PoolFormer解读
Posted 周先森爱吃素
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PoolFormer解读相关的知识,希望对你有一定的参考价值。
这是近期的一篇视觉Transformer领域的工作,文章并没有设计更加复杂的token mixer,而是通过简单的池化算子验证视觉Transformer的成功在于整体架构设计,即MetaFormer。
简介
Transformer已经在计算机视觉中展现了巨大的潜力,一个常见的观念是视觉Transformer之所以取得如此不错的效果主要是由于基于self-attention的token mixer模块。但是视觉MLP的近期工作证明将这个token mixer换为spatial MLP依然可以保持相当好的效果。作者并没有在这方面做过多的探究,而是认为这些工作之所以成功的原因是因为他们模型结构采用MetaFormer这样的通用架构(即token mixer+channel MLP(FFN)),至于具体采用哪种token mixer模块,影响并不是那么大。
-
论文标题
MetaFormer is Actually What You Need for Vision
-
论文地址
https://arxiv.org/abs/2111.11418
-
论文源码
https://github.com/sail-sg/poolformer
介绍
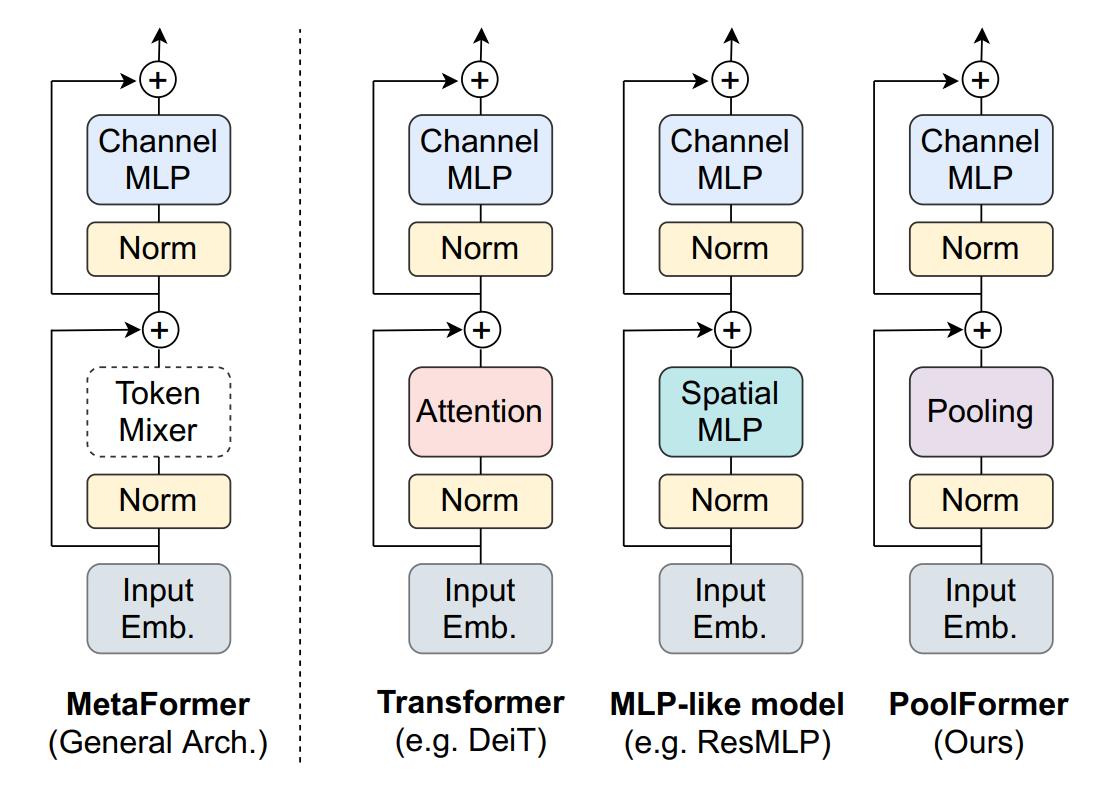
如上图第二幅图所示,Transformer的编码器一般包含两个组件,即一个注意力模块和channel MLP等后续组件,前者用于混合token之间的信息,称为token mixer,后者包括channel MLP和残差连接等。
忽略掉token mixer用注意力模块实现的细节,可以将上述架构抽象为上图第一幅图的MetaFormer架构,后来的一些工作将注意力模块换成了简单的spatial MLP,如代表性的MLP-Mixer,也取得了不遑多让的效果。这也促使了研究者不断探索token mixer的形式,比如最近的工作采用傅里叶变换作为token mixer。
但是,这篇论文的作者并没有在这个思路上越扎越深,而是回过头了做了个总结,竟然各种token mixer效果都很好,那说明这些模型成功的原因应该是整个架构的设计啊,也就是MetaFormer可以保证模型总能获得一个不错的效果。那么自然就会产生一个新的问题了,这个token mixer可以简洁到什么地步呢?
这篇论文中,作者将注意力模块换为了一个没有参数的空间池化算子,原论文对此的描述为简单到让人尴尬。
PoolFormer
MetaFormer
首先,作者对视觉Transformer和视觉MLP等架构做了一个归纳,得到了上图最左侧的通用架构MetaFormer。
首先,输入 I I I呗切分为patch并转换为token,得到序列 X ∈ R N × C X \\in \\mathbbR^N \\times C X∈RN×C,其中 N N N为序列长度, C C C是嵌入的维度。
X = InputEmb ( I ) X=\\operatornameInputEmb(I) X=InputEmb(I)
然后,这个embedding tokens会被送入多个MetaFormer blocks中,每个block包含两个子block。
第一个子blcok通过一个token mixer模块来实现不同token之间的信息交互, N o r m Norm Norm表示某种标准化方法,如LN、BN。 T o k e n M i x e r TokenMixer TokenMixer的形式 就比较多样了,可以是最近的视觉Transformer提出的注意力模块,也可以是视觉MLP采用的spatialMLP结构。需要注意的是,尽管有些token mixer能够混合通道之间的信息,但是token mixer的主要功能还是混合不同token之间的信息。
Y = TokenMixer ( Norm ( X ) ) + X Y=\\text TokenMixer (\\operatornameNorm(X))+X Y= TokenMixer (Norm(X))+X
第二个子block主要由两层MLP和非线性激活函数组成,形式如下。 W 1 ∈ R C × r C W_1 \\in \\mathbbR^C \\times r C W1∈RC×rC和 W 2 ∈ R r C × C W_2 \\in \\mathbbR^r C \\times C W2∈RrC×C是可学习参数。
Z = σ ( Norm ( Y ) W 1 ) W 2 + Y Z=\\sigma\\left(\\operatornameNorm(Y) W_1\\right) W_2+Y Z=σ(Norm(Y)W1)W2+Y
将上述过程的token mixer更换,就形成了主流的视觉Transformer和MLP模型。
PoolFormer
此前的很多工作要么改进了自注意力模块,要么设计了更加精致的token mixer模块,很少有人关注整体架构。这篇论文的作者认为,MetaFormer这种通用架构才是Transformer和MLP模型取得成功的主要原因。
为了验证猜想,作者设计了一个没有参数的空间池化算子来作为token mixer模块,这个池化没有任何可学习的参数,只是用于使得每个token平均聚合其附近的tokens的信息。若输入为 T ∈ R C × H × W T \\in \\mathbbR^C \\times H \\times W T∈RC×H×W,该池化算子数学上表示如下, K K K表示池化核尺寸,减去自身是因为后续有个残差连接会再次加上(为了统一为MetaFormer形式)。
T : , i , j ′ = 1 K × K ∑ p , q = 1 K T : , i + p − K + 1 2 , i + q − K + 1 2 − T : , i , j T_:, i, j^\\prime=\\frac1K \\times K \\sum_p, q=1^K T_:, i+p-\\fracK+12, i+q-\\fracK+12-T_:, i, j T:,i,j′=K×K1p,q=1∑KT:,i+p−2K+1,i+q−2K+1−T:,i,j
该算子的PyTorch风格代码如下,其中池化核和padding的设置是为了输入和输出尺寸不变。

要知道,self-attention和spatial MLP 的计算复杂度与要混合的token数量成平方倍。 更糟糕的是,spatial MLP 在处理更长的序列时会带来更多的参数。 因此,self-attention 和spatial MLP 通常只能处理数百个token。相比之下,池化的计算复杂度和序列的长度是线性关系,且不需要可学习参数。
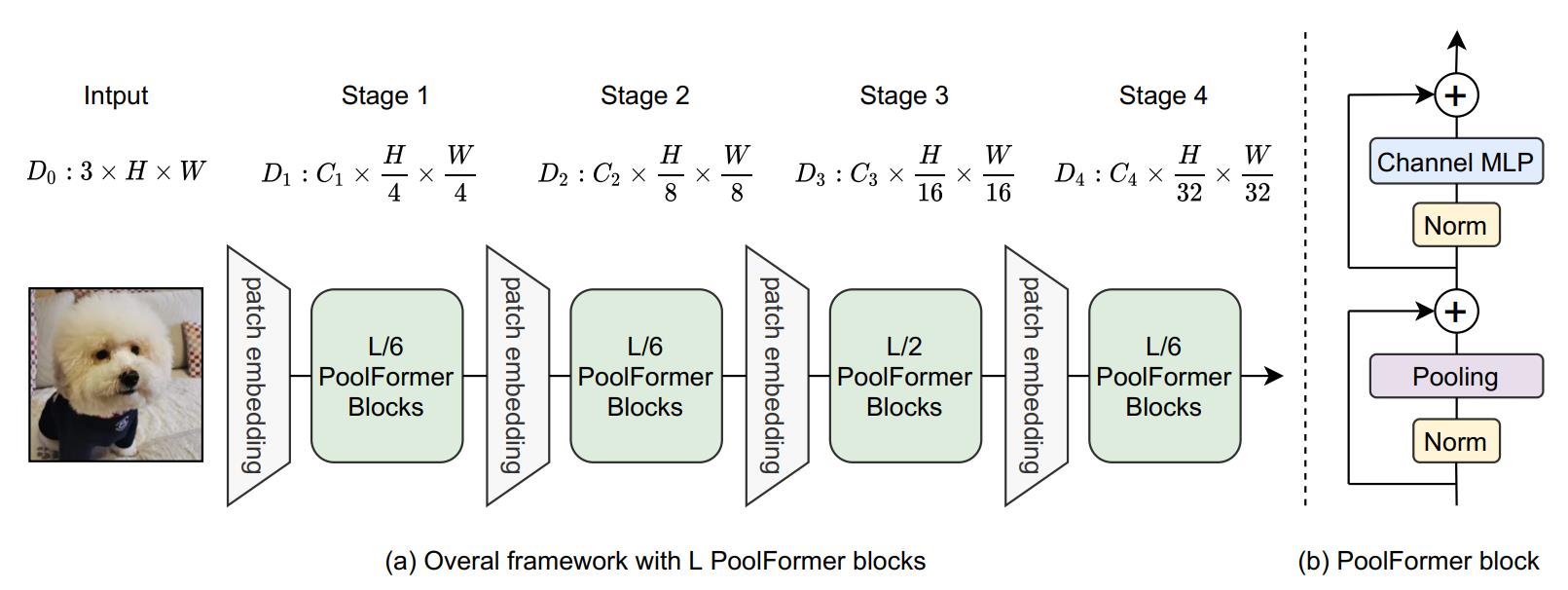
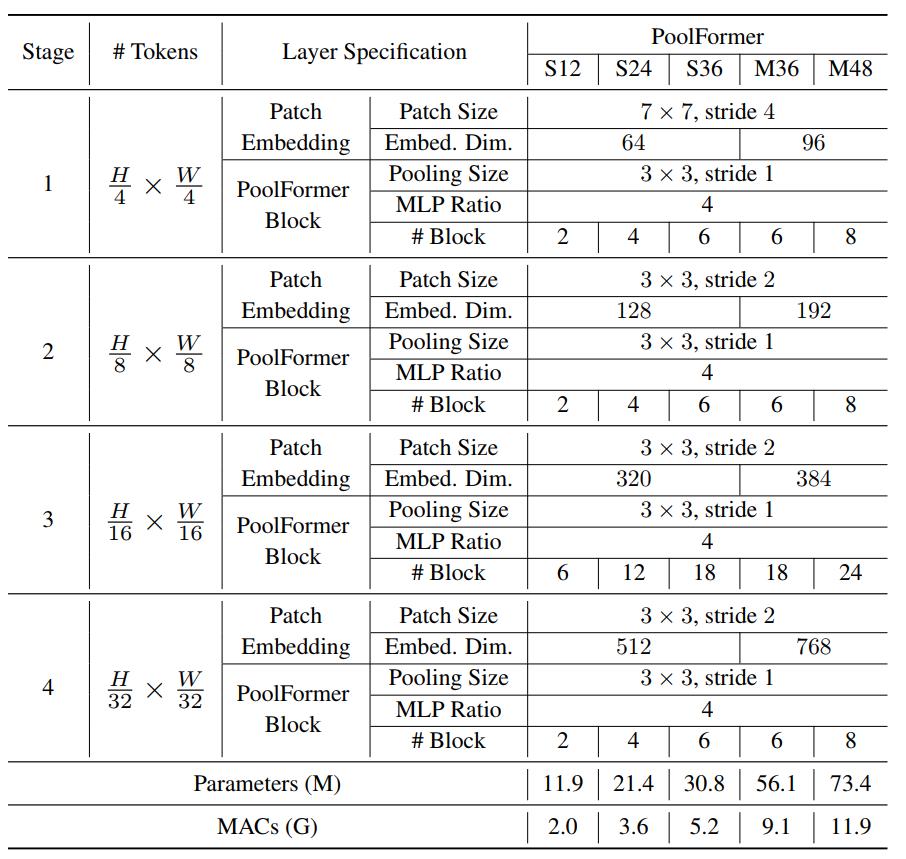
因此,作者以池化为token mixer参考CNN结构和最近的层级Transformer结构,设计了如下图所示的网络,即PoolFormer。它由四个stage组成,每个stage下采样加倍,具体配置见下标。
实验
作者在图像分类、目标检测和实例分割以及语义分割等任务上验证了PoolFormer的效果。
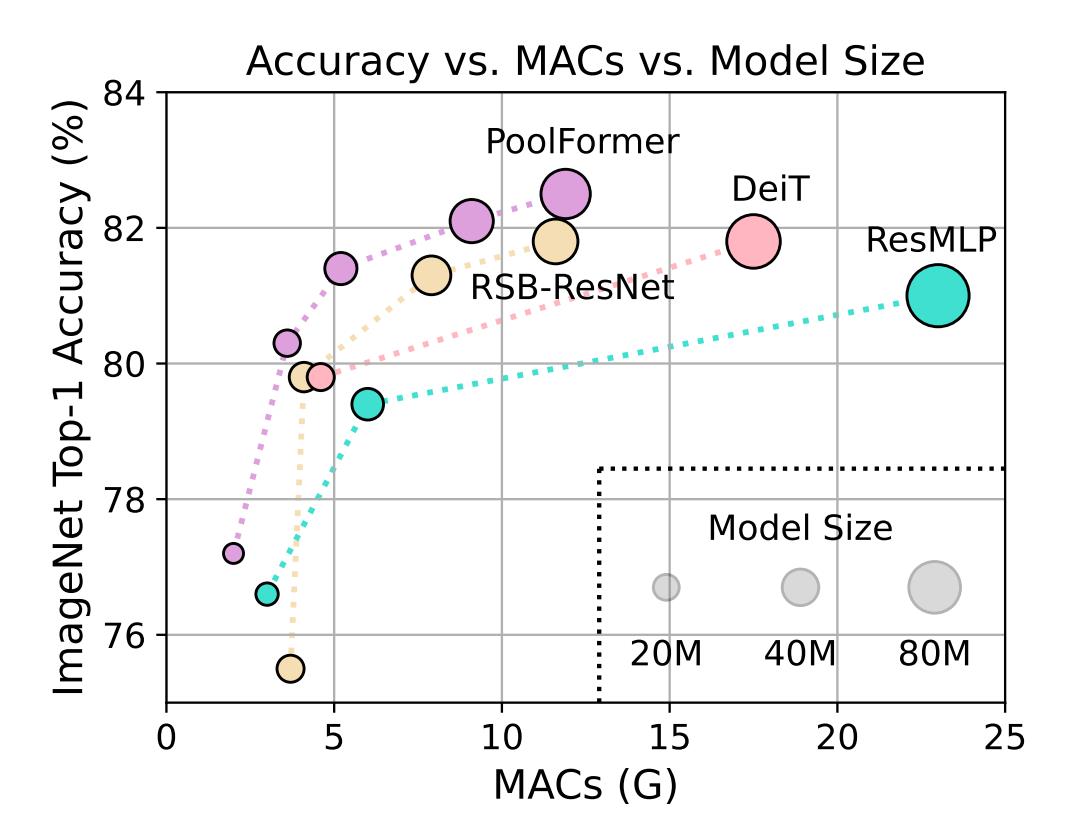
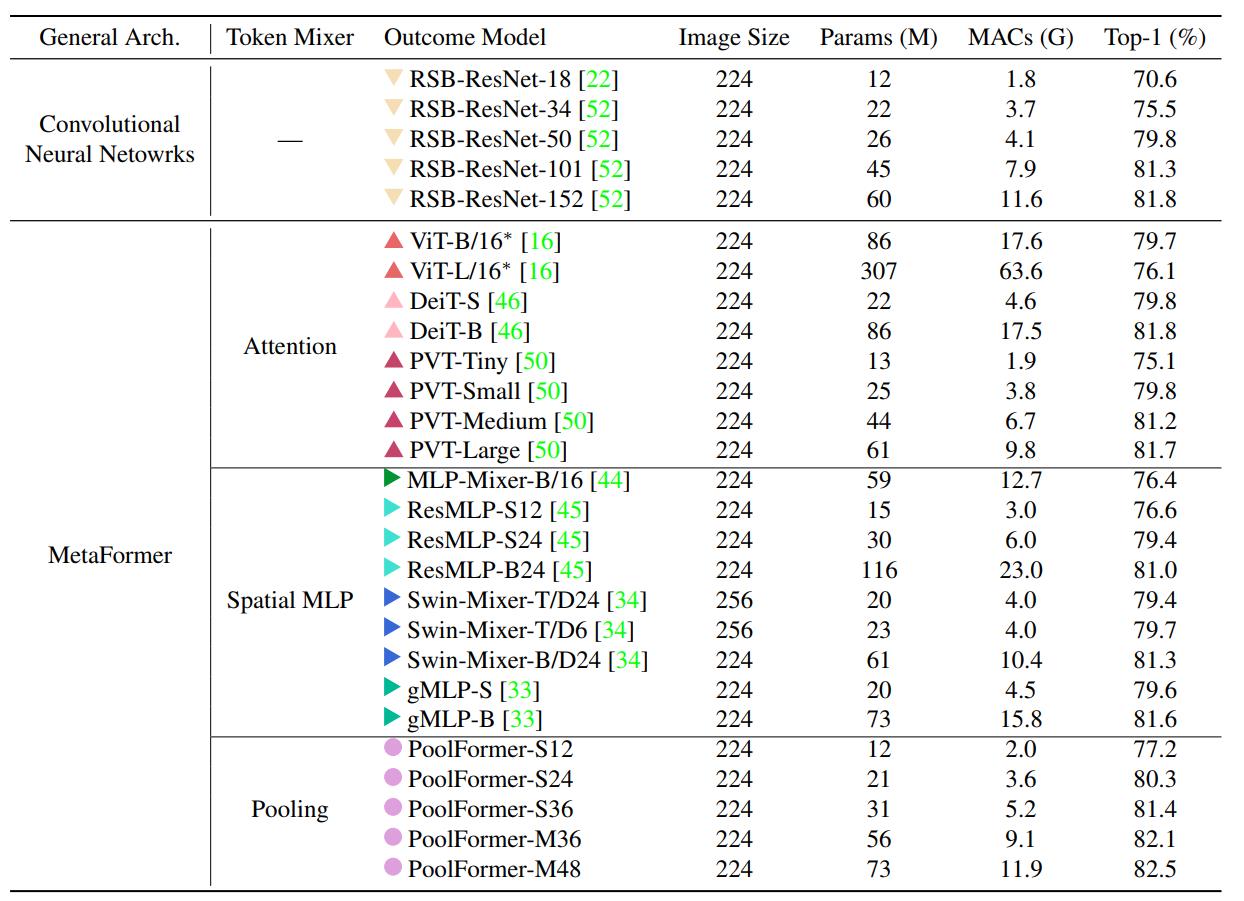
下表是在ImageNet上验证图像分类任务的效果。可以看到,PoolFormer-S24 和 PoolFormer-S36 这样的小模型就可以分别达到 80.3 % 80.3\\% 80.3%和 81.4 % 81.4\\% 81.4%的 Top-1,它们仅仅需要3.6G 和5.2G 的 MACs,超过了几种典型的 视觉Transformer 和 视觉MLP 模型。这说明,即使使用池化这种极其简单的 token mixer,MetaFormer仍然具有很强的性能,说明 这整个架构才是我们在设计视觉模型时所真正需要的。
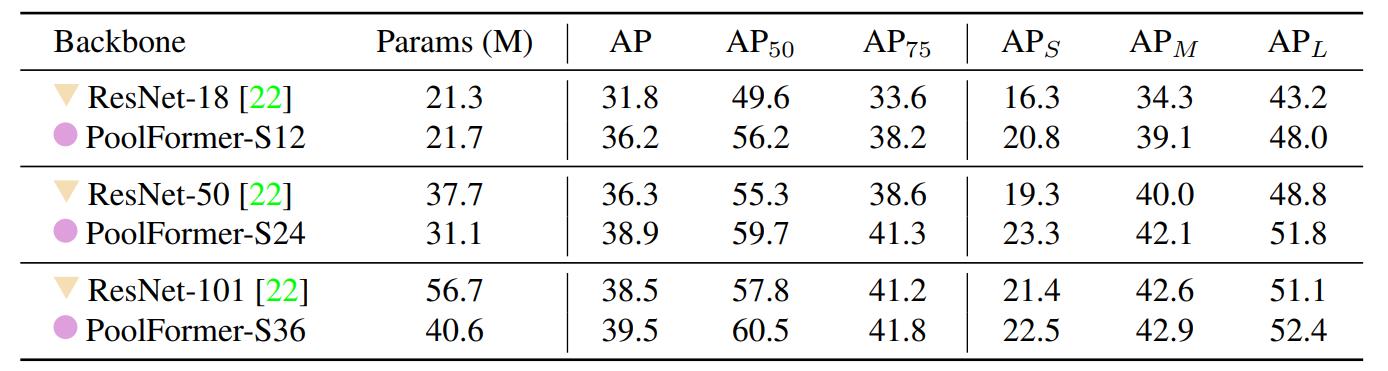
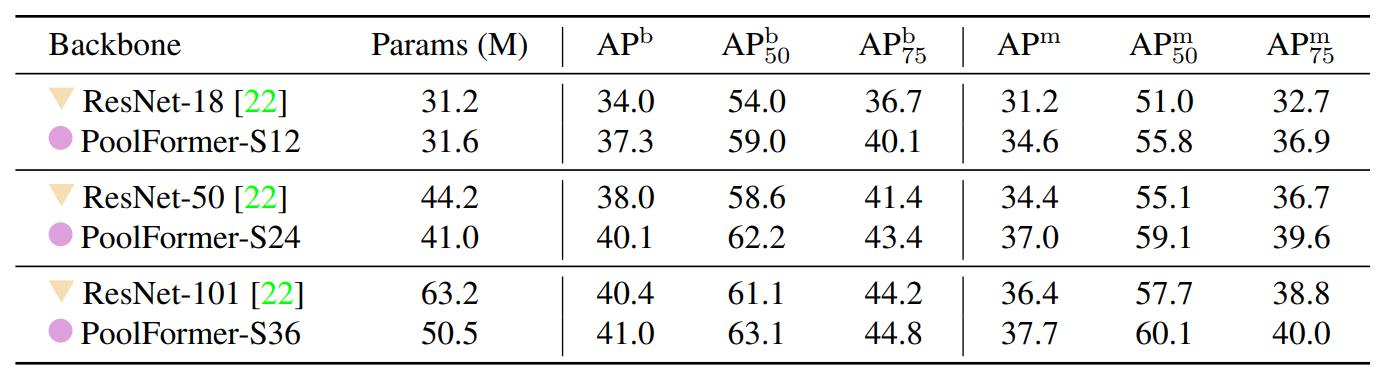
下表是在COCO上目标检测和实例分割的结果,也很能说明问题。
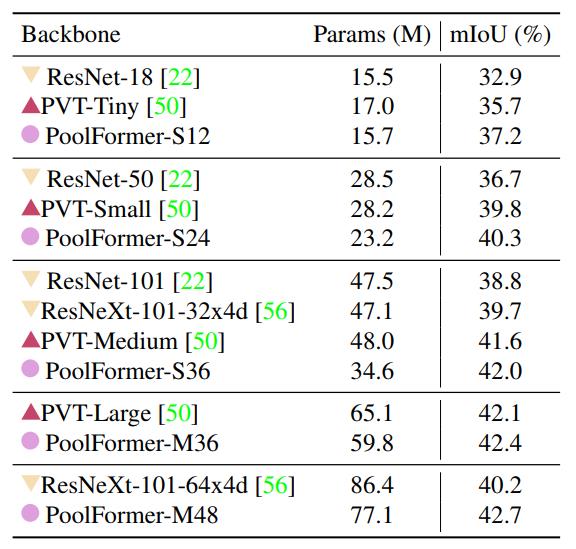
最后,在ADE20K上进行语义分割的实验,结果如下。
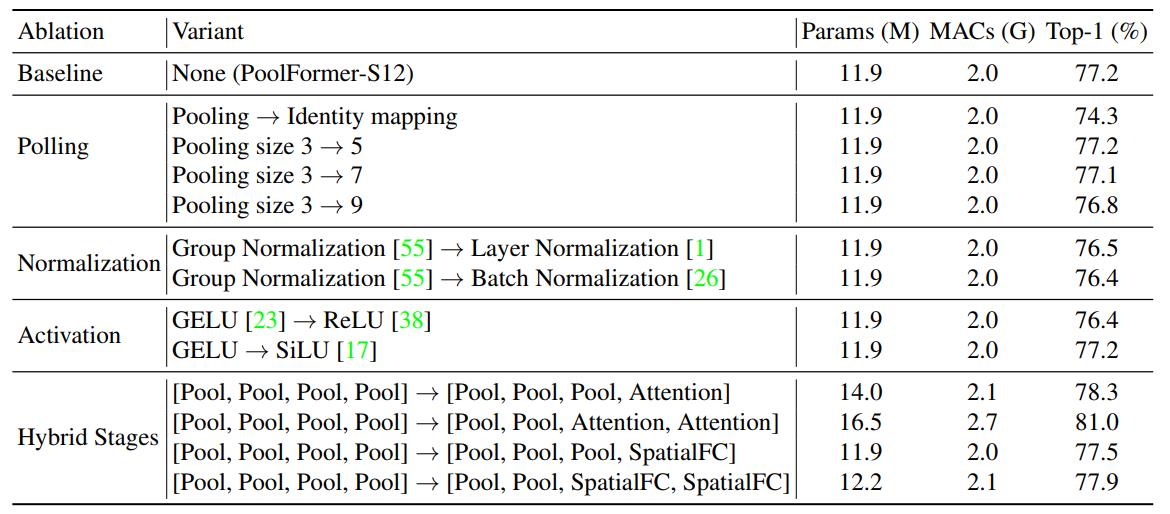
作者还进行了一些消融实验,都在下表中列了出来,着重看最后一部分,作者将四个stage的池化换为了注意力模块或者spatial MLP,发现这些结构混用也不会有什么问题,而且前两个stage池化后两个stage注意力这种设计效果尤其不错,同比之下的ResMLP-B24需要7倍的参数量和8.5倍的MACs才能获得同等精度。
总结
这篇文章中,作者独树一帜提出视觉Transformer及其变种的成功原因主要是架构的设计,并且将token mixer换为了简单的池化获得了相当好的效果。这也反映了视觉Transformer其实还有很多值得研究的地方,这篇论文的代码也已经开源,代码量不大,感兴趣的可以通过源码了解到更多的细节。本文也只是我本人从自身出发对这篇文章进行的解读,想要更详细理解的强烈推荐阅读原论文。最后,如果我的文章对你有所帮助,欢迎一键三连,你的支持是我不懈创作的动力。
以上是关于PoolFormer解读的主要内容,如果未能解决你的问题,请参考以下文章