行 20 多个 ES 集群,以限制爆炸半径。Logstash 管道的数量更多,每个区域有 50 多个,以适应特殊用例和自定义配置。昂贵的查询和映射爆炸都会严重影响 ES 集群的性能,有时甚至会“冻结”集群,这时我们不得不重新启动集群使其恢复。随着集群数量的增加,这种中断越来越频繁。虽然我们竭尽全力实现流程自动化,例如检测并禁用会引起映射爆炸和类型冲突的字段,重新平衡 ES 集群之间的流量等等,但是人工干预解决类型冲突等仍是不可避免的。我们想要一个能够支持我们组织中大量新用例的平台,而不必承担大量的运营开销。
- 硬件成本:在 ES 中,索引字段的成本相当高,因为它需要建立和维护复杂的倒排索引和正排索引结构,并将其写入事务日志,周期性地将内存缓冲区刷新到磁盘上,并定期进行后台合并,以保持刷新索引段的数量不至于无限制地增长,这些都需要大量的处理能力,并且会增加日志成为可查询的延迟。因此,我们的 ES 集群没有对日志中的所有字段进行索引,而是配置为索引多达三个级别的字段。但是摄取所有生成的日志仍然会消耗大量的硬件资源,并且扩展成本太高。
- 聚合查询:在我们的生产环境中发现,80% 以上的查询都是聚合查询,比如术语、直方图和百分数聚合。虽然 ES 在优化前向索引结构方面有所改进,但其设计仍然不能支持跨大型数据集的快速聚合。低效的性能会导致不愉快的用户体验。举例来说,在查询最后 1 小时的日志(大约 1.3 TB)时,一个日志数量巨大的服务的关键仪表盘加载速度非常缓慢,而且在查询最后 6 小时的日志时常常出现超时,从而导致无法诊断产品问题。
我们只能在一个基于 ELK 的平台上摄取 Uber 内部生成的部分日志。在 ELK 平台基础上的大规模部署和许多固有的低效,使扩展以摄取所有日志并提供完整的、高分辨率的产品环境概述的成本高得令人望而却步。
EFK方案
由于 logstash 内存占用较大,灵活性相对没那么好, ELK 正在被 EFK 逐步替代 . 其中本文所讲的 EFK 是 Elasticsearch+Fluentd+Kfka。
Kubernetes 中比较流行的日志收集解决方案是 Elasticsearch 、 Fluentd 和 Kibana ( EFK) 技术栈,也是官方现在比较推荐的一种方案。
Fluentd 是一个收集日志文件的开源软件,目前提供数百个插件可用于存储大数据用于日志搜索,数据分析和存储。
Fluentd适用于以下场景。
收集多台服务器的访问日志进行可视化
在AWS 等云端使用 AutoScaling 时把日志文件收集至 S3( 需要安装插件 )
收集客户端的信息并输出至Message Queue ,供其他应用处理

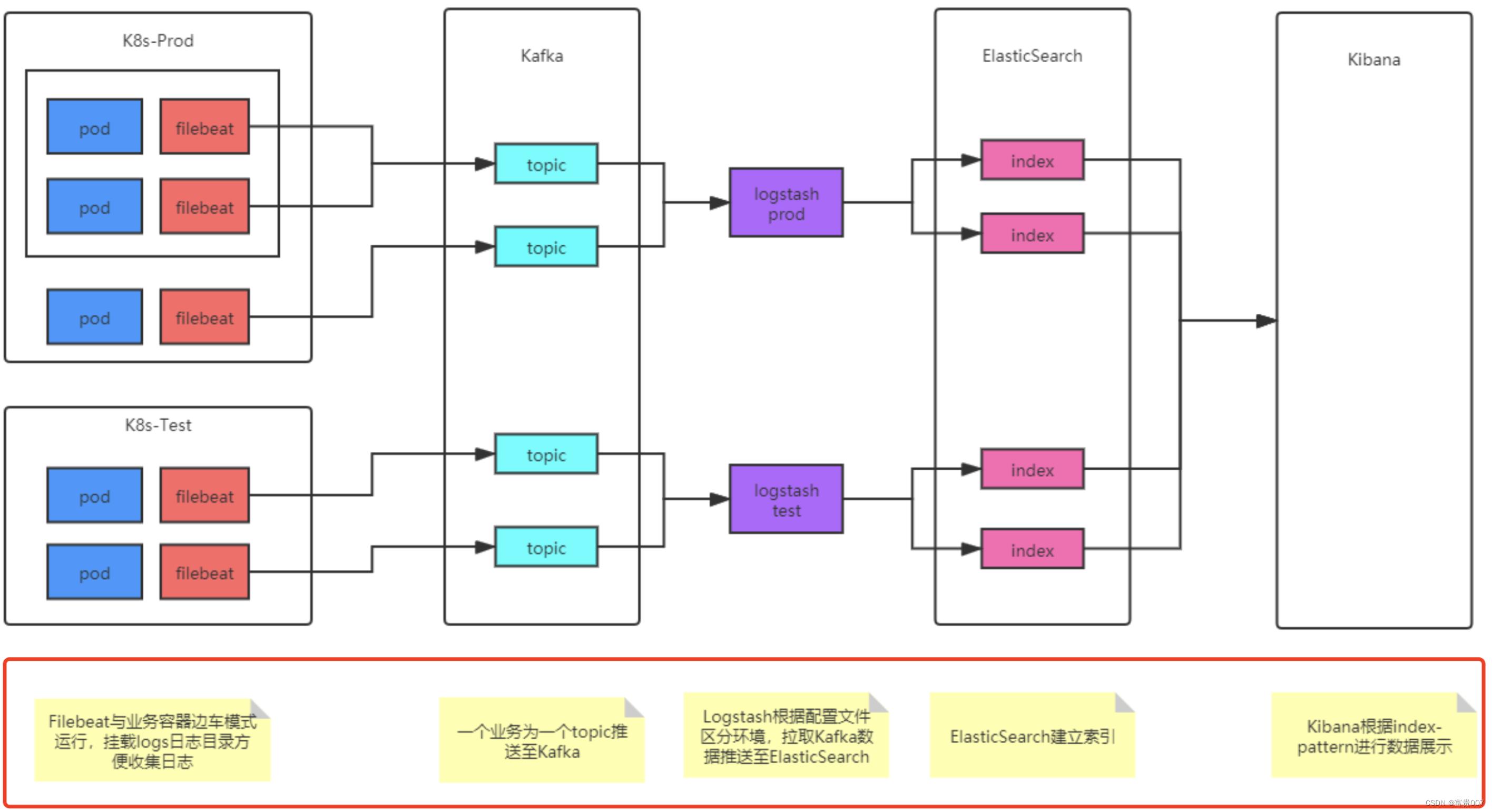
第一层,数据采集层:数据采集层位于最左边的业务服务器集群上,在每个业务服务器上面安装了 Filebeat 做日志收集,然后把采集到的原始日志发送到 Kafka+ZooKeeper 集群上。
第二层,消息队列层:原始日志发送到 Kafka+ZooKeeper 集群上后,会进行集中存储,此时,Filbeat 是消息的生产者,存储的消息可以随时被消费。
第三层,数据分析层:Logstash 作为消费者,会去 Kafka+ZooKeeper 集群节点实时拉取原始日志,然后将获取到的原始日志根据规则进行分析、清洗、过滤,最后将清洗好的日志转发至 Elasticsearch 集群中。
第四层,数据持久化存储:Elasticsearch 集群在接收到 Logstash 发送过来的数据后,执行写磁盘、建索引库等操作,最后将结构化的数据存储到 Elasticsearch 集群上。
第五层,数据查询、展示层:Kibana 是一个可视化的数据展示平台,当有数据检索请求时,它从 Elasticsearch 集群上读取数据,然后进行可视化出图和多维度分析。
ClickHouse方案
ClickHouse 是一款常用于大数据分析的 DBMS,因为其压缩存储,高性能,丰富的函数等特性,近期有很多尝试 ClickHouse 做日志系统的案例。本文将分享如何用 ClickHouse 做出通用日志系统。
可以解决的问题:
大数据量。对开发者来说日志最方便的观测手段,而且很多情况下会直接打印 HTTP、RPC 的请求响应日志,这基本上就是把网络流量复制了一份。
非固定检索模式。用户有可能使用日志中的任意关键字任意字段来查询。
成本要低。日志系统不宜在 IT 成本中占比过高。
即席查询。日志对时效性要求普遍较高。
数据量大,检索模式不固定,既要快,还得便宜。所以日志是一道难解的题,它的需求几乎违反了计算机的基本原则,不过幸好它还留了一扇窗,就是对并发要求不高。大部分查询是人为即兴的,即使做一些定时查询,所检索的范围也一定有限。
Fluent bit:目前社区日志采集和处理的组件不少,之前elk方案中的logstash,cncf社区中的fluentd,efk方案中的filebeat,以及大数据用到比较多的flume。而Fluent Bit是一款用c语言编写的高性能的日志收集组件,整个架构源于fluentd。官方比较数据如下:
日志系统主要分为四个部分:日志采集、日志传输、日志存储、日志管理。
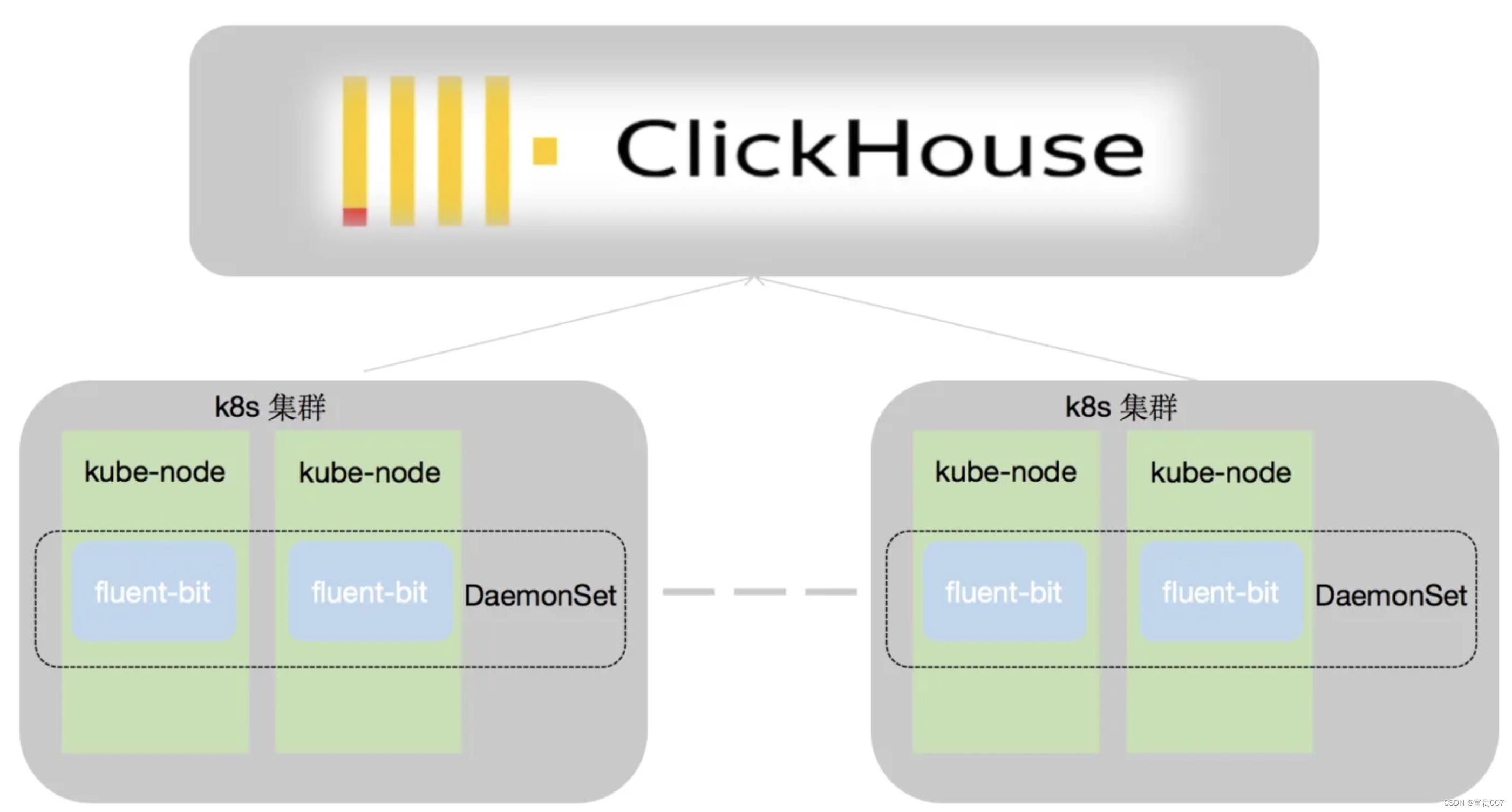
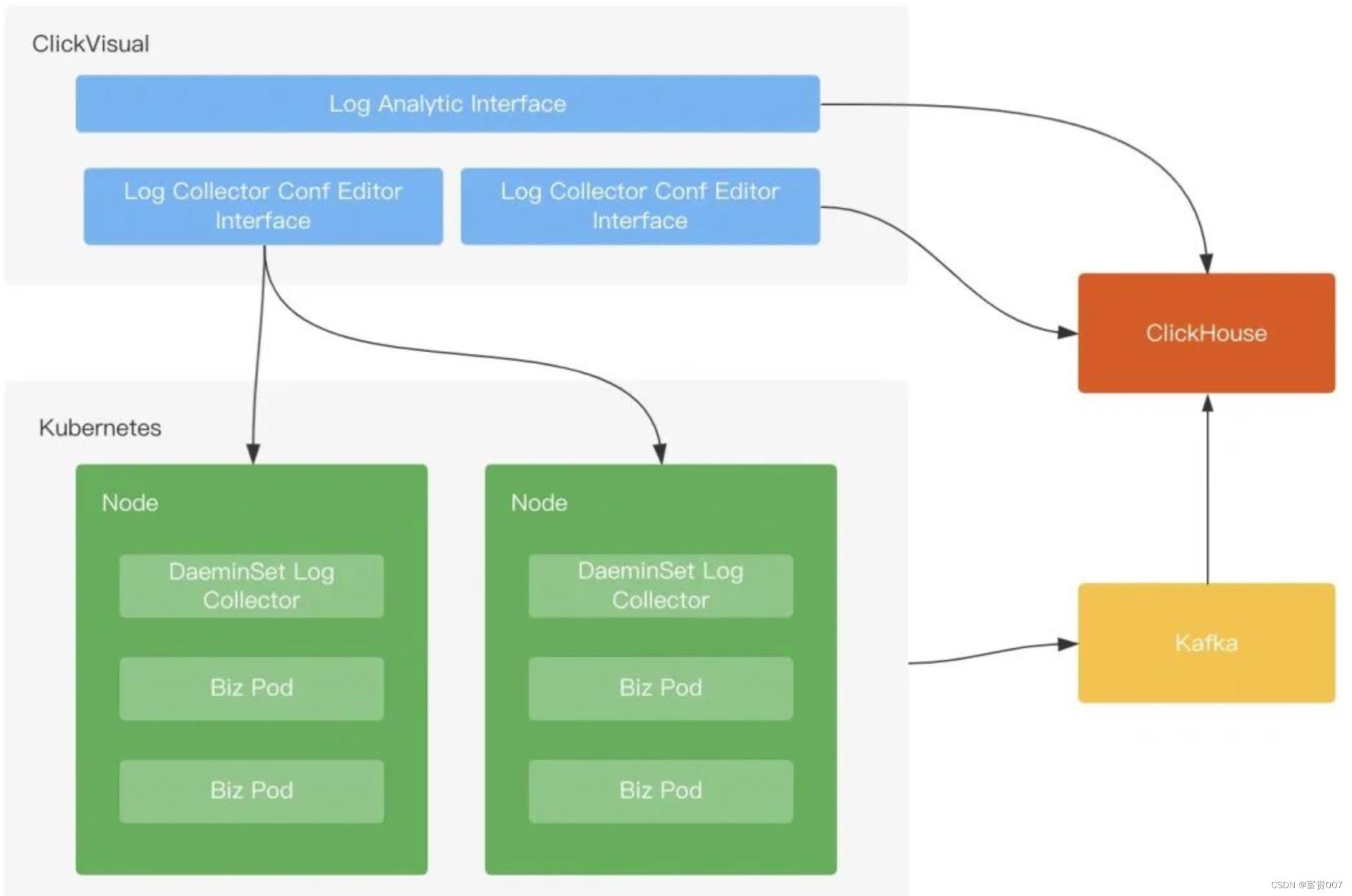
● 日志采集:LogCollector 采用 Daemonset 方式部署,将宿主机日志目录挂载到 LogCollector 的容器内,LogCollector 通过挂载的目录能够采集到应用日志、系统日志、K8S 审计日志等
● 日志传输:通过不同 Logstore 映射到 Kafka 中不同的 Topic,将不同数据结构的日志做了分离
● 日志存储:使用 Clickhouse 中的两种引擎数据表和物化视图
● 日志管理:开源的 ClickVisual 系统,能够查询日志,设置日志索引,设置 LogCollector 配置,设置 Clickhouse 表,设置报警等
B站架构
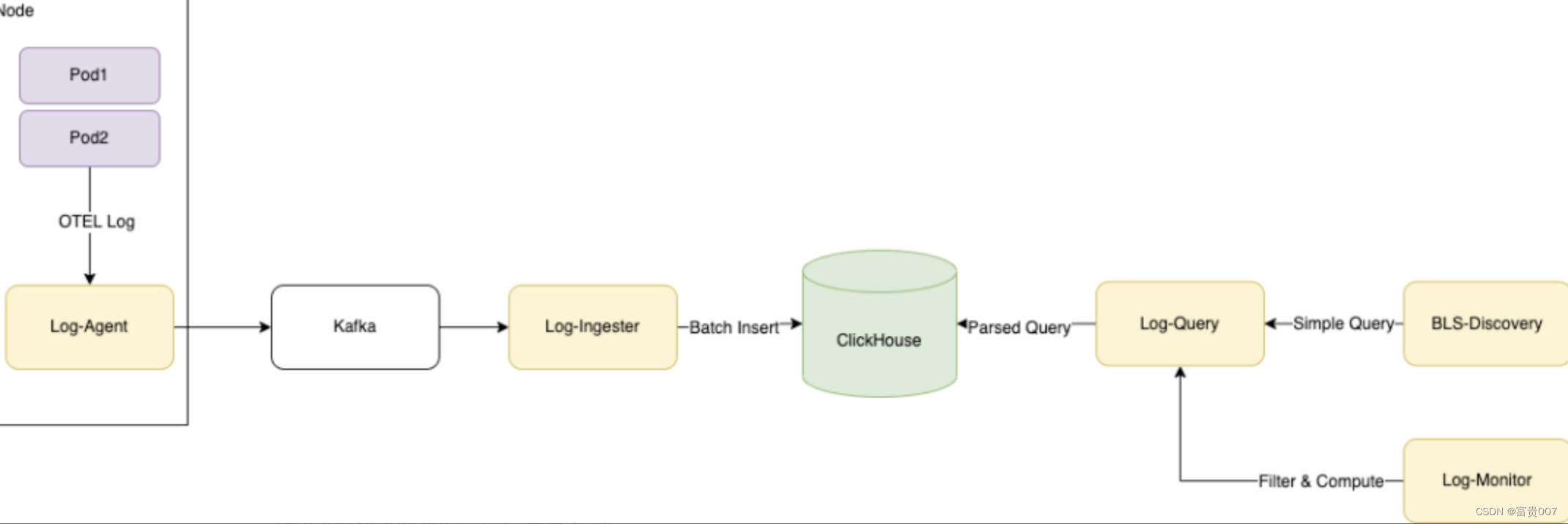
如图所示为日志实时上报和使用的全链路。使用ClickHouse作为存储,实现了自研的日志可视化分析平台,并使用OpenTelemetry作为统一日志上报协议。日志从产生到消费会经过采集→摄入 →存储 →分析四个步骤,分别对应我们在链路上的各个组件,先做个简单的介绍:
● OTEL Logging SDK完整实现OTEL Logging日志模型规范和协议的结构化日志高性能SDK,提供了Golang和Java两个主要语言实现。
● Log-Agent
日志采集器,以Agent部署方式部署在物理机上,通过Domain Socket接收OTEL协议日志,同时进行低延迟文件日志采集,包括容器环境下的采集。支持多种Format和一定的加工能力,如解析和切分等。
● Log-Ingester
负责从日志 kafka 订阅日志数据, 然后将日志数据按时间维度和元数据维度(如AppID) 拆分,并进行多队列聚合, 分别攒批写入ClickHouse中.
● ClickHouse
我们使用的日志存储方案,在ClickHouse高压缩率列式存储的基础上,配合隐式列实现了动态Schema以获得更强大的查询性能,在结构化日志场景如猛虎添翼。
● Log-Query
日志查询模块,负责对日志查询进行路由、负载均衡、缓存和限流,以及提供查询语法简化。
● BLS-Discovery
新一代日志的可视化分析平台,提供一站式的日志检索、查询和分析,追求日志场景的高易用性,让每个研发0学习成本无障碍使用。
结合湖仓一体
在湖仓一体日益成熟的背景下,日志入湖会带来以下收益:
● 部分日志有着三年以上的存储时间要求,比如合规要求的审计日志,关键业务日志等,数据湖的低成本存储特性是这个场景的不二之选。
● 现在日志除了用来进行研发排障外,也有大量的业务价值蕴含其中。日志入湖后可以结合湖上的生态体系,快速结合如机器学习、BI分析、报表等功能,将日志的价值发挥到最大。
此外,我们长远期探索减少日志上报的中间环节,如从agent直接到ClickHouse,去掉中间的Kafka,以及更深度的结合ClickHouse和湖仓一体,打通ClickHouse和iceberg。
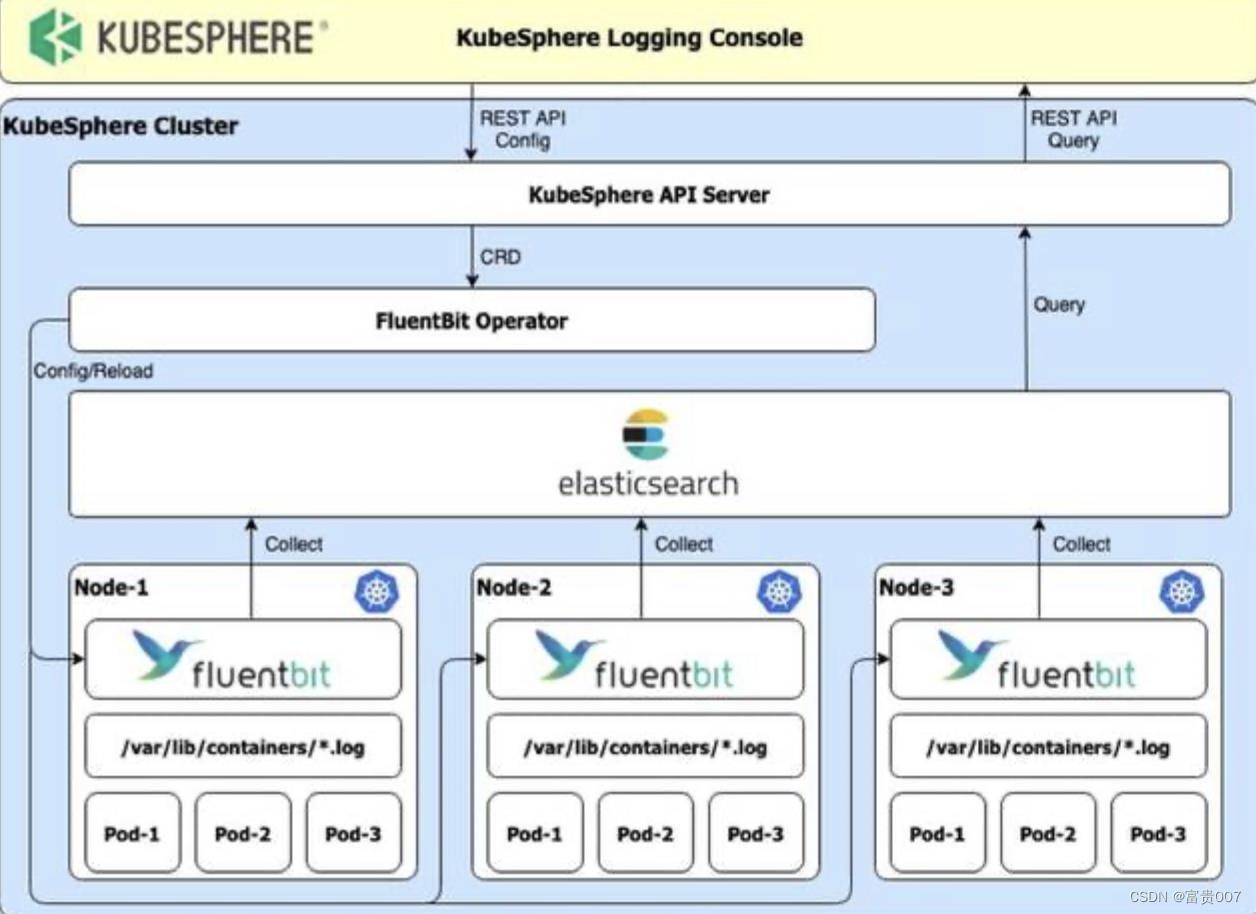
Kubesphere方案
在 KubeSphere 中,选择 Elasticsearch 作为日志后端服务,使用 Fluent Bit 作为日志采集器,KubeSphere 日志控制台通过 FluentBit Operator 控制 FluentBit CRD 中的 Fluent Bit 配置。(用户也可以通过 kubectl edit fluentbit fluent-bit 以 kubernetes 原生的方式来更改 FluentBit 的配置)
通过 FluentBit Operator,KubeSphere 实现了通过控制台灵活的添加/删除/暂停/配置日志接收者。
以上是关于日志与可视化方案:从ELK到EFK,再到ClickHouse的主要内容,如果未能解决你的问题,请参考以下文章