什么猫咪最受欢迎?Python爬取全网猫咪图片,哪一款是你最爱的
Posted 程序猿中的BUG
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么猫咪最受欢迎?Python爬取全网猫咪图片,哪一款是你最爱的相关的知识,希望对你有一定的参考价值。
前言
采集目标

工具准备
开发工具:pycharm
开发环境:python3.7, Windows11
使用工具包:requests
项目思路解析
做爬虫案例首先需要明确自己的采集目标,白又白这里采集的是当前网页的所有图片信息,有目标后梳理自己的代码编写流程,爬虫的基本四步骤:
- 第一步:获取到网页资源地址
- 第二步:对地址发送网络请求
- 第三步:提取对应数据信息
- 提取数据的方式一般有正则、xpath、bs4、jsonpath、css选择器
- 第四步:保存数据信息
第一步:找数据地址
数据的加载方式一般有两种,一种静态一种动态,当前网页的数据在往下刷新时不断的加载数据,可以判断出数据加载的方式为动态的,动态数据需要通过浏览器的抓包工具获取,鼠标右击点击检查,或者按f12的快捷方式,找到加载的数据地址
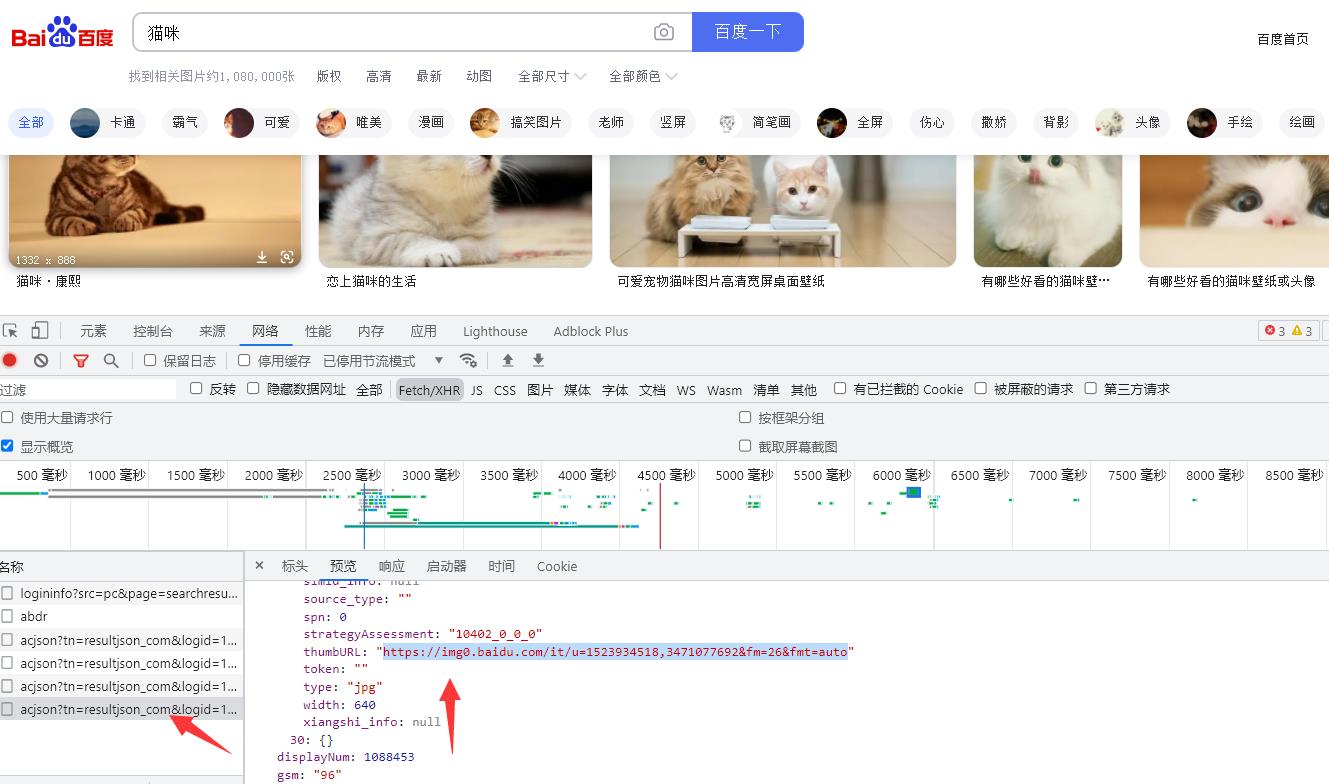
找到对应数据地址,点击弹出的接口后可以点击预览,预览打开的页面是展示给我们的数据,在数据多的时候通过他来进行查看,获取的数据是通过网址获取的,网址数据在请求里,对网址发送网络请求
第二步:代码发送网络请求
发送请求的工具包会非常多,入门阶段更多的是使用requests工具包,requests是第三方工具包,需要进行下载:pip install requests 发送请求时需要注意我们通过代码请求,web服务器会根据http请求报文来进行区分是浏览器还是爬虫,爬虫不受欢迎的,爬虫代码需要对自己进行伪装,发送请求时带上headers传输的数据类型为字典键值对,ua字段是非常重要的浏览器的身份证
第三步:提取数据
当前获取的数据为动态数据,动态数据动态数据一般都是json数据,json数据可以通过jsonpath直接提取,也可以直接转换成字典,通过Python提取最终的目的是提取到图片的url地址
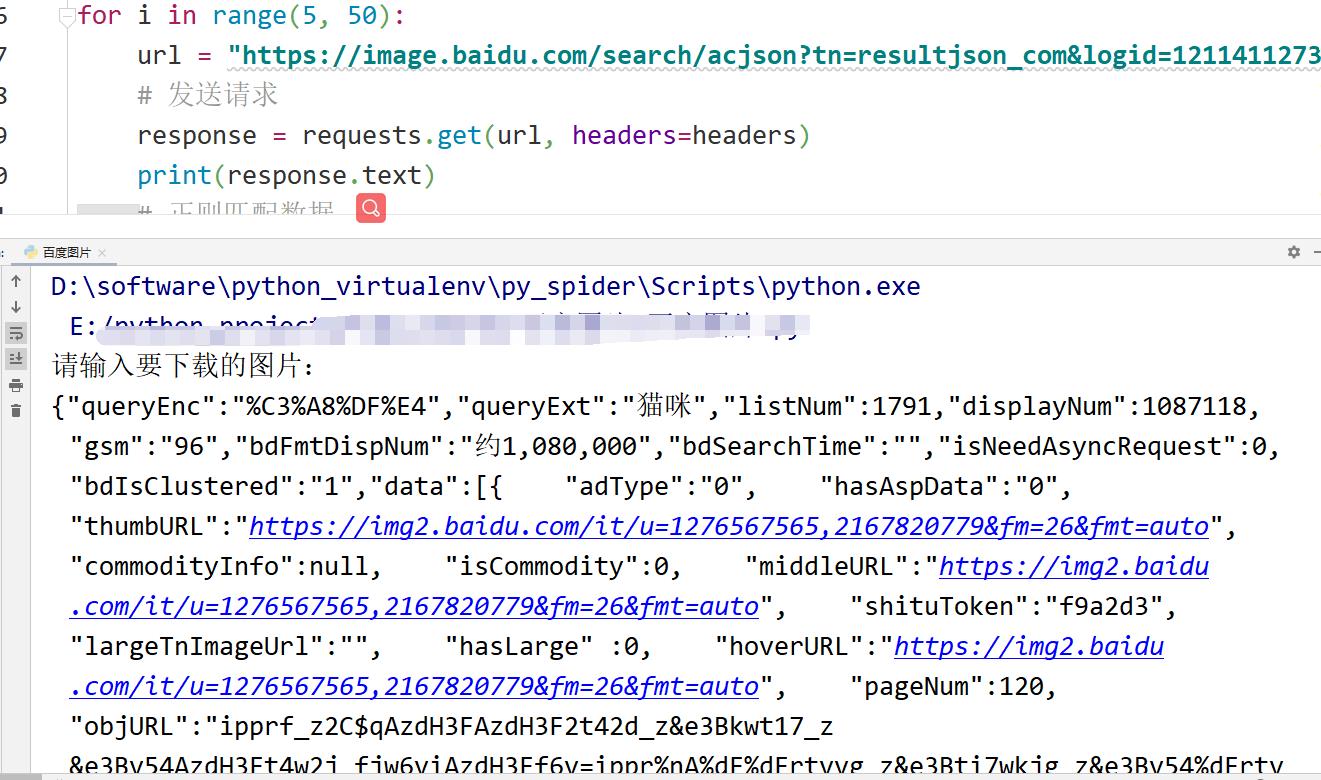

提取出新的地址后需要再次对网址发送请求,我们需要的是图片数据,链接一般是保存在数据中,发送请求获取图片对应的进制数据
第四步: 保存数据
数据获取到之后将数据进行储存,选择自己数据储存的位置,选择写入方式,我们获取的数据是进制数据,文件访问模式用的wb,将获取到的图片进入数据写入就行,文件的后缀需要是图片结尾的后缀,可以选择用标题命名,白又白使用网址后部分进行命名。
简易源码分享
import requests # 导入请求的工具包
import re # 正则匹配工具包
# 添加请求头
headers = {
# 用户代理
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/70.0.3538.67 Safari/537.36",
# 请求数据来源
# "Referer": "https://tupian.baidu.com/search/index",
# "Host": "tupian.baidu.com"
}
key = input("请输入要下载的图片:")
# 保存图片的地址
path = r"图片/"
# 请求数据接口
for i in range(5, 50):
url = "https://image.baidu.com/search/acjson?tn=resultjson_com&logid=12114112735054631287&ipn=rj&ct=201326592&is=&fp=result&fr=&word=%E7%8C%AB%E5%92%AA&queryWord=%E7%8C%AB%E5%92%AA&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&expermode=&nojc=&isAsync=&pn=120&rn=30&gsm=78&1635836468641="
# 发送请求
response = requests.get(url, headers=headers)
print(response.text)
# 正则匹配数据
url_list = re.findall('"thumbURL":"(.*?)",', response.text)
print(url_list)
# 循环取出图片url 和 name
for new_url in url_list:
# 再次对图片发送请求
result = requests.get(new_url).content
# 分割网址获取图片名字
name = new_url.split("/")[-1]
print(name)
# 写入文件
with open(path + name, "wb")as f:
f.write(result)
我是白又白i,一名喜欢分享知识的程序媛❤️
感兴趣的可以关注我的公众号:白又白学Python【非常感谢你的点赞、收藏、关注、评论,一键三连支持】
以上是关于什么猫咪最受欢迎?Python爬取全网猫咪图片,哪一款是你最爱的的主要内容,如果未能解决你的问题,请参考以下文章
什么猫咪最受欢迎?Python爬取全网猫咪图片,哪一款是你最爱的