一文读懂生成式对抗网络模型
Posted 图灵人工智能
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文读懂生成式对抗网络模型相关的知识,希望对你有一定的参考价值。
摘要
生成式对抗网络模型(GAN)是基于深度学习的一种强大的生成模型,可以应用于计算机视觉、自然语言处理、半监督学习等重要领域。生成式对抗网络最最直接的应用是数据的生成,而数据质量的好坏则是评判GAN成功与否的关键。本文介绍了GAN最初被提出时的基本思想,阐述了其一步步演化、改进的动机和基本思想以及原理,从基于模型改进的角度介绍了WGAN,WGAN-GP,LSGAN,f-GAN,LS-GAN以及GLS-GAN,EBGAN,BEGAN等GAN发展过程中较为重要的改进模型,以及从应用创新角度介绍了CGAN,InfoGAN,Pix2Pix,CycleGAN,StarGAN等较为常用或热门的GAN的应用方法。此外,本文还介绍了GAN的几种应用,包括图像翻译,语言翻译以及基于GAN的辅助驾驶等。最后本文还介绍了GAN的主要发展和研究方向,提出了GAN现在以及将来发展的热点与难点等,如如何提高图片的质量,避免模式崩塌等。
深度学习 生成式对抗网络 卷积神经网络 Wasserstein距离 对抗训练
deep learning, generate adversial network, convolutionalneural network, Wasserstein Distance, adversial training
引言
近年来,人工智能与深度学习已经成为耳熟能详的名词。一般而言,深度学习模型可以分为判别式模型与生成式模型。由于反向传播(Back propagation, BP)、Dropout等算法的发明,判别式模型得到了迅速发展。然而,由于生成式模型建模较为困难,因此发展缓慢,直到近年来最成功的生成模型——生成式对抗网络的发明,这一领域才焕发新的生机。
生成式对抗网络(Generative adversarial network, GAN)自Ian Goodfellow[1]等人提出后,就越来越受到学术界和工业界的重视。而随着GAN在理论与模型上的高速发展,它在计算机视觉、自然语言处理、人机交互等领域有着越来越深入的应用,并不断向着其它领域继续延伸。因此,本文将对GAN的理论与其应用做一个总结与介绍。
GAN的基本思想
GAN受博弈论中的零和博弈启发,将生成问题视作判别器和生成器这两个网络的对抗和博弈:生成器从给定噪声中(一般是指均匀分布或者正态分布)产生合成数据,判别器分辨生成器的的输出和真实数据。前者试图产生更接近真实的数据,相应地,后者试图更完美地分辨真实数据与生成数据。由此,两个网络在对抗中进步,在进步后继续对抗,由生成式网络得的数据也就越来越完美,逼近真实数据,从而可以生成想要得到的数据(图片、序列、视频等)。
如果将真实数据和生成数据服从两个分布,那么如图所示
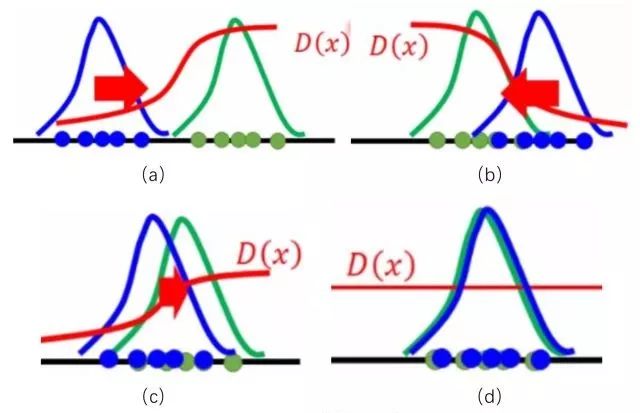 图1 GAN的基本思想
图1 GAN的基本思想
蓝色分布为生成分布,绿色分布为真实分布,D为判别器,GAN从概率分布的角度来看,就是通过D来将生成分布推向真实分布,紧接着再优化D,直至到达图1(d)所示,到达Nash均衡点,从而生成分布与真实分布重叠,生成极为接近真实分布的数据。
GAN的基本模型
设z为随机噪声,x为真实数据,生成式网络和判别式网络可以分别用G和D表示,其中D可以看作一个二分类器,那么采用交叉熵表示,可以写作:
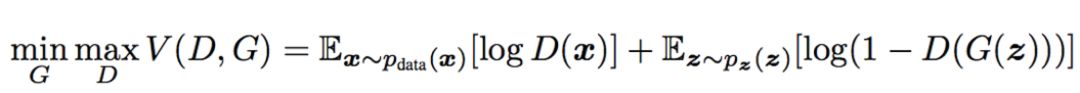
其中第一项的logD(x)表示判别器对真实数据的判断,第二项log(1 − D(G(z)))表示则对数据的合成与判断。通过这样一个极大极小(Max-min)博弈,循环交替地分别优化G和D来训练所需要的生成式网络与判别式网络,直到到达Nash均衡点。
GAN与Jensen-Shannon散度
对于原目标函数,在生成器G固定参数时,可以得到最优的判别器D。对于一个具体的样本,它可能来自真实分布也可能来自生成分布,因此它对判别器损失函数的贡献是:
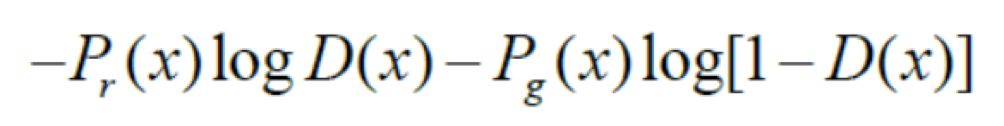
其中pr为真实分布,pg为生成分布。令上式关于D(x)的导数为0,可以得到D(x)的全局最优解为:
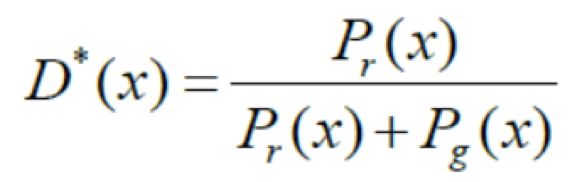
对于gan 的生成器的优化函数可以写成:
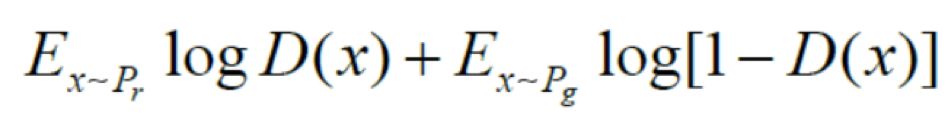
将最优判别器代入,可以得到生成器的优化函数为:
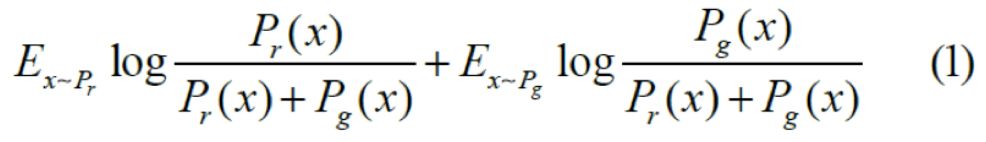
此处简单回顾一下JS散度与KL散度:
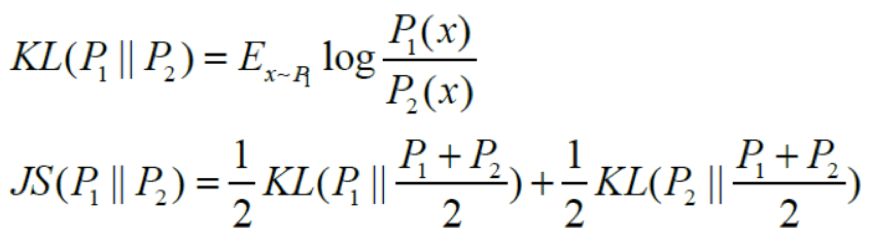
显然,(1)式与JS散度形式相似,可以转换成:
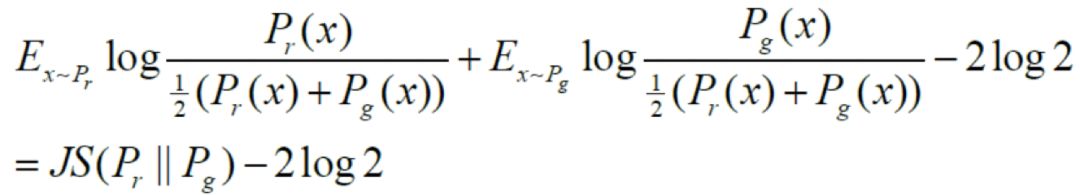
综上,可以认为,当判别器过优时,生成器的loss可以近似等价于优化真实分布与生成器产生数据分布的JS散度。
生成器与判别器的网络
Ian在2014年提出的朴素GAN在生成器和判别器在结构上是通过以多层全连接网络为主体的多层感知机(Multi-layer Perceptron, MLP) 实现的,然而其调参难度较大,训练失败相当常见,生成图片质量也相当不佳,尤其是对较复杂的数据集而言。
由于卷积神经网络(Convolutional neural network, CNN)比MLP有更强的拟合与表达能力,并在判别式模型中取得了很大的成果。因此,Alec等人[2]将CNN引入生成器和判别器,称作深度卷积对抗神经网络(Deep Convolutional GAN, DCGAN)。图2为DCGAN生成器结构图。本质上,DCGAN是在GAN的基础上提出了一种训练架构,并对其做了训练指导,比如几乎完全用卷积层取代了全连接层,去掉池化层,采用批标准化(Batch Normalization, BN)等技术,将判别模型的发展成果引入到了生成模型中。此外,[2]还并强调了隐藏层分析和可视化计数对GAN训练的重要性和指导作用。
DCGAN虽然没有带来理论上以及GAN上的解释性,但是其强大的图片生成效果吸引了更多的研究者关注GAN,证明了其可行性并提供了经验,给后来的研究者提供了神经网络结构的参考。此外,DCGAN的网络结构也可以作为基础架构,用以评价不同目标函数的GAN,让不同的GAN得以进行优劣比较。DCGAN的出现极大增强了GAN的数据生成质量。而如何提高生成数据的质量(如生成图片的质量)也是如今GAN研究的热门话题。
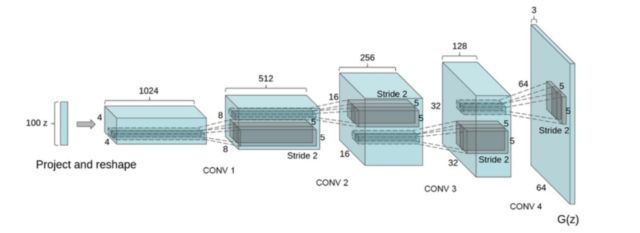 图2 DCGAN生成器网络结构图
图2 DCGAN生成器网络结构图
GAN的模型改进
然而,GAN自从2014年提出以来,就存在着训练困难、不易收敛、生成器和判别器的loss无法指示训练进程、生成样本缺乏多样性等问题。从那时起,很多研究人员就在尝试解决,并提出了改进方案,切实解决了部分问题,如生成器梯度消失导致的训练困难。当然也还有很多问题亟待解决,如生成样本的评价指标问题。本文将简单阐述几个较为突出的的改进措施。
WGAN
与前文的DCGAN不同,WGAN(Wasserstein GAN)并不是从判别器与生成器的网络构架上去进行改进,而是从目标函数的角度出发来提高模型的表现[3]。Martin Arjovsky等人先阐述了朴素GAN因生成器梯度消失而训练失败的原因[4]:他们认为,朴素GAN的目标函数在本质上可以等价于优化真实分布与生成分布的Jensen-Shannon散度。而根据Jensen-Shannon散度的特性,当两个分布间互不重叠时,其值会趋向于一个常数,这也就是梯度消失的原因。此外,Martin Arjovsky等人认为,当真实分布与生成分布是高维空间上的低维流形时,两者重叠部分的测度为0的概率为1,这也就是朴素GAN调参困难且训练容易失败的原因之一。
针对这种现象,Martin Arjovsky等人利用Wasserstein-1距离(又称Earth Mover距离)来替代朴素GAN所代表的Jensen-Shannon散度[3]。Wasserstein距离是从最优运输理论中的Kantorovich问题衍生而来的,可以如下定义真实分布与生成分布的Wasserstein-1距离:
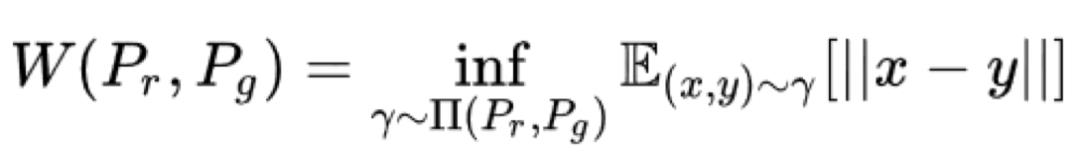
其中pr,pg分别为真实分布与生成分布,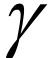 为pr,pg分的联合分布。相较于Jensen-Shannon散度,Wasserstein-1距离的优点在于,即使pr,pg互不重叠,Wasserstein距离依旧可以清楚地反应出两个分布的距离。为了与GAN相结合,将其转换成对偶形式:
为pr,pg分的联合分布。相较于Jensen-Shannon散度,Wasserstein-1距离的优点在于,即使pr,pg互不重叠,Wasserstein距离依旧可以清楚地反应出两个分布的距离。为了与GAN相结合,将其转换成对偶形式:
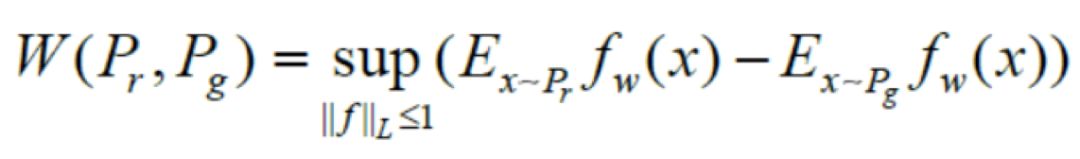
从表示GAN的角度理解,fw表示判别器,与之前的D不同的是,WGAN不再需要将判别器当作0-1分类将其值限定在[0,1]之间,fw越大,表示其越接近真实分布;反之,就越接近生成分布。此外,||f||L ≤ 1表示其Lipschitz常数为1。显然,Lipschitz连续在判别器上是难以约束的,为了更好地表达Lipschitz转化成权重剪枝,即要求参数w ∈ [−c, c],其中为常数。因而判别器的目标函数为:
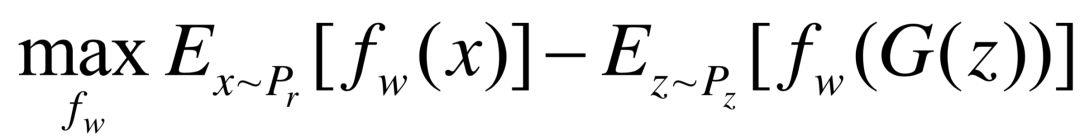
其中w ∈ [−c, c],生成器的损失函数为:
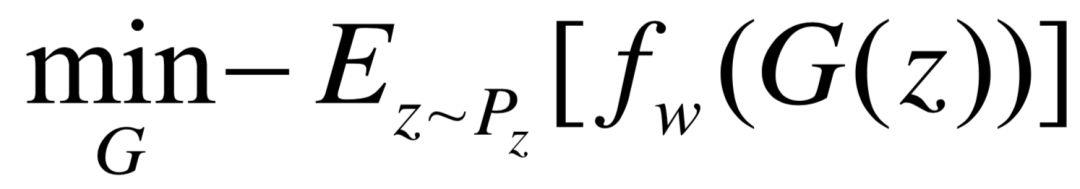
WGAN的贡献在于,从理论上阐述了因生成器梯度消失而导致训练不稳定的原因,并用Wasserstein距离替代了Jensen-Shannon散度,在理论上解决了梯度消失问题。此外,WGAN还从理论上给出了朴素GAN发生模式坍塌(mode collapse)的原因,并从实验角度说明了WGAN在这一点上的优越性。最后,针对生成分布与真实分布的距离和相关理论以及从Wasserstein距离推导而出的Lipschitz约束,也给了后来者更深层次的启发,如基于Lipschitz密度的 损失敏感GAN(loss sensitive GAN, LS-GAN)。
WGAN—GP
虽然WGAN在理论上解决了训练困难的问题,但它也有各种各样的缺点。在理论上,由于对函数(即判别器)存在Lipschitz-1约束,这个条件难以在神经网络模型中直接体现,所以作者使用了权重剪枝(clip) 来近似替代Lipschitz-1约束。显然在理论上,这两个条件并不等价,而且满足Lipschitz-1约束的情况多数不满足权重剪枝约束。而在实验上,很多人认为训练失败是由权重剪枝引起的,如图3。对此Ishaan Gulrajani提出了梯度带梯度惩罚的WGAN(WGAN with gradient penalty, WGAN-GP)[5],将Lipschitz-1约束正则化,通过把约束写成目标函数的惩罚项,以近似Lipschitz-1约束条件。
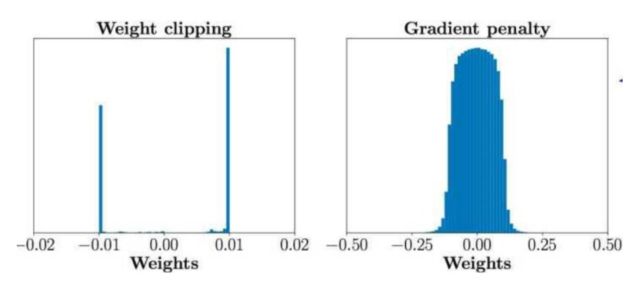 图3 WGAN与WGAN-GP的权重分布情况
图3 WGAN与WGAN-GP的权重分布情况
因而,WGAN的目标函数可以写作
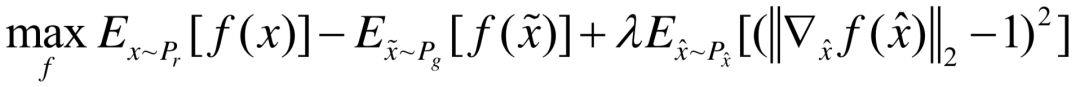
其中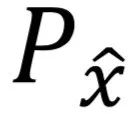 是pr与pg之间的线性采样,即满足
是pr与pg之间的线性采样,即满足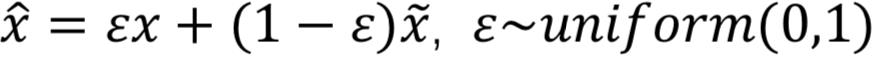 。此外,生成器的目标函数与WGAN相同,取第二项进行优化即可。
。此外,生成器的目标函数与WGAN相同,取第二项进行优化即可。
WGAN-GP的贡献在于,它用正则化的形式表达了对判别器的约束,也为后来GAN的正则化模型做了启示。此外WGAN-GP基本从理论和实验上解决了梯度消失的问题,并且具有强大的稳定性,几乎不需要调参,即在大多数网络框架下训练成功率极高。
LSGAN
虽然WGAN和WGAN-GP已经基本解决了训练失败的问题,但是无论是训练过程还是是收敛速度都要比常规 GAN 更慢。受WGAN理论的启发,Mao 等人提出了最小二乘GAN (least square GAN, LSGAN)[6]。LSGAN的一个出发点是提高图片质量。它的主要想法是为判别器D提供平滑且非饱和梯度的损失函数。这里的非饱和梯度针对的是朴素GAN的对数损失函数。显然,x越大,对数损失函数越平滑,即梯度越小,这就导致对判别为真实数据的生成数据几乎不会有任何提高。针对于此,LSGAN的判别器目标函数如下:
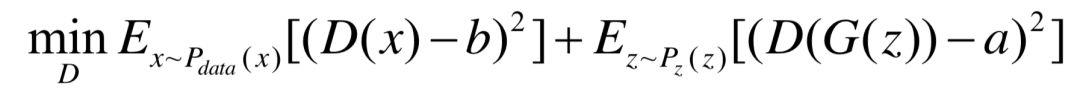
生成器的目标函数如下:
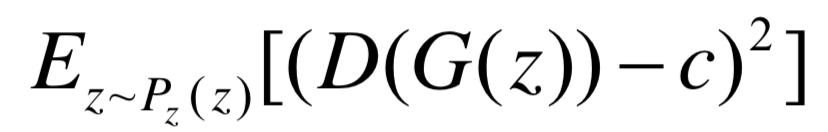
这里a, b, c满足b − c = 1和b − a = 2。根据[6],它等价于f散度中的散度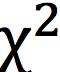 ,也即是说,LSGAN用散度取代了朴素GAN的Jensen-Shannon散度。
,也即是说,LSGAN用散度取代了朴素GAN的Jensen-Shannon散度。
最后,LSGAN的优越性在于,它缓解了GAN训练时的不稳定,提高了生成数据的质量和多样性,也为后面的泛化模型f-GAN提供了思路。
f-GAN
由于朴素GAN所代表的Jensen-Shannon散度和前文提到的LSGAN所代表的散度都属于散度的特例,那么自然而然地想到,其它f散度所代表的GAN是否能取得更好的效果。实际上,这些工作早已完成[7],时间更是早过WGAN与LSGAN。甚至可以认为,是f-GAN开始了借由不同散度来代替Jensen-Shannon散度,从而启示了研究者借由不同的距离或散度来衡量真实分布与生成分布。首先衡量p(x), q(x)的f散度可以表示成如下形式:
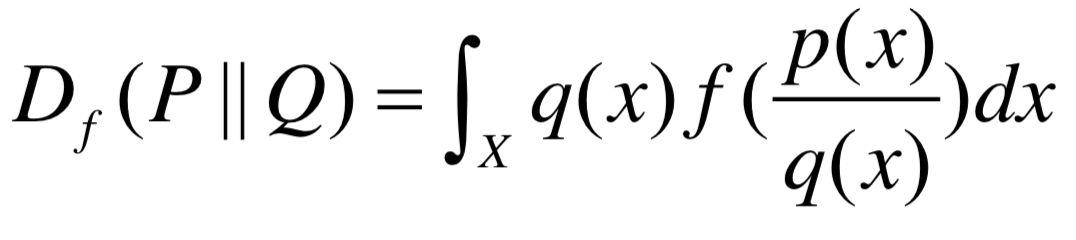
其中下半连续映射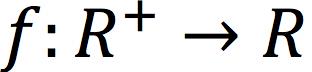 ,通过各种特定的函数f,可以得到不同的散度。其结果如表1所示:
,通过各种特定的函数f,可以得到不同的散度。其结果如表1所示:
 表1 f-GAN中基于不同散度的结果
表1 f-GAN中基于不同散度的结果
此外,f-GAN还可以得到如下的泛化模型,其目标函数如下:
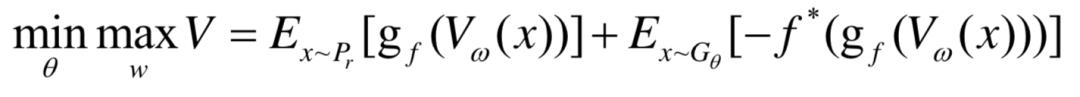
其中vw是判别器的输出函数,gf是最后一层的激活函数,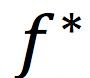 是f的共轭凸函数,以朴素GAN为例,当
是f的共轭凸函数,以朴素GAN为例,当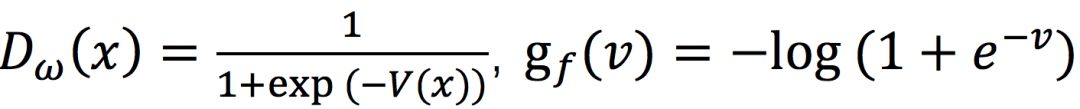 ,时,上式即为朴素GAN的目标函数。
,时,上式即为朴素GAN的目标函数。
LS-GAN(损失敏感GAN)与GLS-GAN
与前文提到的LSGAN (least square GAN)不同,这里的LS-GAN是指Loss-Sensitive GAN,即损失敏感GAN。一般认为,GAN可以分为生成器G和判别器D。与之不同的是,针对判别器D,LS-GAN想要学习的是损失函数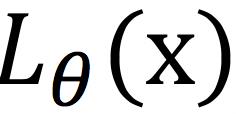 ,要求在真实样本上尽可能小,在生成样本上尽可能大。由此,LS-GAN基于损失函数的目标函数为:
,要求在真实样本上尽可能小,在生成样本上尽可能大。由此,LS-GAN基于损失函数的目标函数为:
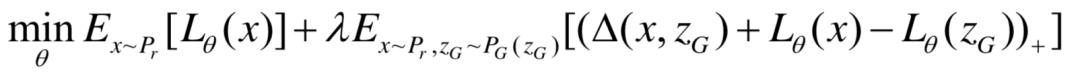
生成器的目标函数为:
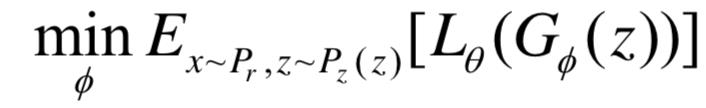
此处∆(x, zG )是来自约束假设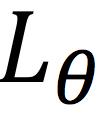 (x) ≤ ( zG) − ∆(x, zG),表示真实的样本要与生成样本间隔∆(x,zG)的长度,如此LS-GAN就可以将用于提高距离真实样本较远的样本上,可以更合理的发挥LS-GAN的建模能力。
(x) ≤ ( zG) − ∆(x, zG),表示真实的样本要与生成样本间隔∆(x,zG)的长度,如此LS-GAN就可以将用于提高距离真实样本较远的样本上,可以更合理的发挥LS-GAN的建模能力。
此外,为了证明LS-GAN的收敛性,还做了一个基本的假设:要求真实分布限定在Lipschitz 密度上,即真实分布的概率密度函数建立在紧集上,并且它是Lipschitz连续的。通俗地说,就是要求真实分布的概率密度函数不能变化的太快,概率密度的变化不能随着样本的变化而无限地增大。
最后,Qi等人还对LS-GAN做了推广,将其扩展为GLS-GAN(Generalized LS-GAN)。所谓的GLS-GAN,就是将损失函数的目标函数扩展为:
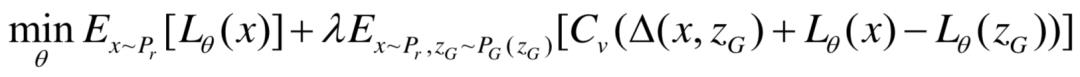
此处Cv (a) = max{a, va},其中v∈ [−∞, 1]。可以证明,当v = 0时,GLS-GAN就是前文的LS-GAN。另外,当v = 1时,可以证明,GLS-GAN就是WGAN。所以,Qi认为,LS-GAN与WGAN都是GLS-GAN的一种特例。
EBGAN
朴素GAN提出将二分类器作为判别器以判别真实数据和生成数据,并将生成数据“拉向”生成数据。然而自从WGAN抛弃了二分类器这个观点,取以函数fw代替,并不将之局限在[0,1]之后,很多改进模型也采取了类似的方法,并将之扩展开来。例如LS-GAN以损失函数(x)作为目标,要求(x)在真实样本上尽可能小,在生成样本尽可能大。
基于能量的GAN(Energy-based GAN, EBGAN)则将之具体化了。它将能量模型以及其相关理论引入GAN,以“能量”函数在概念上取代了二分类器,表示对真实数据赋予低能量,对生成数据赋予高能量。
首先,EBGAN给出了它的目标函数
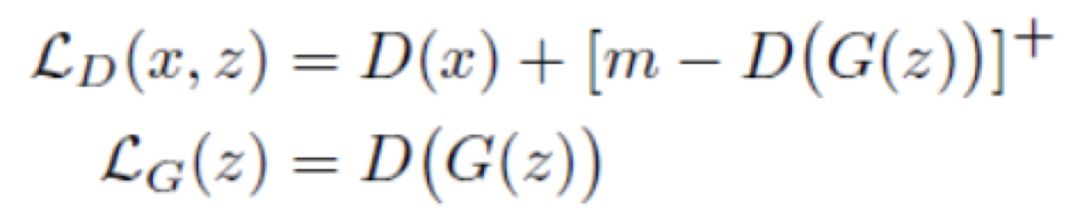
其中[∙]+ = max{0,∙},极大化LD的同时极小化LG。EBGAN的设计思想是,一方面减少真实数据的重构误差,另一方面,使得生成数据的重构误差趋近于m,即当D(G(z)) < m时,改下为正,对LD的极小化产生贡献,反之D(G(z)) ≥ m,LD为0,会通过极小化LG,将D(G(z))拉向m。可以证明,当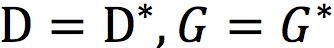 到达Nash均衡时,生成数据分布等于真实数据分布,并且此时LD的期望即
到达Nash均衡时,生成数据分布等于真实数据分布,并且此时LD的期望即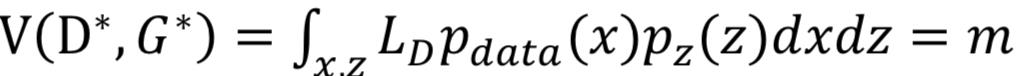 。
。
此外在EBGAN中,对D的结构也做了改进。不再采用DCGAN对D的网络框架或者其相似结构,EBGAN对D的架构采用自动编码器的模式,模型架构如图所示
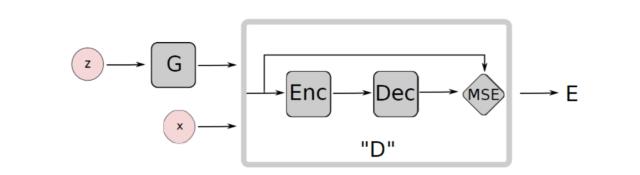 图4 EBGAN模型架构
图4 EBGAN模型架构
可以发现,其判别器或者说能量函数D可以写作
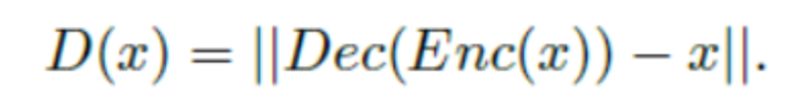
其中Enc,Dec是自编码器中的编码与解码操作。
最后,由于自编码器的特殊构造,EBGAN还针对LG做了特殊设计,即增加一个正则项fPT来避免模式崩溃(mode collapse)问题。设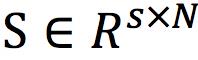 是一个batch的编码器(encoder)输出结果,fPT可以定义为
是一个batch的编码器(encoder)输出结果,fPT可以定义为
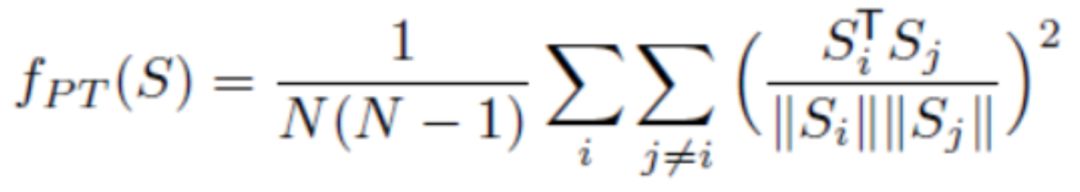
其思想很简单,利用一个批次的编码器输出结果计算余弦距离并求和取均值,若这一项越小,则两两向量越接近正交。从而解决模式崩溃问题,不会出现一样或者极其相似的图片数据。
BEGAN
以上的GAN在本质上的目标是让真实分布pr与生成分布pg尽量接近,大多数GAN之间可以解释成其区别在于衡量方式不同,比如朴素GAN的Jensen-Shannon散度,WGAN的Wasserstein距离,f-GANs的f散度等等。
特殊的是,边界平衡GAN(Boundary Equilibrium Generative Adversarial Networks, BEGAN)颠覆了这种思路,虽然它是基于WGAN与EBGAN上发展而来的。
首先,设D为判别函数,其结构采用上一节中EBGAN上的自编码器的模式,即
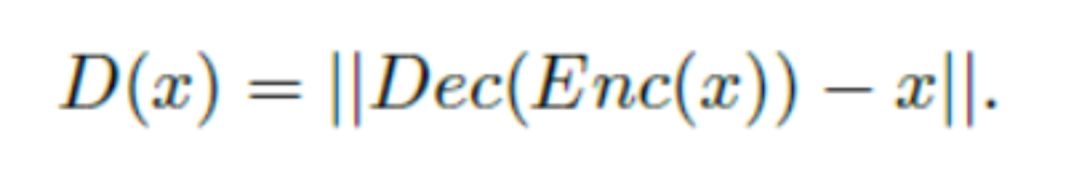
另外,设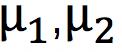 为D(x)与D(G(z))的分布,其中x即为输入的样本图片,G(z)为生成图片,那么真实分布pr与生成分布pg之间的Wasserstein距离如下
为D(x)与D(G(z))的分布,其中x即为输入的样本图片,G(z)为生成图片,那么真实分布pr与生成分布pg之间的Wasserstein距离如下
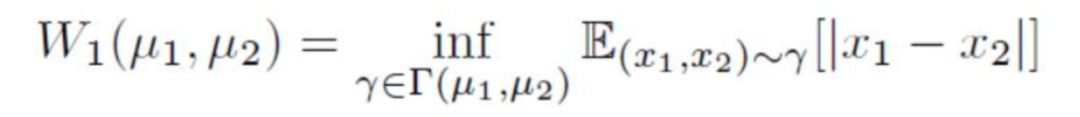
设m1,m2为的期望,根据Jensen不等式,有
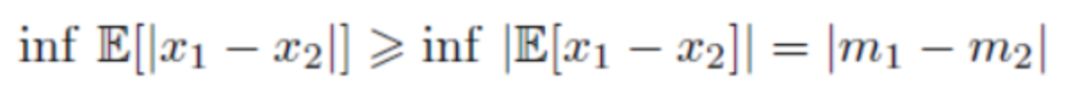
由此,BEGAN的特殊性在于,它优化的不是真实分布pr与生成分布pg之间的距离,而是样本图片和生成图片下的判别函数的分布之间的Wasserstein下界。
要计算Wasserstein下界,就要最大化|m1 − m2|,显然它至少有两个解,极大化m1,极小化m2或者极大化m2,极小化m1,此处取后一种,即可从优化
Wasserstein下界的角度看待GAN下的优化,即
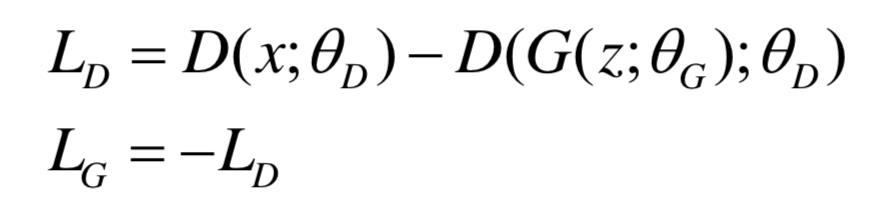
上式均取极小值,前者LD优化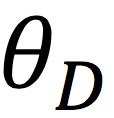 ,极大化m2,极小化m1,由此计算Wasserstein下界;后者LG优化
,极大化m2,极小化m1,由此计算Wasserstein下界;后者LG优化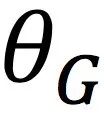 ,极小化m2,由此优化Wasserstein下界。
,极小化m2,由此优化Wasserstein下界。
当上述的GAN成功训练到达均衡点,显然有:
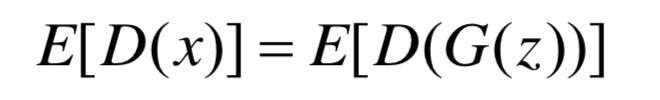
当真实分布pr与生成分布pg相等时,显然满足上式。但是在训练时,并不是两者完全重叠最佳,LS-GAN在设计时就有这种思想。同样,BEGAN在设计时选择通过超参∈ [0,1]来放宽均衡点
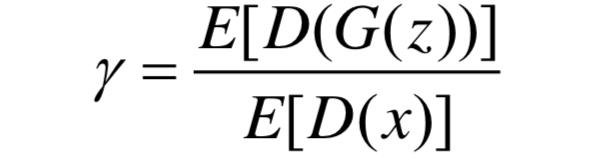
即生成样本判别损失的期望与真实样本判别损失的期望值之比。而此处之所以让判别器设计成自编码其的模式,是因为判别器有两个作用:1.对真实图片自编码;2. 区分生成图片与真实图片。超参的特殊之处在于,它能平衡这两个目标:值过低会导致图片多样性较差,因为判别器太过关注对真实图片自编码;反之,图片视觉质量则会不佳。
由此,可以BEGAN的目标函数如下
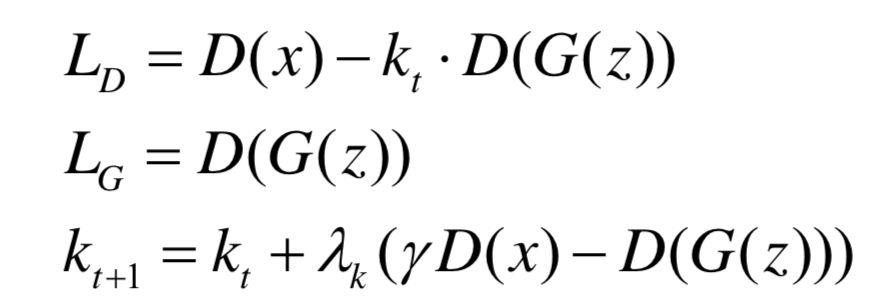
其中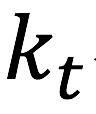 初始化为0,
初始化为0,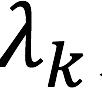 为学习率(learning rate)。
为学习率(learning rate)。
此外,BEGAN的另一个卓越效果是,它的网络结构极为简单,不需要ReLU,minbatch,Batch Normalization等非线性操作,但其图片质量远远超过与其结构相近的EBGAN。
改进模型的总结
前文除了DCGAN,其余的改进都是基于目标函数。如果不考虑InfoGAN,CGAN和Auto-GAN等当下流行的GAN模型,可以将针对目标函数的改进分为两种,正则化与非正则化。如图所示:
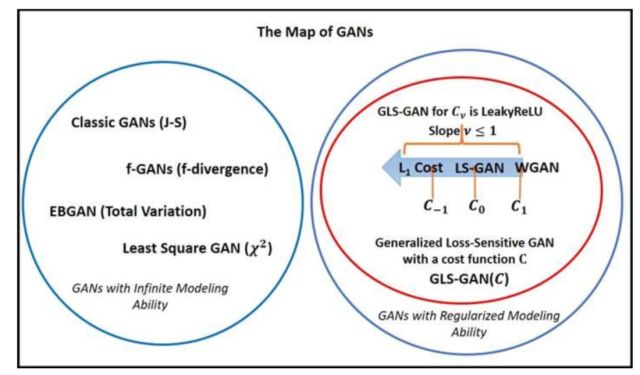 图5 基于loss改进的GAN的分类
图5 基于loss改进的GAN的分类
一般认为,到目前为止,GLS-GAN有更好的建模能力。而GLS-GAN的两种特例LS-GAN和WGAN都是建立在Lipschitz连续函数空间中进行训练。而对判别器或损失函数而言,至今也尚未发现比Lipschitz约束更好的限制判别能力的条件,这也可能是今后研究的难点。
GAN的应用模型改进
以上对GAN的改进可以说是对GAN基础的改进。然而基础的GAN有时在实际中是不足以满足我们对生成数据的要求。例如,有时侯我们会要求生成指定的某类图像,而不是随意模拟样本数据,比如生成某个文字;有时我们要求对图像某些部分做生成替换,而不是生成全部的图像,比如消除马赛克。基于这些实际生活上的要求,GAN也需要对模型的结构做出调整,以满足生成我们需要的数据。
cGAN
如今在应用领域,绝大多数的数据是多标签的数据,而如何生成指定标签的数据就是条件GAN(conditional GAN,cGAN)在GAN模型上做的贡献。在基本的GAN模型中,生成器是通过输入一串满足某个分布的随机数来实现的(一般以均匀分布和高斯分布为主下,当然,改进后的GAN也有不以随机数作为生成器的输入值的,如CycleGAN等,此处暂不讨论),而在CGAN中,不仅要输入随机数,还需要将之与标签类别做拼接(concat,一般要将标签转换成如one-hot或其它的tensor),再将其输入生成器生成所需要的数据。此外,对判别器,也需要将真实数据或生成数据与对应的标签类别做拼接,再输入判别器的神经网络进行识别和判断,其目标函数如下:
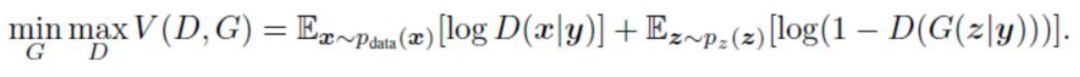
其模型结构图如下:
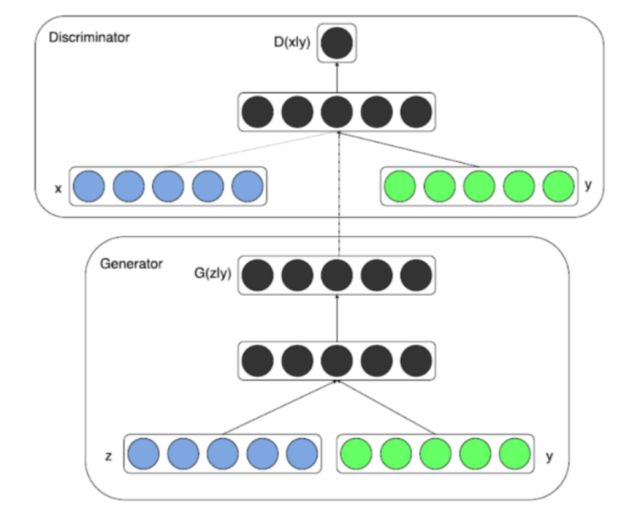 图6 CGAN的结构图
图6 CGAN的结构图
InfoGAN
自cGAN被提出后,针对cGAN的后续工作,也有很多学者利用cGAN做了应用或者改进。如拉普拉斯GAN (Laplacian Generative Adversarial Networks, LAPGAN)结合了GAN与cGAN的原理,利用一个串联的网络,以上一级生成的图片作为条件变量,构成拉普拉斯金字塔(laplacian pyramid),从而生成从粗糙到精密的图片。
InfoGAN(MutualInformation)本质上也可以看作是一种cGAN。从出发点看,InfoGAN是基于朴素GAN改进的。它将原先生成器上输入的z进行分解,除了原先的噪声z以外,还分解出一个隐含编码c。其中c除了可以表示类别以外,还可以包含多种变量。以MNIST数据集为例,还可以表示诸如光照方向,字体的倾斜角度,笔画粗细等。InfoGAN的基本思想是,如果这个c能解释生成出来的G(z,c),那么c应该与G(z,c)由高度的相关性。在InfoGAN中,可以表示为两者的互信息,目标函数可以写作
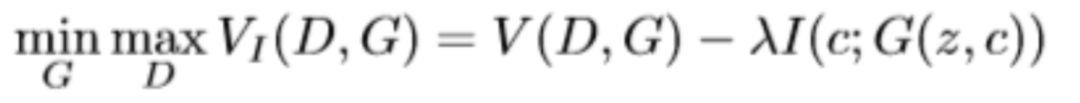
然而在互信息I(c; G(z, c))的优化中,真实的P(c|x)很难计算,因此作者采用了变分推断的思想,引入了变分分布Q(c|x)来逼近P(c|x),
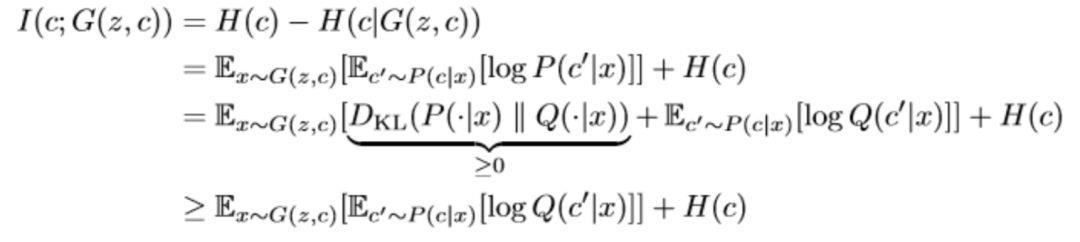
如此可以定义变分下界为
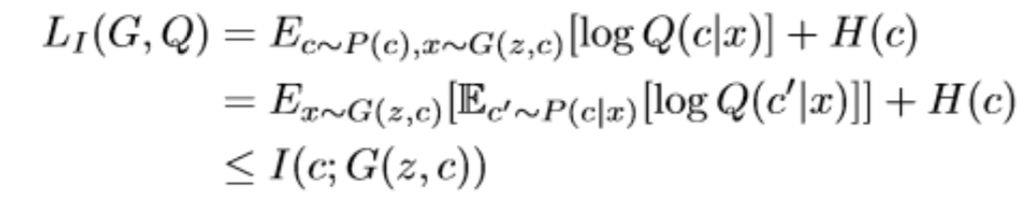
这样InfoGAN的目标函数可以写作
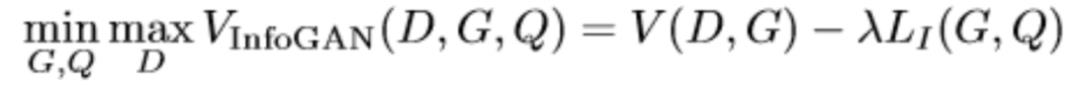
从模型结构上,可以表示成如下所示
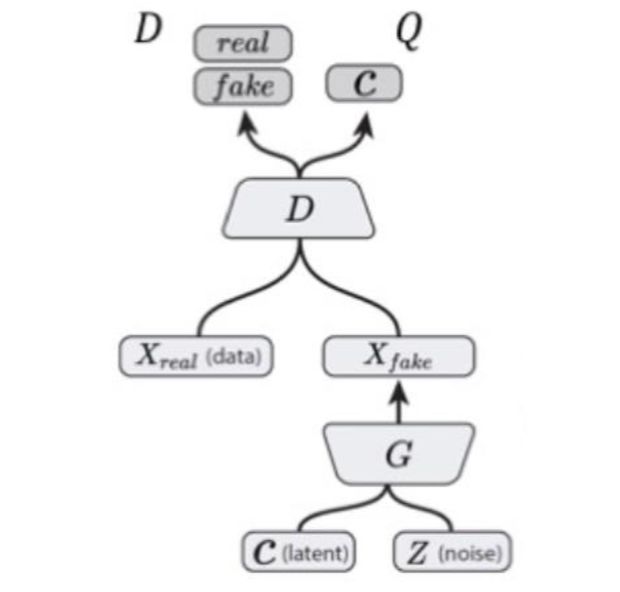 图7 InfoGAN模型结构示意图
图7 InfoGAN模型结构示意图
Q通过与D共享卷积层,计算花销大大减少。此外,Q是一个变分分布,在神经网络中直接最大化,Q也可以视作一个判别器,输出类别c。
InfoGAN的重要意义在于,它通过从噪声z中拆分出结构化的隐含编码c的方法,使得生成过程具有一定程度的可控性,生成结果也具备了一定的可解释性。
Pix2Pix
图像作为一种信息媒介,可以有很多种表达方式,比如灰度图、彩色图、素描图、梯度图等。图像翻译就是指这些图像的转换,比如已知灰度图,进而生成一张彩色照片。多年以来,这些任务都需要用不同的模型去生成。在GAN以及CGAN出现后,这些任务成功地可以用同一种框架来解决,即基于CGAN的变体——Pix2Pix。
Pix2Pix将生成器看作是一种映射,即将图片映射成另一张需要的图片,所以才将该算法取名为Pix2Pix,表示map pixels to pixels,即像素到像素的映射。这种观点也给了后来研究者改进的想法和启发。
因此,生成器输入除随机数z以外,将图片x(如灰度图,素描图等)作为条件进行拼接,输出的是转换后的图片(如照片)。而判别器输入的是转换后的图片或真实照片,特别之处在于,文章发现,判别器也将生成器输入的图片x作为条件进行拼接,会极大提高实验的结果,其结构图如下所示(此处结构图隐去了生成器的随机数z)
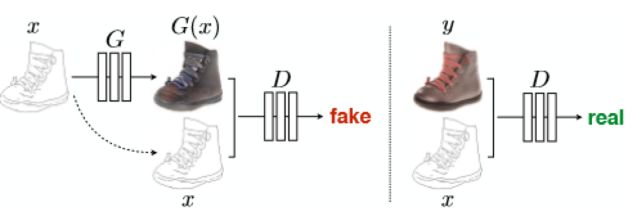 图8 Pix2Pix模型结构示意图
图8 Pix2Pix模型结构示意图
Pix2Pix的目标函数分为两部分,首先是基于CGAN的目标函数,如下式所示,
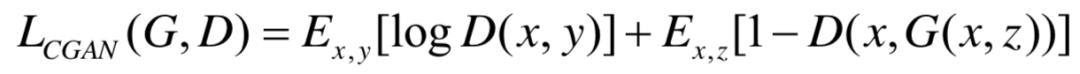
此外,还有生成的图像与原图一致性的约束条件
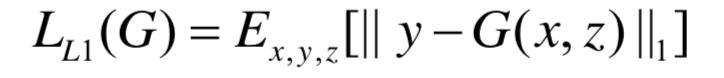
将之作为正则化约束,所以Pix2Pix的目标函数为
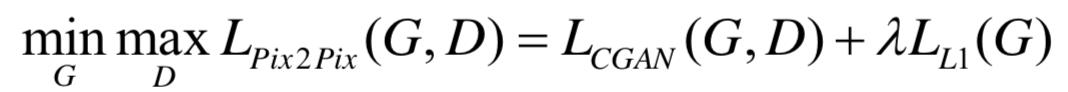
Pix2Pix成功地将GAN应用于图像翻译领域,解决了图像翻译领域内存在的众多问题,也为后来的研究者做了重要的启发。
CycleGAN
然而,Pix2Pix致命的缺点在于,Pix2Pix的训练需要相互配对的图片x与y,然而,这类数据是极度缺乏的,也为极大限制了Pix2Pix的应用。
对此,CycleGAN提出了不需要配对的数据的图像翻译方法。
设X,Y为两类图像,px,py为两类图像间的相互映射。CycleGAN由两对生成器和判别器组成,分别为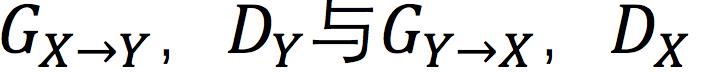 ,若以wgan为基础,那么对Y类图像,有
,若以wgan为基础,那么对Y类图像,有
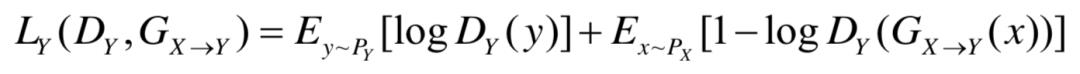
同样,对X类图像,有
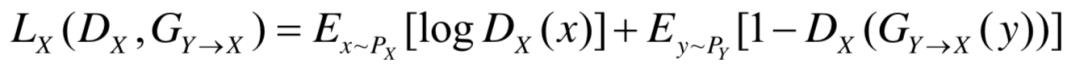
此外,Cycle以及CycleGAN中较为重要的想法循环一致性(Cycle-Consistent),这也是CycleGAN中Cycle这一名称的由来。循环一致性也可以看作是Pix2Pix一致性约束的演变进化,其基本思想是两类图像经过两次相应的映射后,又会变为原来的图像。因此,循环一致性可以写作
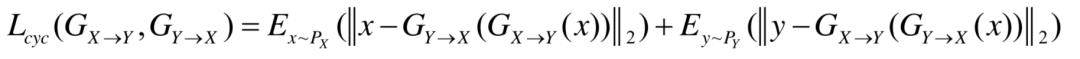
因此,优化问题可以写成
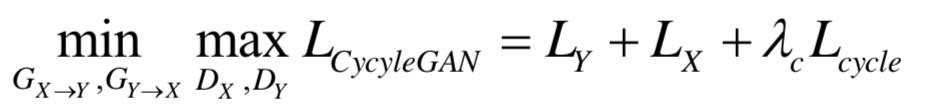
其中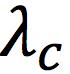 为常数。
为常数。
CycleGAN的成功之处在于,他们用如此简单的模型,成功解决了图像翻译领域面临的数据缺乏问题。不需要配对的两个场景的相互映射,实现了图像间的相互转换,是图像翻译领域的又一重大突破。
StarGAN
由上所述,Pix2Pix解决了有配对的图像翻译问题,CycleGAN解决了无配对的图像翻译问题,然而无论是Pix2Pix又或者是Cycle,他们对图像翻译而言,都是一对一的,也即是一类图像对一类图像。然而涉及多类图像之间的转换,就需要CycleGAN进行一对一逐个训练,如图6(a)所示,显然这样的行为是极为低效的。
针对这种困境,StarGAN解决了这类问题。如下图所示,StarGAN希望能够通过一个生成器解决所有跨域类别问题。
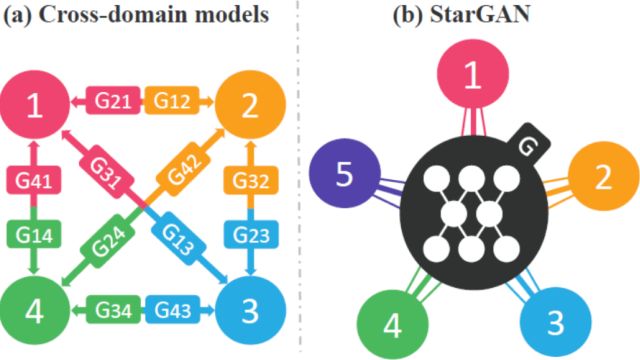 图9 跨域模型(如CycleGAN等)与StarGAN
图9 跨域模型(如CycleGAN等)与StarGAN
针对于此,StarGAN在生成器与判别器的设计以及模型结构上如下图所示:
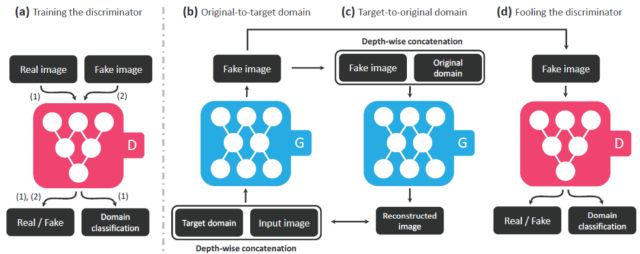 图10 StarGAN模型结构示意图
图10 StarGAN模型结构示意图
模型中(a)-(d)的要求如下:
(a)D学会区分真实图像和生成图像,并将真实图像分类到其对应的域。因此,对D而言,实际上是由两部分组成的,即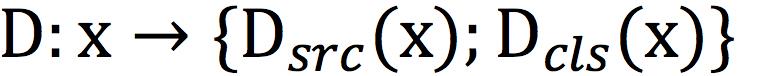 ;
;
(b)拼接目标标签与输入图片,将之输入G,并生成相应的图像;
(c)在给定原始域标签的情况下,G要尽量能重建原始图像。这与CycleGAN的循环一致性一脉相承;
(d)这一点与一般的GAN相同,G要尽量生成与真实图像相似的图像,但同时又尽量能被D区分出来。
从目标函数上来看,首先判别器的目标函数,要求满足GAN的结构,即
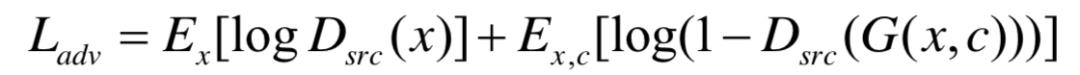
此外,还要就判别器能将真实图像分类到相应的域,
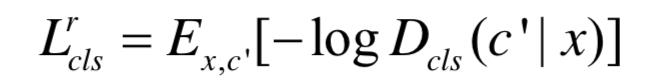
针对生成器,除了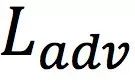 对应的GAN的结构外,还要求判别器能将生成图像分类到相应的域
对应的GAN的结构外,还要求判别器能将生成图像分类到相应的域
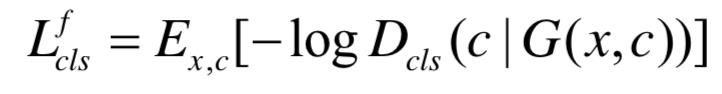
此外,还要求尽量能重建原始图像
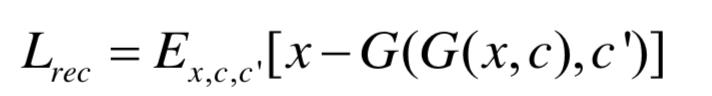
其中,c′为原始图像对应的类别。如此,可以得到判别器的目标函数
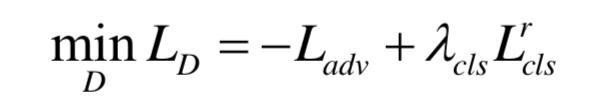
以及生成器的目标函数为
其中均为常数。
StarGAN作为CycleGAN的推广,将两两映射变成了多领域之间的映射,是图像翻译领域的又一重大突破。此外,StarGAN还可以通过实现多数据集之间的联合训练(比如将拥有肤色,年龄等标签的CelebA数据集和拥有生气、害怕等表情标签的RaFD数据集),将之训练到同一个模型,完成了模型的压缩,是图像翻译领域的一大突破。
GAN 的应用
GAN最直接的应用在于数据的生成,也就是通过GAN的建模能力生成图像、语音、文字、视频等等。而如今,GAN最成功的应用领域主要是计算机视觉,包括图像、视频的生成,如图像翻译、图像上色、图像修复、视频生成等。此外GAN在自然语言处理,人机交互领域也略有拓展和应用。本章节将从图像领域、视频领域以及人机交互领域分别介绍GAN的相关应用。
图像领域
例如,CycleGAN就是GAN在图像领域上的一种重要应用模型。CycleGAN以无需配对的两类图像为基础,可以通过输入一张哭脸将其转变为笑脸。StarGAN是CycleGAN的进一步扩展,一个类别与一个类别对应就要训练一次太过麻烦,我们不但需要把笑脸转化为哭脸,还需要把它转化为惊讶,沮丧等多种表情,而StarGAN实现了这种功能。
此外,很多的GAN技术也有将文字描述转换成图片,根据轮廓图像生成接近真实的照片等等功能。
视频领域
Mathieu[10]等人首先将GAN训练应用于视频预测,即生成器根据前面一系列帧生成视频最后一帧,判别器对该帧进行判断。除最后一帧外的所有帧都是真实的图片,这样的好处是判别器能有效地利用时间维度的信息,同时也有助于使生成的帧与前面的所有帧保持一致。实验结果表明,通过对抗训练生成的帧比其他算法更加清晰。
此外,Vondrick[11]等人在视频领域也取得了巨大进展,他们能生成32帧分辨率为64×64 的逼真视频,描绘的内容包括高尔夫球场、沙滩、火车站以及新生儿。经过测试,20%的标记员无法识别这些视频的真伪。
人机交互领域
Santana等人实现了利用GAN 的辅助自动驾驶。首先,生成与真实交通场景图像分布一致的图像,然后,训练一个基于循环神经网络的转移模型来预测下一个交通场景。
另外,GAN还可以用于对抗神经机器翻译,将神经机器翻译(neural machine translation, NMT)作为GAN 的生成器,采用策略梯度方法训练判别器,通过最小化人类翻译和神经机器翻译的差别生成高质量的翻译。
总结
GAN由于其强大的生成能力,正被广泛地研究与关注。目前,在学术领域,目前GAN训练指标,模式坍塌以及模型的生成能力的可解释性正受广泛的关注。最后,在拓展应用领域,由于生成的图片有较高的噪音,如何提高数据(图片或视频等)也是研究的一大热点。此外,GAN作为一种深度模型,也是解决自然语言处理(Natural Language Processing, NLP)天然的良好模型。如何将GAN应用在NLP领域也是下一步要解决的问题。
参考文献:
[1] Goodfellow I J, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets[C]//: International Conference on Neural Information Processing Systems, 2014.
[2] Radford A, Metz L, Chintala S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks[J]. Computer Science, 2015.
[3] Arjovsky M, Bottou L. Towards Principled Methods for Training Generative Adversarial Networks[J]. 2017.
[4] Arjovsky M, Chintala S, Bottou L. Wasserstein GAN[J]. 2017.
[5] Gulrajani I, Ahmed F, Arjovsky M, et al. Improved Training of Wasserstein GANs[J]. 2017.
[6] Mao X, Li Q, Xie H, et al. Least Squares Generative Adversarial Networks[C]// IEEE International Conference on Computer Vision. IEEE Computer Society, 2017:2813-2821.
[7] Nowozin S, Cseke B, Tomioka R. f-GAN: Training Generative Neural Samplers using Variational Divergence Minimization[J]. 2016.
[8] Qi G J. Loss-Sensitive Generative Adversarial Networks on Lipschitz Densities[J]. 2017.
[9] Salimans T, Goodfellow I, Zaremba W, et al. Improved Techniques for Training GANs[J]. 2016.
[10] Mathieu M, Couprie C, Lecun Y. Deep multi-scale video prediction beyond mean square error[J]. arXiv: arXiv1511.05440, 2015.
[11] Vondrick C, Pirsiavash H, Torralba A. Generating videos with scene dynamics[C]//Conferrence on Neural Information Processing Systems. 2016: 613-621.
[12] Wu L, Xia Y, Zhao L, et al. Adversarial neural machine translation [J]. arXiv: arXiv1704.06933, 2017.
以上是关于一文读懂生成式对抗网络模型的主要内容,如果未能解决你的问题,请参考以下文章