[Pytorch系列-58]:循环神经网络 - 词向量的自动构建与模型训练代码示例
Posted 文火冰糖的硅基工坊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Pytorch系列-58]:循环神经网络 - 词向量的自动构建与模型训练代码示例相关的知识,希望对你有一定的参考价值。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/121725458
目录
第1章 代码编写前的准备
1.1 理论前提
 https://blog.csdn.net/HiWangWenBing/article/details/121709147
https://blog.csdn.net/HiWangWenBing/article/details/1217091471.2 业务说明
词向量编码时指对某一段文字中的单词进行向量化,把每个单词编码成多维向量空间中的一个点。
这些点在向量空间中的位置关系,反应了这些词在某段文字中的语言和语义关系。
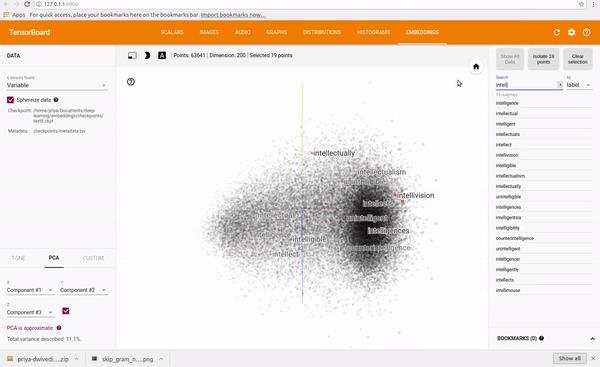
很显然,文本中的单词的数量少,比如几十个,人工编码的方式是可以做大的,但如果文字中包含的单词很多,比如几万,甚至几十万时,人工编码就不可行了。需要机器自动进行编码。
本文就是搭建个能够自动进行词向量编码的神经网络。
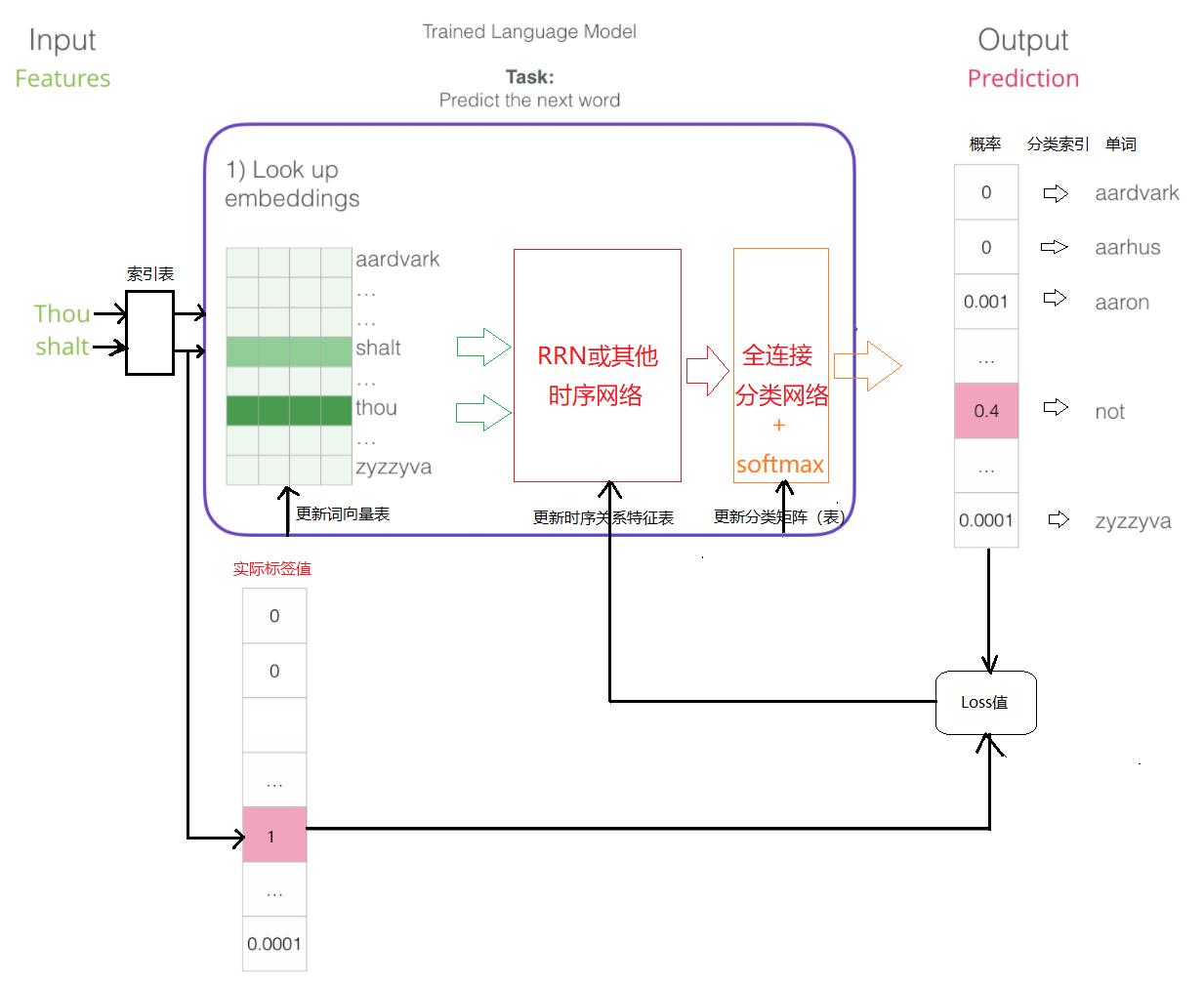
在本文,用普通的线性网络替代了RNN网络。使用一段莎士比亚的文章作为训练的文本,文本数量不大,仅仅作为演示之用,在实际应用系统中,需要使用业务领域的文本来替代。
1.3 pytorch库
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from gensim.models import Word2Vec
import matplotlib.pyplot as plt1.4 pytorch词向量表nn.Embedding
pytorch为词向量表定义了专门的数据结构nn.Embedding.
利用该结构,可以方便的定义词向量表,最重要的是,能够与普通神经网络一起,参与模型的训练与参数迭代,这极大的方便了词向量模型的自动构建。
#测试一下nn.Embedding的使用方法
word_to_ix = "hello": 0, "world": 1
embeds = nn.Embedding(2, 5) # 2 words in vocab, 5 dimensional embeddings
lookup_tensor = torch.tensor([word_to_ix["hello"]], dtype=torch.long)
hello_embed = embeds(lookup_tensor)
print(hello_embed)tensor([[ 0.6135, -0.9467, -1.7076, -0.4223, 0.6349]],
grad_fn=<EmbeddingBackward0>)
第2章 代码实现
2.1 文本数据
# 我们用莎士比亚的十四行诗 Sonnet 2
test_sentence = """When forty winters shall besiege thy brow,
And dig deep trenches in thy beauty's field,
Thy youth's proud livery so gazed on now,
Will be a totter'd weed of small worth held:
Then being asked, where all thy beauty lies,
Where all the treasure of thy lusty days;
To say, within thine own deep sunken eyes,
Were an all-eating shame, and thriftless praise.
How much more praise deserv'd thy beauty's use,
If thou couldst answer 'This fair child of mine
Shall sum my count, and make my old excuse,'
Proving his beauty by succession thine!
This were to be new made when thou art old,
And see thy blood warm when thou feel'st it cold.""".split()
# 分词后的文章
print(test_sentence)['When', 'forty', 'winters', 'shall', 'besiege', 'thy', 'brow,', 'And', 'dig', 'deep', 'trenches', 'in', 'thy', "beauty's", 'field,', 'Thy', "youth's", 'proud', 'livery', 'so', 'gazed', 'on', 'now,', 'Will', 'be', 'a', "totter'd", 'weed', 'of', 'small', 'worth', 'held:', 'Then', 'being', 'asked,', 'where', 'all', 'thy', 'beauty', 'lies,', 'Where', 'all', 'the', 'treasure', 'of', 'thy', 'lusty', 'days;', 'To', 'say,', 'within', 'thine', 'own', 'deep', 'sunken', 'eyes,', 'Were', 'an', 'all-eating', 'shame,', 'and', 'thriftless', 'praise.', 'How', 'much', 'more', 'praise', "deserv'd", 'thy', "beauty's", 'use,', 'If', 'thou', 'couldst', 'answer', "'This", 'fair', 'child', 'of', 'mine', 'Shall', 'sum', 'my', 'count,', 'and', 'make', 'my', 'old', "excuse,'", 'Proving', 'his', 'beauty', 'by', 'succession', 'thine!', 'This', 'were', 'to', 'be', 'new', 'made', 'when', 'thou', 'art', 'old,', 'And', 'see', 'thy', 'blood', 'warm', 'when', 'thou', "feel'st", 'it', 'cold.']
备注:把文本数据(字符串数组)分割成有一个个独立的单词组成的列表。
2.2 构建训练数据
(1)构建单词到索引的映射表
# 构建单词到索引的映射字典
vocab = set(test_sentence)
word_to_ix = word: i for i, word in enumerate(vocab)
print(word_to_ix)
print("")
print("index=",word_to_ix["when"])'now,': 0, 'own': 1, 'held:': 2, 'lies,': 3, 'say,': 4, 'Were': 5, 'gazed': 6, 'to': 7, 'Shall': 8, 'all': 9, 'proud': 10, 'in': 11, 'Thy': 12, 'old': 13, 'when': 14, 'by': 15, "'This": 16, 'be': 17, 'eyes,': 18, 'use,': 19, 'count,': 20, 'winters': 21, 'To': 22, 'fair': 23, 'more': 24, 'blood': 25, 'beauty': 26, 'field,': 27, 'forty': 28, 'a': 29, 'lusty': 30, 'couldst': 31, 'succession': 32, 'livery': 33, 'And': 34, 'see': 35, 'Then': 36, 'small': 37, 'trenches': 38, 'shall': 39, 'warm': 40, 'and': 41, 'made': 42, 'cold.': 43, 'thou': 44, 'This': 45, 'being': 46, "totter'd": 47, 'thriftless': 48, "beauty's": 49, 'make': 50, 'sunken': 51, 'child': 52, 'sum': 53, 'thine!': 54, 'his': 55, 'were': 56, 'mine': 57, 'Will': 58, 'Proving': 59, 'weed': 60, 'it': 61, 'within': 62, 'all-eating': 63, 'much': 64, 'deep': 65, 'art': 66, 'treasure': 67, 'answer': 68, "excuse,'": 69, 'praise': 70, 'brow,': 71, 'If': 72, 'thine': 73, 'so': 74, 'dig': 75, 'shame,': 76, 'praise.': 77, 'old,': 78, 'the': 79, 'my': 80, 'new': 81, 'Where': 82, 'thy': 83, 'worth': 84, 'When': 85, 'How': 86, 'besiege': 87, 'asked,': 88, "deserv'd": 89, 'days;': 90, "youth's": 91, 'of': 92, 'on': 93, 'where': 94, "feel'st": 95, 'an': 96
index= 14
(2)构建样本序列:两个输入单词 + 一个输出单词(标签)
输入:两个向量的单词组成的列表, 如['When', 'forty']
输出:下一个单词,如'winters'
在送入神经网络时,会word_to_ix把单词转换成对应的索引index。
# 根据文本,构建一连串的输入样本,每个样本的格式为:输入=[单词1, 单词2], 输出=单词3
# 创建一系列的元组,每个元组都是([ word_i-2, word_i-1 ], target word)的形式。
trigrams = [([test_sentence[i], test_sentence[i + 1]], test_sentence[i + 2])
for i in range(len(test_sentence) - 2)]
# 先看下是什么样子。
print(trigrams)[(['When', 'forty'], 'winters'), (['forty', 'winters'], 'shall'), (['winters', 'shall'], 'besiege'), (['shall', 'besiege'], 'thy'), (['besiege', 'thy'], 'brow,'), (['thy', 'brow,'], 'And'), (['brow,', 'And'], 'dig'), (['And', 'dig'], 'deep'), (['dig', 'deep'], 'trenches'), (['deep', 'trenches'], 'in'), (['trenches', 'in'], 'thy'), (['in', 'thy'], "beauty's"), (['thy', "beauty's"], 'field,'), (["beauty's", 'field,'], 'Thy'), (['field,', 'Thy'], "youth's"), (['Thy', "youth's"], 'proud'), (["youth's", 'proud'], 'livery'), (['proud', 'livery'], 'so'), (['livery', 'so'], 'gazed'), (['so', 'gazed'], 'on'), (['gazed', 'on'], 'now,'), (['on', 'now,'], 'Will'), (['now,', 'Will'], 'be'), (['Will', 'be'], 'a'), (['be', 'a'], "totter'd"), (['a', "totter'd"], 'weed'), (["totter'd", 'weed'], 'of'), (['weed', 'of'], 'small'), (['of', 'small'], 'worth'), (['small', 'worth'], 'held:'), (['worth', 'held:'], 'Then'), (['held:', 'Then'], 'being'), (['Then', 'being'], 'asked,'), (['being', 'asked,'], 'where'), (['asked,', 'where'], 'all'), (['where', 'all'], 'thy'), (['all', 'thy'], 'beauty'), (['thy', 'beauty'], 'lies,'), (['beauty', 'lies,'], 'Where'), (['lies,', 'Where'], 'all'), (['Where', 'all'], 'the'), (['all', 'the'], 'treasure'), (['the', 'treasure'], 'of'), (['treasure', 'of'], 'thy'), (['of', 'thy'], 'lusty'), (['thy', 'lusty'], 'days;'), (['lusty', 'days;'], 'To'), (['days;', 'To'], 'say,'), (['To', 'say,'], 'within'), (['say,', 'within'], 'thine'), (['within', 'thine'], 'own'), (['thine', 'own'], 'deep'), (['own', 'deep'], 'sunken'), (['deep', 'sunken'], 'eyes,'), (['sunken', 'eyes,'], 'Were'), (['eyes,', 'Were'], 'an'), (['Were', 'an'], 'all-eating'), (['an', 'all-eating'], 'shame,'), (['all-eating', 'shame,'], 'and'), (['shame,', 'and'], 'thriftless'), (['and', 'thriftless'], 'praise.'), (['thriftless', 'praise.'], 'How'), (['praise.', 'How'], 'much'), (['How', 'much'], 'more'), (['much', 'more'], 'praise'), (['more', 'praise'], "deserv'd"), (['praise', "deserv'd"], 'thy'), (["deserv'd", 'thy'], "beauty's"), (['thy', "beauty's"], 'use,'), (["beauty's", 'use,'], 'If'), (['use,', 'If'], 'thou'), (['If', 'thou'], 'couldst'), (['thou', 'couldst'], 'answer'), (['couldst', 'answer'], "'This"), (['answer', "'This"], 'fair'), (["'This", 'fair'], 'child'), (['fair', 'child'], 'of'), (['child', 'of'], 'mine'), (['of', 'mine'], 'Shall'), (['mine', 'Shall'], 'sum'), (['Shall', 'sum'], 'my'), (['sum', 'my'], 'count,'), (['my', 'count,'], 'and'), (['count,', 'and'], 'make'), (['and', 'make'], 'my'), (['make', 'my'], 'old'), (['my', 'old'], "excuse,'"), (['old', "excuse,'"], 'Proving'), (["excuse,'", 'Proving'], 'his'), (['Proving', 'his'], 'beauty'), (['his', 'beauty'], 'by'), (['beauty', 'by'], 'succession'), (['by', 'succession'], 'thine!'), (['succession', 'thine!'], 'This'), (['thine!', 'This'], 'were'), (['This', 'were'], 'to'), (['were', 'to'], 'be'), (['to', 'be'], 'new'), (['be', 'new'], 'made'), (['new', 'made'], 'when'), (['made', 'when'], 'thou'), (['when', 'thou'], 'art'), (['thou', 'art'], 'old,'), (['art', 'old,'], 'And'), (['old,', 'And'], 'see'), (['And', 'see'], 'thy'), (['see', 'thy'], 'blood'), (['thy', 'blood'], 'warm'), (['blood', 'warm'], 'when'), (['warm', 'when'], 'thou'), (['when', 'thou'], "feel'st"), (['thou', "feel'st"], 'it'), (["feel'st", 'it'], 'cold.')]
2.3 前向运算模型构建
(1)模型定义
class NGramLanguageModeler(nn.Module):
def __init__(self, vocab_size, embedding_dim, context_size):
super(NGramLanguageModeler, self).__init__()
#定义词向量表
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
#定义特征提取网络
self.linear1 = nn.Linear(context_size * embedding_dim, 128)
#定义分类网络
self.linear2 = nn.Linear(128, vocab_size)
def forward(self, inputs):
#词向量变化
embeds = self.embeddings(inputs).view((1, -1))
# 特征提取
out = F.relu(self.linear1(embeds))
# 分类
out = self.linear2(out)
probabilities = F.log_softmax(out, dim=1)
#probabilities = F.softmax(out, dim=1)
#返回
return probabilities(2)模型的示例化
CONTEXT_SIZE = 2 #同时输入到网络中单词的个数
EMBEDDING_DIM = 10 #每个单词的词向量的维度
EMBEDDING_SIZE = (len(vocab)) #单词的总数量
model = NGramLanguageModeler(EMBEDDING_SIZE, EMBEDDING_DIM, CONTEXT_SIZE)
print(model)NGramLanguageModeler( (embeddings): Embedding(97, 10) (linear1): Linear(in_features=20, out_features=128, bias=True) (linear2): Linear(in_features=128, out_features=97, bias=True) )
备注:
在本案例中,使用了线性网络替代了RNN网。因为本文需要构建的仅仅是词向量表。
而文本输入序列样本本身已经部分体现了单词之间的关系。
2.4 反向传播模型定义
#loss_function = nn.NLLLoss()
loss_function = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001)2.4 模型训练
(1)训练前的准备
#迭代的轮数
epoch_size = 10000
#存放没一轮迭代的loss值
losses = [](2)模型训练
for epoch in range(epoch_size):
total_loss = 0
for context_words, target_word in trigrams:
# 步骤 1\\. 准备好进入模型的数据 (例如将单词转换成整数索引,并将其封装在变量中)
context_idxs = torch.tensor([word_to_ix[word] for word in context_words], dtype=torch.long)
# 步骤 2\\. 回调torch累乘梯度
# 在传入一个新实例之前,需要把旧实例的梯度置零。
model.zero_grad()
# 步骤 3\\. 继续运行代码,得到所欲分类单词的log概率值。
probabilities = model(context_idxs)
# 步骤 4\\. 计算损失函数(再次注意,Torch需要将目标单词封装在变量里)。
# 获得目标标签对应的Index
label = torch.tensor([word_to_ix[target_word]], dtype=torch.long)
# Loss函数自动把index的Label,转换成OneHot编码值
loss = loss_function(probabilities, label)
# 步骤 5\\. 反向传播更新梯度
loss.backward()
optimizer.step()
# 通过调tensor.item()得到单个Python数值。
total_loss += loss.item()
#print(loss.item())
#print(probabilities)
if(epoch % 100 == 0):
print("epoch=%d, loss=%4f"%(epoch, total_loss))
losses.append(total_loss)epoch=0, loss=520.545579 epoch=100, loss=261.041876 epoch=200, loss=63.733812 epoch=300, loss=22.033269 epoch=400, loss=12.730851 epoch=500, loss=9.246820 epoch=600, loss=7.509527 epoch=700, loss=6.491206 epoch=800, loss=5.830179 epoch=900, loss=5.370453 epoch=1000, loss=5.033796 epoch=1100, loss=4.777777
........
epoch=9600, loss=3.144380 epoch=9700, loss=3.142568 epoch=9800, loss=3.140693 epoch=9900, loss=3.138768
(3)显示迭代过程中loss的变换过程
# 显示迭代过程中loss的变换过程
plt.grid()
plt.xlabel("iters")
plt.ylabel("")
plt.title("loss", fontsize = 12)
plt.plot(losses, "r")
plt.show()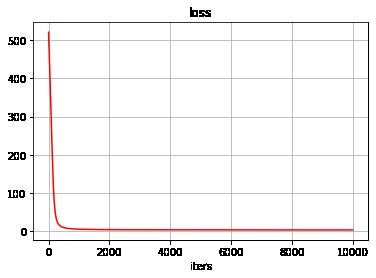
2.5 模型测试
(1)通过索引获取对应的训练好的词向量
通过索引获取对应的训练好的词向量,索引是通过列表的方式呈现,这样可以一次性读多个词向量。
embed_code = model.embeddings
# 生成一个以index为数据的多维的tensor
lookup_tensor = torch.tensor([0,2], dtype=torch.long)
print(lookup_tensor)
#查找指定tensor对应的词向量
# 每个单词用一个索引指示
# 每个单词对应的词向量是一个多维向量
embed_code = embed_code(lookup_tensor)
print(embed_code)ensor([0, 2])
tensor([[ 1.0879, 0.0286, 0.2702, 2.6052, 2.2662, 1.4505, -0.1695, 2.3666,
-0.6005, 0.0197],
[ 0.6688, -0.2273, -0.4991, -1.4674, 0.1719, -1.6898, 0.4688, -0.9412,
-0.5305, -0.4485]], grad_fn=<EmbeddingBackward0>)
备注:
这里读取了index=0和index=2处的训练好的词向量。每个词向量的size = 10.
至此,训练好的词向量表,就可以用于其他与文字处理相关的业务领域的应用了。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/121725458
以上是关于[Pytorch系列-58]:循环神经网络 - 词向量的自动构建与模型训练代码示例的主要内容,如果未能解决你的问题,请参考以下文章