深度学习基础一文读懂卷积神经网络(Convolutional Neural Networks, CNN)
Posted 非晚非晚
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习基础一文读懂卷积神经网络(Convolutional Neural Networks, CNN)相关的知识,希望对你有一定的参考价值。
文章目录
1. 基本概念
- 历史简单介绍
CNN从90年代的LeNet开始,21世纪初沉寂了10年。直到2012年Geoffrey和他学生Alex在ImageNet的竞赛中,刷新了image classification的记录,一举奠定了deep learning 在计算机视觉中的地位。这次竞赛中Alex所用的结构就被称为作为AlexNet,AlexNet使用的就是CNN。
之后从ZF Net到VGG,GoogLeNet再到ResNet和DenseNet,网络越来越深,架构越来越复杂,解决反向传播时梯度消失的方法也越来越巧妙。
- 全连接神经网络与CNN
全连接神经网络(Fully connected neural network)处理图像最大的问题在于全连接层的参数太多。参数增多除了导致计算速度减慢,还很容易导致过拟合问题。所以需要一个更合理的神经网络结构来有效地减少神经网络中参数的数目,而卷积神经网络(Convolutional Neural Network,CNN)就可以做到这一点。
这里简单介绍一下卷积神经网络之父Yann LeCun,他出生在法国,曾在多伦多大学跟随深度学习鼻祖 Geoffrey Hinton 进行博士后研究。担任Facebook首席人工智能科学家和纽约大学教授,2018年图灵奖(Turing Award)得主。早在 20 世纪 80 年代末,Yann LeCun 就作为贝尔实验室的研究员提出了卷积网络技术,并展示如何使用它来大幅度提高手写识别能力。
ACM(国际计算机学会)宣布,有“深度学习三巨头”之称的Yoshua Bengio、Yann LeCun、Geoffrey Hinton共同获得了2018年的图灵奖,这是图灵奖1966年建立以来少有的一年颁奖给三位获奖者。
卷积神经网络与普通神经网络的区别在于,卷积神经网络包含了一个由卷积层和子采样层构成的特征抽取器。卷积和子采样大大简化了模型复杂度,减少了模型的参数。
- 卷积层:在卷积神经网络的卷积层中,
一个神经元只与部分邻层神经元连接。在CNN的一个卷积层中,通常包含若干个特征平面(feature Map),每个特征平面由一些矩形排列的的神经元组成,同一特征平面的神经元共享权值,这里共享的权值就是卷积核。卷积核一般以随机小数矩阵的形式初始化,在网络的训练过程中卷积核将学习得到合理的权值。共享权值(卷积核)带来的直接好处是减少网络各层之间的连接,同时又降低了过拟合的风险。子采样也叫做池化(pooling),通常有均值子采样(mean pooling)和最大值子采样(max pooling)两种形式。子采样可以看作一种特殊的卷积过程。
2. 卷积神经网络的结构
这里放一张李宏毅老师ppt中的一张图:

卷积神经网络的层级结构为:
- 输入层(input):用于数据的输入;
- 卷积层(convolution):使用卷积核进行特征提取和特征映射;
- 激励层:由于
卷积也是一种线性运算,因此需要增加非线性映射,通常为 ReLU layer;- 池化层(Max Pooling):进行下采样,对特征图稀疏处理,减少数据运算量;
- 全连接层(Fully-connexted):通常在CNN的尾部进行重新拟合,减少特征信息的损失;
- 输出层(output):用于输出结果;
当然中间还可以使用一些其他的功能层:
- 归一化层(Batch Normalization):在CNN中对特征的归一化
- 切分层:对某些(图片)数据的进行分区域的单独学习
- 融合层:对独立进行特征学习的分支进行融合
2.1 输入层
深度卷积网络可直接将图片作为网络的输入,通过训练提取特征,但是为了获得更好的效果,通常需要将图片进行预处理,在人脸识别中,就需要进行人脸检测等处理(MTCNN是一种较好的人脸检测方法)。此外,在样本不足的情况下会需要进行样本增强处理,包括旋转、平移,剪切、增加噪声、颜色变换等。
一些常见的操作说明:
- 去均值:把输入数据各个维度都中心化为0。
- 归一化:幅度归一化到同样的范围。比如,我们有两个维度的特征A和B,A范围是0到10,而B范围是0到10000,如果直接使用这两个特征是有问题的,好的做法就是归一化,
即A和B的数据都变为0到1的范围。
2.2 卷积层
这一层就是卷积神经网络最重要的一个层次,它产生了网络中大部分的计算量(不是参数量),也是“卷积神经网络”的名字来源。卷积层的功能是对输入数据进行特征提取,其内部包含多个卷积核,组成卷积核的每个元素都对应一个权重系数和一个偏差量(bias vector),类似于一个前馈神经网络的神经元(neuron)。
- 卷积过程是使用一个卷积核,在每层像素矩阵上不断按步长扫描下去,每次扫到的数值会和卷积核中对应位置的数进行相乘,然后相加求和,得到的值将会生成一个新的矩阵(
激活映射(activation map)或特征映射(feature map))。 - 卷积核相当于卷积操作中的一个过滤器,用于提取我们图像的特征,特征提取完后会得到一个特征图(feature map)。
- 卷积核的大小一般选择3x3和5x5,比较常用的是3x3,训练效果会更好。卷积核里面的每个值就是我们需要训练模型过程中的神经元参数(权重),开始会有随机的初始值,当训练网络时,网络会通过后向传播不断更新这些参数值,知道寻找到最佳的参数值。对于如何判断参数值的最佳,则是通过loss损失函数来评估。

再来看一张动态图来加深对卷积计算的理解:

引用一段知乎上机器之心给的一段通俗易懂的解释:
CNN 的第一层通常是卷积层(Convolutional Layer)。首先需要了解卷积层的输入内容是什么。假如,输入内容为一个 32 x 32 x 3 的像素值数组。现在,解释卷积层的最佳方法是想象有一束手电筒光正从图像的左上角照过。假设手电筒光可以覆盖 5 x 5 的区域,想象一下手电筒光照过输入图像的所有区域。在机器学习术语中,这束手电筒被叫做过滤器(filter,有时候也被称为神经元(neuron)或核(kernel)),被照过的区域被称为感受野(receptive field)。过滤器同样也是一个数组(其中的数字被称作权重或参数)。重点在于过滤器的深度必须与输入内容的深度相同(这样才能确保可以进行数学运算),因此过滤器大小为 5 x 5 x 3。现在,以过滤器所处在的第一个位置为例,即图像的左上角。当筛选值在图像上滑动(卷积运算)时,过滤器中的值会与图像中的原始像素值相乘(又称为计算点积)。这些乘积被加在一起(从数学上来说,一共会有 75 个乘积)。现在你得到了一个数字。切记,该数字只是表示过滤器位于图片左上角的情况。我们在输入内容上的每一位置重复该过程。(下一步将是将过滤器右移 1 单元,接着再右移 1 单元,以此类推。)输入内容上的每一特定位置都会产生一个数字。过滤器滑过所有位置后将得到一个 28 x 28 x 1 的数组,我们称之为激活映射(activation map)或特征映射(feature map)。之所以得到一个 28 x 28 的数组的原因在于,在一张 32 x 32 的输入图像上,5 x 5 的过滤器能够覆盖到 784 个不同的位置。这 784 个位置可映射为一个 28 x 28 的数组。
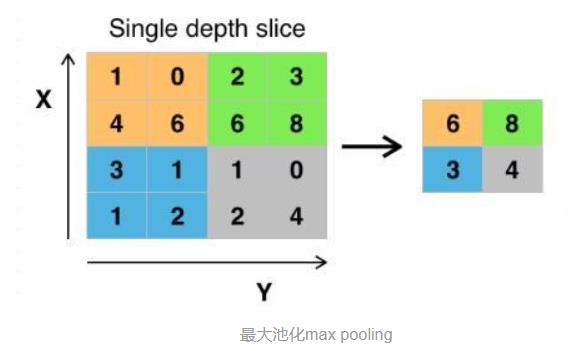
2.3 池化层
- 池化操作相当于
降维操作,有最大池化和平均池化,其中最大池化(max pooling)最为常用。 - 经过卷积操作后我们提取到的特征信息,相邻区域会有相似特征信息,这是可以相互替代的,如果全部保留这些特征信息会存在信息冗余,增加计算难度。
- 通过池化层会不断地减小数据的空间大小,参数的数量和计算量会有相应的下降,
这在一定程度上控制了过拟合。
2.4 全连接层
对n-1层和n层而言,n-1层的任意一个节点,都和第n层所有节点有连接。即第n层的每个节点在进行计算的时候,激活函数的输入是n-1层所有节点的加权。
全连接层在整个网络卷积神经网络中起到“分类器”的作用。如果说卷积层、池化层和激活函数等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的特征表示(feature map)映射到样本的标记空间的作用。
简单地说,这一层处理输入内容(该输入可能是卷积层、ReLU 层或是池化层的输出)后会输出一个 N 维向量,N 是该程序必须选择的分类数量。例如,如果你想得到一个数字分类程序,如果有 10 个数字,N 就等于 10。这个 N 维向量中的每一数字都代表某一特定类别的概率。例如,如果某一数字分类程序的结果矢量是 [0 .1 .1 .75 0 0 0 0 0 .05],则代表该图片有 10% 的概率是 1、10% 的概率是 2、75% 的概率是 3、还有 5% 的概率是 9(注:还有其他表现输出的方式,这里只展示了 softmax 的方法)。
2.5 卷积神经网络的其它概念
(1)感受野
在卷积神经网络中,感受野(Receptive Field)的定义是卷积神经网络每一层输出的特征图(feature map)上的像素点在输入图片上映射的区域大小。再通俗点的解释是,特征图上的一个点对应输入图上的区域。注意这里是输入图,不是原始图。

在处理图像这样的高维度输入时,让每个神经元都与前一层中的所有神经元进行全连接是不现实的。相反,我们让每个神经元只与输入数据的一个局部区域连接。该连接的空间大小叫做神经元的感受野(receptive field),它的尺寸是一个超参数(其实就是滤波器的空间尺寸)。在深度方向上,这个连接的大小总是和输入量的深度相等。
我们对待空间维度(宽和高)与深度维度是不同的:连接在空间(宽高)上是局部的,但是在深度上总是和输入数据的深度一致。
(2)padding
padding,顾名思义,就是在图像周围进行填充,常用 zero padding,即用 0 来填充。当 P=1 时,在图像周围填充一圈;当 P=2 时,填充两圈。
padding的原因:
- 在进行卷积操作的过程中,处于
中间位置的数值容易被进行多次的提取,但是边界数值的特征提取次数相对较少,为了能更好的把边界数值也利用上,所以给原始数据矩阵的四周都补上一层0,这就是padding操作。- 在进行卷积操作之后维度会变少,
得到的矩阵比原矩阵要小,不方便计算,原矩阵加上一层0的padding操作可以很好的解决该问题,卷积出来的矩阵和原矩阵尺寸一致。
(3)stride
stride是滤波器扫描时的步长。stride=1时,计算卷积输出矩阵不同位置的值是将滤波器矩阵(右或下)移动一格。stride=2时,计算卷积输出矩阵不同位置的值是将滤波器矩阵(右或下)移动2格。
(4)Flatten
Flatten将池化后的数据拉开,变成一维向量来表示,一般用在卷积层与全链接层之间,方便输入到全连接网络。也就是把 (height,width,channel)的数据压缩成长度为 height × width × channel 的一维数组,然后再与 FC层连接,这之后就跟普通的神经网络无异了。
(5)Dropout
在训练过程中,按照一定的比例将网络中的神经元进行丢弃,可以防止模型训练过拟合的情况。
在训练的时候,传统的训练方法是每次迭代经过某一层时,将所有的结点拿来做参与更新,训练整个网络。加入dropout层,我们只需要按一定的概率(retaining probability)p 来对weight layer 的参数进行随机采样,将被采样的结点拿来参与更新,将这个子网络作为此次更新的目标网络。这样做的好处是,由于随机的让一些节点不工作了,因此可以避免某些特征只在固定组合下才生效,有意识地让网络去学习一些普遍的共性(而不是某些训练样本的一些特性)这样能提高训练出的模型的鲁棒性。
- Dropout只发生在模型的训练阶段,
预测、测试阶段则不用Dropout。- 直观认识:Dropout随机删除神经元后,网络变得更小,训练阶段也会提速。
- 事实证明,dropout已经被正式地作为一种正则化的替代形式。
- 有了dropout,网络不会为任何一个特征加上很高的权重(因为那个特征的输入神经元有可能被随机删除),最终dropout产生了收缩权重平方范数的效果。
- Dropout的功能类似于L2正则化,但Dropout更适用于不同的输入范围。
- 如果你担心某些层比其它层更容易过拟合,可以把这些层的keep-prob值设置的比其它层更低。
- Dropout主要用在计算机视觉领域,
因为这个领域我们通常没有足够的数据,容易过拟合,但在其它领域用的比较少。Dropout的一大缺点就是代价函数不再被明确定义,所以在训练过程中,代价函数的值并不是单调递减的。
3. 卷积神经网络之优缺点
- 优点
- 共享卷积核,对高维数据处理无压力
- 无需手动选取特征,训练好权重,即得特征分类效果好
- 缺点
- 需要调参,需要大样本量,训练最好要GPU
- 物理含义不明确(也就说,
我们并不知道每个卷积层到底提取到的是什么特征,而且神经网络本身就是一种难以解释的“黑箱模型”)
参考:
https://www.zhihu.com/question/52668301
https://cloud.tencent.com/developer/article/1020738
以上是关于深度学习基础一文读懂卷积神经网络(Convolutional Neural Networks, CNN)的主要内容,如果未能解决你的问题,请参考以下文章