数据挖掘之关联规则实战关联规则智能推荐算法
Posted 爱运动的小陈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据挖掘之关联规则实战关联规则智能推荐算法相关的知识,希望对你有一定的参考价值。
数据说明
数据参数
OrderNumber: 客户昵称
LineNumber:购买顺序,如前三行分别表示同一个客户购买的三样商品
Model:商品名
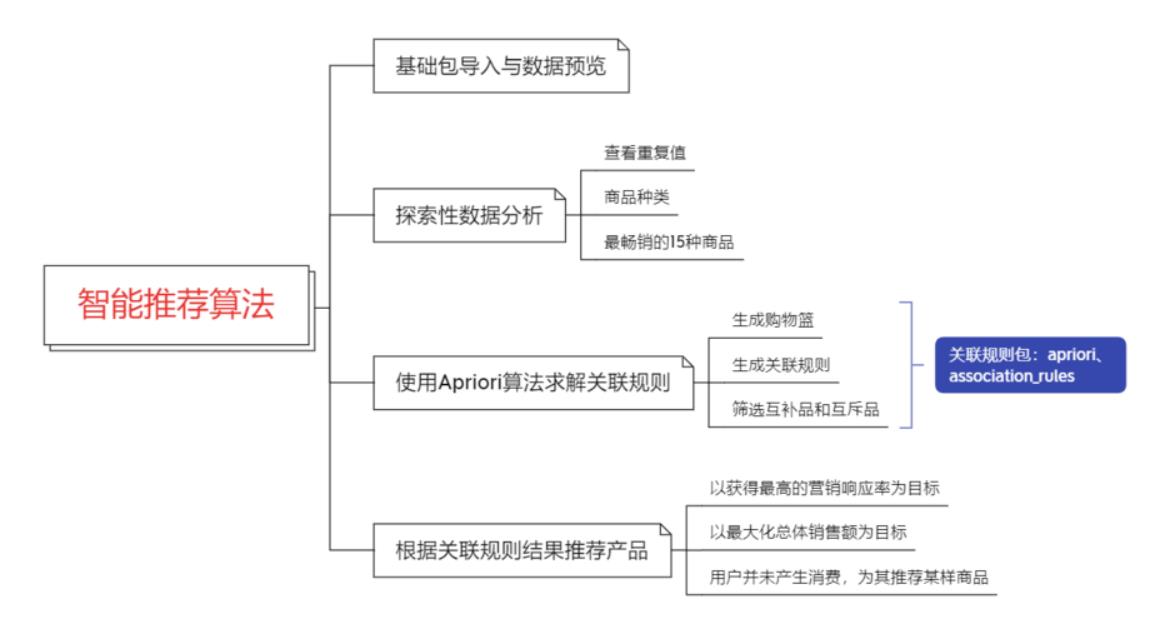
问题描述
基于购物篮的关联规则智能算法推荐的应用。
三个基本问题:
1、以获得最高的营销响应率为目标,该如何推送商品?
2、以最大化总体销售额为目标,该如何推荐商品
3、用户并未产生消费,为其推荐某样商品?


智能推荐算法有很多种,本文只对关联规则进行实践。
本文将专注于理解起来最容易且又十分经典常用的基于关联规则的购物篮推荐。商品的关联度分析对于提高商品的活力、挖掘消费者的购买力、促进最大化销售有很大帮助。
其建模理念为:物品被同时购买的模式反映了客户的需求模式。
适用场景:无需个性化定制的场景;有销售记录的产品,向老客户推荐;套餐设计与产品摆放。
购物篮简介
问:什么是购物篮?主要运用在什么场景?
答:单个客户一次购买商品的综合称为一个购物篮,即某个客户本次的消费小票。常用场景:超市货架布局:互补品与互斥品;套餐设计。
问:购物篮的常用算法?
答:常用算法有
不考虑购物顺序:关联规则。购物篮分析其实就是一个因果分析。关联规则其实是一个很方便的发现两样商品关系的算法。共同提升的关系表示两者是正相关,可以作为互补品,如豆瓣酱和葱一起卖也才是最棒的。替代品的概念便是我买了这个就不用买另外一个。
考虑购物顺序:序贯模型。多在电商中使用,比如今天你将这个商品加入了购物车,过几天又将另一个商品加入了购物车,这就有了一个前后顺序。但许多实体商店因为没有实名认证,所以无法记录用户的消费顺序。
问:求出互补品与互斥品后对布局有什么用?
答:根据关联规则求出的商品间的关联关系后,可能会发现商品间存在强关联,弱关联与排斥三种关系。每种清醒有各自对应的布局方式。
强关联:关联度的值需要视实际情况而定,在不同的行业不同的也业态是不同的。强关联的商品彼此陈列在一起会提高双方的销售量。双向关联的商品如果陈列位置允许的话应该相关联陈列,即A产品旁边有B,B产品边上也一定会有A,比如常见的剃须膏与剃须刀,男士发油与定型梳;而对于那些单向关联的商品,只需要被关联的商品陈列在关联商品旁边就行,如大瓶可乐旁边摆纸杯,而纸杯旁边则不摆大瓶可乐,毕竟买大可乐的消费者大概率需要纸杯,而购买纸杯的顾客再购买大可乐的概率不大。
弱关联:关联度不高的商品,可以尝试摆在一起,然后再分析关联度是否有变化,如果关联度大幅提高,则说明原来的弱关联有可能是陈列的原因造成的。
排斥关系:指两个产品基本上不会出现在同一张购物小票中,这种商品尽量不要陈列在一起。
根据购物篮的信息来进行商品关联度的分析不仅仅只有如上三种关系,它们仅代表商品关联度分析的一个方面(可信度)。全面系统的商品关联分析必须有三度的概念,三度包括支持度,可信度和提升度。
关联规则
直接根据关联三度所定义的概念去理解会有不少难度,尤其是可信度喝提升度中的“ 谁对谁 ”的问题。其实可以换一种方式来看:
规则 X 的支持度 = 规则 X 的交易次数 / 交易的总数。理解:支持度表示规则 X 是否普遍。
规则 X(A→B) 的置信度 = 规则 X 的交易次数/规则X中商品B 的交易次数。理解:置信度是一种条件概率,表示购买了A产品的客户再购买B产品的概率。
问:仅看支持度和置信度是否靠谱?
答:看一个案例:食堂卖饭,1000份打饭记录中,买米饭的有800人次,买牛肉的有600人次,两个共同买的有400人次,那么可以得出对于规则(牛肉 - > 米饭)Support=P(牛肉&米饭)= 400/1000=0.40;Confidence=P(米饭|牛肉)=400/600=0.67置信度和支持度都很高,但是给买牛肉的人推荐米饭有意义吗?显然是没有任何意义的。因为无任何条件下用户购买米饭的概率:P(米饭)=800/1000=0.8,都已经大过买了牛肉的前提下再买米饭的概率 0.67,毕竟米饭本来就比牛肉要畅销啊。
这个案例便引出了提升度的概念:提升度 = 置信度/无条件概率=0.67/0.8。规则 X(A→B) 的提升度为 n 时:向购买了 A 的客户推荐 B 的话,这个客户购买 B 的概率是 TA 自然而然购买 B 的 n × 100% 左右。生活理解:消费者平时较少单独购买桌角防撞海绵,可能偶尔想到或自己小孩碰到的时候才会想起购买,如果我们在桌子(书桌饭桌)的成功下单页面添加桌角防撞海绵的推荐,则很大程度上可以提高防撞海绵的销量。这也符合我们希望通过畅销商品带动相对非畅销商品的宗旨。
问:除了公式的含义,关联三度(支持度,置信度,提升度)还有什么关联吗?
答:可以这样理解:
支持度代表这组关联商品的份额是否够大
置信度(可信度)代表关联度的强弱
而提升度则是看该关联规则是否有利用价值和值得推广,用了(客户购买后推荐)比没用(客户自然而然的购买)要提高多少。
所以 1.0 是提升度的一个分界值,刚才的买饭案例中给买了牛肉的用户推荐米饭的这种骚操作的提升度小于 1 也就不难理解了。另外,高置信度的两个商品(假设达到了 100%,意味着它们总是成双成对的出现),但如果支持度很低(意味着份额低),那它对整体销售提升的帮助也不会大。
关联规则Python代码
导入基本包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
# 各种细节配置如 图像大小、轴标签、刻度、文字大小,图例文字等杂项
large = 22; med = 16; small = 12
params = 'axes.titlesize': large,
'legend.fontsize': med,
'figure.figsize': (16, 10),
'axes.labelsize': med,
'axes.titlesize': med,
'xtick.labelsize': med,
'ytick.labelsize': med,
'figure.titlesize': large
plt.rcParams.update(params)
plt.style.use('seaborn-whitegrid')
sns.set_style("white")
plt.rc('font', **'family': 'Microsoft YaHei, SimHei') # 设置中文字体的支持
# sns.set(font='SimHei') # 解决Seaborn中文显示问题,但会自动添加背景灰色网格
plt.rcParams['axes.unicode_minus'] = False
# 解决保存图像是负号'-'显示为方块的问题
数据概览
#读取文件使用utf-8会出现解码错误,需要更改为gbk解码
bike=pd.read_csv("C://Python//分享资料3//bike_data.csv",encoding='gbk')
print(bike.head())
print(bike.info())
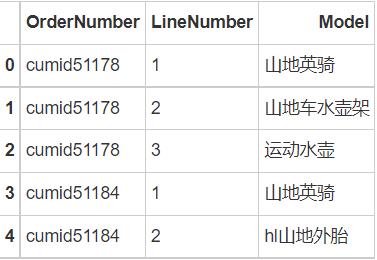

OrderNumber: 客户昵称
LineNumber:购买顺序,如前三行分别表示同一个客户购买的三样商品
Model:商品名
探索性数据分析EDA
#查看缺失值
print(bike.isnull().sum())
#查看重复值
print(bike.duplicated().sum())

商品种类探索
model=bike['Model'].nunique()
modelnames=bike['Model'].unique()
print("共有"+str(model)+"种商品\\n")
print("商品名分别为:\\n")
#每行显示5个
for i in range(0,len(modelnames),5):
print(modelnames[i:i+5])

#最畅销的15种商品
bestseller = bike.groupby('Model')['Model'].count().sort_values(ascending=False).reset_index(name='count')
bestseller.head(15)
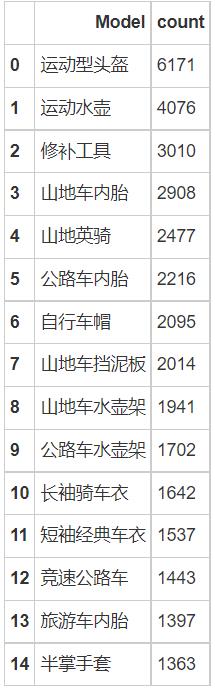
top_15 = bestseller.head(15)
sns.barplot(x='count',y='Model',data=top_15)
plt.title('最畅销的15种商品')
plt.grid(True)

top_15 = top_15['Model'].tolist()
print('由销量排名,该自行车店排名前15的畅销单品为:')
for i in range(0,15,5):
print(top_15[i:i+5])

使用Apriori算法求解关联规则
from mlxtend.frequent_patterns import apriori as apri
# 生成购物篮:将同一个客户购买的所有商品放入同一个购物篮
baskets =bike.groupby('OrderNumber')['Model'].apply(lambda x :x.tolist())
baskets = list(baskets)
#导入关联规则算法的包
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
#转换为算法可接受模型(布尔值)
te = TransactionEncoder()
baskets_tf = te.fit_transform(baskets)
df = pd.DataFrame(baskets_tf,columns=te.columns_)
print(df.head(5))
编码后的数据:

维度是(21255, 37),行表示共有21255个用户,列表示对应用户下商品是否购买,如果购买了则该商品下为true,否则false。当用户量与商品量非常巨大时,矩阵维度也会非常大。
#设置支持度求频繁项集
frequent_itemsets = apriori(df,min_support=0.01,use_colnames= True)
#求关联规则,设置最小置信度为0.15
rules = association_rules(frequent_itemsets,metric = 'confidence',min_threshold = 0.1)
#设置最小提升度
# rules = rules.drop(rules[rules.lift <1.0].index)
#设置标题索引并打印结果
rules.rename(columns = 'antecedents':'lhs','consequents':'rhs','support':'sup','confidence':'conf',inplace = True)
rules = rules[['lhs','rhs','sup','conf','lift']]
print(rules)
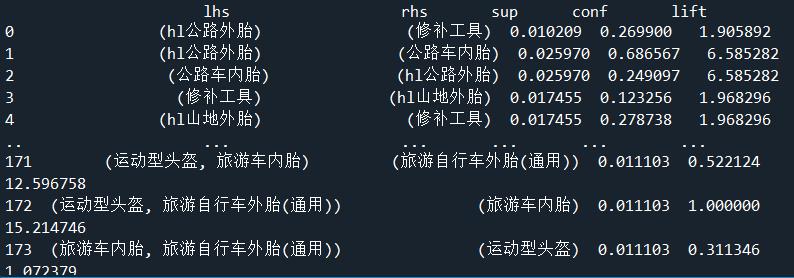
- lhs: 被称为左手规则,通俗理解即用户购买的商品 - 山地车内胎
- 被称为右手规则,通俗理解即根据用户购买某商品来推荐的另一件商品 - ll山地胎
- support: 支持度,山地车内胎 和 ll山地胎 同时出现在一张购物小票中的概率
- confidence: 置信度,购买了 山地车内胎 的前提下,同时购买 ll山地胎 的概率
- lift:向购买了 山地车内胎 的客户推荐 ll山地胎 的话,这个客户购买 ll山地胎 的概率是这个客户自然而然购买 ll山地胎 的 400% 左右,即高了 300% 多,通俗理解:消费者平时较少单独购买桌角防撞海绵,可能偶尔想到的时候或自己小孩碰到的时候才会想起购买,如果我们在桌子(书桌饭桌)的成功下单页面添加桌角防撞海绵的推荐,则很大程度上可以提高防撞海绵的销量。这也符合我们在探索性数据分析中发现的前 15 名畅销商品后并希望通过畅销商品带动“相对非畅销商品”的宗旨。
筛选互补品和互斥品
# 互补品
# lift 提升度首先要大于1,然后再排序选择自己希望深究的前 n 个
complementary = rules[rules['lift'] > 1].sort_values(by='lift', ascending=False).head(20)
# 互斥品
#lift提升都首先要小于1,然后再排序选择自己希望深究的前n个
exclusive = rules[rules['lift'] < 1].sort_values(by='lift', ascending=True).head(20)
### 根据关联规则结果推荐产品
需要结合业务需求
- 获得最大营销响应度?-- 看置信度,越高越好
- 销售最大化?-- 看提升度,越高越好
- 用户未产生消费,我们向其推荐商品?
1、获得最高的营销响应率
如果一个客户刚刚下单了山地车英骑这个产品,那么在他付费成功页面上最应该推荐什么产品才能获得最高的营销响应率。
# 使用的是左手规则:lhs(left hand rules),lhs 表示的是购买的产品
## 使用 frozenset 来对字典的键进行选择
purchase_good = rules[rules['lhs'] == frozenset('山地英骑')]
print(purchase_good.sample(3))
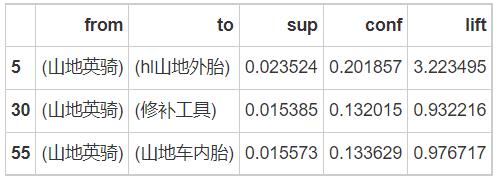
# 根据置信度排序
print(purchase_good.sort_values(by='conf', ascending=False))
# 根据下表,应该首先推荐山地车挡泥板
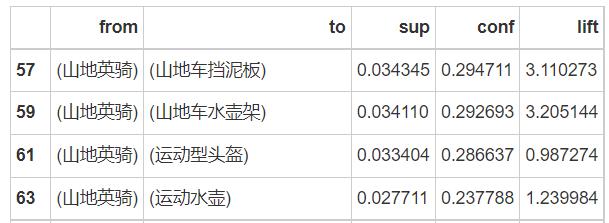
1、获得最大化销售额
如果一个新客户刚下单了 山地英骑 这个产品,
如果希望最大化提升总体的销售额,那么在他付费成功的页面上应该推荐什么产品?
print(purchase_good.sort_values(by='lift', ascending=False))
# 由下表可知,应该首推 hl 山地车外胎

提升度是相对于自然而然购买而言,A对B的提升度为4.0的理解如下
向购买了A的用户推荐B,则该用户购买B的概率是该用户单独
(即自然而然的购买)购买B的概率的 400%
向购买了A的用户推荐B,则该用户购买B的概率比该用户单独
(即自然而然的购买)购买B的概率 \\textbf高 300%
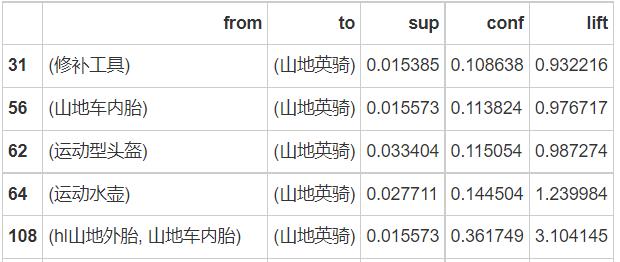
3、用户并未产生消费,我们为其推荐某样商品
# 如果希望推荐山地英骑自行车,应该如何制定营销策略?
## 这里应该选出右手规则,因为直接就是推荐的产品,
##没有产生消费,消费了的即买了的才使用左手规则
purchase_good = rules[rules['rhs'] == frozenset('山地英骑')].sort_values('lift')
# 根据置信度或提升度排序都可以,因为直接根据右手规则选出来的数据框中,
## confidence 和 lift 成正比例关系,你高我就高
print(purchase_good)
# 所以山地英骑跟山地车水壶架,山地车挡泥板,hl山地外胎一起推荐比较好
以上是关于数据挖掘之关联规则实战关联规则智能推荐算法的主要内容,如果未能解决你的问题,请参考以下文章
python数据分析与挖掘学习笔记-电商网站数据分析及商品自动推荐实战与关联规则算法
python数据分析与挖掘学习笔记-电商网站数据分析及商品自动推荐实战与关联规则算法
R语言使用apriori算法进行关联规则挖掘实战:关联规则概念频繁项集支持度(support)置信度(confidence)提升度(lift)apriori算法