推荐算法基于关联规则的推荐算法
Posted 智能推荐系统
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐算法基于关联规则的推荐算法相关的知识,希望对你有一定的参考价值。
导读
基于关联规则的推荐是根据历史数据统计不同规则出现的关系及概率,用于指导新的推荐。它是一种常用的经典推荐算法,本文在分析关联规则算法的基础上再介绍一种在实际业务当中简单实用的关联规则算法。
一、算法简介
关联规则是常见的推荐算法,从发现大量用户行为数据中发现有强关联的规则。它是一种无监督的机器学习方法,用于知识发现。
基于关联规则的推荐是根据历史数据统计不同规则出现的关系,形如:X->Y,表示X事件发生后,Y事件会有一定概率发生,这个概率是通过历史数据统计而来。
对于一个规则X->Y,有两个指标对该规则进行衡量。一个是支持度,表示在所有样本数据中,同时包含X和Y样本的占比。另一个是置信度,表示在所有包含X的样本中,包含Y的样本占比。
关联规则推荐算法的优缺点也比较明显,如下:
优点
能够从大量行为数据中挖掘出无法直接感受到的规则,往往能给出意想不到的规则组合。
缺点
难以进行模型评估,一般通过行业经验判断结果是否合理。
二、基础概念
下面介绍几个关联规则推荐中的基本概念:
前项和后项
假设存在规则{A,B}->{C},则称:
{A,B}为前项,记为LHS(Left Hand Side)
{C}为后项,记为RHS(Right Hand Side)
支持度
支持度的计算对象为项集,上例中,{A,B},{C}均为项集。项集支持度,即项集在所有交易中出现的交易数。support(A)=n(A)/N
置信度(confidence)
置信度的对象是规则,{A}->{B}为一条规则,以该规则为例,其置信度为AB同时出现的次数占B出现的次数比例,即confidence(A->B)=N(AB)/N(B)
提升度(lift)
规则的提升度在于说明项集{A}和项集{B}之间的独立性,Lift=1说明{A}和{B}相互独立,说明两个条件没有任何关联。如果Lift<1,说明两个事件是互斥的。一般认为Lift>3才是有价值的规则。可以这样理解规则的提升度:将两种物品捆绑销售的结果,比分别销售两种物品的结果提升的倍数。support和confidence都很高的时候,不代表规则很好,通常很可能是Lift很高。计算公式如下:
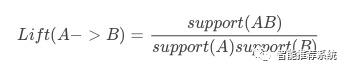
频繁项集
支持度大于一定阈值的规则成为频繁项集,这个阈值通常由经验给出,或者通过对数据探索得到。
强关联规则
置信度大于一定阈值的频繁项集为强关联规则,阈值通常也是通过经验给出,或通过数据探索得到,可通过不断的尝试和调整确定合适的阈值。
三、算法及业务实践
关联规则最经典的是购物篮分析,啤酒和尿布就是一个经典案例。运用在早期亚马逊、京东、淘宝等购物推荐场景中,往往表现为”买过这本书的人还买了XXX”,”看了这部电影的人还想看XXX”。其推荐结果包含的个性化信息较低,相对简单粗暴。
在关联推荐算法中,最主要的是如何找到最大频繁项,业界主要的做法有Apriori算法、FP-Growth树和Eclat(具体算法的思想可以自行在网上查到)。但在互联网海量的用户特征中,使用这些算法挖掘频繁集计算复杂度非常高,下面我们介绍一种在业务当中简单实用的关联规则算法。
同样是以购物篮子为例,业务场景是:根据用户历史购物记录,给用户推荐商品。下面我们介绍如何构建简单的关联规则推荐算法。
Step1:数据准备
首先收集用户展示购买记录,并且关联用户在展示时刻的特征数据。设总样本数量为n条,数据格式如下:
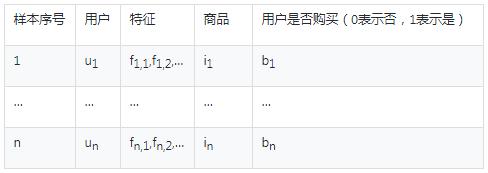
表1:初始数据
其中用户特征可以是用户历史购买的商品ID,也可以是用户属性特征,例如:年龄、性别、居住地等等。
Step2:特征交叉
在上表中,对于同一个样本所有特征两两交叉,生成长度为2的特征规则,合并原来的长度为1的特征规则,得到关联规则数据输入表如下:
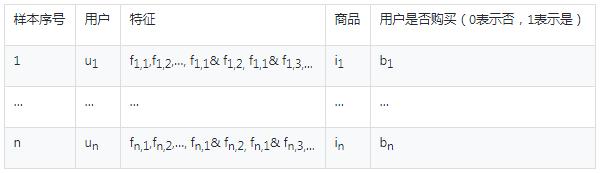
表2:rule输入数据
上述表中只用长度为1(原始特征)和2(原始特征两两交叉)的规则作为后面rule的候选集,不做长度为3的规则主要的考虑点是降低规则空间复杂度。
Step3:生成关联规则
首先把上表的特征展开,使得一个特征一条记录,如下表:
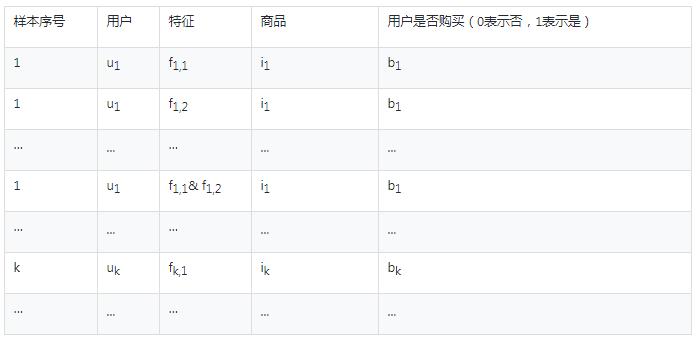
表3:展开数据
计算每个规则的支持度,置信度,提升度。首先作变量声明:
f->i 表示具备特征f的用户购买商品i的事件
sf,i 表示规则f->i的支持度
cf,i 表示规则f->i的置信度
sf,i 计算方法为:统计表3中中同时满足特征=f,商品=i,用户是否购买=0的记录条数记为notbuyersf,i
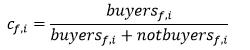
规则选择,规则可以通过以下条件进行过滤。
条件1:大于等于某个值,参考值取20-100。
条件2:对所有规则的支持度做降序,取75位数为参考值,sf,i大于等于这个值。
条件3:对所有规则的置信度做降序,取75位数为参考值,cf,i大于等于这个值。
Step4:给用户推荐商品
给定一个用户u和一个商品i,通过上述方法生成用户u的特征集合记为F. 我们用该用户特征集合下,所有对i有效特征的均值衡量用户u对该物品的购买可能性p(u,i):
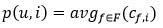
通过上述公式对全库商品求top 10得分的商品推荐给用户。在实际计算当中,并非会进行全库计算,而是采用特征索引技术进行减少大量冗余计算。
「 更多干货,更多收获 」
以上是关于推荐算法基于关联规则的推荐算法的主要内容,如果未能解决你的问题,请参考以下文章