[Pytorch系列-59]:循环神经网络 - 中文新闻文本分类详解-1-业务目标分析与总体架构
Posted 文火冰糖的硅基工坊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Pytorch系列-59]:循环神经网络 - 中文新闻文本分类详解-1-业务目标分析与总体架构相关的知识,希望对你有一定的参考价值。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/121756744
目录
第1章 业务分析
1.1 本文的业务目标
给定一个限定长度的新闻文本标题,判断其属于哪种类型的新闻,主要的新闻类型有:
(0)finance:财经
(1)realty:房地产
(2)stocks:股票
(3)education:教育
(4)science:科学
(5)society:社会
(6)politics:政治
(7)sports:体育
(8)game:游戏
(10)entertainment:娱乐
上述分类为10分类。
上述类型定义在..\\新闻数据集text\\THUCNews\\data\\class.txt文件中。
1.2 基本思路
(1)首先,这是分类问题
(2)其二,这是文本分类,而不是图片分类,文本分类属于时序网络
(3)其三,选择神经网络进行预测
(4)在预测前,需要使用标签过的样本对模型进行训练
第2章 总体架构与建模
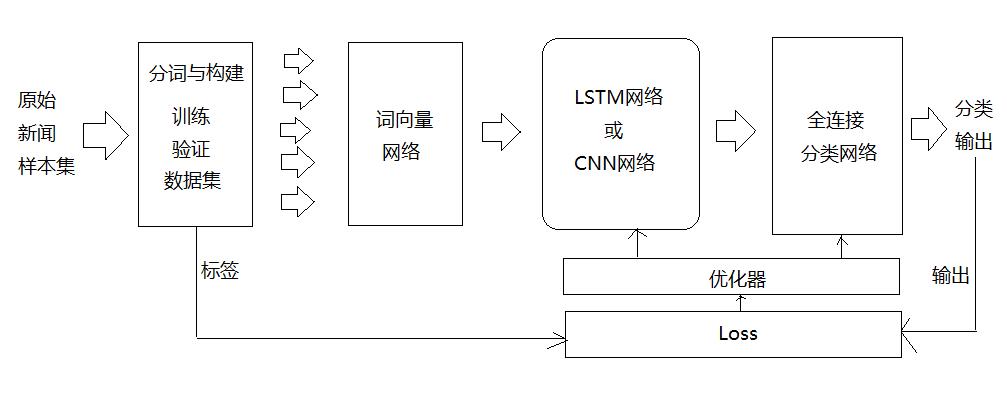
LSTM网络或CNN网络:提取不同词向量的文本特征。
全连接网络:根据LSTM或CNN提取的词向量的特征进行10分类。
备注:
传统的文本分类是根据关键词进行分类。
神经网络的分类是根据所有单词的特征以及这些特征的权重进行分类,权重的大小需要预先训练。
训练的过程就是建立词向量以及提取的特征、对应的特征权重与分类类型建立映射关系。
第3章 数据集分析
3.1 数据集的种类与大小
(1)训练集:train.txt =》 18万个条目
..\\新闻数据集text\\THUCNews\\data\\train.txt文件中。
(2)验证集:dev.txt =》 1万个条目
..\\新闻数据集text\\THUCNews\\data\\dev.txt文件中。
(3)测试集:test.txt =》 1万个条目
..\\新闻数据集text\\THUCNews\\data\\test.txt文件中。
3.2 数据集的内容
中华女子学院:本科层次仅1专业招男生 3
两天价网站背后重重迷雾:做个网站究竟要多少钱 4
东5环海棠公社230-290平2居准现房98折优惠 1
卡佩罗:告诉你德国脚生猛的原因 不希望英德战踢点球 7
82岁老太为学生做饭扫地44年获授港大荣誉院士 5
记者回访地震中可乐男孩:将受邀赴美国参观 5
冯德伦徐若�隔空传情 默认其是女友 9
传郭晶晶欲落户香港战伦敦奥运 装修别墅当婚房 1
《赤壁OL》攻城战诸侯战硝烟又起 8
“手机钱包”亮相科博会 4
上海2010上半年四六级考试报名4月8日前完成 3
.......................................................................
备注:
文字:表示新闻标题
数字:表示新闻分类
3.3 数据集的预处理
(1)原始的数据集转换成神经网络能够识别的数据集
(2)采用data loader的批处理机制
第4章 词向量选择分析
词向量是本应用的一个重要的因素,本应用是新闻文本分类,因此,词向量最好是能够是通过新闻文本训练出来的词向量。
为了提升训练的效率,本案例就不重新训练词向量表,完全可以利用新闻网站已经训练好的词向量表。
这里,国内可选的词向量表有:
.\\新闻数据集text\\THUCNews\\data\\embedding_Tencent.npz =》腾讯训练好的词向量
.\\新闻数据集text\\THUCNews\\data\\embedding_SougouNews.npz =》 sougou训练好的词向量
第5章 模型选择
常规来讲,由于是文本分析,因此RNN或LSTM或GRU网络是比较好的选择,本应用选择LSTM网络。
为了深入了解文本分类的时序性,作为对比,本应用,还进一步采用CNN网络来实现时序特征的提取。
第6章 开发工具
由于文件的规模较大,且需要对功能进行切分,因此jupter工具已经不太适合。
本应用,选用pycharm工具进行开发与调试。
第7章 代码结构分析
(1)...\\新闻数据集text\\ =》逻辑处理代码
- run.py:该应用的main主程序,复杂组织代码的执行流程。
- train_eval.py:模型训练的主代码
- utils.py:数据集的预处理的主代码。
- utils_fasttext.py:同上
(2)...\\新闻数据集text\\models =》模型代码
- TextCNN.py:CNN网络构建的主代码
- TextRNN.py:RNN网络构建的主代码
(3)..\\新闻数据集text\\THUCNews:数据
- ..\\新闻数据集text\\THUCNews\\data:三种原始的数据集文件
- ..\\新闻数据集text\\THUCNews\\log:训练过程中的loss、accuary等训练数据
- ..\\新闻数据集text\\THUCNews\\saved_dict:训练好的模型文件
(4)代码分析: 参考下一篇文章
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/121756744
以上是关于[Pytorch系列-59]:循环神经网络 - 中文新闻文本分类详解-1-业务目标分析与总体架构的主要内容,如果未能解决你的问题,请参考以下文章
[Pytorch系列-58]:循环神经网络 - 词向量的自动构建与模型训练代码示例
[Pytorch系列-55]:循环神经网络 - 使用LSTM网络对股票走势进行预测
[Pytorch系列-53]:循环神经网络 - torch.nn.LSTM()参数详解
[Pytorch系列-54]:循环神经网络 - torch.nn.GRU()参数详解