码农吸猫必备,几行代码就能采集万张猫咪图
Posted 梦想橡皮擦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了码农吸猫必备,几行代码就能采集万张猫咪图相关的知识,希望对你有一定的参考价值。
这篇文章参加了某站的一个小活动,CSDN 同步一份
作为一个 Python 爬虫爱好者,当看到涉及猫咪活动的时候,首先想到的就是采集猫咪图,那我们就实现一款猫咪图采集器吧。
目标站点说明
本次要采集的站点为:《素材公社》,该网站提供了丰富的图片资源,这些内容都可以分类采集,本文仅采集与 “猫咪” 相关的素材。
本案例用到的技术模块
requests:负责请求发送;lxml:负责数据提取。
目标站点分析
列表页分页规则如下所示:
https://www.tooopen.com/img/89_869_1_1.aspx
https://www.tooopen.com/img/89_869_1_2.aspx
https://www.tooopen.com/img/89_869_1_页码.aspx
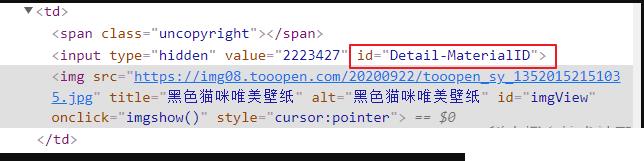
通过开发者工具查阅页面元素时,发现页面有 JS 动态加载而成,在 DOM 结构中存在如下代码(下图红框区域),这部分数据为 JSON 格式,在后续的编码过程中,可以直接进行序列化操作。

获取猫咪大图
由于列表页展示的是猫咪缩略图,所以需要进入详情页提取分辨率更高的图片,这里采用两步编码,第一步提取详情页地址,第二步从详情页提取大图地址。
拿 详情页 举例,该部分标签中存 id=Detail-MaterialID,既然标签存在 ID 值,那后续的提取就变的简单了许多。
编码时间
首先封装一个通用的请求函数,原因是存在 3 次请求的发送:
- 请求列表页,获取详情页地址;
- 请求详情页,获取猫咪大图地址;
- 请求猫咪大图,获取图片数据(不过最后一步,没有写到该函数中进行判断)
# 获取网页响应内容
def common_requests(url):
try:
res = requests.get(url=url, headers=headers, timeout=3)
html_str = res.text
# format_html(html_str)
return html_str
except Exception as e:
print(e)
return None
公用请求函数编写完毕之后,就可以编写核心逻辑部分,这部分代码由 2 部分构成:
- 获取网页响应源码;
- 解析网页源码,提取详情页地址。
def get_html(url):
# 列表页响应的源码
ret_html = common_requests(url)
if ret_html is not None:
format_html(html=ret_html)
def format_html(html):
element = etree.HTML(html)
# 得到详情页地址
img_name = element.xpath('//a[@class="pic"]/@title')
detail_links = element.xpath('//a[@class="pic"]/@href')
name_links = list(zip(img_name, detail_links))
data_more_str = element.xpath('//div[@id="data-more"]/text()')[0]
# 获取更多图片
data_more = json.loads(data_more_str)
if len(data_more) > 0:
name_links.extend([(_['title'], _["url"]) for _ in data_more])
if len(name_links) > 0:
for name, link in name_links:
# 详情页响应源码
ret_detail_html = common_requests(link)
if ret_detail_html is not None:
get_big_img(name, ret_detail_html)
else:
pass
上述代码需要关注的是,提取本文开篇提及目标数据标签位置的代码,局部代码如下:
element.xpath('//div[@id="data-more"]/text()')[0]
上述代码还调用了一个函数:get_big_img(),该函数目的是获取猫咪大图,函数体如下所示,可同步编写 save_img() 函数
def get_big_img(name, ret_detail_html):
element = etree.HTML(ret_detail_html)
img_url = element.xpath('//img[@id="imgMainView"]/@src')
if len(img_url) > 0:
save_img(name, img_url[0])
else:
pass
# 保存图片
def save_img(name, img_url):
img_headers =
"Host": "img08.tooopen.com",
"Referer": "https://www.tooopen.com/view/2298460.html"
res = requests.get(url=img_url, headers=img_headers, timeout=10)
data = res.content
if data is not None:
with open(f'./imgs/name.jpg', 'wb+') as f:
f.write(data)
在请求图片地址时,由于其存在外链限制,所以需要在请求头中增加 HOST 与 Referer 参数。
最后在增加 main() 函数,实现对上述代码的调用,即可完成本案例。
if __name__ == '__main__':
headers =
"user-agent": 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:94.0) Gecko/20100101 Firefox/94.0'
base_url = 'https://www.tooopen.com/img/89_869_1_.aspx'
urls = [base_url.format(_) for _ in range(1, 100)]
for url in urls:
get_html(url)
运行代码之后,就会得到高清猫咪图,(由于目标站点不属于自己,可能存在版权问题,顾采集之后的图片及时删除)
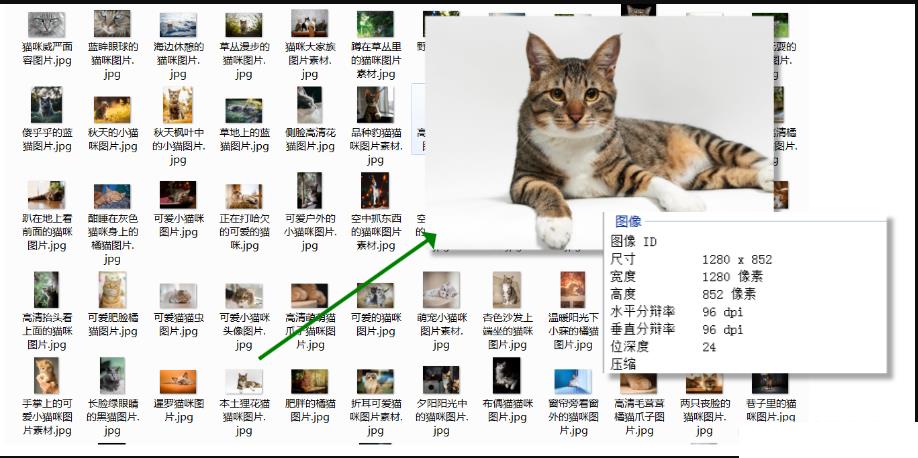
本案例顺利完成,欢迎在评论区一起交流+吸猫
以上是关于码农吸猫必备,几行代码就能采集万张猫咪图的主要内容,如果未能解决你的问题,请参考以下文章
什么猫咪最受欢迎?Python爬取全网猫咪图片,哪一款是你最爱的
什么猫咪最受欢迎?Python爬取全网猫咪图片,哪一款是你最爱的