kafka生产者开发方式
Posted PacosonSWJTU
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka生产者开发方式相关的知识,希望对你有一定的参考价值。
【README】
本文记录了 kafka生产者开发方式;
【1】生产者概览
【1.1】kafka发送消息过程
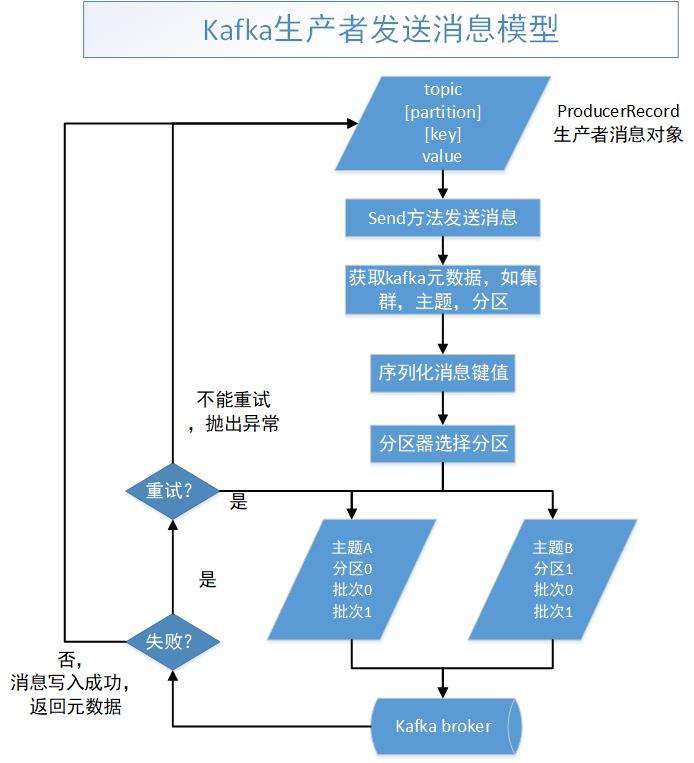
【1.2】创建kafka生产者
1)创建kafka生产者, 有3个必选属性:
- bootstrap.servers: kakfa集群节点地址;
- key.serializer: 键序列化器;
- value.serializer:值序列化器;
/* 1.创建kafka生产者的配置信息 */
Properties props = new Properties();
/* 指定连接的kafka集群, broker-list */
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "centos201:9092");
/* key, value 的序列化类 */
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
/** 设置压缩算法 */
props.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy");
/* 2.创建生产者对象 */
KafkaProducer<String, String> producer = new KafkaProducer<>(props);【2】发送消息到kafka
1)发送消息有3种方式:
- 发送并忘记:把消息发送给服务器,不管它是否到达;
- 同步发送:调用send()方法, 返回一个Future对象,调用其get() 方法进入阻塞,服务器响应时,阻塞线程被唤醒并获得消息写入的元数据;
- 异步发送:调用send() 方法,并指定一个回调函数,服务器在响应是调用该函数;
【2.1】同步发送
/**
* @Description 同步发送生产者
* @author xiao tang
* @version 1.0.0
* @createTime 2021年12月09日
*/
public class MyProducerSync
public static void main(String[] args)
// 1.创建kafka生产者的配置信息
Properties props = new Properties();
// 指定连接的kafka集群, broker-list
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.163.201:9092,192.168.163.202:9092,192.168.163.203:9092");
// key, value 的序列化类
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 2.创建生产者对象
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
// 3.发送数据
Future<RecordMetadata> future = producer.send(
new ProducerRecord<String, String>("hello10","k1", "v1"));
try
// 当前线程阻塞,直到kafka响应返回写入消息的元数据
RecordMetadata respMetadata = future.get();
System.out.println("[生产者写入消息] 分区【" + respMetadata.partition() + "】-offset【" + respMetadata.offset() + "】");
catch (Exception e)
// 关闭生产者
producer.close();
System.out.println("kafka生产者写入数据完成");
kafka生产者一般发生两类错误:
- 可重试错误,如连接错误(通过再次建立连接来解决),无主错误(通过重新分区选举首领解决);
- 不可重试错误,如消息太大错误;
【2.2】异步发送消息 (带回调函数)
/**
* @Description 【异步】发送生产者
* @author xiao tang
* @version 1.0.0
* @createTime 2021年12月09日
*/
public class MyProducerAsync
public static void main(String[] args)
// 1.创建kafka生产者的配置信息
Properties props = new Properties();
// 指定连接的kafka集群, broker-list
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.163.201:9092,192.168.163.202:9092,192.168.163.203:9092");
// key, value 的序列化类
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 2.创建生产者对象
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
// 3.发送数据
producer.send(
new ProducerRecord<String, String>("hello10","k1", "v1"),
new MyProducerCallback());
// 关闭生产者
producer.close();
System.out.println("kafka生产者写入数据完成");
/**
* @Description 生产者发送消息后回调类
* @author xiao tang
* @version 1.0.0
* @createTime 2021年12月09日
*/
private static class MyProducerCallback implements Callback
// kafka服务器响应时回调方法
@Override
public void onCompletion(RecordMetadata metadata, Exception exception)
if (exception == null)
System.out.println("[生产者写入消息成功] 分区【" + metadata.partition() + "】-offset【" + metadata.offset() + "】");
else
System.out.printf("写入kafka失败,异常信息【%s】", exception);
【2.3】生产者配置
1)acks: 有3个可选项;表示生产者消息被认为写入成功时,需要写入的副本个数;
- 0:无需判断,只要把消息发送出去,就认为成功;
- 1:仅首领副本;
- all:所有副本;
2)buffer.memory: 设置生产者内存缓冲区大小,用于缓冲发送到服务器的消息;
- 若缓冲区不足,send() 方法要么阻塞,要么抛出异常;取决于如何设置 max.block.ms 参数(抛出异常前可以阻塞一段时间);
3)compression.type: 压缩算法;
- 默认不压缩;可选压缩算法包括 snappy, gzip ,lz4 ;
- 使用压缩可以降低网络传输开销和存储开销,这是 kafka发送消息的瓶颈所在;
4)retries: 发送消息失败时,生产者可以重试的次数;
- 如果达到这个次数,生产者会放弃重试并返回错误; 默认情况下,生产者会在每次重试之间等待 100ms,通过 retry.backoff.ms 参数来改变这个时间间隔;
- 一般情况下,没必须处理可重试错误。但需要处理不可重试错误或重试次数超过上限的情况;
5)batch.size: 生产者把多个消息放在同一个批次里;该参数指定了一个批次可以使用的内存大小,单位字节;不过生产者不一定等到批次被填满才发送(参考 linger.ms);
6)linger.ms:指定生产者在发送批次前等待更多消息加入批次的时间;
- 生产者会在批次填满或linger.ms 达到上限时把批次发送出去;
- 建议把linger.ms 设置为大于0的数,虽然增加了延时但提高了吞吐量;
7)client.id : 任意字符串,服务器用它识别消息来源,还可以用在 日志和配额指标里;
8)max.in.flight.requests.per.connection : 指定生产者在收到服务器响应前可以发送多少个消息;
- 把它设置为1,可以保证消息是按照顺序写入服务器的,即使发生了重试;
9)timeout.ms , request.timeout.ms 和 metadata.fetch.timeout.ms
- request.timeout.ms: 指定了生产者在发送数据时等待服务器返回响应的时间;
- metadata.fetch.timeout.ms: 指定了生产者在获取元数据时等待服务器返回响应时间;若等待超时,要么重试,要么抛出异常;
- timeout.ms:指定了broker等待同步副本返回消息确认的时间, 与 acks 相匹配;
10)max.block.ms : send() 方法或使用 partitionFor() 获取元数据时生产者的阻塞时间;
- 当生产者发送缓冲区已满,或没有可用的元数据,这些方法就会阻塞;在阻塞时间达到 该值时,生产者抛出超时异常;
11)max.request.size: 指定生产者发送的请求大小;
- 可以指单个消息的最大值,也可以指单个请求所有消息总大小(如一批多个消息但走了一个请求);
- 注意: broker对可接受的消息最大值有自己的限制(通过 message.max.bytes) 指定;
12)receive.buffer.bytes 和 send.buffer.bytes
- 分别指定 TCP socket接收和发送数据包的缓冲区大小; 如果设置为-1,使用操作系统默认值;
【2.4】生产者常用配置代码示例
public class MyProducer
public static void main(String[] args)
/* 1.创建kafka生产者的配置信息 */
Properties props = new Properties();
/*2.指定连接的kafka集群, broker-list */
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "centos201:9092");
/*3.ack应答级别*/
props.put(ProducerConfig.ACKS_CONFIG, "all");
/*4.重试次数*/
props.put(ProducerConfig.RETRIES_CONFIG, 0);
/*5.批次大小,一次发送多少数据,当数据大于16k,生产者会发送数据到 kafka集群 */
props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16 * KfkNumConst._1K);
/*6.等待时间, 等待时间超过1毫秒,即便数据没有大于16k, 也会写数据到kafka集群 */
props.put(ProducerConfig.LINGER_MS_CONFIG, 1);
// 超时时间
props.put(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG, 3000);
props.put(ProducerConfig.MAX_BLOCK_MS_CONFIG, 3000);
/*7. RecordAccumulator 缓冲区大小*/
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 32 * KfkNumConst._1M);
/*8. key, value 的序列化类 */
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
/** 设置压缩算法 */
props.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy");
System.out.println(props);
/* 9.创建生产者对象 */
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
/* 10.发送数据 */
String now = DateUtils.getNowTimestamp();
int order = 1;
for (int i = 0; i < 50000; i++)
for (int j = 0; j < 3; j++)
Future<RecordMetadata> future = producer.send(new ProducerRecord<String, String>("hello10",j, "", String.format("[%s] ", order++) + now + " > " + DataFactory.INSTANCE.genChar(5)));
try
System.out.println("[生产者] 分区【" + future.get().partition() + "】-offset【" + future.get().offset() + "】");
catch (Exception e)
/* 11.关闭资源 */
producer.close();
System.out.println("kafka生产者写入数据完成");
【3】分区
1)使用消息的键来做hash,以hash值作为分区号;
2)如果键为null,则使用默认分区器;默认使用 轮询(Round Robin)算法把消息均衡分布到各个分区上;
【3.1】实现自定义分区策略
/**
* @Description 自定义分区策略的生产者
* @author xiao tang
* @version 1.0.0
* @createTime 2021年12月09日
*/
public class MyProducerWithPartition
public static void main(String[] args)
// 1.创建kafka生产者的配置信息
Properties props = new Properties();
// 指定连接的kafka集群, broker-list
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.163.201:9092,192.168.163.202:9092,192.168.163.203:9092");
// key, value 的序列化类
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 设置分区器
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, MyPartitioner.class.getName());
// 2.创建生产者对象
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
// 3.发送数据
Future<RecordMetadata> future = producer.send(
new ProducerRecord<String, String>("hello10","31", "v1"));
try
// 当前线程阻塞,直到kafka响应返回写入消息的元数据
RecordMetadata respMetadata = future.get();
System.out.println("[生产者写入消息] 分区【" + respMetadata.partition() + "】-offset【" + respMetadata.offset() + "】");
catch (Exception e)
// 关闭生产者
producer.close();
System.out.println("kafka生产者写入数据完成");
分区器
/**
* @Description 分区器
* @author xiao tang
* @version 1.0.0
* @createTime 2021年12月09日
*/
public class MyPartitioner implements Partitioner
// 对键首位字符ascii取分区数的模获得分区号
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster)
int partitionSize = cluster.partitionCountForTopic(topic);
int operand = 0;
if (key != null && String.valueOf(key).length() > 0)
operand = String.valueOf(key).codePointAt(0);
return operand % partitionSize;
@Override
public void close()
@Override
public void configure(Map<String, ?> configs)
【4】拦截器
定义拦截器,设置拦截器属性(可配置多个拦截器);
/** 设置拦截器 */
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,
Arrays.asList(TimeInterceptor.class.getName()));/**
* @Description 时间拦截器
* @author xiao tang
* @version 1.0.0
* @createTime 2021年12月10日
*/
public class TimeInterceptor implements ProducerInterceptor<String, String>
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record)
// 在消息被序列化以及计算分区前调用, 追加时间戳(偷梁换柱)
return new ProducerRecord<>(
record.topic(), record.partition(), record.key(), record.value() + "[TimeInterceptor]" + DateUtils.getNowTimestamp());
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception)
// 在消息从 RecordAccumulator 成功发送到Kafka Broker之后,或者在发送过程中失败时调用
// 写入数据库
@Override
public void close()
@Override
public void configure(Map<String, ?> configs)
消费消息日志:
消费者-分区【0】offset【7774】 -> 2021-12-10 21:05:32--[1] > ABCDE[TimeInterceptor]2021-12-10 21:05:30
消费者-分区【1】offset【7644】 -> 2021-12-10 21:05:32--[2] > ABCDE[TimeInterceptor]2021-12-10 21:05:32
消费者-分区【2】offset【7626】 -> 2021-12-10 21:05:32--[3] > ABCDE[TimeInterceptor]2021-12-10 21:05:32
以上是关于kafka生产者开发方式的主要内容,如果未能解决你的问题,请参考以下文章
SpringCloud系列十一:SpringCloudStream(SpringCloudStream 简介创建消息生产者创建消息消费者自定义消息通道分组与持久化设置 RoutingKey)(代码片段