[人工智能-深度学习-56]:循环神经网络 - 词向量的自动构建与模型训练
Posted 文火冰糖的硅基工坊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[人工智能-深度学习-56]:循环神经网络 - 词向量的自动构建与模型训练相关的知识,希望对你有一定的参考价值。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/121709147
目录
前言:如何能将文本向量化呢?
先来考虑第一个问题:如何能将文本向量化呢?
看起来比较抽象,可以先从人的角度来观察。
第1章 “人”的向量化


第2章 语言的向量化
2.1 词的向量化
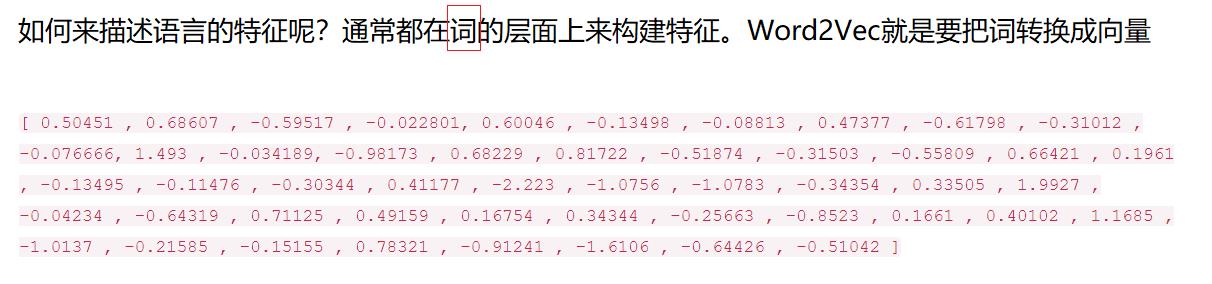
2.2 热度图
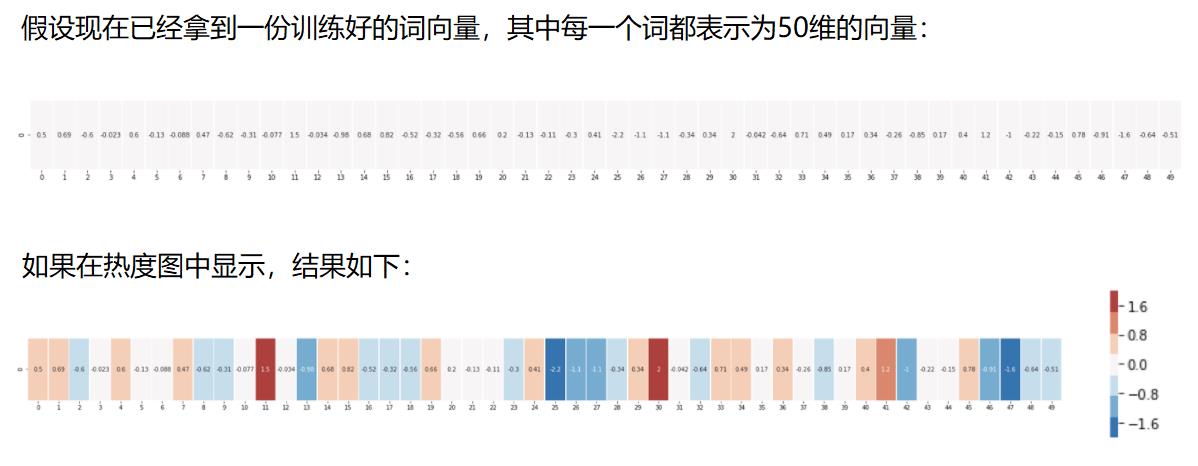
热度图:展现的是,每个词的每个维度的数据值,通过颜色的方式展现出来。
然后通过观察两个向量颜色,来只管的比较两个单词的相似度。
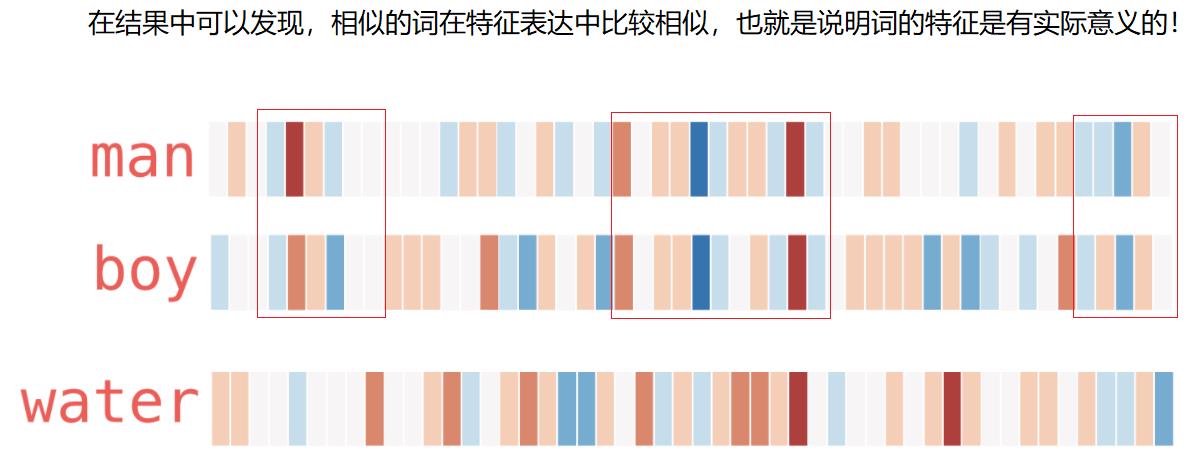
从上图可以看出,man和boy在热度图上有很多一致的向量值,反应的是这两个词的相似度很高。
而water与boy的相似性就比较少。
2.3 词向量的多维空间
如下是多维词向量空间的示意图:
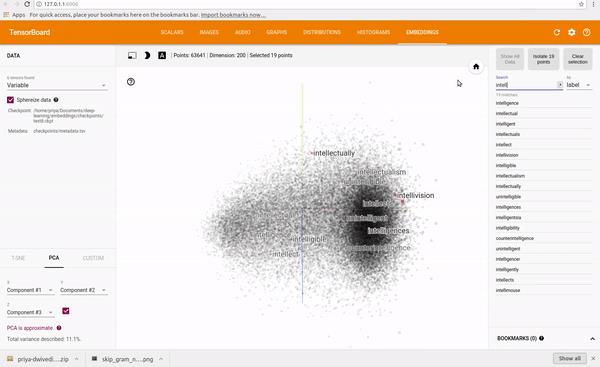
从上图可以看出,不同的词,处于多维空间的不同的位置:
有些词,在多维空间中的综合距离相近,
有些词,在多维空间中的综合距离相差甚远。
有些词,在某些维度相差较近,如水果Apply与Apply公司,输入相同
有些词,在某些维度相差远,如水果Apply与Apply公司,语义完全不同。
第3章 词向量训练模型的构建与训练(如何做到的?)
3.1 概述
词向量编码的难点是:
(1)如何指派各个词向量每个维度的浮点数值,(2)且要确保相似度相近的词的词向量的距离相对较小,语义关联的词的词向量的向量距离较小。
如果少量的词,如几十个,通过人工的方式来排列或指定是可以做到的,然而,如果词的数量高达几十万个,再通过人工的方式来厘清词与词的关系以及通过特定的词向量来体现,就不太可行了。
因此,每个单词的词向量的编码值,并非人为设定的,而是通过分析大量的文章,进行机器自动学习获得的。
3.2 前向运算模型
(1)通用模型

(2)词向量前向预测模型

(3)组成
- 输入:单词序列
- 词向量网络:词向量表(对应的W参数)
- RNN网络:特征提取表
- 全连接网络:分类
- 输出:预测的单词
(4)输入输出
输入是:从大量已经出版的文字中提取的单词序列(无监督学习),
输出是:从大量已经出版的文字中提取的某个单词的概率。
如我爱北京天安门门前的红旗飘
输入:我,爱;输出:北京
输入:爱,北京; 输出:天安门
输入:北京,天安门;输出:门前
....
输入:门前,红旗;输出:飘
备注:
输入是:单词序列 =》 单词分类的索引值,而不是ASCII值。
输出是:某个单词 =》 单词分类的索引值,而不是ASCII值。
通过索引值,在词向量表中可以查到对应的词向量。
通过索引查找词向量的方法参考:
 https://blog.csdn.net/HiWangWenBing/article/details/121707481
https://blog.csdn.net/HiWangWenBing/article/details/1217074813.3 反向训练模型

3.4 输入数据从何而来
不同词对应的向量值,与特定的文本文字有关。不同的文本,其训练出来的词向量是不相同的。
这也好理解,在不同的文本语境中,相同的词汇,其语义是不同的,自然词向量也不相同。
那么文本数据从哪儿来呢?这取决于我们的应用,比如IT公司的词向量与生物医药公司的词向量就不相同。
当然,有些非专业词,在所有的场合都实用。

文本数据来源:为网络中已经存在的规范化的文章。
3.5 如何从源数据自动构建训练样本

通过控制滑动窗口的大小控制单词序列输入的大小,即控制了词上下文的大小。
窗口越大,单词的上下文就越大,需要的RNN网络的参数和内存就越多,网络就越复杂。
窗口越大,训练出来的词向量表,其反应的某个单词与其他单词在物理的距离就可以越远。
物理距离:在文本上下文中间隔的单词数。
语义距离: 词向量的余弦距离。
通过滑动窗口,就可以得到多个连续的字符序列,如下图所示:

3.6 如何根据源数据自动构建样本标签
上述的输入样本和对应的下一个字构成的标签,都是从文本序列中自动提取的,而不需要人为打标签,这就是无监督式学习的一种方式。
假设上述文字的序列长度为:2。
当输入为:“thou shalt”时,对应的标签是“not”
当输入为:“shalt not” 时,对应的标签是“make”
当输入为:“not make” 时,对应的标签是“a”
3.7 把单词转换成分类索引
单词是一个字母序列,无法直接送到神经网络中,需要进一步的转换。
(1)查找文章的单词字典,获取单词对应的索引。
(2)对于输入数据,可以通过单词对应的索引,查找到对应的向量表。
(3)对于标签数据,可以通过单词对应的索引,得到其对应的OneHot的分类编码。
3.8 训练模型(输入与输出关系)选择
(1)多对一单词填空:根据上下文,填空中间单词。
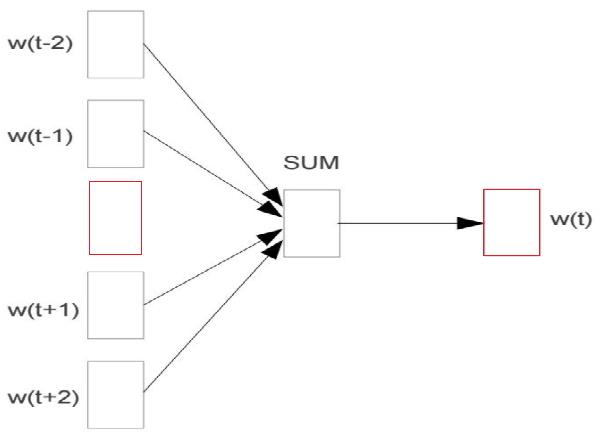
输入是上下文单词序列,标签是中间的某个单词,即把中间的某个单词作为标签单词。
训练的目的:在某一个单词序列下,网络的预测的输出单词与实际的标签单词一致。
由于此时的输入和输出,都是按照文本中的序列生成的,因此获得的词向量表,就能够反应单词在向量空间中的关系。
备注:
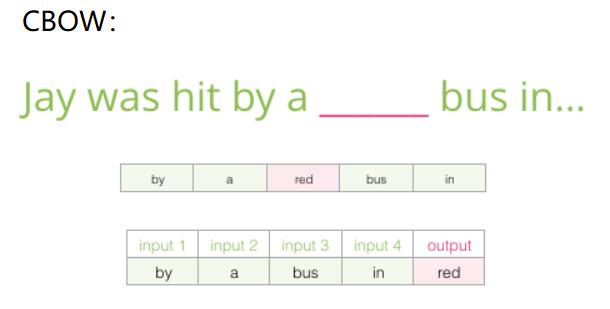
相同的输入序列,对应的标签可能有多种。这与无上下文关系的图片分类是不同的,无上下文关系的、各自独立的图片,一张图片的标签是唯一的;而这里单词是有上下文的,因此相同的输入,有可能多种不同的输出(即不同的语义)
上述输入序列的情况下,标签是“red”, 也有可能句子中出现“blue”。
相同句子,不同标签的多少,取决于实际文章的文字内容。
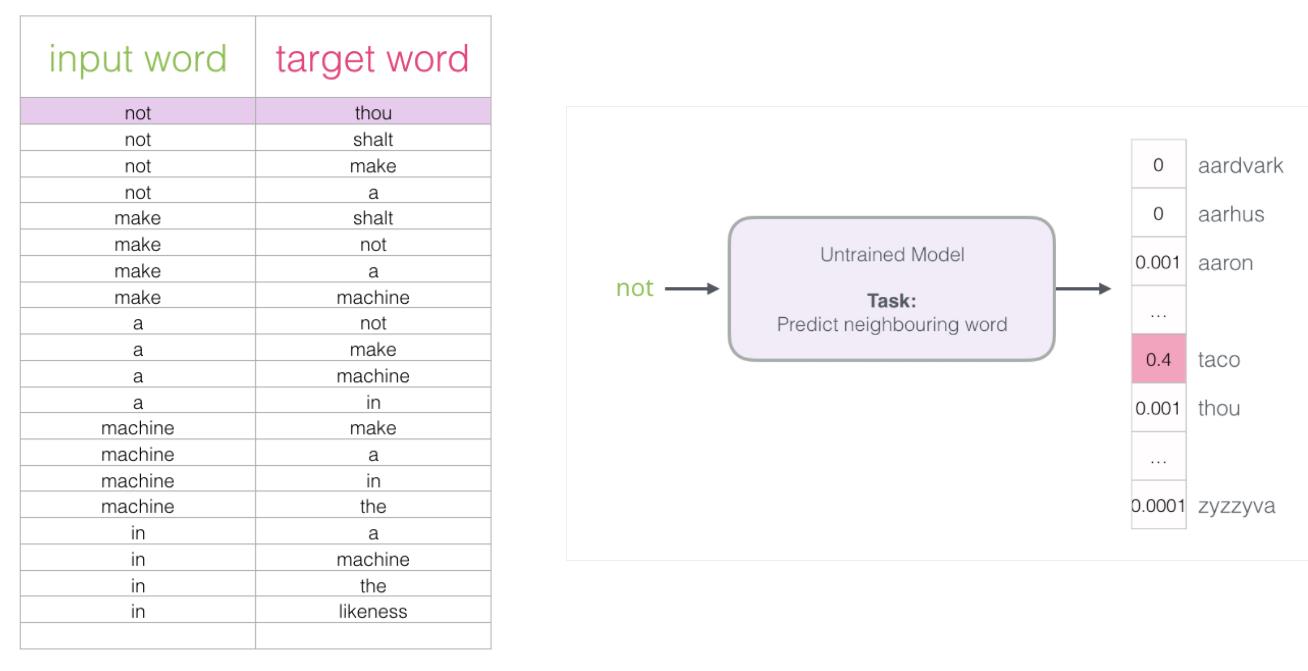
(2)一对多填充填空:根据某一个单词,出现多种可能的上下文单词
在该模型中,输入单个单词,有多个不同输出上下文。



在上图中,上下文的总长度为4,因此:
相同的输入“not”,有4个同步的上下文输出,每个输入与输出,就是一对样本。
相同的输入“make”,有4个同步的上下文输出,每个输入与输出,就是一对样本。
每个输入与输出,就是一对样本,每个输入与输出,就是一对样本。
相同的输入“a”,有4个同步的上下文输出,每个输入与输出,就是一对样本。
相同的输入“machine”,有4个同步的上下文输出,每个输入与输出,就是一对样本。
3.9 词向量模型的训练
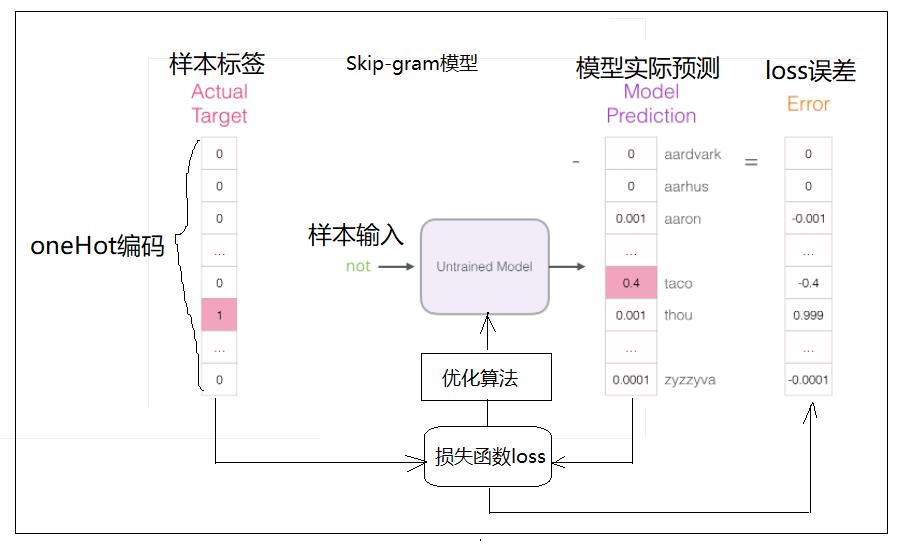
(1)输入数据:
输入数据为单词“not”
先把“not”转换成词分类的index。
(2)输入标签
根据index,进行oneHot编码,得到该词的标签。
(3)前向预测
- 词向量表特征表示:根据index,获取该词对应的词向量,该向量作为该词的特征数据,送入到RNN网络。
- RRN网络特征提取:根据词向量的特征输入,进行时序特征的提取。
- 全连接分类网络:根据提取的时序特征,预测下一个输出。
(3)SoftMax分类输出
获取输出是各个单词的可能性,不同的单词,其可能性大小不同。
(4)误差
把分类输出的可能性与OneHot的编码进行比较,获得交叉商loss值。
(5)梯度下降迭代
根据loss值,更新神经网络,包括:
- 全连接分类网络
- RRN网络特征提取
- 词向量表
词向量表示神经网络更新的一部分,词向量表示机器根据已知文本信息上下文自动学习获得的。
经过大量文本样本的输入,经过反复的迭代,网络最终获得最佳的词向量表分布。
3.10 词向量表的使用与模型预测
词向量表,能够真实的反应某个现存的文本,其单词在N维度的向量空间的分布特征。
因此,词向量表与特定的应用场合是相关的,它体现了现有文字、文章的单词的分布特征。
不同的应用场景,其单词的向量空间分布特征是不一样的。
利用获得的词向量表,就可以把他应用在某个特定领域的预测中,如自动编写新闻、自动编写古诗、自动音乐创作。
第4章 模型的优化
4.1 上述模型的不足
输入样本标签和输出,都采用的是OneHot编码和Softmax,对于词的分类数目少的文章,是可以应付的,但如果文章中,单词的数目超过上万,甚至几十万、上百万的文字系统,OneHot编码和softmax带来的内存空间的占用和计算量是非常非常大的。
大量的稀疏矩阵也会导致内存空间的浪费。
对于大型词库(词分类)的场合,就需要对上述模型进行优化!!!
上述模型不足的关键是:在一定的输入下,如何标识输出和其对应标签, 即OneHot编码。
- “1”的作用:其实真正有效的信息是“1”。
- “0”的作用:大量的“0”其实是无效信息,神经网络其实并不关注这些“0”, “0”唯一的作用,就是用来标识输入与输出在索引的对应关系!!!
4.2 模型的输入、输出优化:多分类问题转换成二分类问题
第1步: 单输出
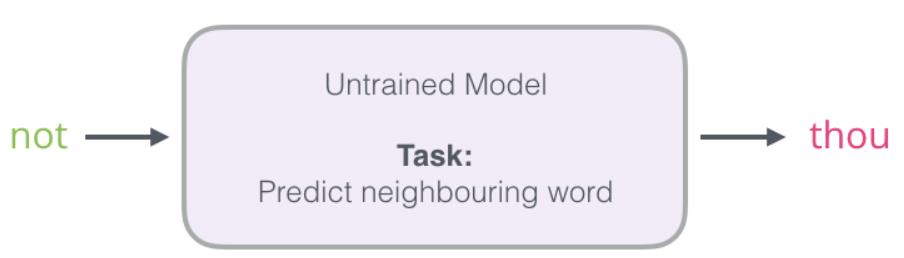
之所以需要OneHot编码,这是因为需要标识单词thou。
第2步:把输出单词转为输入单词序列的一部分

把输出某一个单词概率问题,转变成了,某种单词序列的组合的概率。
这种转变带了两个好处:
- 多分类问题转为二分类问题,简化模型的规模和计算。
- 与原始的文章序列输入更加的接近,更加的自然。
第3步:识别上述改进后的问题
但这样的转变也有一个缺点:样本标签始终为1,因为输出标签总是标识某个位置的单词在该组合中的概率,对于给定的某个输入序列,任意单词的在该组合中的概率都是“1” (不是在全文中的概率,而是在该次序列输入中的概率)

这就导致一个严重的问题,不管单词序列是什么,样本标签都是“1”。
导致训练时,神经网络就向“1”这个方向训练,或者说“瞎蒙”。
在OneHot编码时,OneHot编码自身,天然的携带了“0”和1, 即携带了"是什么”的概率和“不是什么”的概率。
然后,如果采用二分类标签时,那现存的文章输入,所有的输入都表明“是什么”,并没有信息表明“不是什么”,即什么样的组合是不存在的?
4.3 负样本标签
第4步:负样本标签
这就需要人为的构建一些负样本标,告诉神经网络,哪些组合是不可能存现的。
有正样本,有负样本,这样神经网络训练出来的结果,就不会再“瞎蒙”,而是真实的反应输入序列的特征。



负样本标签的本质是告诉神经网络,哪些单词的组合是不可能出现的!
负样本标签通常是人为生成的,也可以通过某种规则,自动生成负样本标签。
4.4 训练模型

(1)输入序列除了来自文章中的单词序列外,还需要构建负样本序列,即文章中不存在的单词序列
(2) 实际标签:对于正样本(即来自于实际文章中的单词序列),标签始终为“1”,对于人为构建的负样本,输出标签始终为“0”
(3)网络的输出值:二分类输出,因此可以使用sigmod输出,而不需要softmax
4.5 模型训练
(1)模型W矩阵

(2)样本标签
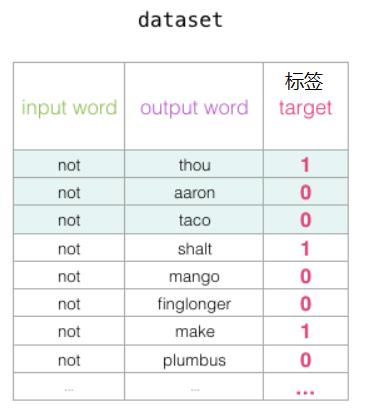
(3)权重更新

与传统模型更新不同,除了更新RNN网络和全连接网络的参数,还需要更新词向量表的权重参数。
第5章 作者感悟
(1)人工智能、机器学习、深度学习的本质:
通过某种数学模型,能否发现海量数据中的规律,并用这些发现的规律,对新数据的输入进行预测和创作。
(2)这些海量数据(超大维度)涉及到社会、自然的方方面面:
- 社会:房价、股市、人口流动、购物特征.......
- 自然:天气的运动、原子的运动规律........
- 个人:个人特色的音乐、个人的性格行为特征、
(3)所谓规律
就是存在于已发生事件、已发生数据中的内在的特征。
(4)所谓预测
所谓预测,不仅仅是预测未来,还有多层含义
- 预测未来:所谓预测未来,就是新数据、新事件的发生,必须等到一定的时间后才能发生,新数据、新事件的发生是不可控的,但可以用历史数据、历史时间来预测新事件、新数据。
- 个人作品鉴别:通过机器学习,获得个人的历史作品,包括文章、图片、音乐等特征,然后,判断一个新作品,是否符合原作品的特征,来判断作品的真假。
- 个人作品创作:通过机器学习,获得个人的历史作品,包括文章、图片、音乐等特征,创作符合现有特征的新的作品。
(5)懂得大数据分析的人,人生都不会太差
(6)哲学是内涵
要想发现更多的原创性的规律和创建原创性的模型,除了数学,更进一步的是需懂得哲学。
哲学最最重要的作用是:能否发现一些深层次的原创性的问题!!!
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/121709147
以上是关于[人工智能-深度学习-56]:循环神经网络 - 词向量的自动构建与模型训练的主要内容,如果未能解决你的问题,请参考以下文章
[人工智能-深度学习-51]:循环神经网络RNN基本原理详解