一文理解 K8s 容器网络虚拟化
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文理解 K8s 容器网络虚拟化相关的知识,希望对你有一定的参考价值。
简介:本文需要读者熟悉 Ethernet(以太网)的基本原理和 Linux 系统的基本网络命令,以及 TCP/IP 协议族并了解传统的网络模型和协议包的流转原理。文中涉及到 Linux 内核的具体实现时,均以内核 v4.19.215 版本为准。

作者 | 浅奕
来源 | 阿里技术公众号
本文需要读者熟悉 Ethernet(以太网)的基本原理和 Linux 系统的基本网络命令,以及 TCP/IP 协议族并了解传统的网络模型和协议包的流转原理。文中涉及到 Linux 内核的具体实现时,均以内核 v4.19.215 版本为准。
一 内核网络包接收流程
1 从网卡到内核协议栈
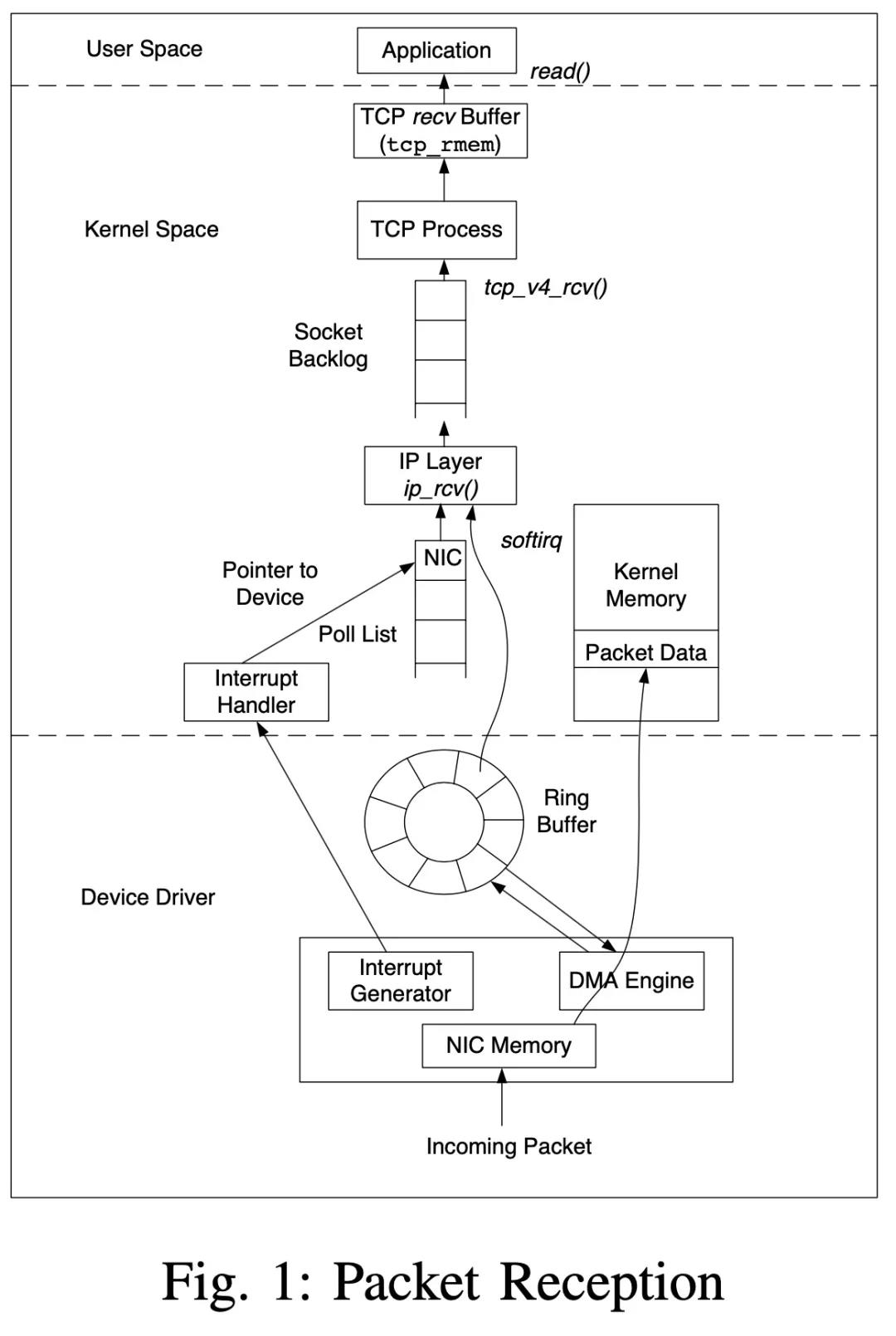
如图[1],网络包到达 NC(Network Computer,本文指物理机)时,由 NIC(Network Interface Controller,网络接口控制器,俗称网卡)设备处理,NIC 以中断的方式向内核传递消息。Linux 内核的中断处理分为上半部(Top Half)和下半部(Bottom Half)。上半部需要尽快处理掉和硬件相关的工作并返回,下半部由上半部激活来处理后续比较耗时的工作。
具体到 NIC 的处理流程如下:当 NIC 收到数据时,会以 DMA 方式将数据拷贝到 Ring Buffer (接收队列) 里描述符指向的映射内存区域,拷贝完成后会触发中断通知 CPU 进行处理。这里可以使用 ethtool -g 设备名,如eth0 命令查看 RX/TX (接收/发送)队列的大小。CPU 识别到中断后跳转到 NIC 的中断处理函数开始执行。此时要区分 NIC 的工作模式,在早先的非 NAPI(New API)[2]模式下,中断上半部更新相关的寄存器信息,查看接收队列并分配 sk_buff 结构指向接收到的数据,最后调用 netif_rx() 把 sk_buff 递交给内核处理。在 netif_rx() 的函数的流程中,这个分配的 sk_buff 结构被放入 input_pkt_queue队列后,会把一个虚拟设备加入poll_list 轮询队列并触发软中断 NET_RX_SOFTIRQ 激活中断下半部。此时中断上半部就结束了,详细的处理流程可以参见 net/core/dev.c 的 netif_rx() -> netif_rx_internal() -> enqueue_to_backlog() 过程。下半部 NET_RX_SOFTIRQ 软中断对应的处理函数是 net_rx_action(),这个函数会调用设备注册的 poll() 函数进行处理。非 NAPI 的情况下这个虚拟设备的 poll() 函数固定指向 process_backlog() 函数。这个函数将 sk_buff 从 input_pkt_queue 移动到 process_queue 中,调用 __netif_receive_skb() 函数将其投递给协议栈,最后协议栈相关代码会根据协议类型调用相应的接口进行后续的处理。特别地,这里的 enqueue_to_backlog() 以及 process_backlog() 函数也用于和启用了 RPS 机制后的相关逻辑。
非 NAPI(New API)模式下每个网络包的到达都会触发一次中断处理流程,这么做降低了整体的处理能力,已经过时了。现在大多数 NIC 都支持 NAPI 模式了。NAPI 模式下在首包触发 NIC 中断后,设备就会被加入轮询队列进行轮询操作以提升效率,轮询过程中不会产生新的中断。为了支持 NAPI,每个 CPU 维护了一个叫 softnet_data 的结构,其中有一个 poll_list 字段放置所有的轮询设备。此时中断上半部很简单,只需要更新 NIC 相关的寄存器信息,以及把设备加入poll_list 轮询队列并触发软中断 NET_RX_SOFTIRQ就结束了。中断下半部的处理依旧是 net_rx_action() 来调用设备驱动提供的 poll() 函数。只是 poll() 此时指向的就是设备驱动提供的轮询处理函数了(而不是非 NAPI 模式下的内核函数 process_backlog())。这个设备驱动提供的轮询 poll() 函数最后也会调用 __netif_receive_skb() 函数把 sk_buff 提交给协议栈处理。
非 NAPI 模式和 NAPI 模式下的流程对比如下(其中灰色底色是设备驱动要实现的,其他都是内核自身的实现):
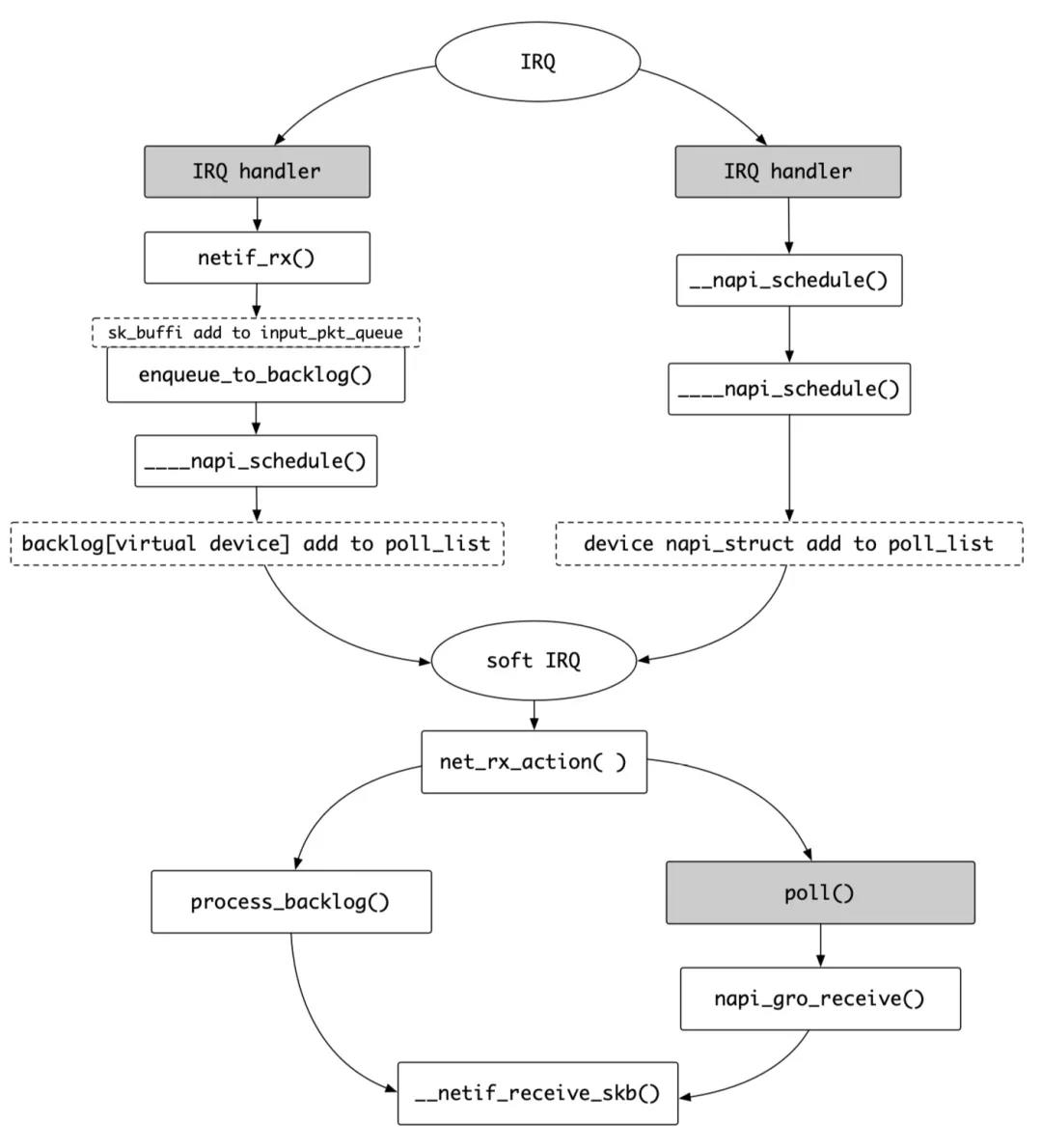
关于 NAPI 模式网络设备驱动的实现以及详细的 NAPI 模式的处理流程,这里提供一篇文章和其译文作为参考[3](强烈推荐)。这篇文章很详细的描述了 Intel Ethernet Controller I350 这个 NIC 设备的收包和处理细节(其姊妹篇发包处理过程和译文[4])。另外收包这里还涉及到多网卡的 Bonding 模式(可以在/proc/net/bonding/bond0 里查看模式)、网络多队列(sudo lspci -vvv 查看 Ethernet controller 的 Capabilities信息里有 MSI-X: Enable+ Count=10 字样说明 NIC 支持,可以在 /proc/interrupts 里查看中断绑定情况)等机制。这些本文都不再赘述,有兴趣的话请参阅相关资料[5]。
2 内核协议栈网络包处理流程
前文说到 NIC 收到网络包构造出的 sk_buff 结构最终被 __netif_receive_skb() 提交给了内核协议栈解析处理。这个函数首先进行 RPS[5] 相关的处理,数据包会继续在队列里转一圈(一般开启了 RSS 的网卡不需要开启 RPS)。如果需要分发包到其他 CPU 去处理,则会使用 enqueue_to_backlog() 投递给其他 CPU 的队列,并在 process_backlog()) 中触发 IPI(Inter-Processor Interrupt,处理器间中断,于 APIC 总线上传输,并不通过 IRQ)给其他 CPU 发送通知(net_rps_send_ipi()函数)。
最终,数据包会由 __netif_receive_skb_core() 进行下一阶段的处理。这个处理函数主要的功能有:
- 处理ptype_all 上所有的 packet_type->func(),典型场景是 tcpdump 等工具的抓包回调(paket_type.type 为 ETH_P_ALL,libcap 使用 AF_PACKET Address Family)
- 处理 VLAN(Virtual Local Area Network,虚拟局域网)报文 vlan_do_receive() 以及处理网桥的相关逻辑(skb->dev->rx_handler() 指向了 br_handle_frame())
- 处理 ptype_base上所有的 packet_type->func() , 将数据包传递给上层协议层处理,例如指向 IP 层的回调 ip_rcv() 函数
截至目前,数据包仍旧在数据链路层的处理流程中。这里复习下 OSI 七层模型与 TCP/IP 五层模型:
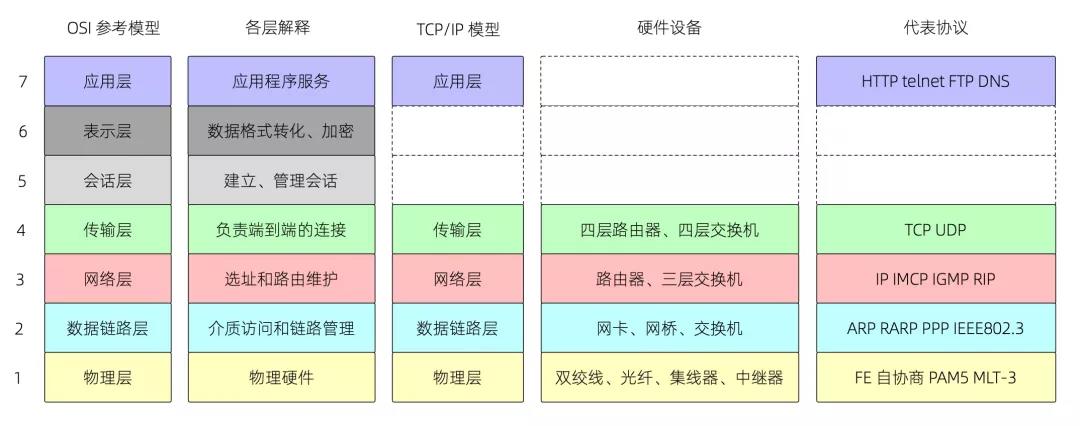
在网络分层模型里,后一层即为前一层的数据部分,称之为载荷(Payload)。一个完整的 TCP/IP 应用层数据包的格式如下[6]:
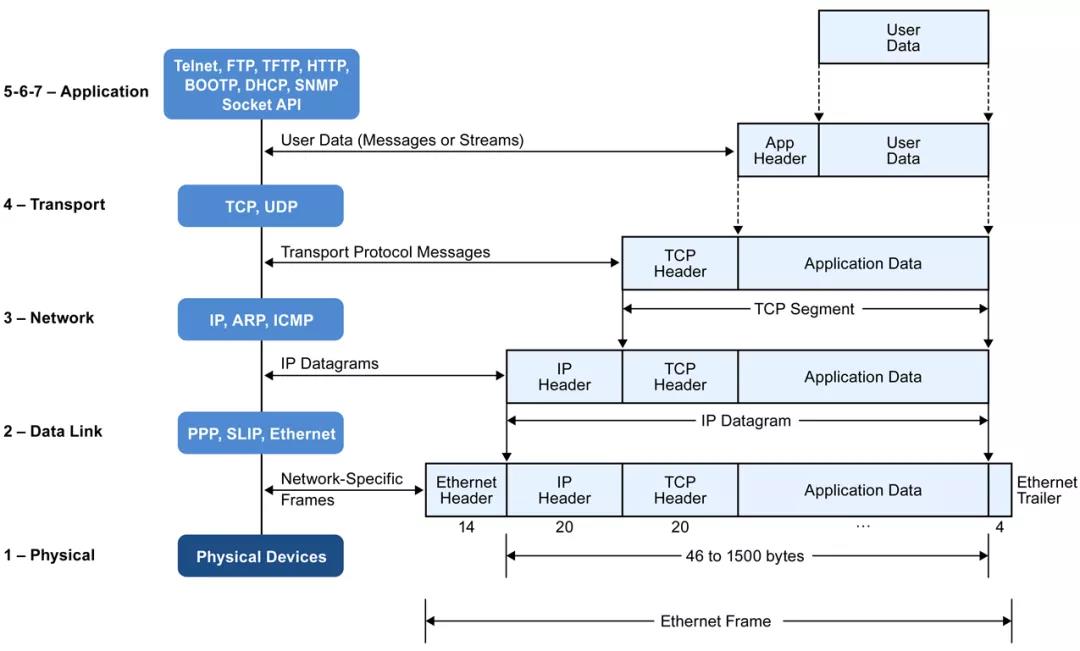
__netif_receive_skb_core() 的处理逻辑中需要关注的是网桥和接下来 IP 层以及 TCP/UDP 层的处理。首先看 IP 层,__netif_receive_skb_core() 调用 deliver_skb(),后者调用具体协议的 .func() 接口。对于 IP 协议,这里指向的是 ip_rcv() 函数。这个函数做了一些统计和检查之后,就把包转给了 Netfilter [7]框架并指定了函数 ip_rcv_finish() 进行后续的处理(如果包没被 Netfilter 丢弃)。经过路由子系统检查处理后,如果包是属于本机的,那么会调用 ip_local_deliver() 将数据包继续往上层协议转发。这个函数类似之前的逻辑,依旧是呈递给 Netfilter 框架并指定函数 ip_local_deliver_finish() 进行后续的处理,这个函数最终会检查和选择对应的上层协议接口进行处理。
常见的上层协议比如 TCP 或者 UDP 协议的流程不在本文讨论的范围内,仅 TCP 的流程所需要的篇幅足以超过本文所有的内容。这里给出 TCP 协议(v4)的入口函数 tcp_v4_rcv() 以及 UDP 协议的入口函数 udp_rcv() 作为指引自行研究,也可以阅读其他的资料进行进一步的了解[9]。
3 Netfilter/iptables 与 NAT(网络地址转换)
关于 Netfilter 框架需要稍微着重的强调一下,因为后文要提到的网络策略和很多服务透出的实现都要使用 Netfilter 提供的机制。
Netfilter 是内核的包过滤框架(Packet Filtering Framework)的实现。简单说就是在协议栈的各个层次的包处理函数中内置了很多的 Hook 点来支持在这些点注册回调函数。
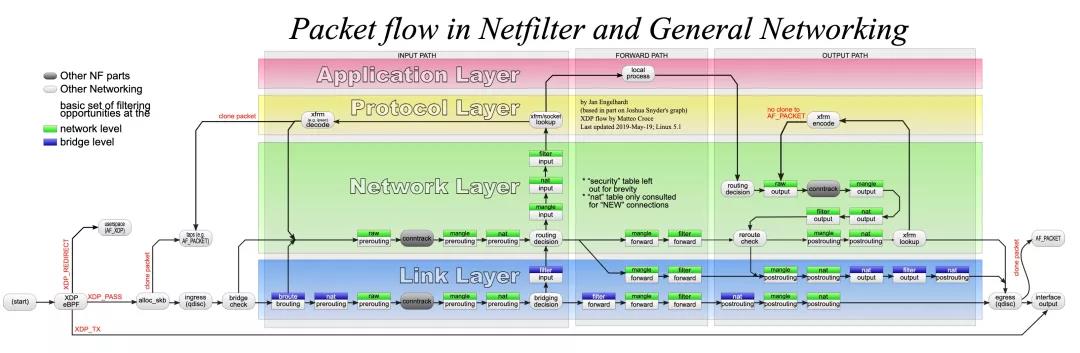
图片来自 Wikimedia,可以点开参考文献[8]查看大图(svg 矢量图,可以调大网页显示百分比继续放大)。
Linux 上最常用的防火墙 iptables 即是基于 Netfilter 来实现的(nftables 是新一代的防火墙)。iptables 基于表和链(Tables and Chains)的概念来组织规则。注意这里不要被“防火墙”这个词误导了,iptables 所能做的不仅仅是对包的过滤(Filter Table),还支持对包进行网络地址转换(NAT Table)以及修改包的字段(Mangle Table)。在网络虚拟化里,用的最多的便是 NAT 地址转换功能。通常此类功能一般在网关网络设备或是负载均衡设备中很常见。当 NC 需要在内部进行网络相关的虚拟化时,也是一个类似网关以及负载均衡设备了。
在设置 iptables 的 NAT 规则前,还需要打开内核的包转发功能 echo "1" > /proc/sys/net/ipv4/ip_forward 才可以。另外建议也打开 echo "1" /proc/sys/net/bridge/bridge-nf-call-iptables 开关(可能需要 modprobe br_netfilter)。bridge-nf-call-iptables 从上面的源码分析就能理解,网桥的转发处理是在 Netfilter 规则之前的。所以默认情况下二层网桥的转发是不会受到三层 iptables 的限制的,但是很多虚拟化网络的实现需要 Netfilter 规则生效,所以内核也支持了让网桥的转发逻辑也调用一下 Netfilter 的规则。这个特性默认情况不开启,所以需要检查开关。至于具体的 iptables 命令,可以参考这篇文章和其译文[10]进行了解,本文不再讨论。
这里强调下,Netfilter 的逻辑运行在内核软中断上下文里。如果 Netfilter 添加了很多规则,必然会造成一定的 CPU 开销。下文在提到虚拟化网络的性能降低时,很大一部分开销便是源自这里。
二 虚拟网络设备
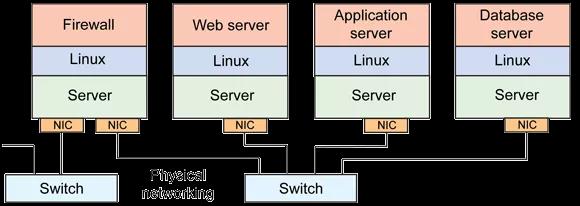
在传统的网络认知里,网络就是由带有一个或多个 NIC 的一组 NC 使用硬件介质和 switch(交换机)、Router(路由器)所组成的一个通信集合(图片来自 [11],下同):
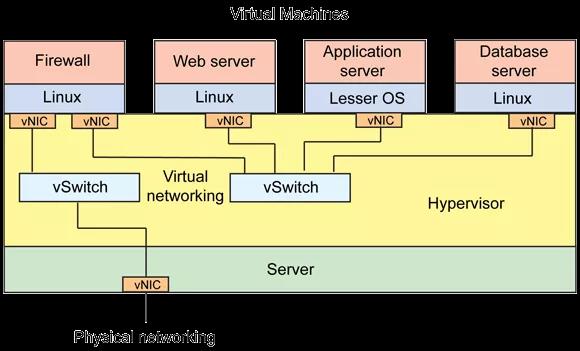
网络虚拟化作为 SDN(Software Defined Network,软件定义网络)的一种实现,无非就是虚拟出 vNIC(虚拟网卡)、vSwitch(虚拟交换机)、vRouter(虚拟路由器)等设备,配置相应的数据包流转规则而已。其对外的接口必然也是符合其所在的物理网络协议规范的,比如 Ethernet 和 TCP/IP 协议族。
随着 Linux 网络虚拟化技术的演进,有了若干种虚拟化网络设备,在虚拟机和虚拟容器网络中得到了广泛的应用。典型的有 Tap/Tun/Veth、Bridge 等:
- Tap/Tun 是 Linux 内核实现的一对虚拟网络设备,Tap/Tun 分别工作在二层/三层。Linux 内核通过 Tap/Tun 设备和绑定该设备的用户空间之间交换数据。基于 Tap 驱动即可实现虚拟机 vNIC 的功能,Tun 设备做一些其他的转发功能。
- Veth 设备总是成对创建(Veth Pair),一个设备收到内核发送的数据后,会发送到另一个设备上去,可以把 Veth Pair 可以想象成一对用网线连接起来的 vNIC 设备。
- Bridge 是工作在二层的虚拟网桥。这是虚拟设备,虽然叫网桥,但其实类似 vSwitch 的设计。当 Bridge 配合 Veth 设备使用时,可以将 Veth 设备的一端绑定到一个Bridge 上,相当于真实环境把一个 NIC 接入一个交换机里。
虚拟机和容器的网络在传输流程上有些区别,前者比如 KVM 一般是使用 Tap 设备将虚拟机的 vNIC 和宿主机的网桥 Bridge 连接起来。而容器的 Bridge 网络模式是将不同 Namespace 里的 Veth Pair 连接网桥 Bridge 来实现通信(其他方式下文讨论)。
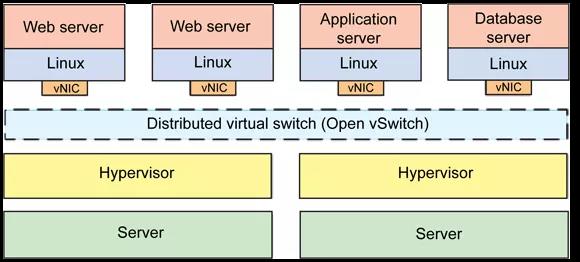
Linux Bridge 配合桥接或者 NAT 模式很容易可以实现同主机或跨主机的虚拟机/容器之间通信,而且 Bridge 本身也支持 VLAN 的配置,可以实现一些三层交换机的能力。但是很多厂商都在研发功能更丰富的虚拟交换机,流行的有 Cisco Nexus 1000V、 VMware Virtual Switch 以及广泛使用的开源的 Open vSwitch[12] 等。利用 vSwitch,可以构建出支持更多封装协议、更高级的虚拟网络:
1 Linux Bridge + Veth Pair 转发
VRF(Virtual Routing and Forwarding,虚拟路由转发)在网络领域中是个很常见的术语。上世纪九十年代开始,很多二层交换机上就能创建出 4K 的 VLAN 广播域了。4K 是因为 VLAN 标签的格式遵循 802.1q 标准,其中定义的 VLAN ID 是 12 位的缘故(802.1q in 802.1q 可以做到 4094*4094 个,0 和 4095 保留)。如今 VRF 概念被引入三层,单个物理设备上也可以有多个虚拟路由/转发实例了。Linux 的 VRF 实现了对三层的网络协议栈的虚拟,而 Network Namespace(以下简称 netns)虚拟了整个网络栈。一个 netns 的网络栈包括:网卡(Network Interface)、回环设备(Loopback Device)、路由表(Routing Table)和 iptables 规则。本文使用 netns 进行演示(毕竟在讨论容器),下文使用 ip[14] 命令创建和管理 netns 以及 Veth Pair 设备。
创建、查看、删除 Network Namespace
# 创建名为 qianyi-test-1 和 add qianyi-test-2 的命名 netns,可以在 /var/run/netns/ 下查看
ip netns add qianyi-test-1
ip netns add qianyi-test-2
# 查看所有的 Network Namespace
ip netns list
# 删除 Network Namespace
ip netns del qianyi-test-1
ip netns del qianyi-test-2执行结果如图(删除先不执行):

有兴趣的话可以使用 strace 命令跟踪这个创建过程看看 ip 命令是怎么创建的(strace ip netns add qianyi-test-1)。
在 netns 中执行命令
# 在 qianyi-test-1 这个 netns 中执行 ip addr 命令(甚至可以直接执行 bash 命令得到一个 shell)
# nsenter 这个命令也很好用,可以 man nsenter 了解
ip netns exec qianyi-test-1 ip addr执行结果如下:
图片
这个新创建的 netns 里一贫如洗,只有一个孤独的 lo 网卡,还是 DOWN 状态的。下面开启它:
开启 lo 网卡,这个很重要
ip netns exec qianyi-test-1 ip link set dev lo up
ip netns exec qianyi-test-2 ip link set dev lo up

状态变成了 UNKOWN,这是正常的。这个状态是驱动提供的,但是 lo 的驱动没有做这个事情。
创建 Veth Pair 设备
# 分别创建 2 对名为 veth-1-a/veth-1-b 和 veth-2-a/veth-2-b 的 Veth Pair 设备
ip link add veth-1-a type veth peer name veth-1-b
ip link add veth-2-a type veth peer name veth-2-b使用 ip addr 命令可以查看:
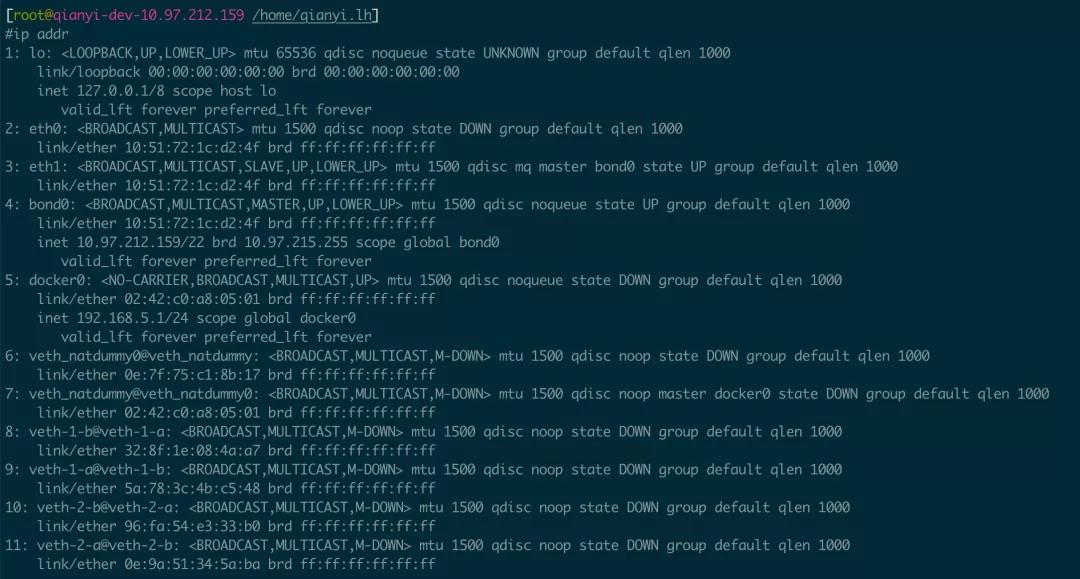
8-9,10-11 便是上面创建出来的 2 对 Veth Pair 设备,此时它们都没有分配 IP 地址且是 DOWN 状态。
将 Veth Pair 设备加入 netns
# 将 veth-1-a 设备加入 qianyi-test-1 这个 netns
ip link set veth-1-a netns qianyi-test-1
# 将 veth-1-b 设备加入 qianyi-test-2 这个 netns
ip link set veth-1-b netns qianyi-test-2
# 为设备添加 IP 地址/子网掩码并开启
ip netns exec qianyi-test-1 ip addr add 10.0.0.101/24 dev veth-1-a
ip netns exec qianyi-test-1 ip link set dev veth-1-a up
ip netns exec qianyi-test-2 ip addr add 10.0.0.102/24 dev veth-1-b
ip netns exec qianyi-test-2 ip link set dev veth-1-b up此时我们分别在两个 netns 中执行 ip addr 命令,即可看到设备已经存在,且路由表(route 或 ip route 命令)也被默认创建了:
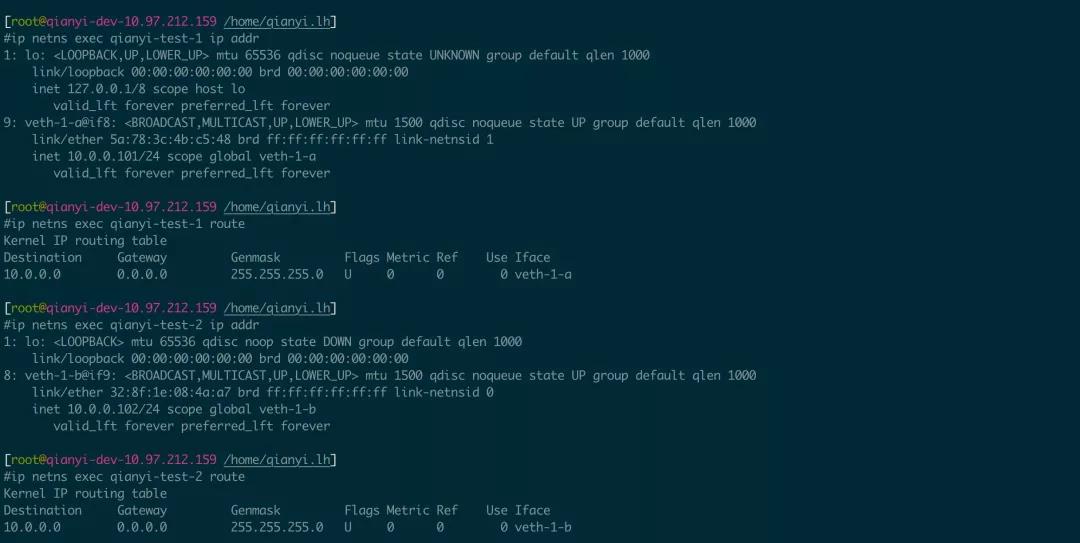
这里操作和查看设备都必须采用 ip netns exec ... 的方式进行,如果命令很多,也可以把执行的命令换成 bash,这样可以方便的在这个 shell 里对该 netns 进行操作。
现在通过 veth-1-a/veth-1-b 这对 Veth Pair 联通了 qianyi-test-1 和 qianyi-test-2 这两个 netns,这两个 netns 之间就可以通过这两个 IP 地址相互访问了。
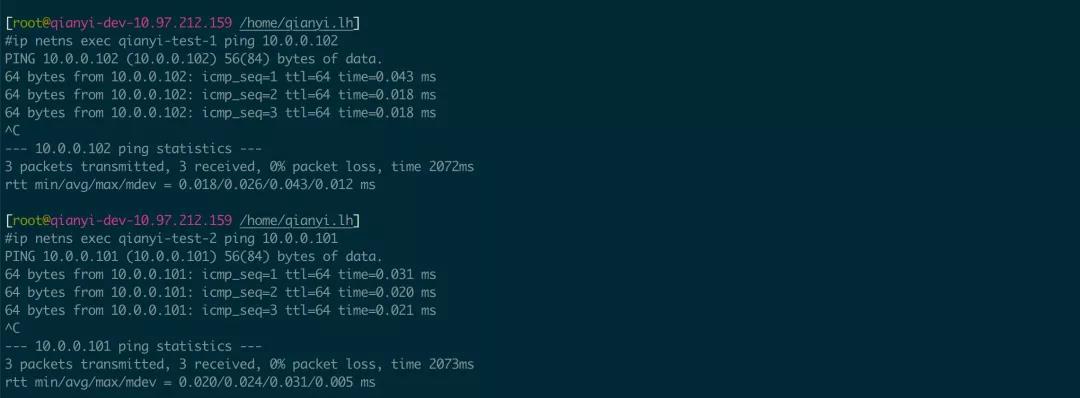
ping 的同时在 101 上抓包的结果如下:
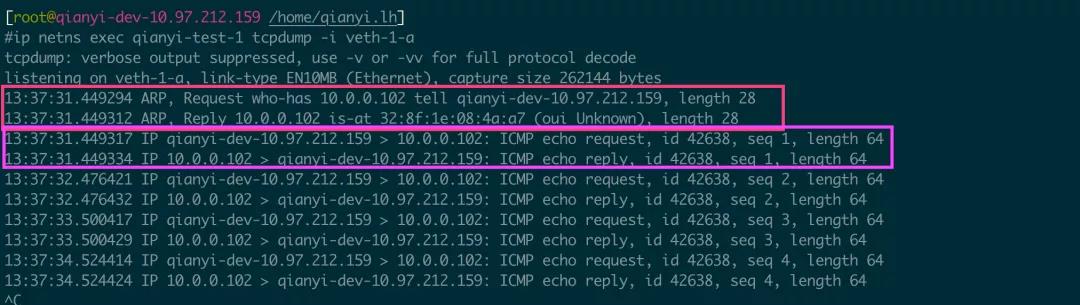
可以很清楚的看到,eth-1-a(10.0.0.101)先通过 ARP (Address Resolution Protocol,地址解析协议)询问 10.0.0.102 的 MAC 地址。得到回应后,就以 ICMP (Internet Control Message Protocol,Internet 报文控制协议) request 和 reply 了,这也正是 ping 使用的协议。
ARP 解析的缓存信息也可以通过 arp 命令查看:

此时的网络连接模式是这样的:
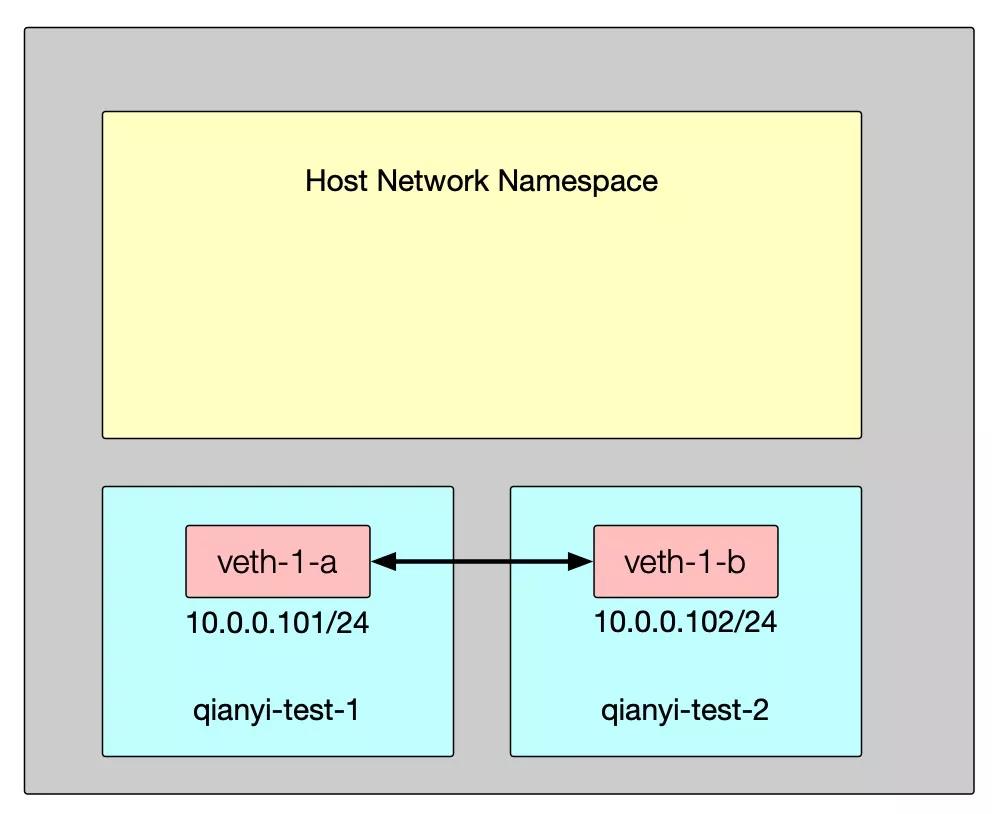
这种连接模式,就很像是现实中把两个带有 NIC 的设备用网线连接起来,然后配置了相同网段的 IP 后彼此就可以通信了。那如果超过一个设备需要建立互联呢?现实中就需要交换机等网络设备了。还记得前文中说的 Linux 自带的 Bridge 么?接下来就使用 Bridge 机制建立网络。
进行下面的试验前需要把 veth-1-a/veth-1-b 这对 Veth Pair 从 qianyi-test-1 和 qianyi-test-2 移动回宿主机的 netns 里,恢复初始的环境。
# 宿主机的 netns id 是 1(有些系统可能不是,请查询相关系统的文档)
ip netns exec qianyi-test-1 ip link set veth-1-a netns 1
ip netns exec qianyi-test-2 ip link set veth-1-b netns 1创建 Linux Bridge 并配置网络
# 创建一个名为 br0 的 bridge 并启动(也可以使用 brctl 命令)
ip link add br0 type bridge
ip link set br0 up
# 将 veth-1-a/veth-1-b 和 veth-2-a/veth-2-b 这两对 Veth Pair 的 a 端放入 qianyi-test-1 和 qianyi-test-2
ip link set veth-1-a netns qianyi-test-1
ip link set veth-2-a netns qianyi-test-2
# 为 veth-1-a 和 veth-2-a 配置 IP 并开启
ip netns exec qianyi-test-1 ip addr add 10.0.0.101/24 dev veth-1-a
ip netns exec qianyi-test-1 ip link set dev veth-1-a up
ip netns exec qianyi-test-2 ip addr add 10.0.0.102/24 dev veth-2-a
ip netns exec qianyi-test-2 ip link set dev veth-2-a up
# 将 veth-1-a/veth-1-b 和 veth-2-a/veth-2-b 这两对 Veth Pair 的 b 端接入 br0 网桥并开启接口
ip link set veth-1-b master br0
ip link set dev veth-1-b up
ip link set veth-2-b master br0
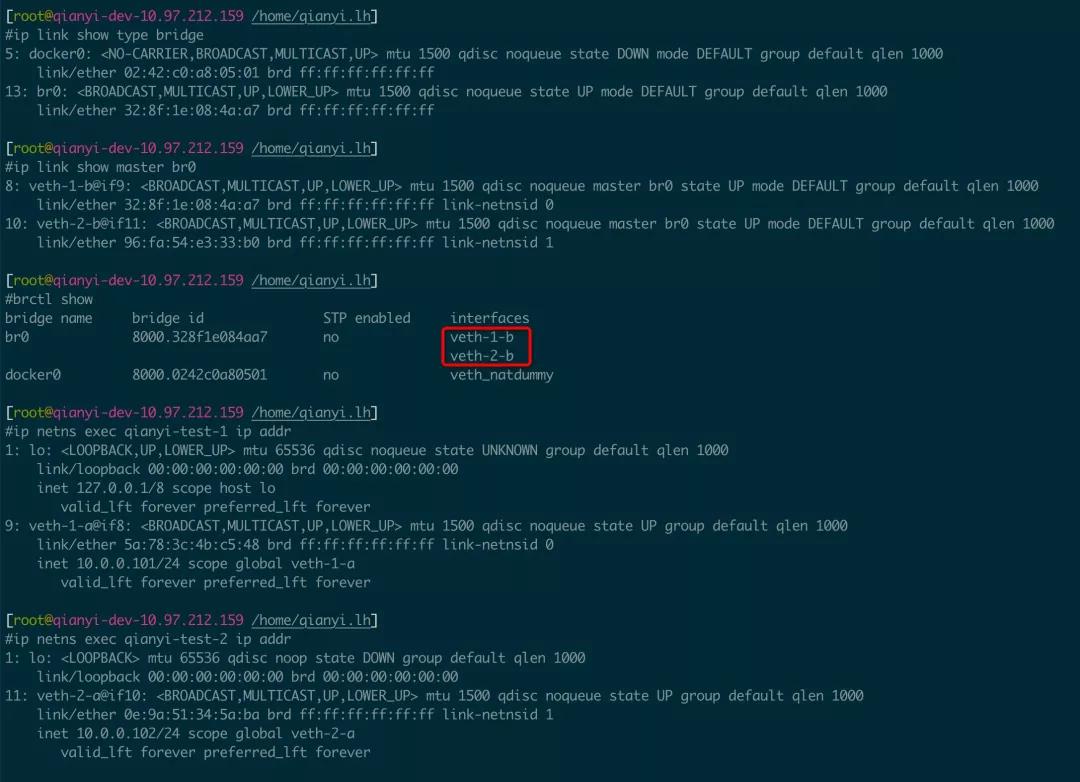
ip link set dev veth-2-b up执行完可以查看创建好的网桥和配置好的 IP,实际上 brctl show 命令显示的结果更易懂,可以很清楚的看到 veth-1-b 和 veth-2-b 连接在了网桥的接口上。当 Veth Pair 的一端连接在网桥上时,就会从“网卡”退化成一个“水晶头”。
当下模式抓包的结果并没有什么区别,但网络连接模式不同:
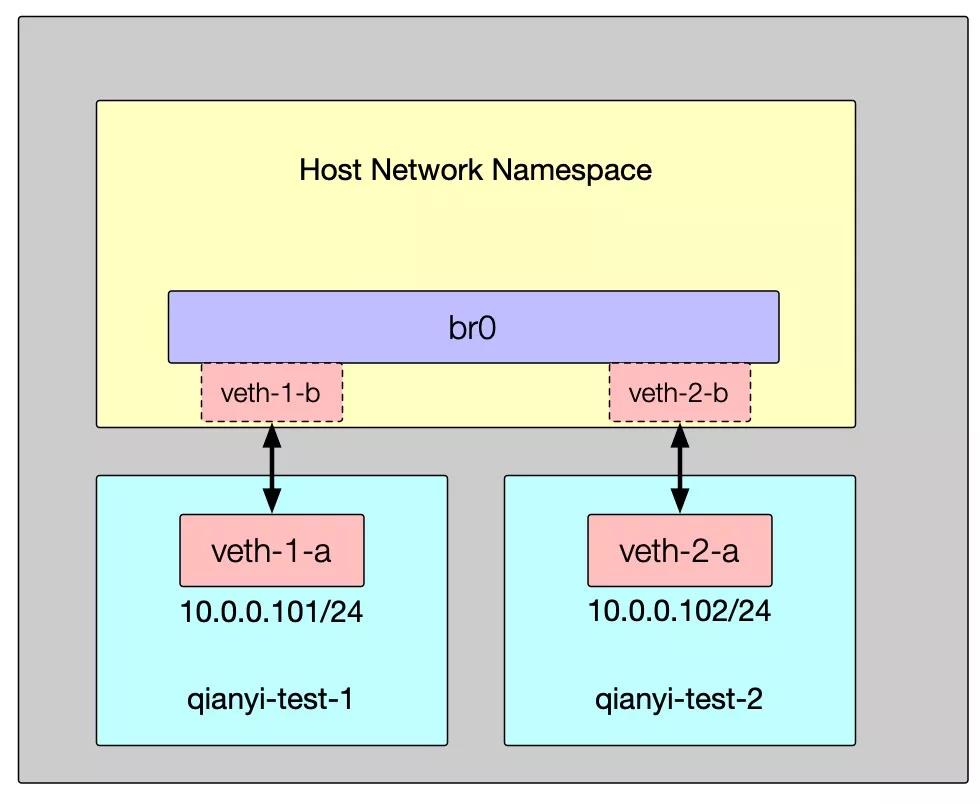
按照这个模式,如果有更多的 Network Namespace 和 Veth Pair 的话,使用相同的方式添加就可以水平扩展了。
但是尝试从 qianyi-test-1 中 ping 宿主机自然是不通的,因为没有任何网络规则可以访问到宿主机的网络:

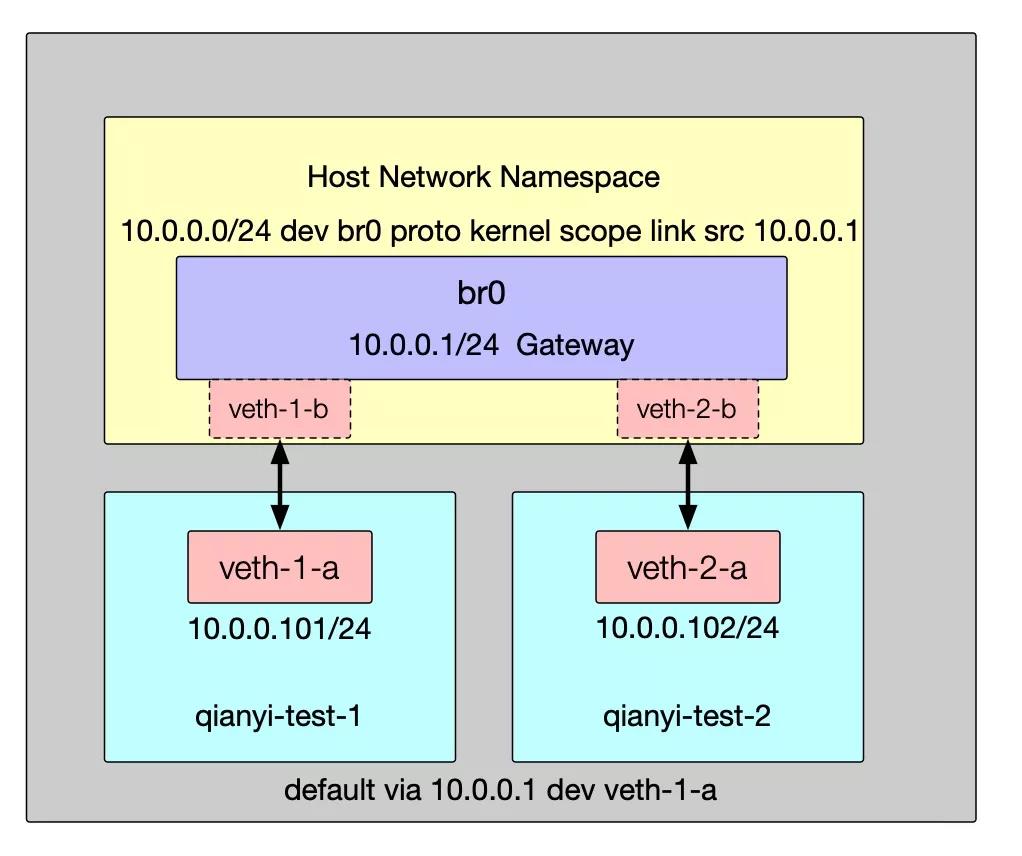
上面的截图中有个 docker0 的网桥。当机器上安装了 Docker 之后会被自动设置好这个网桥供 Docker 使用。可能你注意到了,这个名为 docker0 的网桥居然是有 IP 地址的。现实中的网桥自然是没有 IP 的,但是 Linux Bridge 这个虚拟设备是可以设置的。当 Bridge 设置 IP 之后,就可以将其设置成这个内部网络的网关(Gateway),再配合路由规则就可以实现最简单的虚拟网络跨机通信了(类似现实中的三层交换机)。
下面继续给 br0 网桥创建地址并在 veth-1-a 和 veth-2-a 上设置其为默认的网关地址:
# 确认路由转发开启
echo "1" > /proc/sys/net/ipv4/ip_forward
# 为 br0 设置 IP 地址
ip addr add local 10.0.0.1/24 dev br0
# 为 veth-1-a 和 veth-2-a 设置默认网关
ip netns exec qianyi-test-1 ip route add default via 10.0.0.1
ip netns exec qianyi-test-2 ip route add default via 10.0.0.1此时就能成功的访问宿主机地址了(宿主机上的路由表在 ip link set br0 up 这一步自动创建了):

网络模型进一步变成了这样:
如果此时,另一台宿主机上也存在另一个网段的网桥和若干个 netns 的话,怎么让他们互通呢?分别在两边宿主机上配置一条到目的宿主机的路由规则就好了。假设另一台宿主机的 IP 地址是 10.97.212.160,子网是 10.0.1.0/24 的话,那么需要在当前机器上加一条 10.0.1.0/24 via 10.97.212.160 的规则,10.97.212.160 上加一条 10.0.0.0/24 via 10.97.212.159 的规则就可以了(或者 iptables 配置 SNAT/DNAT 规则)。那如果有 N 台呢?那就会是个 N * N 条的规则,会很复杂。这就一个简单的 Underlay 模式的容器通信方案了。缺点也很明显,要求对宿主机底层网络有修改权,且比较难和底层网络解耦。那如果能在物理网络上构建出一个横跨所有宿主机的虚拟网桥,把所有相关的 netns 里面的设备都连接上去,不就可以解耦了么。这就是 Overlay Network(覆盖网络)方案,下文会进行阐述。至于本节其他虚拟网络设备的安装和配置(比如 Open vSwitch)也是比较类似的,这里不再赘述,有兴趣的话可以自行查看文档并测试。
2 Overlay 网络方案之 VXLAN
VXLAN(Virtual eXtensible Local Area Network,虚拟可扩展局域网,RFC7348)[16],VLAN 的扩展协议,是由 IETF 定义的 NVO3(Network Virtualization over Layer 3)标准技术之一(其他有代表性的还有 NVGRE、STT)。但是 VXLAN 和 VLAN 想要解决的问题是不一样的。VXLAN 本质上是一种隧道封装技术,它将数据链路层(L2)的以太网帧(Ethernet frames)封装成传输层(L4)的 UDP 数据报(Datagrams),然后在网络层(L3)中传输。效果就像数据链路层(L2)的以太网帧在一个广播域中传输一样,即跨越了三层网络却感知不到三层的存在。因为是基于 UDP 封装,只要是 IP 网络路由可达就可以构建出庞大的虚拟二层网络。也因为是基于高层协议再次封装,性能会比传统的网络低 20%~30% 左右(性能数据随着技术发展会有变化,仅代表当前水平)。
这里简要介绍下 VXLAN 的 2 个重要概念:
- VTEP(VXLAN Tunnel Endpoints,VXLAN 隧道端点),负责 VXLAN 报文的封装和解封,对上层隐藏了链路层帧的转发细节
- VNI(VXLAN Network Identifier,VXLAN 网络标识符),代表不同的租户,属于不同 VNI 的虚拟网络之间不能直接进行二层通信。
VXLAN 的报文格式如图[17]:
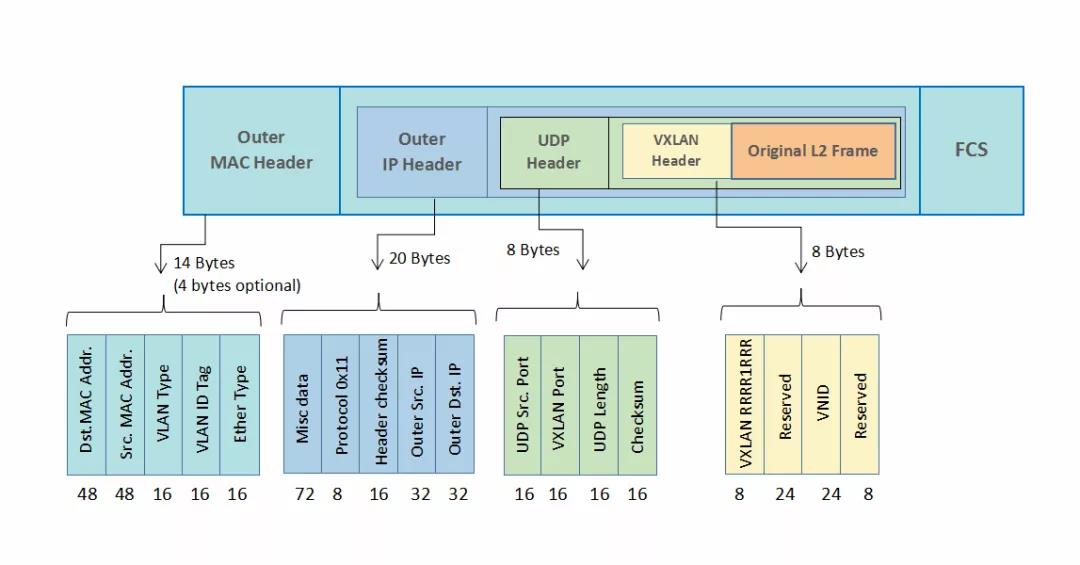
Linux kernel v3.7.0 版本开始支持 VXLAN 网络。但为了稳定性和其他功能,请尽量选择 kernel v3.10.0 及之后的版本。下面我们使用 10.97.212.159 和 11.238.151.74 这两台机器创建一个测试的 VXLAN 网络。
# 10.97.212.159 上操作
# 创建名为 qianyi-test-1 和 add qianyi-test-2 的命名 netns,可以在 /var/run/netns/ 下查看
ip netns add qianyi-test-1
ip netns add qianyi-test-2
# 开启 lo 网卡,这个很重要
ip netns exec qianyi-test-1 ip link set dev lo up
ip netns exec qianyi-test-2 ip link set dev lo up
# 创建一个名为 br0 的 bridge 并启动(也可以使用 brctl 命令)
ip link add br0 type bridge
ip link set br0 up
# 分别创建 2 对名为 veth-1-a/veth-1-b 和 veth-2-a/veth-2-b 的 Veth Pair 设备
ip link add veth-1-a type veth peer name veth-1-b
ip link add veth-2-a type veth peer name veth-2-b
# 将 veth-1-a/veth-1-b 和 veth-2-a/veth-2-b 这两对 Veth Pair 的 a 端放入 qianyi-test-1 和 qianyi-test-2
ip link set veth-1-a netns qianyi-test-1
ip link set veth-2-a netns qianyi-test-2
# 为 veth-1-a 和 veth-2-a 配置 IP 并开启
ip netns exec qianyi-test-1 ip addr add 10.0.0.101/24 dev veth-1-a
ip netns exec qianyi-test-1 ip link set dev veth-1-a up
ip netns exec qianyi-test-2 ip addr add 10.0.0.102/24 dev veth-2-a
ip netns exec qianyi-test-2 ip link set dev veth-2-a up
# 将 veth-1-a/veth-1-b 和 veth-2-a/veth-2-b 这两对 Veth Pair 的 b 端接入 br0 网桥并开启接口
ip link set veth-1-b master br0
ip link set dev veth-1-b up
ip link set veth-2-b master br0
ip link set dev veth-2-b up
# 11.238.151.74 上操作
# 创建名为 qianyi-test-3 和 add qianyi-test-4 的命名 netns,可以在 /var/run/netns/ 下查看
ip netns add qianyi-test-3
ip netns add qianyi-test-4
# 开启 lo 网卡,这个很重要
ip netns exec qianyi-test-3 ip link set dev lo up
ip netns exec qianyi-test-4 ip link set dev lo up
# 创建一个名为 br0 的 bridge 并启动(也可以使用 brctl 命令)
ip link add br0 type bridge
ip link set br0 up
# 分别创建 2 对名为 veth-3-a/veth-3-b 和 veth-4-a/veth-4-b 的 Veth Pair 设备
ip link add veth-3-a type veth peer name veth-3-b
ip link add veth-4-a type veth peer name veth-4-b
# 将 veth-3-a/veth-3-b 和 veth-4-a/veth-4-b 这两对 Veth Pair 的 a 端放入 qianyi-test-3 和 qianyi-test-4
ip link set veth-3-a netns qianyi-test-3
ip link set veth-4-a netns qianyi-test-4
# 为 veth-3-a 和 veth-4-a 配置 IP 并开启
ip netns exec qianyi-test-3 ip addr add 10.0.0.103/24 dev veth-3-a
ip netns exec qianyi-test-3 ip link set dev veth-3-a up
ip netns exec qianyi-test-4 ip addr add 10.0.0.104/24 dev veth-4-a
ip netns exec qianyi-test-4 ip link set dev veth-4-a up
# 将 veth-3-a/veth-3-b 和 veth-4-a/veth-4-b 这两对 Veth Pair 的 b 端接入 br0 网桥并开启接口
ip link set veth-3-b master br0
ip link set dev veth-3-b up
ip link set veth-4-b master br0
ip link set dev veth-4-b up这一长串的命令和之前的步骤完全一致,构建了一个如下图所示的网络环境:
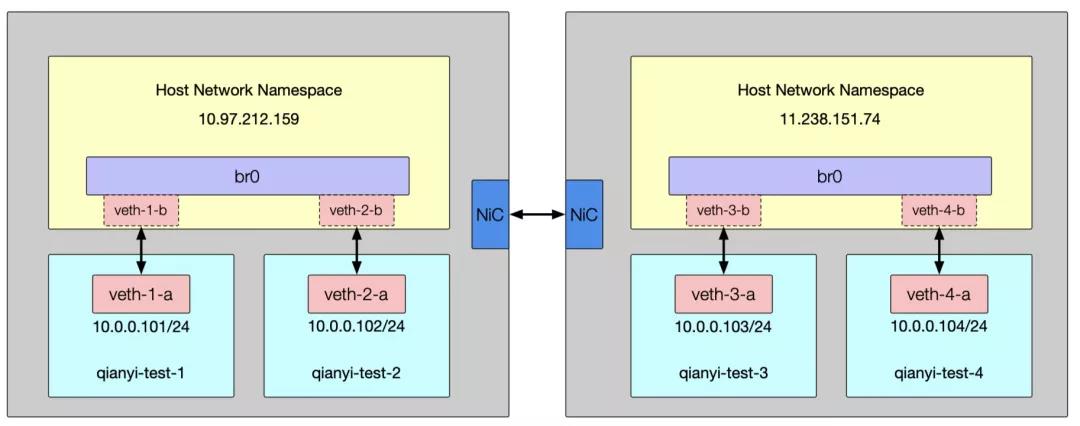
这个环境里,10.0.0.101 和 10.0.0.102 是通的,10.0.0.103 和 10.0.0.104 也是通的,但是显然 10.0.0.101/10.0.0.102 和 10.0.0.103/10.0.0.104 是无法通信的。
接下来配置 VXLAN 环境打通这四个 netns 环境:
# 10.97.212.159 上操作(本机有多个地址时可以用 local 10.97.212.159 指定)
ip link add vxlan1 type vxlan id 1 remote 11.238.151.74 dstport 9527 dev bond0
ip link set vxlan1 master br0
ip link set vxlan1 up
# 11.238.151.74 上操作(本机有多个地址时可以用 local 11.238.151.74 指定)
ip link add vxlan2 type vxlan id 1 remote 10.97.212.159 dstport 9527 dev bond0
ip link set vxlan2 master br0
ip link set vxlan2 up使用 brctl show br0 命令可以看到两个 VXLAN 设备都连接上去了:
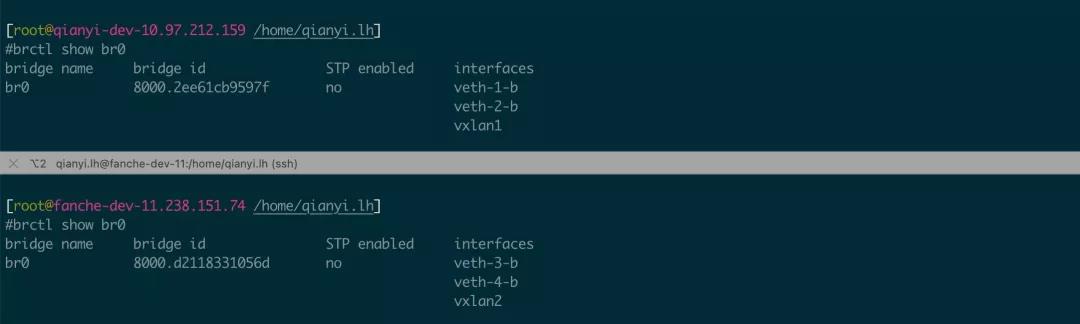
然后从 10.0.0.101 上就可以 ping 通 10.0.0.103 了:

在 10.0.0.101 上抓的包来看,就像是二层互通一样:

直接查看 arp 缓存,也是和二层互通一模一样:

使用 arp -d 10.0.0.103 删掉这个缓存项目,在宿主机上重新抓包并保存文件,然后用 WireShark 打开看看(因为上面设置的不是 VXLAN 默认端口 4789,还需要设置 WireShark 把抓到的 UDP 解析为 VXLAN 协议):
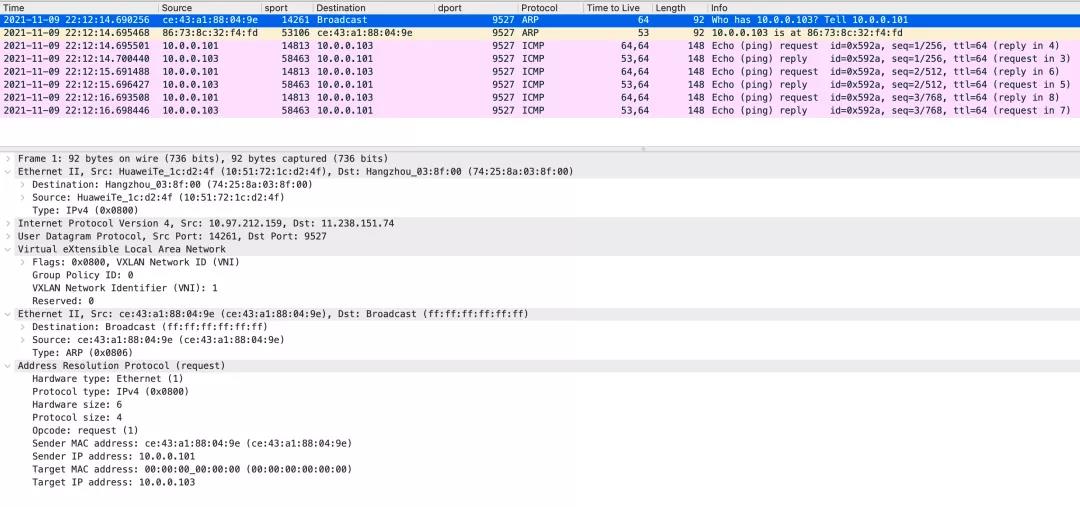
我们得到了预期的结果。此时的网络架构如图所示:
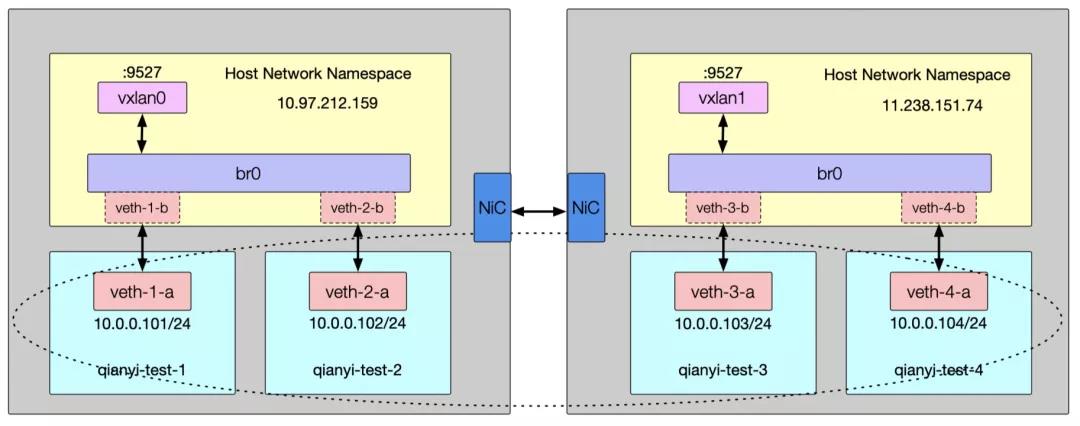
那么问题来了,这里使用 UDP 协议能实现可靠通信吗?当然可以,可靠性不是这一层考虑的事情,而是里层被包裹的协议需要考虑的。完整的通信原理其实也并不复杂,两台机器上各自有 VTEP(VXLAN Tunnel Endpoints,VXLAN 隧道端点)设备,监听着 9527 端口上发送的 UDP 数据包。在收到数据包后拆解通过 Bridge 传递给指定的设备。那 VETP 这个虚拟设备怎么知道类似 10.0.0.3 这样的地址要发送给哪台机器上的 VETP 设备呢?这可是虚拟的二层网络,底层网络上可不认识这个地址。事实上在 Linux Bridge 上维护着一个名为 FDB(Forwarding Database entry)的二层转发表,用于保存远端虚拟机/容器的 MAC 地址、远端 VTEP 的 IP,以及 VNI 的映射关系,可以通过 bridge fdb 命令来对 FDB 表进行操作:
# 新增条目
bridge fdb add <remote_host_mac_addr> dev <vxlan_interface> dst <remote_host_ip_addr>
# 删除条目
bridge fdb del <remote_host_mac_addr> dev <vxlan_interface>
# 替换条目
bridge fdb replace <remote_host_mac_addr> dev <vxlan_interface> dst <remote_host_ip_addr>
# 显示条目
bridge fdb show上面这个简单的实验就 2 台机器,使用了命令的方式直接指定了彼此的 VTEP 地址,当 fdb 表查不到信息时发给对方就行了,这是最简单的互联模式。大规模 VXLAN 网络下,就需要考虑如何发现网络中其他的 VETP 地址了。解决这个问题一般有 2 种方式:一是使用组播/多播( IGMP, Internet Group Management Protocol),把节点组成一个虚拟的整体,包不清楚发给谁的话就广播给整个组了(上述实验中的创建 VETH 设备的命令修改为组播/多播地址比如 224.1.1.1 就行,remote 关键字也要改成 group,具体请参阅其他资料);二是通过外部的分布式控制中心来收集 FDB 信息并分发给同一个 VXLAN 网络的所有节点。组播/多播受限于底层网络的支持情况和大规模下的的性能问题,比如很多云网络上不一定允许这么做。所以下文在讨论和研究 K8s 的网络方案时会看到很多网络插件的实现采用的都是类似后者的实现方式。
这节就介绍到这里了。当然 Overlay 网络方案也不止 VXLAN 这一种方式,只是目前很多主流的方案都采用了这种方式。其他的 Overlay 模式看上去眼花缭乱,其实说白了,无非就是 L2 over L4,L2 over L3,L3 over L3 等等各种包装方式罢了,懂了基本原理之后都没什么大不了的。网络虚拟化的设备和机制也有很多[18],细说的话一天都说不完,但是基本的网络原理掌握之后,无非是各种协议包的流转罢了。
三 K8s 的网络虚拟化实现
1 K8s 的网络模型
每一个 Pod 都有它自己的 IP 地址,这就意味着你不需要显式地在每个 Pod 之间创建链接, 你几乎不需要处理容器端口到主机端口之间的映射。这将创建一个干净的、向后兼容的模型,在这个模型里,从端口分配、命名、服务发现、 负载均衡、应用配置和迁移的角度来看,Pod 可以被视作虚拟机或者物理主机。
Kubernetes 对所有网络设施的实施,都需要满足以下的基本要求(除非有设置一些特定的网络分段策略):
- 节点上的 Pod 可以不通过 NAT 和其他任何节点上的 Pod 通信
- 节点上的代理(比如:系统守护进程、kubelet)可以和节点上的所有 Pod 通信
备注:仅针对那些支持 Pods 在主机网络中运行的平台(比如:Linux):
- 那些运行在节点的主机网络里的 Pod 可以不通过 NAT 和所有节点上的 Pod 通信
这个模型不仅不复杂,而且还和 Kubernetes 的实现廉价的从虚拟机向容器迁移的初衷相兼容, 如果你的工作开始是在虚拟机中运行的,你的虚拟机有一个 IP,这样就可以和其他的虚拟机进行通信,这是基本相同的模型。
Kubernetes 的 IP 地址存在于 Pod 范围内 - 容器共享它们的网络命名空间 - 包括它们的 IP 地址和 MAC 地址。这就意味着 Pod 内的容器都可以通过 localhost 到达各个端口。这也意味着 Pod 内的容器都需要相互协调端口的使用,但是这和虚拟机中的进程似乎没有什么不同, 这也被称为“一个 Pod 一个 IP”模型。
这几段话引用自 K8s 的官方文档[19],简单概括下就是一个 Pod 一个独立的 IP 地址,所有的 Pod 之间可以不通过 NAT 通信。这个模型把一个 Pod 的网络环境近似等同于一个 VM 的网络环境。
2 K8s 的主流网络插件实现原理
K8s 中的网络是通过插件方式实现的,其网络插件有 2 种类型:
- CNI 插件:遵守 CNI(Container Network Interface,容器网络接口)规范,其设计上偏重互操作性
- Kubenet 插件:使用 bridge 和 host-local CNI 插件实现了基本的 cbr0
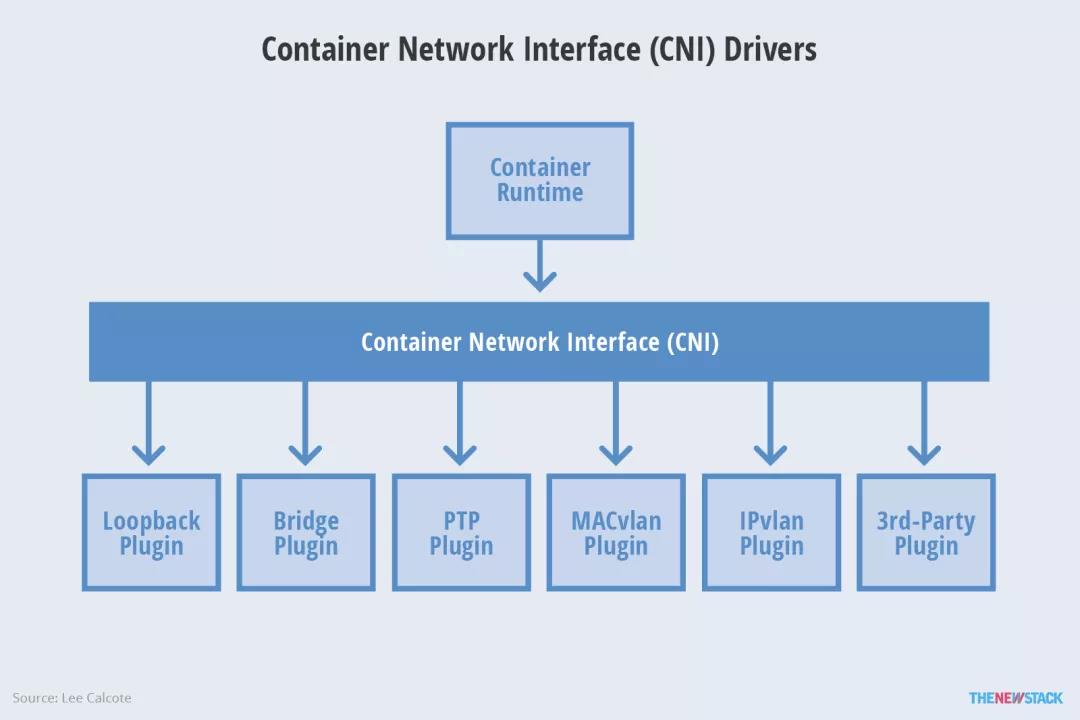
图片来自[20],本文只关注 CNI 接口插件。主流的 K8s 网络插件有这些[21],本文选出 github star 数在千以上的几个项目分析下:
- Flannel:https://github.com/flannel-io/flannel
- Calico:https://github.com/projectcalico/calico
- Cilium:GitHub - cilium/cilium: eBPF-based Networking, Security, and Observability
Flannel
CNI 是由 CoreOS 提出的规范,那就先看下 CoreOS 自己的 Flannel 项目的设计。Flannel 会在每台机宿主机上部署一个名为 flanneld 的代理进程,网段相关的数据使用 Kubernetes API/Etcd 存储。Flannel 项目本身是一个框架,真正为我们提供容器网络功能的,是 Flannel 的后端实现。
目前的 Flannel 有下面几种后端实现:VXLAN、host-gw、UDP 以及阿里云和其他大厂的支持后端(云厂商都是实验性支持),还有诸如 IPIP、IPSec 等一些隧道通信的实验性支持。按照官方文档的建议是优先使用 VXLAN 模式,host-gw 推荐给经验丰富且想要进一步提升性能的用户(云环境通常不能用,原因后面说),UDP 是 Flannel 最早支持的一种性能比较差的方案,基本上已经弃用了。
下文分别对这三种模式进行分析。
1)VXLAN
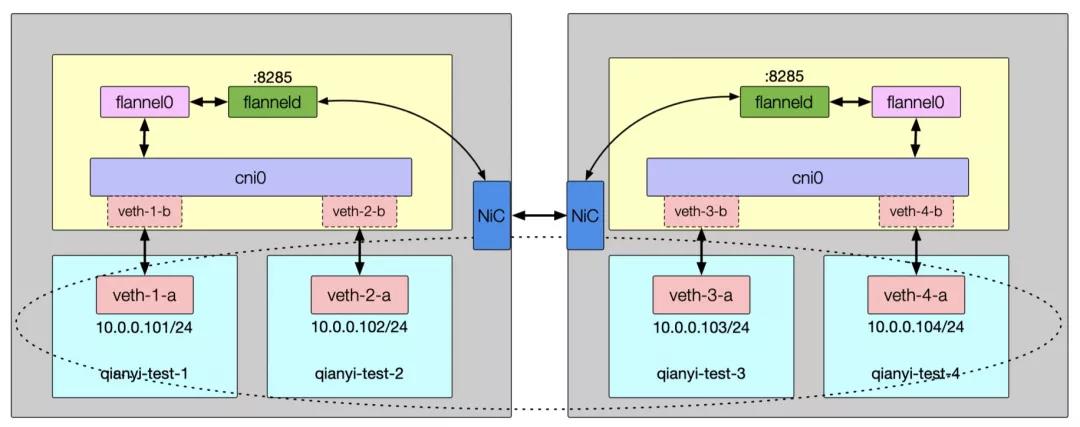
使用 Linux 内核 VXLAN 封装数据包的方式和原理上文已经介绍过了,Flannel 创建了一个名为 flannel.1 的 VETH 设备。因为 flanneld 进程的存在,所以注册和更新新的 VETH 设备关系的任务就依靠这个进程了。所以好像也没什么需要说的了,就是每个新的 K8s Node 都会创建 flanneld 这个 DeamonSet 模式的守护进程。然后注册、更新新的 VETH 设备就变得非常自然了,全局的数据自然也是保存在 Etcd 里了。这种方式图已经画过了,无非是设备名字不一样(VETH 叫 flannel.1,网桥叫 cni0)而已。
2)host-gw
顾名思义,host-gw 就是把宿主机 Host 当做 Gateway 网关来处理协议包的流动。这个方式上文其实也演示过了,至于节点的变化和路由表的增删也是依靠 flanneld 在做的。这个方案优缺点都很明显,最大的优点自然是性能,实打实的直接转发(性能整体比宿主机层面的通信低 10%,VXLAN 可是20% 起步,甚至 30%)。缺点也很明显,这种方式要求宿主机之间是二层连通的,还需要对基础设施有掌控权(编辑路由表),这个在云服务环境一般较难实现,另外规模越来越大时候的路由表规模也会随之增大。这种方式原理上比较简单,图不画了。
3)UDP
每台宿主机上的 flanneld 进程会创建一个默认名为 flannel0 的 Tun 设备。Tun 设备的功能非常简单,用于在内核和用户应用程序之间传递 IP 包。内核将一个 IP 包发送给 Tun 设备之后,这个包就会交给创建这个设备的应用程序。而进程向 Tun 设备发送了一个 IP 包,那么这个 IP 包就会出现在宿主机的网络栈中,然后根据路由表进行下一跳的处理。在由 Flannel 管理的容器网络里,一台宿主机上的所有容器都属于该宿主机被分配的一个“子网”。这个子网的范围信息,所属的宿主机 IP 地址都保存在 Etcd 里。flanneld 进程均监听着宿主机上的 UDP 8285 端口,相互之间通过 UDP 协议包装 IP 包给目的主机完成通信。之前说过这个模式性能差,差在哪里?这个方案就是一个在应用层模拟实现的 Overlay 网络似得(像不像一个用户态实现的 VETH 设备?),数据包相比内核原生支持的 VXLAN 协议在用户态多了一次进出(flanneld 进程封包/拆包过程),所以性能上损失要大一些。
Calico
Calico 是个挺有意思的项目,基本思想是把宿主机完全当成路由器,不使用隧道或 NAT 来实现转发,把所有二三层流量转换成三层流量,并通过宿主机上的路由配置完成包的转发。
Calico 和之前说的 Flannel 的 host-gw 模式区别是什么?首先 Calico 不使用网桥,而是通过路由规则在不同的 vNiC 间转发数据。另外路由表也不是靠 Etcd 存储和通知更新,而是像现实环境一样直接用 BGP(Border Gateway Protocol, 边界网关协议)进行路由表数据交换。BGP 挺复杂的,详细的阐述这个协议有点费劲(而且我也不是很懂),在本文里只需要知道这个协议使得路由设备可以相互发送和学习对方的路由信息来充实自己就可以了,有兴趣的话请查阅其他资料进一步了解。回到 Calico,宿主机上依旧有个名为 Felix 的守护进程和一个名为 BIRD的 BGP 客户端。
上文说过,Flannel 的 host-gw 模式要求宿主机二层是互通的(在一个子网),在 Calico 这里依然有这个要求。但是 Calico 为不在一个子网的环境提供了 IPIP 模式的支持。开启这个模式之后,宿主机上会创建一个 Tun 设备以 IP 隧道(IP tunnel)的方式通信。当然用了这个模式之后,包又是L3 over L3 的 Overlay 网络模式了,性能也和 VXLAN 模式相当。
全路由表的通信方式也没有额外组件,配置好 IP 路由转发规则后全靠内核路由模块的流转来做。IPIP 的架构图也是大同小异的,也不画了。
Cilium
eBPF-based Networking, Security, and Observability
光从这个介绍上就看出来 Cilium 散发出的那种与众不同的气息。这个项目目前的 Github Star 数字快过万了,直接力压前面两位。Cilium 部署后会在宿主机上创建一个名为 cilium-agent 的守护进程,这个进程的作用就是维护和部署 eBPF 脚本来实现所有的流量转发、过滤、诊断的事情(都不依赖 Netfilter 机制,kenel > v4.19 版本)。从原理图的角度画出来的架构图很简单(配图来自 github 主页):
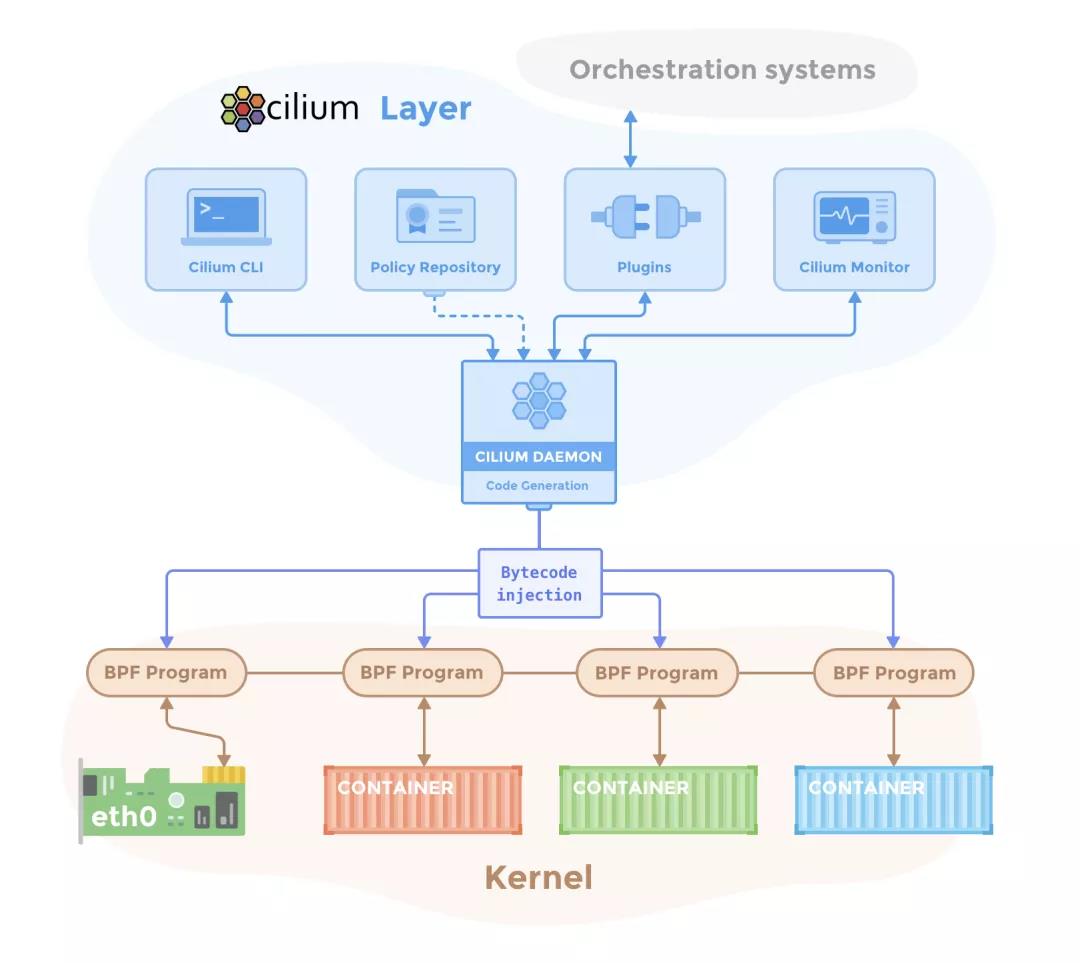
Cilium 除了支持基本的网络连通、隔离与服务透出之外,依托 eBPF 所以对宿主机网络有更好的观测性和故障排查能力。这个话题也很大,本文就此收住。这里给两几篇写的很好的文章何其译文可以进一步了解22。
3 K8s 容器内访问隔离
上文介绍了网络插件的机制和实现原理,最终可以构建出一个二层/三层连通的虚拟网络。默认情况下 Pod 间的任何网络访问都是不受限的,但是内部网络中经常还是需要设置一些访问规则(防火墙)的。
针对这个需求,K8s 抽象了一个名为 NetworkPolicy 的机制来支持这个功能。网络策略通过网络插件来实现,要使用网络策略就必须使用支持 NetworkPolicy 的网络解决方案。为什么这么说?因为不是所有的网络插件都支持 NetworkPolicy 机制,比如 Flannel 就不支持。至于 NetworkPolicy 的底层原理,自然是使用 iptables 配置 netfilter 规则来实现对包的过滤的。NetworkPolicy 配置的方法和 iptables/Netfilter 的原理细节不在本文范围内,请参阅其他资料进行了解24。
4 K8s 容器内服务透出
在一个 K8s 集群内部,在网络插件的帮助下,所有的容器/进程可以相互进行通信。但是作为服务提供方这是不够的,因为很多时候,服务的使用方不会在同一个 K8s 集群内的。那么就需要一种机制将这个集群内的服务对外透出。K8s 使用 Service 这个对象来完成这个能力的抽象。Service 在 K8s 里是个很重要的对象,即使在 K8s 内部进行访问,往往也是需要 Service 包装的(一来 Pod 地址不是永远固定的,二来总是会有负载均衡的需求)。
一句话概括 Service 的原理就是:Service = kube-proxy + iptables 规则。当一个 Service 创建时,K8s 会为其分配一个 Cluster IP 地址。这个地址其实是个 VIP,并没有一个真实的网络对象存在。这个 IP 只会存在于 iptables 规则里,对这个 VIP:VPort 的访问使用 iptables 的随机模式规则指向了一个或者多个真实存在的 Pod 地址(DNAT),这个是 Service 最基本的工作原理。那 kube-proxy 做什么?kube-proxy 监听 Pod 的变化,负责在宿主机上生成这些 NAT 规则。这个模式下 kube-proxy 不转发流量,kube-proxy 只是负责疏通管道。
K8s 官方文档比较好的介绍了 kube-proxy 支持的多种模式和基本的原理[26]。早先的 userspace 模式基本上弃用了,上面所述的 iptables 随机规则的做法在大规模下也不推荐使用了(想想为什么)。现在最推荐的当属 IPVS 模式了,相对于前两种在大规模下的性能更好。如果说 IPVS 这个词比较陌生的话,LVS 这个词恐怕是我们耳熟能详的。在这个模式下,kube-proxy 会在宿主机上创建一个名为 kube-ipvs0 的虚拟网卡,然后分配 Service VIP 作为其 IP 地址。最后 kube-proxy 使用内核的 IPVS 模块为这个地址设置后端 POD 的地址(ipvsadm 命令可以查看)。其实 IPVS 在内核中的实现也是用了 Netfilter 的 NAT 机制。不同的是,IPVS 不会为每一个地址设置 NAT 规则,而是把这些规则的处理放到了内核态,保证了 iptables 规则的数量基本上恒定,比较好的解决了之前的问题。
上面说的只是解决了负载均衡的问题,还没提到服务透出。K8s 服务透出的方式主要有 NodePort、LoadBalancer 类型的 Service(会调用 CloudProvider 在公有云上为你创建一个负载均衡服务)以及 ExternalName(kube-dns 里添加 CNAME)的方式。对于第二种类型,当 Service 繁多但是又流量很小的情况下,也可以使用 Ingress 这个 Service 的 Service 来收敛掉[27]。Ingress 目前只支持七层 HTTP(S) 转发(Service 目前只支持四层转发),从这个角度猜猜 Ingress 怎么实现的?来张图看看吧[28](当然还有很多其他的 Controller[29]):
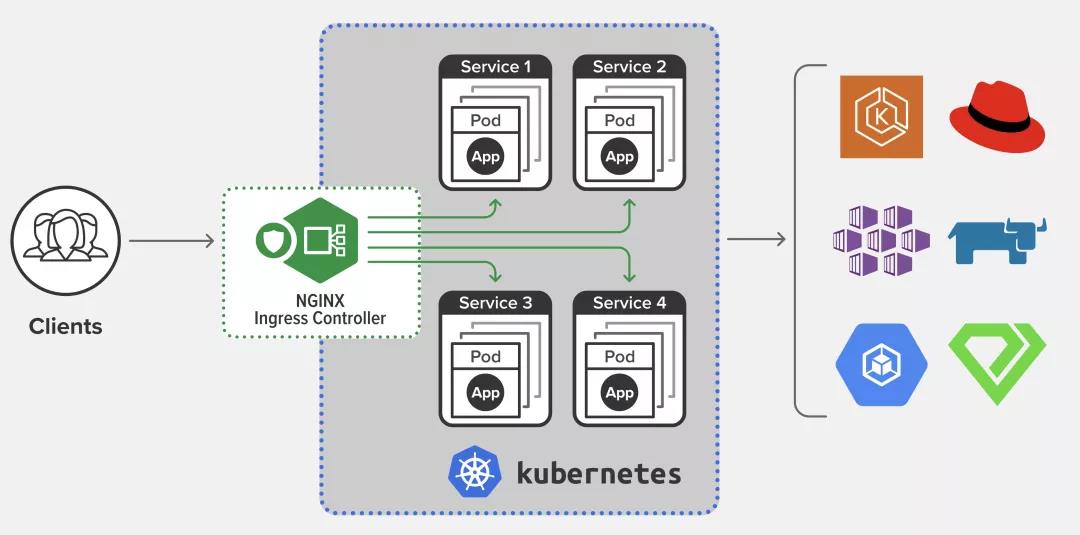
对于这部分,本文不再进行详细阐述了,无非就是 NAT,NAT 多了就想办法收敛 NAT 条目。按照惯例,这里给出一篇特别好的 kube-proxy 原理阐述的文章供进一步了解[30]。
四 总结
网络虚拟化是个很大的话题,很难在一篇文章中完全讲清楚。尽管这篇文章尽量想把重要的知识节点编织清楚,但受限于作者本人的精力以及认知上的限制,可能存在疏忽甚至错漏。如有此类问题,欢迎在评论区讨论/指正。参考文献里给出了很多不错的资料值得进一步去学习(部分地址受限于网络环境,可能需要特定的方式才能访问)。
参考文献
1、TCP Implementation in Linux: A Brief Tutorial, Helali Bhuiyan, Mark McGinley, Tao Li, Malathi Veeraraghavan, University of Virginia:[PDF] TCP Implementation in Linux : A Brief Tutorial | Semantic Scholar
2、NAPI, linuxfoundation, networking:napi [Wiki]
3、Monitoring and Tuning the Linux Networking Stack: Receiving Data, Joe Damato,译文:Linux 网络栈监控和调优:接收数据(2016):[译] Linux 网络栈监控和调优:接收数据(2016)
4、Monitoring and Tuning the Linux Networking Stack: Sending Data, Joe Damato, 译文:Linux 网络栈监控和调优:发送数据(2017):[译] Linux 网络栈监控和调优:发送数据(2017)
5、Scaling in the Linux Networking Stack, https://github.com/torvalds/linux/blob/master/Documentation/networking/scaling.rst
6、Understanding TCP internals step by step for Software Engineers and System Designers, Kousik Nath
7、Netfilter, https://www.netfilter.org/
8、Netfilter-packet-flow, https://upload.wikimedia.org/wikipedia/commons/3/37/Netfilter-packet-flow.svg
9、Analysis TCP in Linux, https://github.com/fzyz999/Analysis_TCP_in_Linux
10、NAT - Network Address Translation, 译文:NAT - 网络地址转换(2016):[译] NAT - 网络地址转换(2016)
11、Virtual networking in Linux, By M. Jones, IBM Developer:Virtual networking in Linux – IBM Developer
12、Open vSwitch, Open vSwitch
13、Linux Namespace, namespaces(7) - Linux manual page
14、ip, ip(8) - Linux manual page
15、Veth, veth(4) - Linux manual page
16、VxLAN, https://en.wikipedia.org/wiki/Virtual_Extensible_LAN
17、QinQ vs VLAN vs VXLAN, John, https://community.fs.com/blog/qinq-vs-vlan-vs-vxlan.htm
18、Introduction to Linux interfaces for virtual networking, Hangbin Liu:Introduction to Linux interfaces for virtual networking | Red Hat Developer
19、Cluster Networking, 英文地址集群网络系统 | Kubernetes
20、THE CONTAINER NETWORKING LANDSCAPE: CNI FROM COREOS AND CNM FROM DOCKER, Lee Calcote:The Container Networking Landscape: CNI from CoreOS and CNM from Docker – The New Stack
21、CNI - the Container Network Interface, https://github.com/containernetworking/cni
22、Making the Kubernetes Service Abstraction Scale using eBPF, [译] 利用 eBPF 支撑大规模 K8s Service (LPC, 2019):Linux Plumbers Conference 2019 (9-11 September 2019): Making the Kubernetes Service Abstraction Scale using eBPF · Indico
23、基于 BPF/XDP 实现 K8s Service 负载均衡 (LPC, 2020)Linux Plumbers Conference 2020 (24-28 August 2020): Kubernetes service load-balancing at scale with BPF & XDP · Indico
{kind=link}
24、A Deep Dive into Iptables and Netfilter Architecture, Justin Ellingwood:A Deep Dive into Iptables and Netfilter Architecture | DigitalOcean
25、Iptables Tutorial 1.2.2, Oskar Andreasson:Iptables Tutorial 1.2.2
26、Virtual IPs and service proxies, 英文地址:Service | Kubernetes
27、Ingress, 英文地址:Ingress | Kubernetes
28、nginx Ingress Controller, F5 NGINX Ingress Controller - Production-Grade Kubernetes
29、Ingress Controllers, 英文地址:Ingress Controllers | Kubernetes
30、Cracking kubernetes node proxy (aka kube-proxy), [译] 深入理解 Kubernetes 网络模型:自己实现 Kube-Proxy 的功能:深入理解 Kubernetes 网络模型:自己实现 kube-proxy 的功能 | 云原生社区
原文链接
本文为阿里云原创内容,未经允许不得转载。
以上是关于一文理解 K8s 容器网络虚拟化的主要内容,如果未能解决你的问题,请参考以下文章