从下往上看内存
Posted 一口Linux
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从下往上看内存相关的知识,希望对你有一定的参考价值。
1 内存条、总线与DMA
计算机组成中内存或者叫主存是非常重要的部件。内存因为地位太重要,所以和CPU直接相连,通过数据总线进行数据传输,并通过地址总线来进行物理地址的寻址。
除了数据总线、地址总线还有控制总线、IO总线等。IO总线是用来连接各种外设的,例如USB全称就是通用串行总线。再比如PCIE是目前最常见的IO总线之一。这里放一张B站硬件茶谈的一张图。
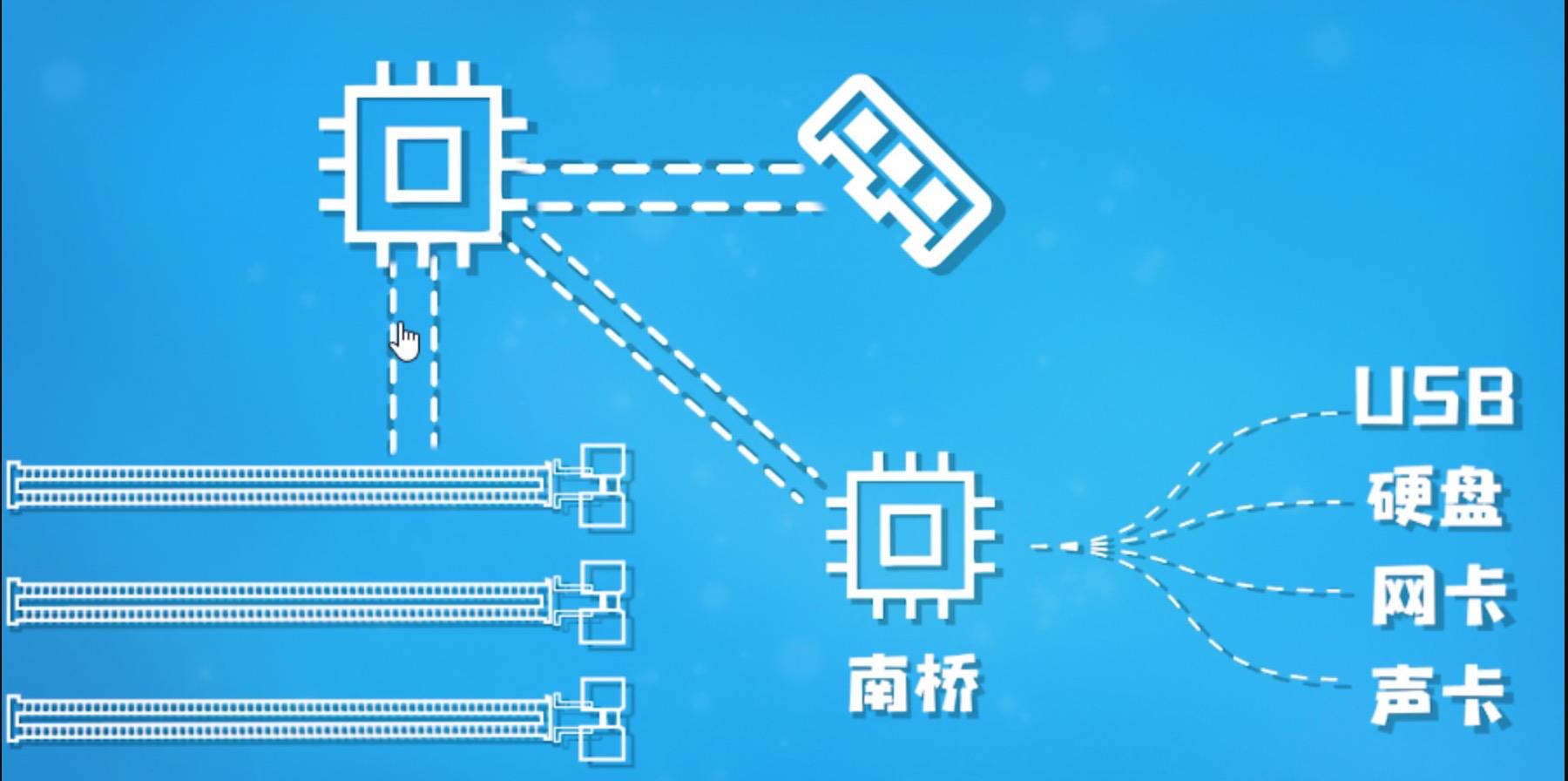
图1-1 硬件图
图中CPU和左侧内存条直接连,并通过PCIE总线与下方的PCIE插槽连接,在PCIE插槽上可以插显卡,网卡,声卡,硬盘等等。PCIE带宽是共享的,如果某个设备用了x1路带宽,则能用的就少一路,因为本质上每一路都是串行的。南桥和CPU之间也有PCIE通道,主要是提供给一些带宽占用很低的外设。
南桥芯片位于主板上,一般在右下角,有个被动散热下面压着。南桥中有个很重要的设备就是DMA控制器,或者叫DMAC。DMA直接内存访问,意思就是DMAC能够直接访问内存。即一般进行IO的时候,cpu会把总线完全交给DMAC(DMAC和CPU会分时掌控总线),DMAC访问设备如磁盘,将数据读到内存中,因为此时接管了总线,所以可以写内存。在这个过程中CPU可以进行其他的任务。这也是异步IO、非阻塞IO等理论的基础。
计算机常考题:

图1-2-1 题目1

图1-2-2 题目2
2 操作系统内存管理与分类
2.1 虚拟内存(逻辑内存)
win32程序从程序上能操作的逻辑地址空间有4G这么大(虽然实际可能用不了那么多),4G的逻辑地址需要全部映射到物理内存上。映射的最小单位如果是字节的话,映射表将会非常大,且效率低下。提出page概念,即最小的映射单位是一个page,一页一般是4K这样的大小,我的机器是这样的,所以下面程序demo中页大小都是4K。
显然逻辑空间可能比实际要大,但是只要程序没有用那么多内存,就不需要去映射那么多page,且就算用了那么多内存,也可以映射到磁盘上。
逻辑页是抽象的,需要映射到物理的页上,才能完成对内存的操作。我们把逻辑页叫页(page)物理页叫帧(page frame)。页号-帧号的映射表叫页表(page table)。
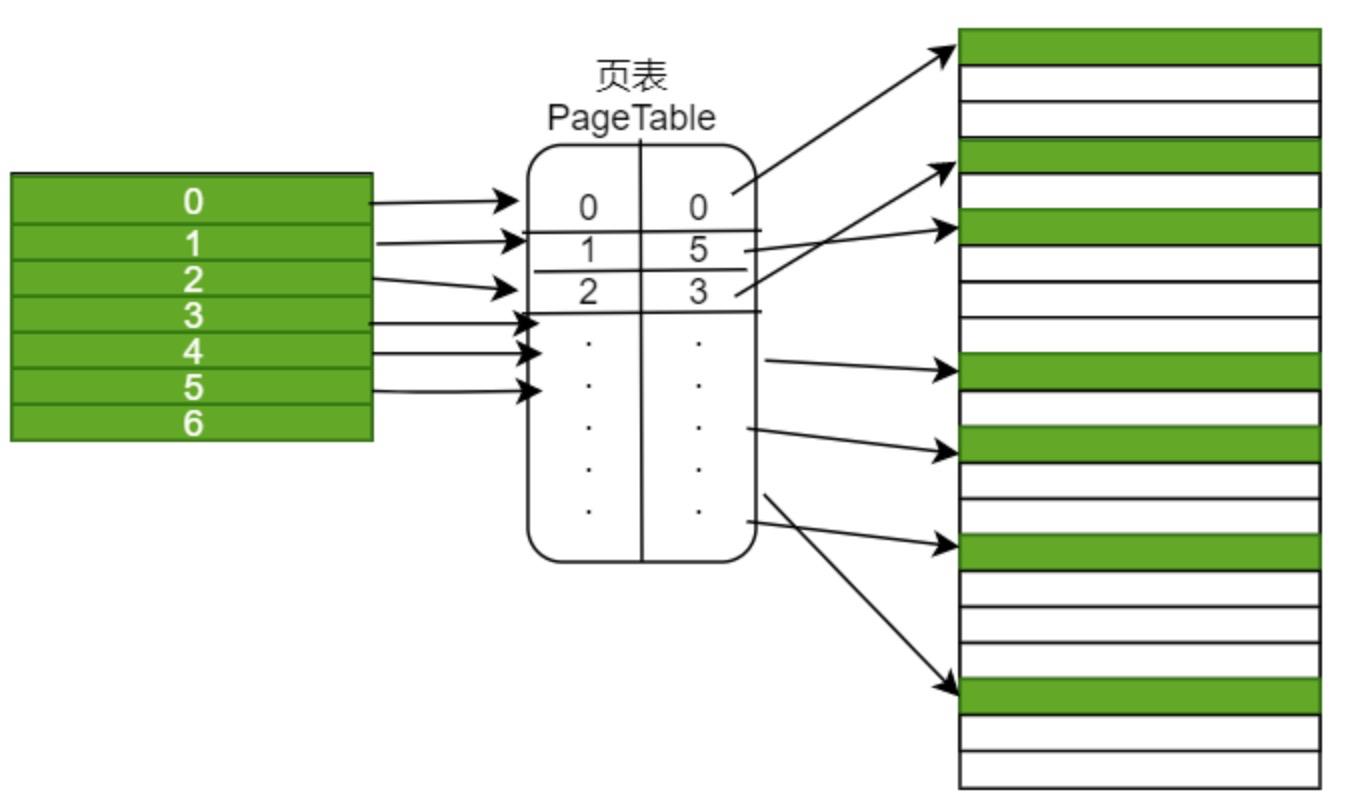
图2-1 页表映射
因为每个程序看到的逻辑地址空间都很大,所以程序变多了之后,程序使用的内存大于了物理内存,此时一般通过将部分"不着急使用"的页映射到磁盘的方式来解决。所以页表中映射项可能是磁盘。
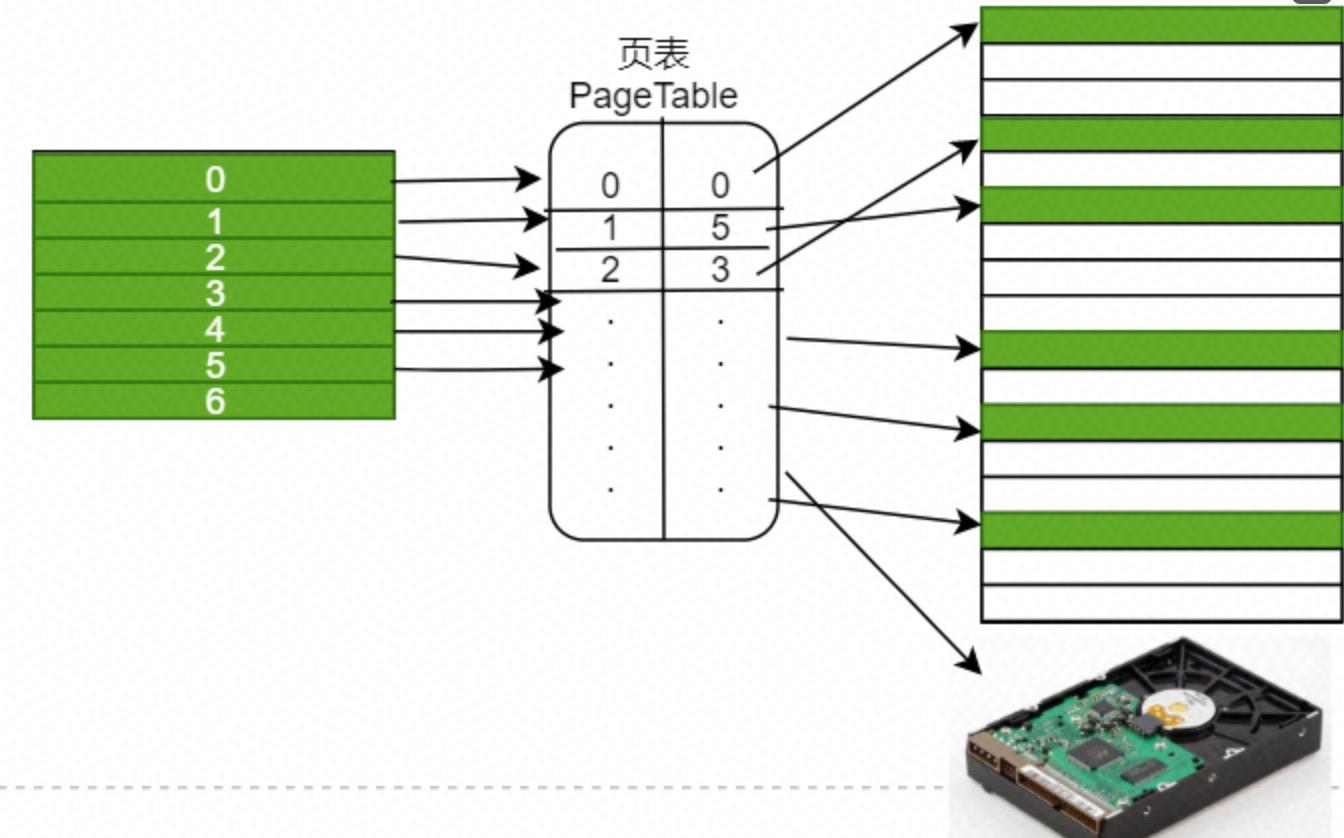
图2-2 页表映射
同时每个进程都有自己的专属页表,如下:
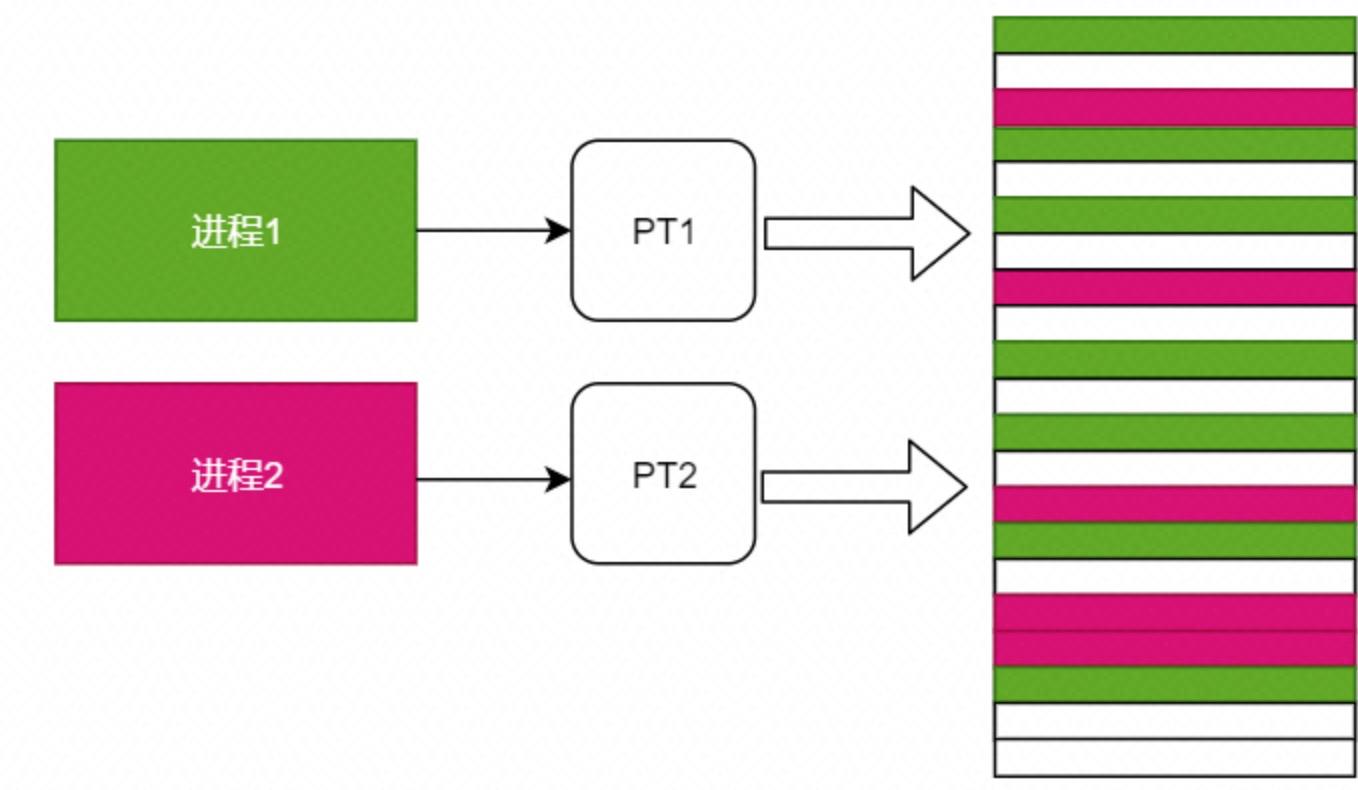
图2-3 多进程的页表
一种实际情况,4G逻辑地址有32bit地址空间,假设pageSize=4K偏移量占12bit,因而页表的逻辑页号有20bit。再假设实际内存条只有256M 28bit地址空间 12bit偏移量 16bit页号。
逻辑地址0x 00001 1a3,去映射的时候00001就是逻辑页号,去查页表发现映射到真实页帧号00f3,然后偏移量不变还是1a3,最终就找到这个物理内存内容了。

图2-4 页表的映射过程
这个过程中,可能会出现映射的帧号是disk,即映射到了磁盘上。此时会触发缺页异常,进入内核态,内核从磁盘中读取缺的这页内容,将其加载到物理内存中。但是物理内存的帧有可能所有帧都满了,此时就需要逐出不太"重要"的帧。
逐出的过程需要判断当前物理页(帧)是否是脏的(脏:与磁盘中内容不一致,即从磁盘加载到物理内存后被改过就是脏的),如果是脏的还需要更新磁盘中的内容保证一致。
逐出后就腾出了位置给从磁盘中读到的这页的数据,然后需要更新页表的这一项的映射关系,将磁盘改为帧号,然后重新进行查页表这一步。
逻辑层的作用:极大的降低了内存碎片;借助磁盘可以实现"无限的内存";各个进程间内存的安全性等。
一个地址中“住”的是一字节(8bit)的数据。
2.2 快表TLB、多级页表
上面提到了逻辑-物理页的映射,这就是页表,但是上面的页表其实除了简单的页号映射,还存储了其他一些属性:是否有效,读写权限,修改位,访问位(淘汰算法和TLB中用),是否是脏(被修改过就是脏的,因为他和硬盘上的数据不一致),是否允许被高速缓存等等。
页表存于主存中,每个进程都有自己的页表。
上面可以看到基于页表的寻址,需要两次访问主存(页表是存在主存的),效率低下。为了提高速度,引入了快表,快表是页表项的缓存,将最近一次的映射项存入快表,因为空间有限所以需要逐出最老的那一项。快表的设计是基于经验:程序经常访问的page一般就那几个,不会经常频繁的更换特别多的页。
快表可能存于硬件MMU中(也可能是软件TLB),一般只有8-256条,每个进程都有自己的快表。
另一个值得讨论的话题是页表占用空间太大,上面例子中(32位程序256M机器pageSize4K)页号有20bit即2百万个,所以需要有1百万条,每条大小如果只算逻辑页号(20bit)和物理页号(16bit)的话:
36bit * 2^20 = 4.5MB如果有64个这样的程序在运行...后果可想而知。
一种很好的解决方法是多级页表,第一级页表用于寻找第二级页表的编号。<20bit-16bit>的单级映射可以改成<10bit-10bit>和<10bit-6bit>两级映射。此时占用内存为
20bit * 2^10 + 16bit * 2^20 = 2M2.3 分段
严格意义的分段是,每一段的虚拟地址都是从0开始。然后页表是段号+页号来映射帧号的。但是这种形式已经被废弃了,只有x86 32位的intel的cpu还保留了这种段页结合的方式,即严格意义的分段已经用的很少。
那为什么还经常听到段的概念?现在所说的段一般是程序在逻辑层面保留的概念,对逻辑地址有个粗略的划分,便于程序编写,但是并不影响os的内存管理(还是分页管理)。
以32位程序为例,在逻辑空间中最高的0xc0000000 - 0xffffffff这1G的内存是给内核留出的,这部分是所有进程共享的。剩余3G内存从低到高分别是Text、Data、Heap、Lib、Stack。64位程序则远大于这里的值。
Heap是从低往高增长,Stack是从高往低增长,且有个最大限制。Data存储静态变量Text存储程序二进制码,Lib存储库函数需要占用的内存,多个程序如果都使用了相同的库,内存是共用的(共享内存)。各个部分的留有随机的一段偏移量,可以保护程序,这也使得每次重新执行程序的时候变量所在的内存地址总是不同的。
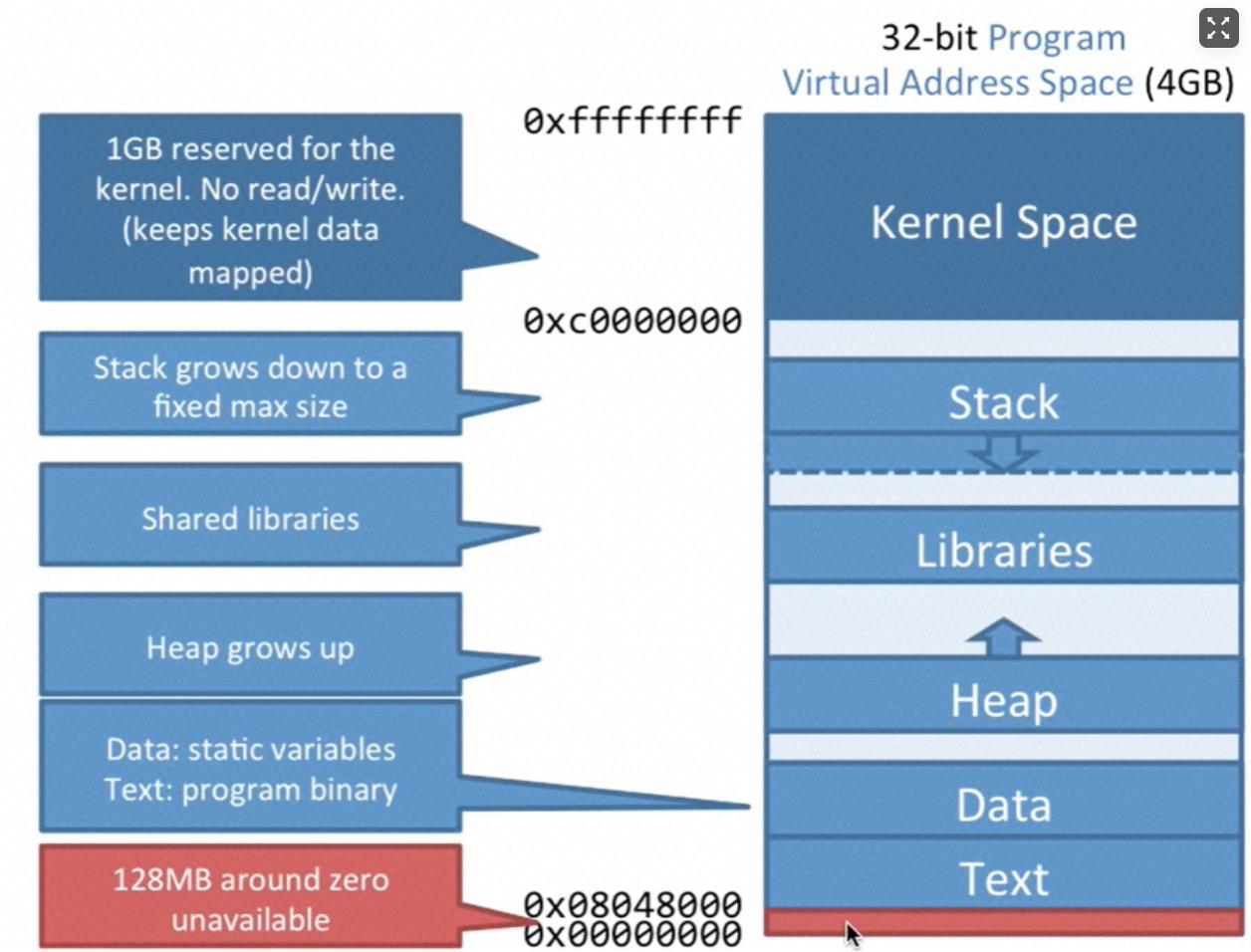
图2-5 32位系统下内存地址的组成
分段是逻辑空间上的,不影响分页的内存管理方式,后面进行分页,映射到物理内存上各部分跨多个页其实并不连续。
2.4 cache
cpu的三级缓存扮演着缓存主存数据的作用,而cache在内存管理中的位置是怎样的呢?
PIPT,物理级cache,cpu分析完映射关系,先到cache找有没有该物理地址的cache。这样会非常的慢,但是所有进程可以共享cache。
VIVT,逻辑级cache,cpu直接通过逻辑地址找cache,miss后再查TLB页表这些。这样很快,但是逻辑地址只能对当期进程使用,其他进程完全不能复用,尤其是库函数这种共享的不能利用好cache。
VIPT,将两者结合,用逻辑地址查找cache,cache中数据部分前面添加一个对应物理地址的tag。这样拿到这个tag后到tlb、页表中查看下这个对应关系是否正确,如果正确就直接读cache。这样速度和共享性都是折中的。
以上三种方式各有优劣,在不同的cpu中可能使用的不一样。
2.5 内存地址大小
很多人想当然的会认为32位系统的虚拟地址是32位,这是没错的,但是64位系统下真正的可用的虚拟地址却不到64位。
#include <stdio.h>
int main()
int x = 10;
printf("%p",&x)

图2-6 C语言打印地址
明显看到是48位,虽然这个指针大小是8byte,但是只有48bit是有效的地址位,前面是多个0。通过cat /proc/cpuinfo最后几行能看到物理地址和虚拟地址的大小,这主要是cpu单方面定制的,我的这台机器是13年买的intel 酷睿i5 3230的CPU。当然我的系统内存只有2G,其实物理地址不会有43位,只是cpu最多支持43位物理地址。
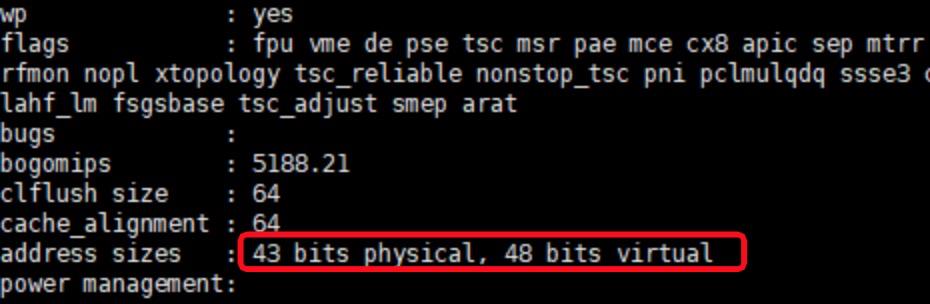
图2-7 cpuinfo中的虚拟地址和物理地址
小细节:栈是仅次于内核的高位地址,参考图2-5. 所以看到前面这个地址基本能推算出分给内核的虚拟空间应该是0xffff ffff ffff - 0x8000 0000 0000。
2.6 内存分类
在生活中我们经常看到各种内存的种类,比如在linux调用free -h的时候可以看到图2-6的分类。
在linux中通过free -h可以看到当前系统的内存情况:

图2-8 free指令下的内存分类
mem是物理内存,swap是交换分区,是用来将内存暂时放到磁盘上的。
total总内存大小,used用户使用的内存大小,free空闲的内存大小,shared共享内存大小,buff/cache文件缓存大小,available可用内存大小是free和buff/cache加起来。
total = used(含shared) + free + buff/cache这里需要理解buff/cache,他们在老一些的内核中是分开显示的分别是buffer cache和page cache,都是对磁盘的缓存。其中buffer cache是硬件层面,对磁盘块中的数据进行缓存,缓存的单位当然也是块。而page cache是文件系统层面,对文件进行缓存,缓存单位就是页。buffer cache的提出非常的早,两者并存时会遇到重复缓存了相同的内容的情况。
较新的内核已经将两者合并,或者说将buffer cache合到了page cache。虽然也还是能缓存磁盘块,但是存储单位也是页了。并且buffer使用前会先检查page cahce是否已经缓存了对应内容,如果是则直接指过去。在机器维度查看内存的时候也能发现BufferCache都是0,因为都合到了pageCache,有Buffer的都是很老的内核的机器。
buff/cache占用大,会不会影响后续程序申请内存?
不会,一旦用户程序需要申请内存,buff/cache就会释放掉一部分。换句话说buff/cache是在内存比较空闲的时候,尽量利用一下来加速文件读写的。如果有大哥需要用内存,是会拱手让出的。
如果想进一步了解两者的演化,这篇文章从内核源码的角度展示了,几个理成本版本下buff cache 和 page cache的变化。
在windows任务管理器中又可以看到下图的几种状态的内存叫法,而在Jprofile查看jvm内存的时候也有图2-8的一些叫法。
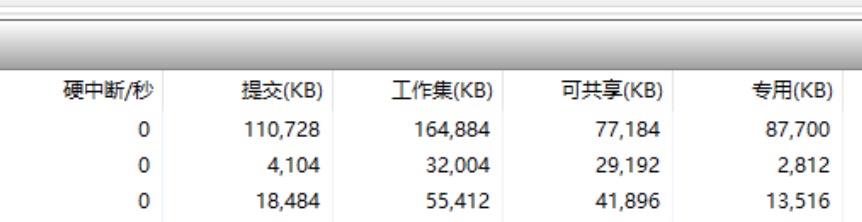
图2-9 windows任务管理器内存分类
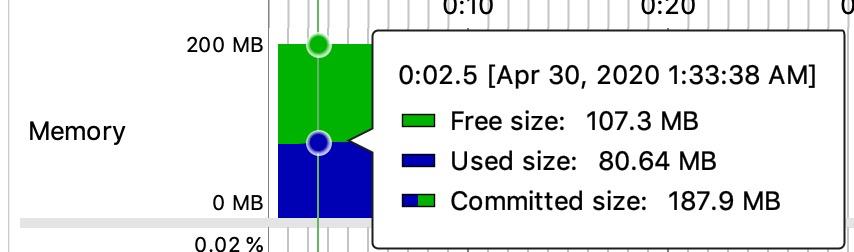
图2-10 jprofile内存分类
已提交的意思是已经向操作系统申请了这么多的内存,操作系统可以已经给了这么多内存了,但是也可能没有给那么多。贴一张微软自己的解释如图

图2-11 几种内存的解释
提交的内存因为是虚拟内存,并不一定系统会立刻给这么多,所以可能提交远超过物理内存上限的大小。我之前看过一个视频,小哥用malloc申请了130000+GB的内存程序才退出,而如果在malloc后给申请的地址填写值,事情就不那么顺利了。感兴趣可以去看下这个视频。当然不了解C语言也没关系我在本文后半段会用java的Unsafe同样申请超过物理上限的内存大小做demo。
3 内存相关的系统调用
3.1 内核态和用户态
内核态、用户态、内核空间、用户空间,是经常说起的概念。因为操作系统不允许用户直接操作硬件,所以需要用户程序通知内核,内核帮你下达指令给硬件。在进行读文件的时候,就需要用到磁盘这个设备,所以需要进入内核态,将文件内容读到内核buffer,然后拷贝到用户buffer并从内核态切换为用户态,程序才能真正拿到数据。
用户态进内核态,一般有三种触发条件,中断、异常和系统调用,中断和异常有时候界限比较模糊,例如缺页中断也有地方叫缺页异常。这里我们引出了系统调用,大多数需要主动操作或读写硬件的都是通过系统调用。例如读写文件的open/read/write是系统调用,网络传输常见的select/poll/epoll也是系统调用,申请内存的malloc底层也是通过brk或mmap这俩系统调用实现的。
系统调用伴随了很多设计的优化,例如通过epoll等系统调用实现的IO多路复用提高了网络包的处理效率,mmap、sendfile等系统调用实现的零拷贝,减少了用户空间和内核空间之间的数据拷贝和上下文切换次数等等。在java的NIO中有大量的函数是直接封装了系统调用。
3.2 brk
malloc小于128K(阈值可修改)的内存时,用的是brk申请内存。C语言中sbrk(可函数)是brk(系统调用)的简单封装,下面代码打印的值可以看出first因为申请了0大小,所以和second指针位置相同。而third则表示的是second的尾部地址。可以看到虚拟地址是连续分配的,brk其实就是向上扩展heap的上界,配合查看图2-5。
#include <stdio.h>
#include <unistd.h>
int main()
void *first = sbrk(0);
void *second = sbrk(1);
void *third = sbrk(0);
printf("%p\\n",first);
printf("%p\\n",second);
printf("%p\\n",third);
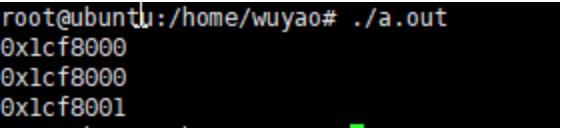
图3-1 brk代码输出
如果此时在 third+1地址处去初始化一个int值,是可以成功的,并不报错。
#include <stdio.h>
#include <unistd.h>
int main()
void *first = sbrk(0);
void *second = sbrk(1);
void *third = sbrk(0);
int *p = (int *)third+1;
*p = 1;
这是因为页大小是4K,sbrk(1)其实也是申请一页,所以third+1位置也是安全的。如果我们将second这行改为4096,那就是另一个故事了,会触发段错误。
void *second = sbrk(4096);
图3-2 brk代码输出2
3.3 mmap
malloc大于128K的内存时,用的是mmap。
// addr传NULL则不关心起始地址,关心地址的话应传个4k的倍数,不然也会归到4k倍数的起始地址。
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
//释放内存munmap
int munmap(void *addr, size_t length);mmap用法有两种,一种是将文件映射到内存,另一种空文件映射,也就是把fd传入-1,就会从映射区申请到一块内存。malloc就是调用的第二种实现。
#include <stdio.h>
#include <unistd.h>
#include <sys/mman.h>
int main()
int* a =(int *) mmap(NULL, 100 * 4096, PROT_READ| PROT_WRITE, MAP_PRIVATE| MAP_ANONYMOUS, -1, 0);
int* b =a;
for(int i=0;i<100;i++)
b = (void *)a + (i*4096);
*b =1;
while(1)
sleep(1);
这里提交400K内存的申请,并且在每页中都进行内存的使用。可以看到不映射文件的话触发的是minflt次数是100次。
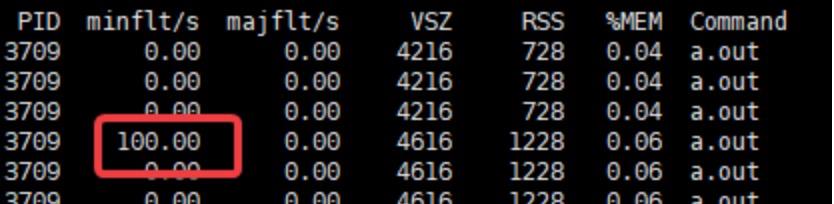
图3-3 进程的内存minflt
这里是mmap内存的惰性加载,一开始mmap100页时其实都没有分配给进程,在用到的时候开始真正拿到内存,此时触发minflt缺页,因为不是映射的文件,不用从磁盘中调内存,所以是小错误。但是仍是消耗性能的。
如果mmap是映射的磁盘文件,也会惰性加载,在初次加载或者页被逐出后再加载的时候,也会缺页,这个时候就不是小错误minflt了,而是majflt。例如下面使用mmap来读文件。
#include <sys/types.h>
#include <fcntl.h>
#include <sys/mman.h>
#include <stdio.h>
#include <sys/stat.h>
#include <unistd.h>
int main()
sleep(4);
int fd = open("./1.txt", O_RDONLY, S_IRUSR|S_IWUSR);
struct stat sb;
if(fstat(fd, &sb) == -1)
perror("cannot get file size\\n");
printf("file size is %ld\\n",sb.st_size);
char *file_in_memory = mmap(NULL, sb.st_size, PROT_READ, MAP_PRIVATE, fd, 0);
for(int i=0;i<sb.st_size;i++)
printf("%c", file_in_memory[i]);
munmap(file_in_memory, sb.st_size);
close(fd);
下图是线程监听的结果,为了方便观察我在开始读之前sleep 4s。可以看到红框第一行,有一次majflt,这是第一次去读文件,直接触发了缺页异常,且指向磁盘。是最耗时的错误。
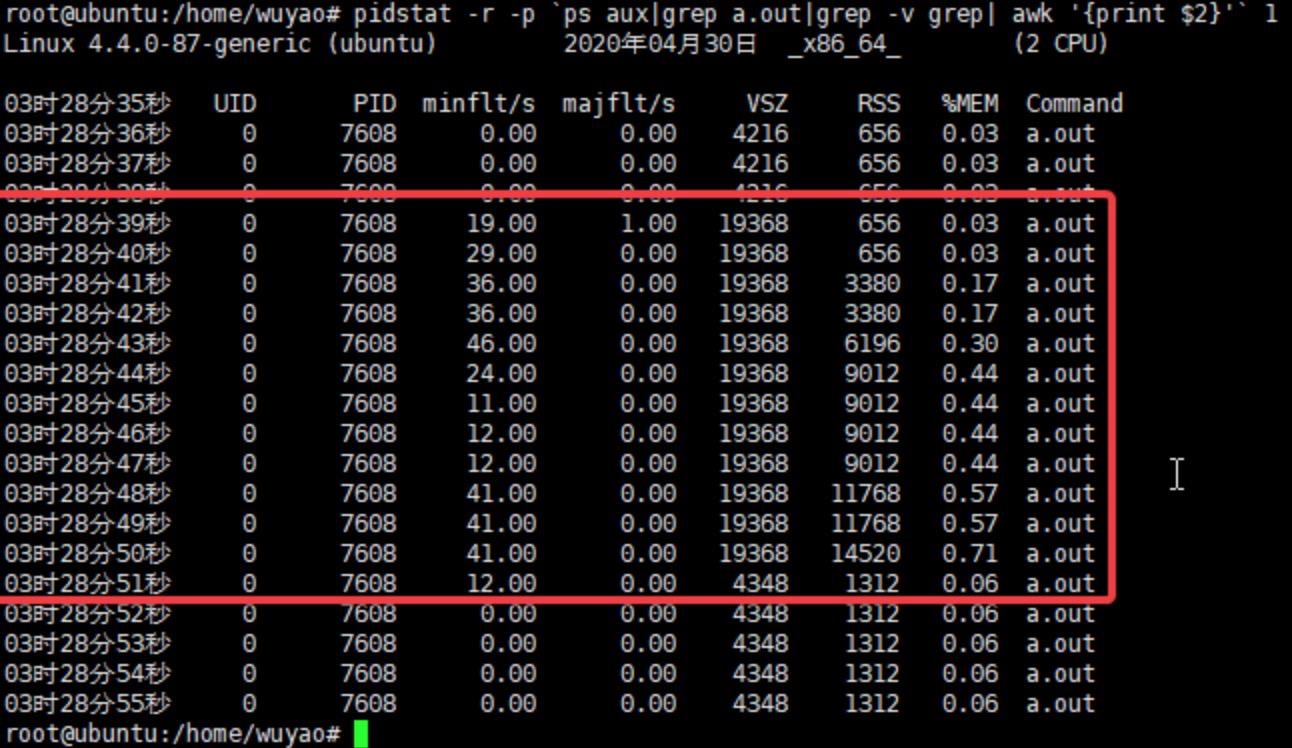
图3-3-2 进程mmap读文件引发majflt
read和mmap都可以读文件,前者有状态转换和多次拷贝,但是后者有缺页中断。在单纯读磁盘文件场景,两者其实没法在孰优孰劣上有定论。
3.4 共享内存
共享内存是进程间通信的一种方式,(管道 信号 信号量 套接字也是进程通信的方式)。共享内存的例子比比皆是,windows下最明显,比如这个上传文件的对话框就是共享内存里的,同一时间windows下不会弹出两个该对话框。再比如动态链接库,也是共享内存中的,多个进程可以共享,两个进程mmap相同文件的方式可以实现共享内存,shmget则是更广泛的共享内存的系统调用。
图3-4 共享内存的典型例子
共享内存原理就是两个进程中页,映射到了相同的帧。代码这里不写了,直接参考geeks这篇的代码。
4 java中的内存
4.1 java内存概述
jvm内存结构主要如图4-1.本文不想对“常考”的知识点再次进行讲解,网上有大量的文章来讲内存结构各自的用途和GC相关的内容,这里我就不展开讲了。下面几节会讲一些比较"冷门"的知识。
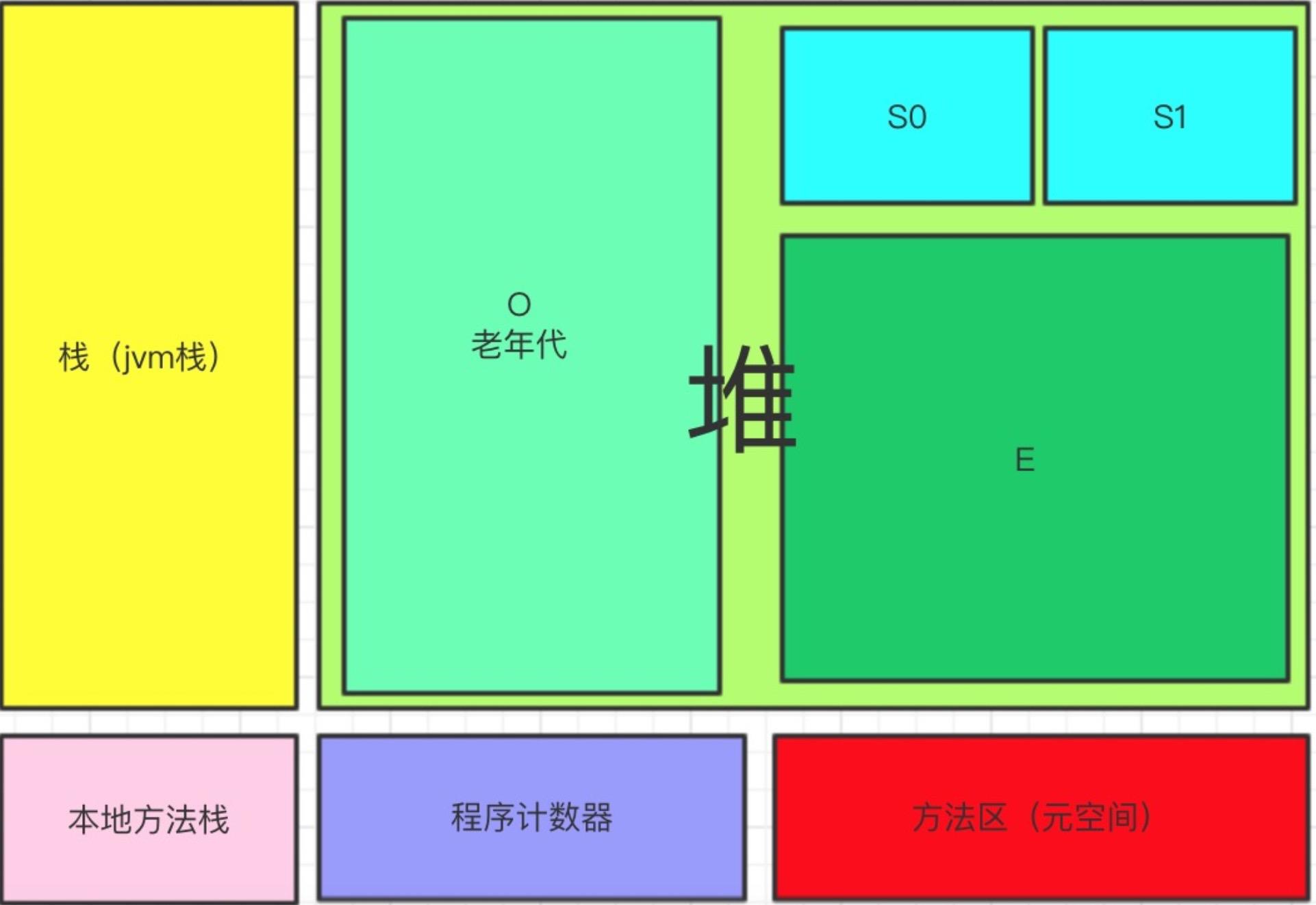
图4-1 java的内存五区
4.2 对象头与指针压缩
在另一篇讲计算java对象大小的文章中提到,java对象是由对象头,对象内容组成,并且是8字节对齐的。其中对象头有以下三部分组成:
- Mark Word(64bits) 当前对象一些运行时数据如锁
- Klass Word(开压缩32bits,不开64bits) 类型指针,指向类元数据Klass地址
- array length(32bits) 数组对象才有
我们这里来看下Klass,有没有想过我们反射的时候操作的都是Class对象而不是这里的Klass,两者关系是:
Klass是C++对象InstanceKlass,里面有个_java_mirror字段指向对应的Class对象。
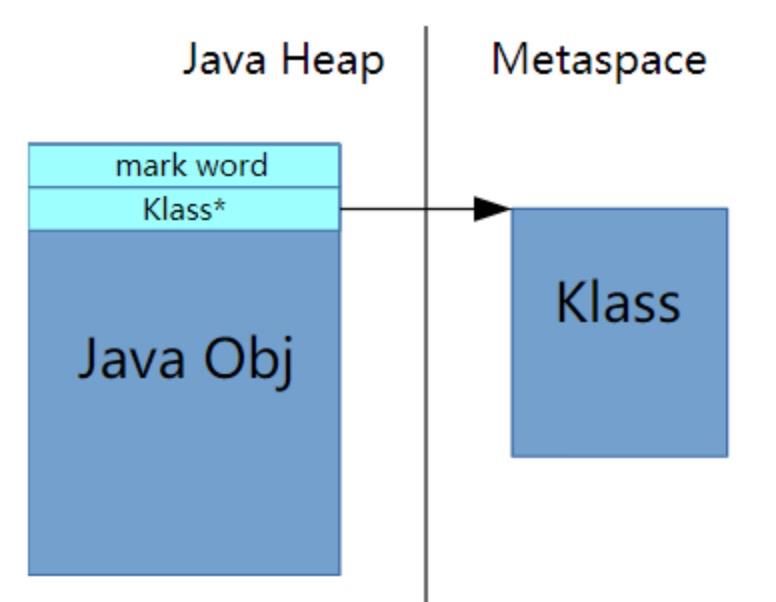
图4-2 java对象头指向metaspace
这里还提到了指针压缩,64位系统,如果jvm堆内存小于32GB是可以开启指针压缩的,此时Klass指针只需要4个字节,同时对象指针也只需要4个字节。这里会衍生出两个问题:
第一个就是4字节最多表示2^32个地址,每个地址里住的是一个字节,所以只能表示4GB,怎么还说32G下都能压缩呢?
因为:上面提到对象都是8字节对齐,所以每个地址里住的是8字节,所以可以表示32GB,实际地址移3位。
第二个问题就是普通对象指针压缩Compressed Object Pointers (“CompressedOops”),压缩的是java堆上的对象的指针(引用)大小,而对象头指向的是Klass,这是个C++的结构,这个指针也压缩了吗?
是的,CompressOops和CompressKlass是相伴而生,默认同时开启的,Klass这部分需要连续的<4G的内存,因为是C++结构,没有8字节对齐限制,所以4字节只能在4G内存上寻址,默认大小是1G。
4.3 metaspace
metaspace存储的是类的元数据信息,上面提到的Klass就是在metaspace中的,一般开启压缩的metaspace有CompressClassSpace和NonClassSpace两部分组成,其中前者内存占用较少,是后者的5-100分之一,前者又叫压缩类空间,实际上这部分内存本身并没有压缩,只是对象头中记录的指向这里的指针进行了压缩。
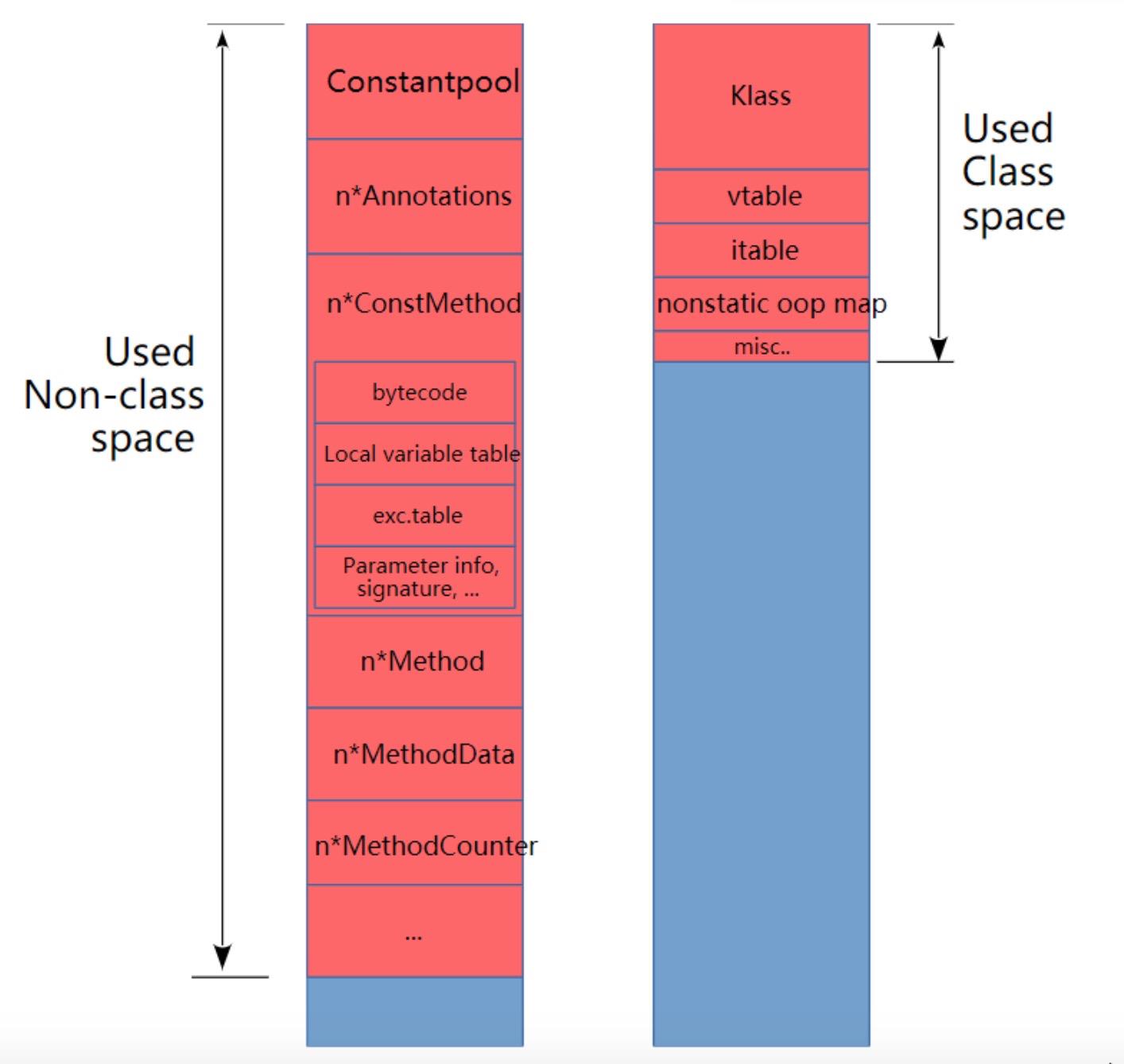
图4-3 metaspace两部分:非类区和压缩类空间
压缩类空间中Klass是c++的对象有着很多元数据字段,vtable是记录虚方法指针,itable是接口方法指针。Non-class中则记录了更详细的元数据信息。开启指针压缩后,如果设置MaxMetaspaceSize参数实际上是限定的Non-class部分的大小,而不包括压缩类空间。通过Jprofile中也能发现Metaspace只包括Non-class部分,那为什么我上来说Metaspace有两部分呢,主要是从概念上讲两者都是元数据,在国外很多文章中也都归为了Metaspace。这里只需要注意这个小细节就可以了。设置MaxMetaspaceSize参数也可以对压缩类空间起到间接的限制,因为前面说了Non-class部分是class部分的n倍。
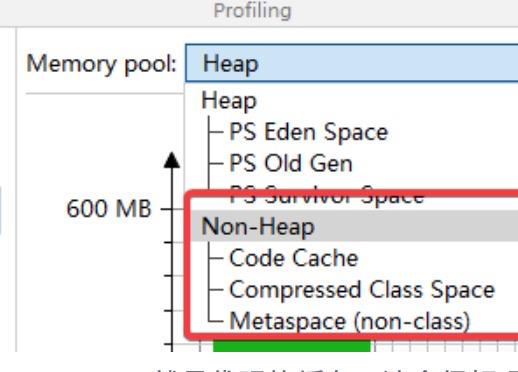
图4-4 指针压缩开启时 非堆
将压缩类空间和非类空间分开的原因之一,就是压缩类空间是对象关联的,只有4G上限,而将更多其他元数据剥离出去后,元空间可以远超过4G。而如果不开启指针压缩,其实两者就没必要分开了。关闭指针压缩后,-XX:-UseCompressedOops 两部分会合为一个。统称Metaspace
图4-5 指针压缩关闭时非堆
Q1:元空间内存什么时候分配?
一个新的类在需要被加载的时候,会使用ClassLoader在元空间申请内存,并存储类的元数据信息。
Q2:元空间什么时候释放内存?
元空间的内存是ClassLoader持有的,所以说只有对应的ClassLoader卸载掉的时候才会释放。ClassLoader又是需要他所加载的类都消失的时候才能消失。一般是伴随在一次GC的过程中进行这个释放。另外元空间如果超过了上限也会导致OOM。
Q3:metaspace溢出会不会导致OOM?
当然会导致OOM,所以metaspace限制大小的配置,需要根据程序谨慎定制。一般通过不断创建新的类,如加载新类(如hsf配置中下发groovy文件就会动态的加载新的class),或者动态代理类(spring中的增强类都是动态代理类)都会导致metaspace的增长。
<dependency>
<groupId>cglib</groupId>
<artifactId>cglib</artifactId>
<version>3.2.4</version>
</dependency>//设置metaspace大小:-XX:MaxMetaspaceSize=200m
public class T
public static void main(String[] args)
while (true)
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(Object.class);
enhancer.setUseCache(false);
enhancer.setCallback((FixedValue)()->":)");
enhancer.create();
监视会发现压缩类空间和非类空间都在增大,后者在200M上有道红线,在2分钟左右溢出,程序挂掉,这个程序中压缩类空间大概是分类的六分之一。

图4-5a 压缩类空间
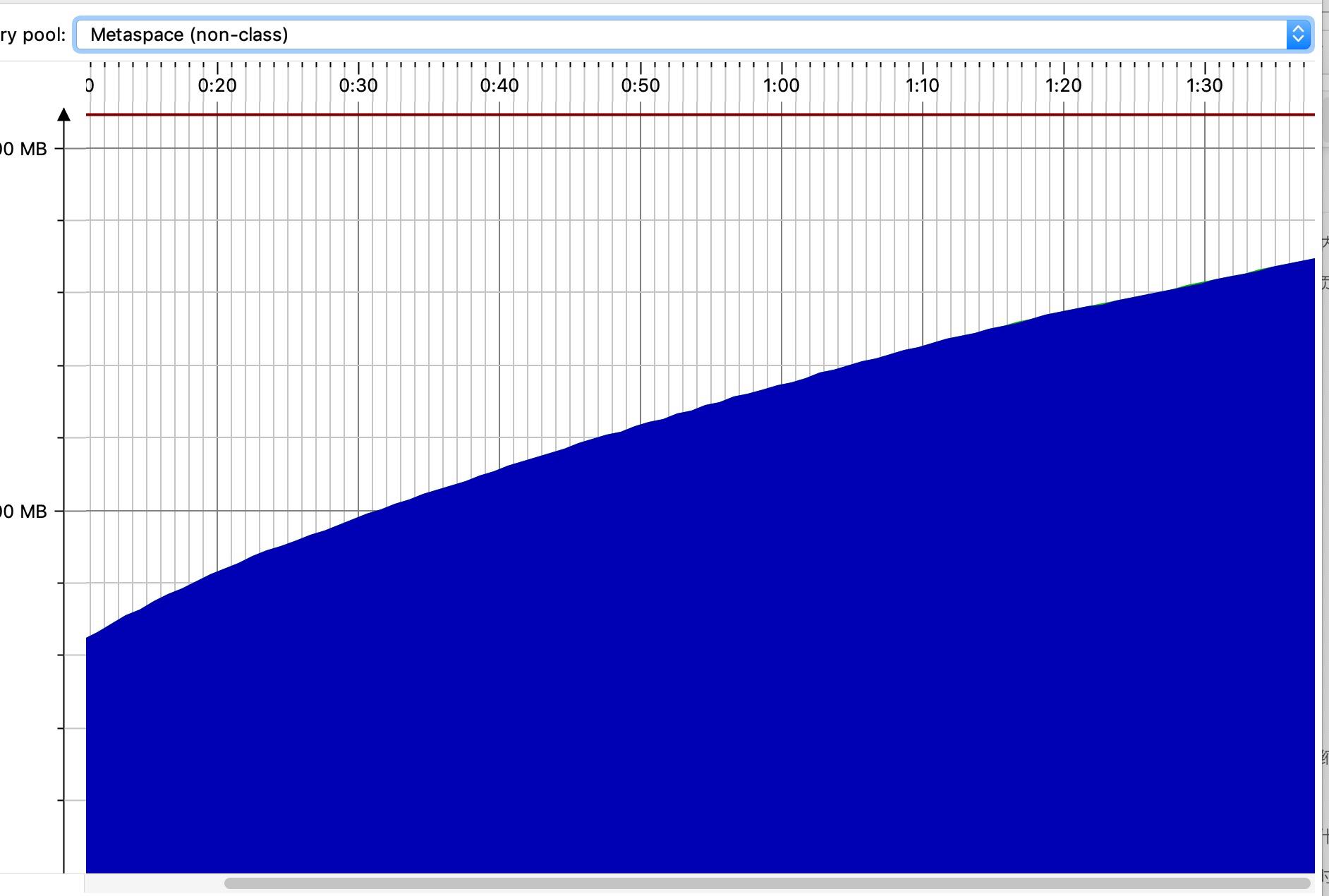
图4-5b 非类空间
4.4 堆外内存
上面的CodeCache和Metaspace毫无疑问是jvm管理下的堆外空间。但是除了这些常规的堆外空间,jvm还可以使用一些native方法,直接申请堆外内存。
例如做这么个demo,我们设置一个简单的java程序的堆大小是10M,此时用jprofile查看内存堆提交了10M实际使用9M多,堆外提交了12M实际使用11M左右。所以算下来是20M+。直接查看进程内存会略大于这个值,因为这个20M是虚拟机内部的内存,本身运行还是需要一些额外内存的,进程提交的内存有90M,实际使用内存47M

图4-6 进程的提交内存和实际内存
接下来我们使用Unsafe申请1G堆外内存(也可以用NIO中的ByteBuffer.allocateDirect())
public static void main(String[] args) throws InterruptedException, IllegalAccessException, NoSuchFieldException
Field f = Unsafe.class.getDeclaredField("theUnsafe");
f.setAccessible(true);
Unsafe us = (Unsafe) f.get(null);
long addr = us.allocateMemory(1024 * 1024 * 1024);
System.out.println("Hello World");
System.out.println(addr);
while(true)
Thread.sleep(1000L);
可以看到提交的内存1G多,实际使用内存也是47M。

图4-7 进程的提交内存和实际内存2
我甚至可以调整申请65G的内存,要知道我的电脑也只有64G的内存,但这仍不会报错,可以看到提交的内存已经超过了物理内存上限,但是得益于前面讲的虚拟内存的管理模式,使得应用申请了超过物理大小的内存,而如果真的使用起来的话,会有页置换来协调。

图4-8 进程可以提交超过现实存在的内存
上面的提交内存很大但是实际使用内存却并不大:
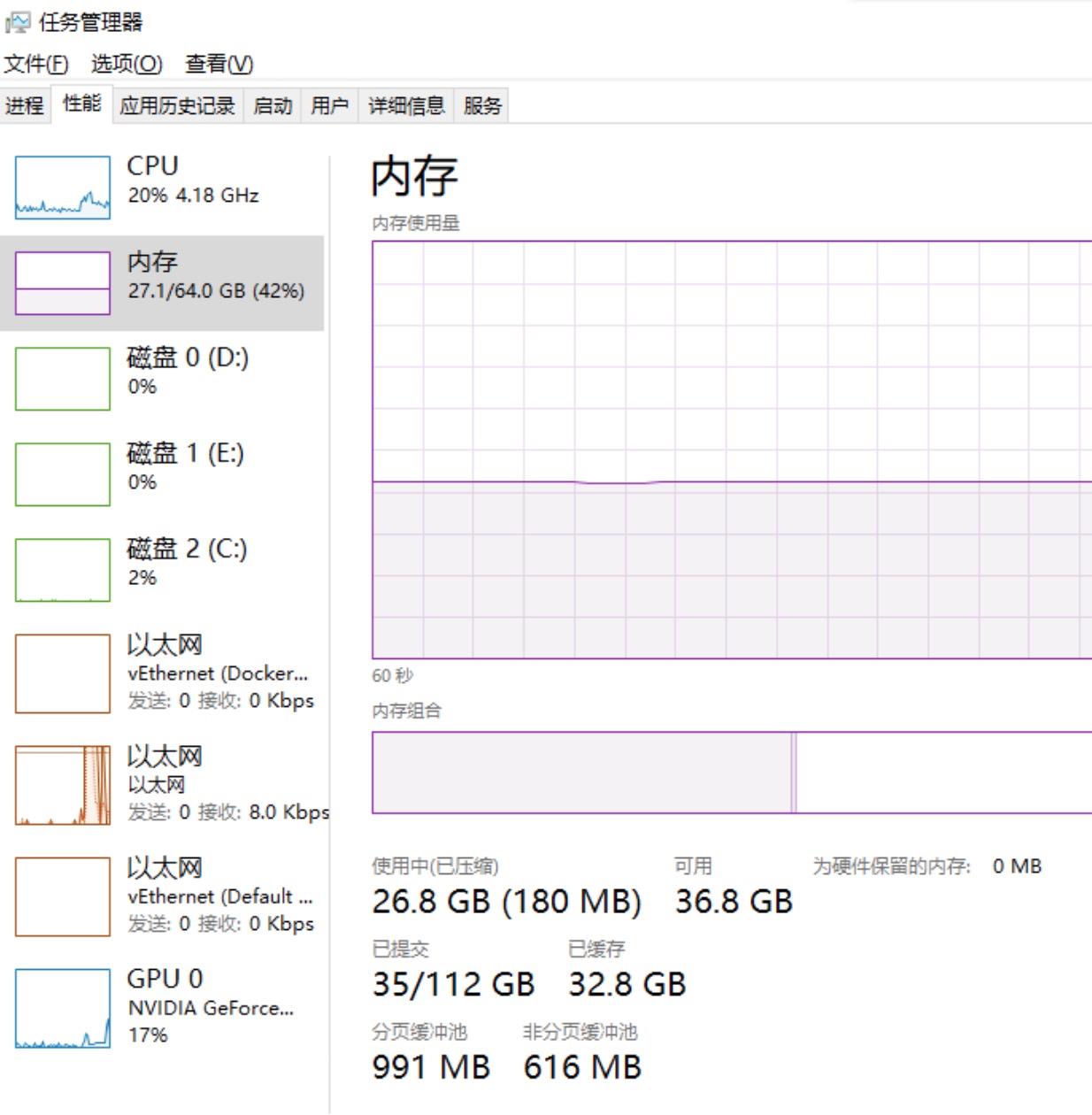
图4-9 任务管理器此时的状态
Unsafe是很危险的一个类,不建议使用。但是可以帮助我们理解有些框架是如何工作的。比如前一阵子看的Ehcache就提供了堆外缓存就是用类似Unsafe申请的。堆外缓存需要自己实现序列化,因为Unsafe设置内存只能设置01字节码不能设置为java对象。
堆外缓存的好处:缓存一般是短时间不需要清理的,如果在堆上则肯定会进入老年代,占用固定的一大块空间,使得触发full GC的门槛降低了,很容易到了那个门限值。而且GC过程中还要去遍历这些对象,效率较低。
堆外内存的坏处:序列化需要自己实现,清理也需要自己实现,访问速度比heap要慢。
以上是关于从下往上看内存的主要内容,如果未能解决你的问题,请参考以下文章
The 2019 ICPC Asia Shanghai Regional Contest---H Tree Partition 二分答案,从下往上切最大子树