AI简报20211203期国产GPU全面开花!黑芝麻智能与RT-Thread达成战略合作
Posted RT-Thread物联网操作系统
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AI简报20211203期国产GPU全面开花!黑芝麻智能与RT-Thread达成战略合作相关的知识,希望对你有一定的参考价值。
RT-AK新闻


1. RT-Thread嵌入式AI师资培训

随着 AI 技术的不断成熟和发展,人工智能正成为推动经济社会发展的新引擎,被广泛应用于各行业。随着深度学习等人工智能理论与技术的发展,越来越多的人工智能学习与推理从云端开始向终端进行迁移,从而来适应和满足广大嵌入式、物联网设备的应用在智能方面的计算需求。本次线上培训将围绕嵌入式人工智能教学实践进行展开,利用RT-Thread Studio与RT-AK工具进行人工智能应用开发,详细讲解从嵌入式操作系统到AI应用开发的全流程,让嵌入式人工智能教学从理论到实践进行落地,助力嵌入式人工智能在行业中落地。
一、培训时间:
2021年12月25日-12月26日
二、主办单位:
上海睿赛德电子科技有限公司
三、培训对象:
计算机、电子信息、自动化及人工智能相关教师、嵌入式大赛指导教师
四、培训平台与形式
培训平台:Darco嵌入式AI开发板
培训形式:腾讯会议
五、培训内容:

六、报名链接:
报名链接:https://wj.qq.com/s2/9226462/e0a7/

联系人:罗齐熙
联系方式:13632716562(微信同号)
电子邮箱:luoqixi@rt-thread.com
嵌入式 AI


2. 黑芝麻智能与睿赛德科技达成战略合作,共同打造自动驾驶基础计算平台
原文链接:
https://mp.weixin.qq.com/s/7y8siApdjZkEVCaT8EDNfA
11月25日,上海睿赛德电子科技有限公司(以下简称“睿赛德科技”)与黑芝麻智能科技有限公司(以下简称“黑芝麻智能”)签署战略合作协议。

双方基于黑芝麻智能车规级高性能自动驾驶计算芯片和睿赛德科技实时操作系统技术协同研发自动驾驶软硬一体功能安全解决方案,为智能汽车产业提供一个高度开放性、可定制化的高性能融合基础计算平台。
汽车产业正在智能电动化浪潮中迎来重启,中国厂商迎来巨大机遇,并在这场变革的多个维度处于领先地位。基础核心技术的国产化也受到产业和政府前所未有的关注和重视。黑芝麻智能与睿赛德科技作为国内两家代表性基础科技企业,希望通过此次合作,强化协同效应,加快国产自动驾驶平台技术的成熟和落地。
双方将投入足够的优势资源,依托黑芝麻智能领先的车规级高性能低功耗的自动驾驶计算芯片、图像传感、机器视觉算法和神经网络处理技术,以及睿赛德科技的符合功能安全要求的实时操作系统、微内核操作系统(RT-Thread Smart)、虚拟化软件等技术,共同打造平台化的自动驾驶软硬一体解决方案,面向车厂、Tier1供应商和自动驾驶示范区联合展示,共同推广。
3. 边缘处理加紧落地,计算核“芯”持续突破
原文链接:
https://mp.weixin.qq.com/s/XAGIG_OKPWa0Qo5x1LDtMA
电子发烧友网报道(文/李宁远)在物联网兴起的今天,基于边缘计算的机器学习技术变得越来越重要,重要数据的处理需要更接近数据最初所在的位置。这两年,人工智能发展的主题已经非常明确,在落地应用上国内外厂商都在抓紧部署。在众多的AI技术当中,无论是上层的算法应用,还是产品,最终都依赖于底层算力的保障,也就是那颗“芯”。

无论在新一代可穿戴设备上,还是在机器人领域,边缘处理的方案似乎更适合这些需要实时、安全、自主响应的应用。而这些多元化的场景里不同的环境都对芯片的功耗和性能要求有差异。如何在能效、安全以及连接性上保证对不同场景的覆盖是一大难点,同时在芯片上执行深度学习任务获取高质量数据也绝非易事。在边缘计算的核“芯”上,主流厂商是怎么突破的?
NXP跨界系列MCU
NXP有一个边缘计算平台EdgeVerse,囊括了全面的处理器、微控制器和签名软件产品组合。i.MX RT系列跨界MCU就是EdgeVerse边缘计算平台的一部分,这个大系列的产品兼顾Arm Cortex-M内核、实时处理功能以及MCU的可用性。
从最初的Cortex-M33内核的RT500系列到现在的M7内核的RT1170。跨界系列的MCU从性能到场景覆盖都很出色,可以说这款跨界产品推动了应用处理器和MCU之间的融合。
RT1170跨界MCU以1GHz的速度刷新了纪录。RT1170的双核为6468 CoreMark,主频达1 GHz的Cortex-M7以及主频达400MHz的Arm Cortex-M4。

RT1170突破性的跨界MCU结合了极其高效的计算能力、多种媒体功能以及各种实时功能。同时配置了大容量低延迟的片上SRAM存储器,SRAM高达2MB,带有面向Cortex-M7的512 KB TCM和面向Cortex-M4的256 KB TCM。这样一来RT1170的实时反应极快,延迟最低仅有12ns。
该系列也尽可能在降低功耗,通过集成DC-DC转换器,在动态功耗上RT1170有所下降,同时该芯片本身也有频率为21MHz的低功耗模式。在高效能计算,实时性以及功耗层面之外,这款跨界MCU的集成度也足够高。本就强大的多媒体性能实现了GUI与增强HMI,通过OpenVG图形加速,主频可达500MHz。
安全方面体现在整个EdgeVerse上,安全启动和加密引擎以及AES解密都在这款跨界MCU上全部体现。可以看出在边缘计算领域,NXP可谓是下了苦功,通过跨界MCU强大性能以及全面的配套体系打造自己的NXP边缘计算生态。
瑞萨边缘计算MPU
瑞萨在边缘计算上使用了我们熟知的老朋友—RZ系列。这一次边缘计算的重任落在了RZ/A系列头上。RZ/A 是基于32位Arm Cortex A9的处理器,具有高达10 MB片上SRAM可以缓冲高达WXGA分辨率的图形。尤其是系列下的A2M,带有动态可配置处理器技术,在嵌入式AI高速图像处理上颇有心得。

RZ/A2M具有大容量内部 RAM (4MB),采用动态可配置处理器提供10倍图像处理性能来支持边缘计算功能,并通过MIPI/LVDS/2端口以太网提供强大的连接功能。A2M提供足够的带宽来处理中央数据中心的全部信息。
4. 国产GPU全面开花!服务器GPU、全功能GPU、高性能GPGPU…加速追赶国际巨头
原文链接:
https://mp.weixin.qq.com/s/c3XTCJmtM5xzmevBKUA-_Q
国产GPU市场的火爆引起广泛关注,几家国产厂商相继发布产品进展的好消息,也有GPU厂商陆续获得大笔融资,这说明国产GPU不仅受到了资本的大力支持,也切实在产品上取得了一定的突破。
GPU市场规模
根据Verified Market Research的数据,2020年全球GPU市场价值为254.1亿美元,2027年有望达到1853.1亿美元,年平均增速高达32.82%。
市场研究机构Jon Peddie Research数据显示,2021年一季度,在全球PC端GPU市场中,英特尔以68%的市场份额位居榜首,AMD和英伟达分别以17%和15%的市场份额名列第二和第三;在PC端独立GPU领域中,英伟达占据81%的市场份额拥有领先优势,AMD以19%的市场份额排名第二。
根据东吴证券的预估,2020年中国大陆的独立GPU市场规模为47.39亿美元,预计2027年中国大陆GPU市场规模将超过345.57亿美元。随着政策端对信息关键基础设施自主可控的重视,国产替代浪潮来临,国内独立GPU产商的广阔市场空间已被打开。
联发科的优势首先体现在工艺上,新发布的天玑 9000 是首款基于台积电 4nm 工艺(N4)打造的移动芯片,这可以称得上是业界第一了。
国产GPU最新进展
进入10月份以来,多家国产GPU厂商发布了产品的研发和商用情况。
2021年10月上旬,壁仞科技首款通用GPU芯片BR100正式交付台积电生产,预计明年面向市场发布。这款芯片主要聚焦人工智能(AI)训练和推理、通用运算等众多计算应用场景,可广泛应用于包括智慧城市、公有云、大数据分析、自动驾驶、医疗健康、生命科学、云游戏等领域。壁仞科技成立两年,累计融资50亿元。
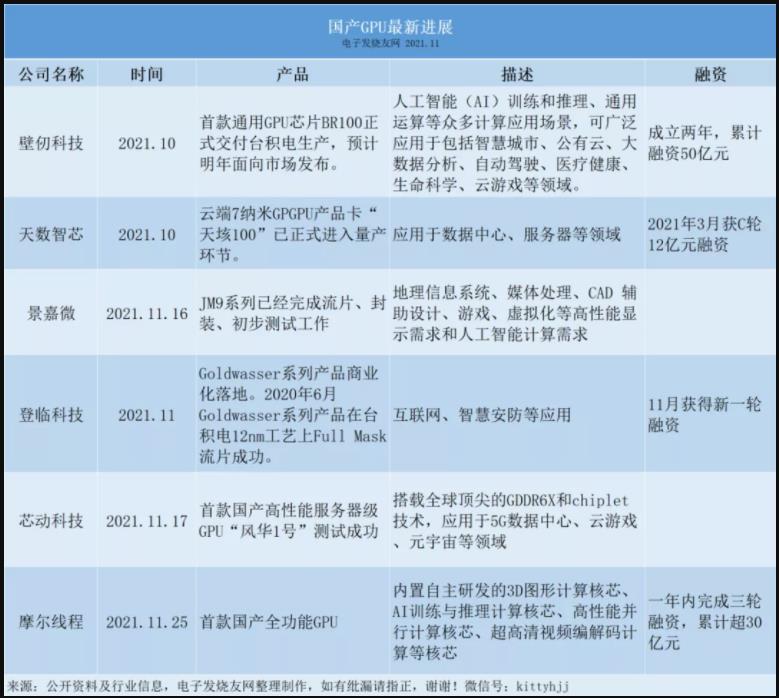
10月29日,天数智芯宣布公司全自研、国内首款云端7纳米GPGPU产品卡——“天垓100”已正式进入量产环节。这颗芯片主要应用于数据中心和服务器等领域。在2021年3月,天数知芯还公布公司获C轮12亿元融资。
5. 亚马逊发布Graviton 3芯片,加速替代AMD和Intel
原文链接:
https://www.iot101.com/news/987.html
据路透社报道,亚马逊公司的云计算部门周在二推出了两款新的定制计算芯片,旨在帮助其客户降低使用英特尔和英伟达芯片的成本。

报道指出,亚马逊网络服务 (AWS) 2020 年的销售额为 453.7 亿美元,是全球最大的云计算提供商,也是数据中心芯片的最大买家之一,AWS 将其计算能力出租给其客户。自 2015 年收购一家名为 Annapurna Labs 的初创公司以来,AWS 一直致力于开发自己的定制芯片。
周二,该公司发布了第三代 Graviton 芯片,旨在与英特尔和 Advanced Micro Devices 的中央处理器竞争。据介绍,Graviton3 比其前一代产品快 25%,亚马逊弹性计算云副总裁 Dave Brown 告诉路透社,该公司预计它的每美元性能将比英特尔的芯片更好。
AWS 还表示,一种名为 Trainium 的新型芯片将很快向其客户提供,该芯片旨在训练机器学习计算机模型并将与 Nvidia 的芯片竞争。AWS 预计它以比 Nvidia 的旗舰芯片低 40% 的成本训练机器学习模型。
AI新闻


6. DeepMind用AI首次实现数学领域重大进展,助力科学家证实两大猜想
原文链接:
https://mp.weixin.qq.com/s/Xg0z0SLANIglwA26tTBJCg
数论是人类知识最古老的一个分支,然而它最深奥的秘密与其最平凡的真理是密切相连的。数学原理极易从事实中归纳出来,但证明却隐藏的极深。可以说数学,是一切科学的基础。就如诺贝尔奖得主费曼说:如果没有数学语言,宇宙似乎是不可以描述的。
徐宗本院士曾表示,数学与 AI 的关系是「融通共进」。一方面,人工智能的基础之一是数学,因此人工智能想要行稳致远,就必须先把数学的基本问题解决好;另一方面,人工智能的发展也对数学领域的研究产生了重要的推动作用。

只是目前为止,人工智能技术未能在纯数学研究中取得重大突破。
12月1日,Nature杂志刊登文章《Advancing mathematics by guiding human intuition with AI》,验证了机器学习在发现数学猜想和定理方面有着巨大潜力。

这篇文章出自人工智能明星公司DeepMind团队,他们与数学领域的顶级科学家合作,在拓扑学和表象理论方面证明了两个新猜想:
与悉尼大学Geordie Williamson教授合作接近证明了一个关于卡兹丹—卢斯提格多项式的古老猜想,这个猜想已困扰数学家们40多年。
与牛津大学Marc Lackenby教授和András Juhász教授一起,通过研究拓扑学纽结理论观察到代数和几何不变量之间的惊人联系。这是利用机器学习做出的第一个重大数学发现。
7. Self-Attention和CNN的优雅集成!清华大学等提出ACmix,性能速度全面提升!
原文链接:
https://mp.weixin.qq.com/s/0LAYmXsGjxBwCm5roXFOtQ
论文链接:https://arxiv.org/pdf/2111.14556.pdf
代码链接:https://github.com/Panxuran/ACmix(尚未发布)
预训练模型:https://gitee.com/mindspore/models
近年来,卷积和Self-Attention在计算机视觉领域得到了长足的发展。卷积神经网络广泛应用于图像识别、语义分割和目标检测,并在各种基准上实现了最先进的性能。最近,随着Vision Transformer的出现,基于Self-Attention的模块在许多视觉任务上取得了与CNN对应模块相当甚至更好的表现。
尽管这两种方法都取得了巨大的成功,但卷积和Self-Attention模块通常遵循不同的设计范式。传统卷积根据卷积的权值在局部感受野上利用一个聚合函数,这些权值在整个特征图中共享。固有的特征为图像处理带来了至关重要的归纳偏差。
相比之下,Self-Attention模块采用基于输入特征上下文的加权平均操作,通过相关像素对之间的相似函数动态计算注意力权重。这种灵活性使注意力模块能够适应地关注不同的区域,并捕捉更多的特征。
考虑到卷积和Self-Attention的不同和互补性质,通过集成这些模块,存在从两种范式中受益的潜在可能性。先前的工作从几个不同的角度探讨了Self-Attention和卷积的结合。
早期的研究,如SENet、CBAM,表明Self-Attention可以作为卷积模块的增强。最近,Self-Attention被提出作为独立的块来替代CNN模型中的传统卷积,如SAN、BoTNet。
另一种研究侧重于将Self-Attention和卷积结合在单个Block中,如 AA-ResNet、Container,而该体系结构限于为每个模块设计独立的路径。因此,现有的方法仍然将Self-Attention和卷积作为不同的部分,并没有充分利用它们之间的内在关系。
在这篇论文中,作者试图揭示Self-Attention和卷积之间更为密切的关系。通过分解这两个模块的操作表明它们在很大程度上依赖于相同的卷积操作。作者基于这一观察结果开发了一个混合模型,名为ACmix,并以最小的计算开销优雅地集成了Self-Attention和卷积。

8. FAIR何恺明团队最新研究:定义ViT检测迁移学习基线
原文链接:
https://mp.weixin.qq.com/s/9o3RqQV6YEb4Cfa4JPDfnQ
为测试预训练模型能否带来性能增益(准确率提升或者训练速度提升),目标检测是一个常用的且非常重要的下游任务。面对新的ViT模型时,目标检测的复杂性使得该基线变得尤为重要(non-trivial )。然而架构不一致、缓慢训练、高内存占用以及未知训练机制等困难阻碍了标准ViT在目标检测任务上的迁移学习。
本文提出了训练技术以克服上述挑战,并采用标准ViT作为Mask R-CNN的骨干。这些工具构成了本文的主要目标:我们比较了五种ViT初始化,包含SOTA自监督学习方法、监督初始化、强随机初始化基线。
结果表明:近期提出的Masking无监督学习方法首次提供令人信服的迁移学习性能改善 。相比监督与其他自监督预训练方法,它可以提升 指标高达4% ;此外masking初始化具有更好的扩展性,能够随模型尺寸提升进一步提升其性能。

9. 注入Attention,精度涨30%!谷歌发表最新多目标“动态抠图”模型
原文链接:
https://mp.weixin.qq.com/s/a0bp1NqvvtBgyVRek-bOKQ
该方法通过在视频中引入注意力机制,成功地解决此前采用了无监督学习的多目标分割和跟踪方法的一些不足。现在的它,不仅可以泛化到更多样、视觉上更复杂的视频中,还能处理更长的视频序列。通过实验还发现,相比此前的模型,谷歌这个新方法在MOVi数据集上的mIoU直接提高了近30%。
为“动态抠图”引入注意力机制
方法被命名为SAVi(Slot Attention for Video)。而此前的无监督目标分割和跟踪方法最大的问题,就是只能应用到非常简单的视频上。为了处理视觉效果更复杂的视频,SAVi采用弱监督学习:
(1)以光流(optical flow)预测为训练目标,并引入注意力机制;
(2)在第一帧图像上给出初始提示(一般是框出待分割物体,或者给出物体上单个点的坐标),进行分割指导。
具体来说,受到常微分方程的“预测-校正器”方法的启发,SAVi对每个可见的视频帧执行预测和校正步骤。为了描述视频物体随时间变化的状态,包括与其它物体的交互,SAVi在进行光流预测时在slot之间使用自注意力。slot就是指视频中各物体,用不同颜色区分。

聊点技术


10. 可视化推导贝叶斯定理公式
原文链接:
https://mp.weixin.qq.com/s/DbInmnMCigzmjnr_1uzEiA
什么是贝叶斯定理?
在统计和应用数学中,贝叶斯定理也被称为贝叶斯规则,它是一个用于确定事件的偶然性概率的数学公式。贝叶斯定理描述了由事件相关条件的先验知识支持的事件发生的概率。

这个定理以英国统计学家贝叶斯的名字命名,他在1763年发现了这个公式。它被认为是被称为贝叶斯推断的特殊统计推断方法的灵感。除了统计学之外,贝叶斯定理还被用于医学和药理学等各个学科。该理论通常用于多个金融领域。例如模拟向借款人贷款的风险或预测投资成功的可能性。
解释

在上面的图片中,我们有两个重叠的事件A和B.例如,A-我今天被弄湿了,B-今天会下雨。在一种或另一种方法中,许多事件彼此关联,如我们的示例中所示。只要B已经发生,让我们计算A的概率。因为B发生了,所以阴影部分是对A重要的也就是是A∩ B、 所以,给定B的概率似乎是:

因此,如果 A 已经发生,我们可以写出事件 B 的公式:

或者:

现在,第二个公式可以改写为:

这就是贝叶斯定理公式
其中:
P(A|B) — 给定事件 B 已经发生时事件 A 发生的概率。P(B|A) — 给定事件 A 已经发生时事件 B 发生的概率。
P(A) — 事件 A 单独发生的概率。P(B) — 事件 B 单独发生的概率。
11. 超全总结!移动机器人三大自主导航算法
原文链接:
https://mp.weixin.qq.com/s/oJbrWS_sSFJGl3fSPWHozA
想象我们要去某个地方游玩,你是不是会先在脑海中勾勒出一条路线,然后出发前往这个地方?
人类的导航如此,那对于机器人来讲,该如何实现导航功能呢?
机器人自主导航
我们先来理清自主导航的框架,其关键是自主定位和路径规划。针对这两个核心功能,ROS提供了一套完整的框架支持,收到导航目标位置后,机器人只需要发布必要的传感器信息,框架中的功能包即可帮助机器人完成导航。

其中,move_base功能包实现机器人导航中的最优路径规划,amcl实现二维地图中的机器人定位。为了实现机器人全局最优路径规划与实时避障路径规划,move_base需要订阅机器人发布的深度传感器信息(sensor_msgs/LaserScan或 sensor_msgs/PointCloud)和里程计信息(nav_msgs/Odometry),同时完整的TF坐标变换也是实现路径规划的重要基础。导航框架最终的输出是控制机器人的速度指令(geometry_msgs/Twist),这就要求机器人控制节点具备解析控制指令中线速度、角速度的能力,并且控制机器人完成相应的运动。
机器人定位
导航功能的顺利进行,离不开机器人的精准定位。自主定位即机器人在任意状态下都可以推算出自己在地图中所处的位置。ROS为开发者提供了一种自适蒙特卡罗定位方法(Adaptive Monte Carlo Localization,amcl),这是一种概率统计方法,针对已有地图使用粒子滤波器跟踪一个机器人的姿态。

给定初始位姿后,AMCL会在机器人周围随机撒一些粒子,随着机器人的运动,每个粒子也会实时跟随机器人的速度更新位姿,当粒子周边的环境状态与机器人差距较大时,就会被逐渐淘汰,反之,则会在机器人周边产生更多粒子。以此类推,粒子都集中在机器人所在位置可能性高的地方,也就是定位的结果。为了调教以上粒子滤波算法,AMCL功能包中可配置的参数很多,一般初次上手不建议,只需要注意订阅和发布的话题名匹配即可,感兴趣的小伙伴可以在官网(http://wiki.ros.org/amcl)查看各个参数的详细介绍,相关的理论算法请参考《概率机器人》一书。
机器人路径规划
机器人知道自己的位置后,如何像人一样根据自己的经验规划出一条路径来呢?move_base功能包就是负责这样的功能,主要由全局路径规划器和本地实时规划器(局部路径规划器)组成。
全局规划就好比我们依靠经验(或地图数据)规划点到点最优路径的过程;局部规划可以理解为去往目的地途中,不断调整机器人姿态、躲避障碍物,以贴合最优路径的过程。

全局路径规划常用Dijkstra算法和A算法。Dijkstra算法深度优先,往往可以找到全局最优路径,不过搜索时间长、消耗资源多,而A算法加入了启发函数,虽然不一定可以找到全局最优路径,但搜索时间更快,适合大空间范围的规划。移动机器人大部分是在室内有限范围内使用,两者搜索时间和消耗资源的差距并不明显,一般使用Dijkstra算法即可。

本地实时规划常用Dynamic Window Approaches(DWA)和Time Elastic Band(TEB)算法,两种算法的核心思想如下,具体算法实现大家可以在网上搜索相关的论文。




邀请你参加 2021 RT-Thread 开发者大会的七大理由
1、刷新RT-Thread最新技术动态和产业服务能力
2、聆听行业大咖分享,洞察产业趋势
4、丰富的技术和产品展示,前沿技术发展和应用
5、绝佳的实践机会:从MCU、AIOT、MPU、RISC-V、安全总有一个应用场景满足你
6、现场揭晓开发者专属纪念胸牌升级和新玩法
7、互动区体验掌握技术带来的魅力



立即长按识别下方二维码报名




你可以添加微信17775982065为好友,注明:公司+姓名,拉进RT-Thread官方微信交流群!

👇 阅读原文报名开发者大会
以上是关于AI简报20211203期国产GPU全面开花!黑芝麻智能与RT-Thread达成战略合作的主要内容,如果未能解决你的问题,请参考以下文章
AI简报20210521期 2nm 芯片性能提升了多少清华「计图」现在支持国产芯片了!...
AI简报20220114期AI for Science催生科研新范式华为诺亚Transformer后量化技术...
AI简报20211029期YOLOv5-Lite 树莓派实时 超过1000个RISC-V核心的AI芯片