一文深入理解 Kubernetes
Posted 腾讯技术工程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文深入理解 Kubernetes相关的知识,希望对你有一定的参考价值。

作者:xixie,腾讯 IEG 后台开发工程师
这篇文章,你要翻很久,建议收藏。
Kubernetes,简称 K8s,是用 8 代替 8 个字符“ubernete”而成的缩写。是一个开源的,用于管理云平台中多个主机上的容器化的应用。k8s 作为学习云原生的入门技术,熟练运用 k8s 就相当于打开了云原生的大门。本文通过笔者阅读书籍整理完成,希望能帮助想学习云原生、以及正在学习云原生的童鞋快速掌握核心要点。学习 k8s 和大家学习 linux 差不多,看似复杂,但掌握了日常熟悉的指令和运行机理就能愉快的使用了,本文的重点和难点是服务、kubernetes 机理部分。
要点
Kubemetes 采用的是指令式模型, 你不必判断出部署的资源的当前状态, 然后向它们发送命令来将资源状态切换到你期望的那样。你需要做的就是告诉 Kuberetes 你希望的状态, 然后 Kubemetes 会采取相关的必要措施来将集群的状态 切换到你期望的样子。
1:资源:定义了一份资源,意味着将创建一个对象(如 Pod) 或 新加了某种规则(类似于打补丁,NetworkPolicy);
2:每个种类的 资源都对应一个 控制器,负责资源的管理;
3:pod 可以看成远行单个应用的 虚拟机,但可能被频繁地自动迁移而无需人工介入;
集群管理和部署的最小单位。
无状态服务:新的 IP 名和主机地址
有状态服务: StatefulSet, 一致的主机名 和 持久化状态
pod 中应用写入磁盘的数据随时 会丢失 【包括运行时, 容器重启,会在新的写入层写入】
记住,pod 是随时可能会被重启
4:容器重启原因:
进程崩溃了
存活探针返回失败
节点内存耗尽,进程被 OOM
需要 Pod 级别的存储卷, 和 Pod 同生命周期, 防止容器重启丢失数据, 例如挂载 emptyDir 卷,看容器启动日志。
容器重启以指数时间避退,直到满 5 分钟。特别注意,容器重启并不影响 Pod 数量变化【理论上所有 Pod 都是一样,即使换新的 Pod,容器还是会重启】。
5:控制 Pod 的启动顺序;
Init 容器:Pod 中可以有任意多个 initContainers,初始化容器用来控制 Pod 与 Pod 之间 启动 的先后顺序;
就绪探针: 一个应用依赖于另一个应用,若依赖无法工作,则 阻止 当前应用成为服务 端点群内的 pod 访问。
Deployment 滚动升级中会应用 就绪探针, 避免错误版本的出现。
6:localhost 一般指代节点,而非 pod;
7:当 Pod 关闭的时候,可能工作节点上 kube-proxy 还没来得及修改 Iptables,还是会将通信转移到 关闭的 Pod 上去;
推荐是 Pod 等一段时间再关闭【等多长时间是个问题, 和 TCP 断开连接等 2MSL 再关闭差不多】,直到 kube-proxy 已修改 路由表。
8:服务目录可以在 kubernetes 中轻松配置和暴露服务;
9:Kubernetes 可以通过单个 JSON 或 YAML 清单部署 一 组资源;
10:Endpoint, 有站点的意思(URL), REST endpoint, 就是一个 http 请求而已。
Endpoint 资源指 Service 下覆盖的 pod 的 ip:端口列表。
整理
字段
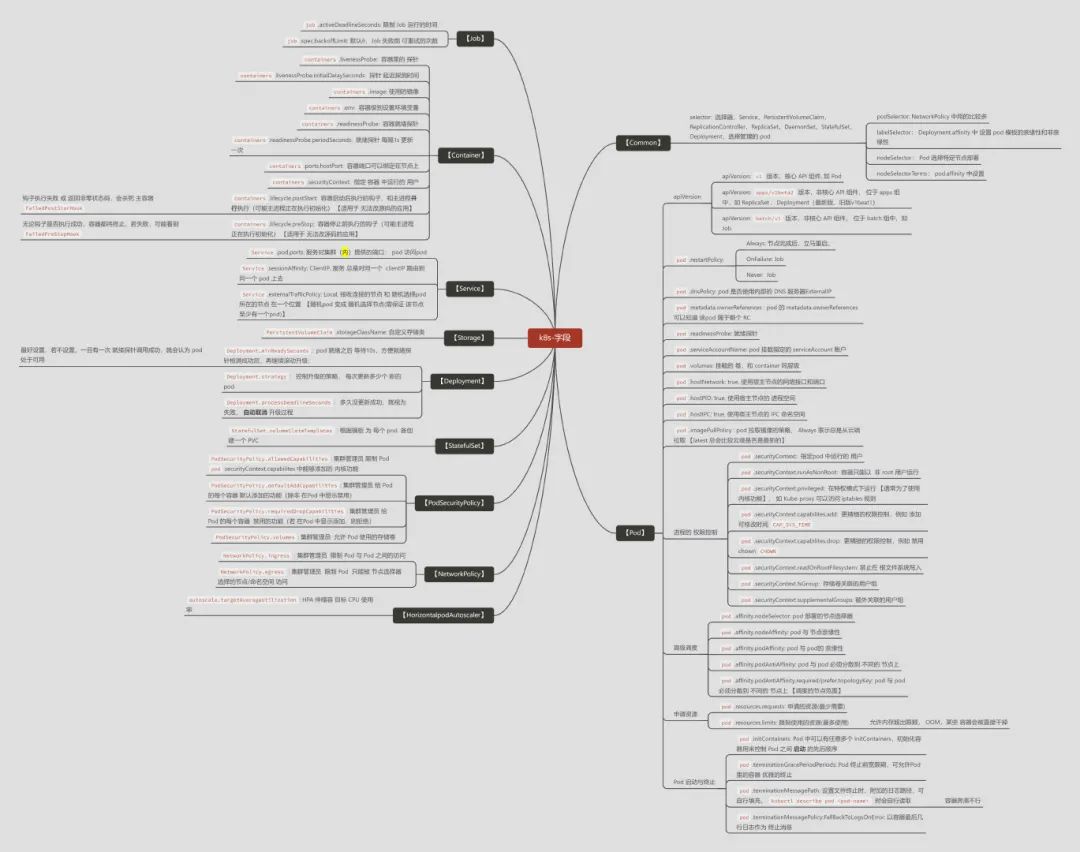
1:在定义 manifest 时, 常用的一些字段罗列如下:
备注:常用字段,非全部。
标注和必知
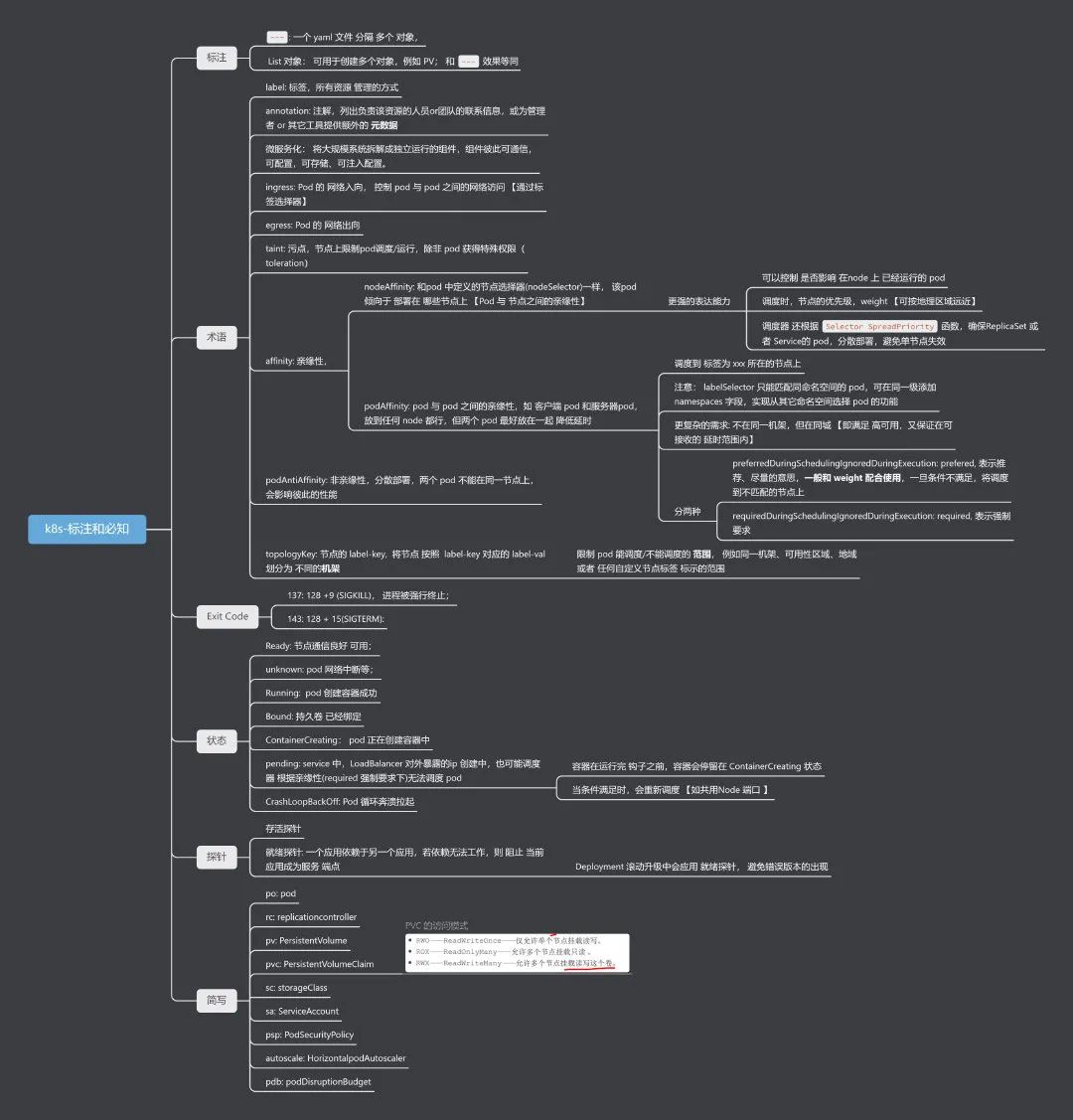
1:常见的注解整列
命名空间和资源
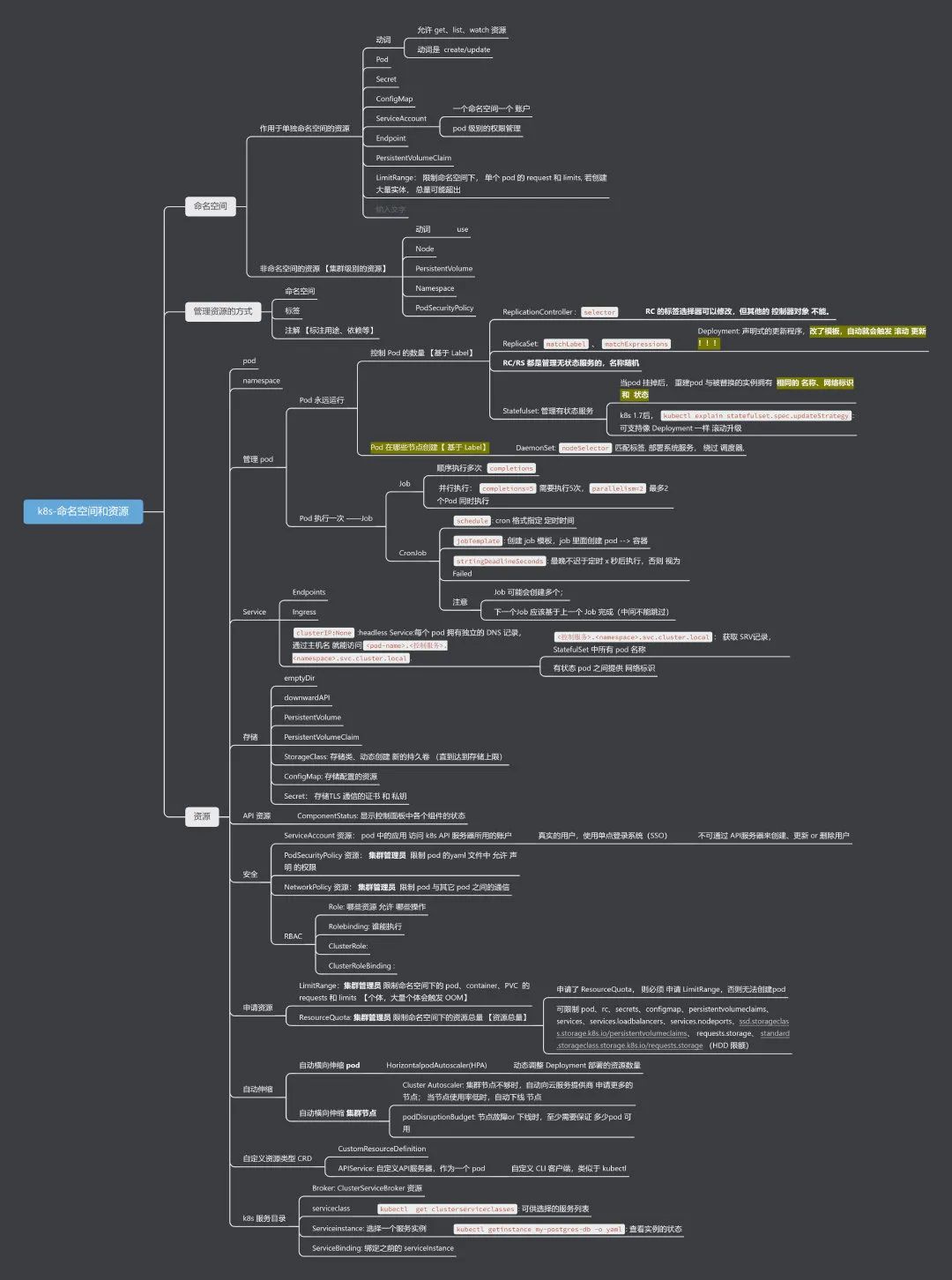
1: k8s 中整理的命名空间和常用资源如下:
常用指令
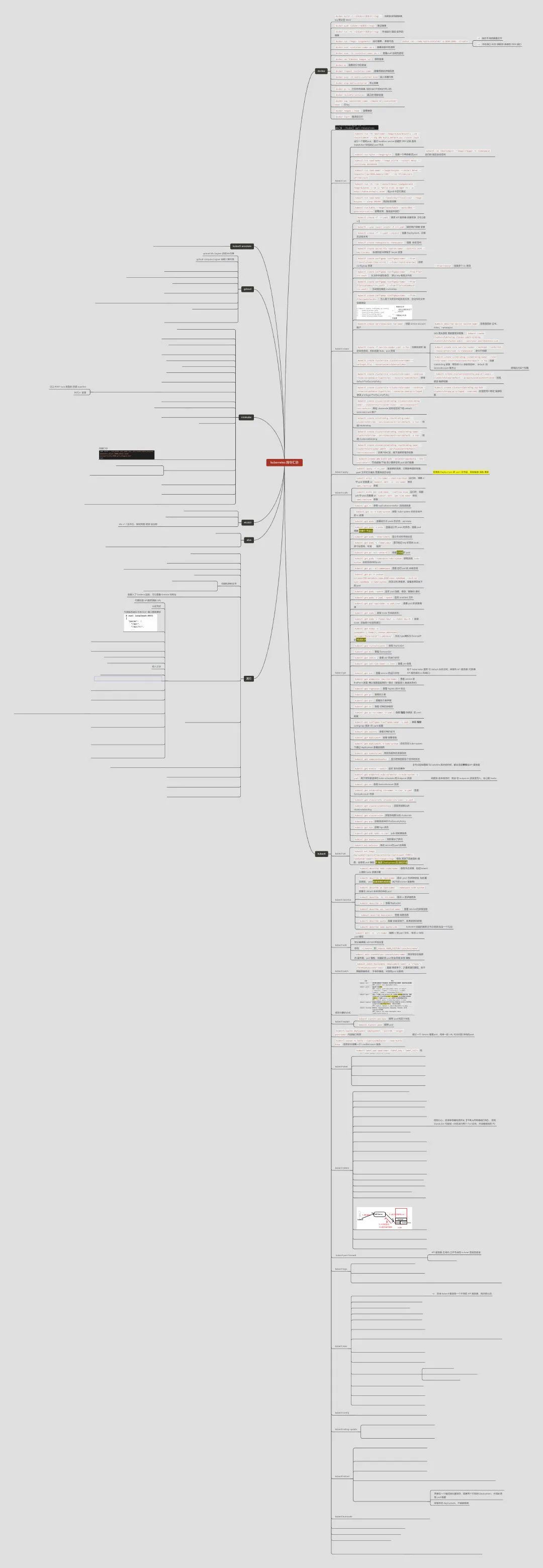
1:梳理常用指令
环境
集群安装
1:单节点集群,minikube
2: 多节点集群,虚拟机 + kubeadm
k8s 介绍
微服务
1:微服务:大量的单体应用 被拆成独立的、小的 组件
2:配置、管理 需要自动化;
3:监控应用,变成了监控 kubernets
传统的应用 由 kubernets 自己去监控
4:拆成微服务的好处:
1: 改动单个服务的 API 成本更小;
2:服务之间可通过 HTTP(同步协议)、AMQP(异步协议)通信;
3:新服务可用不同语言开发;
虚拟机和容器
1:虚拟机多出来的三个部分:
虚拟化 CPU;
用户操作系统;
管理程序:透传虚拟机上应用的 操作指令 到 宿主机上的 物理 CPU 来执行;
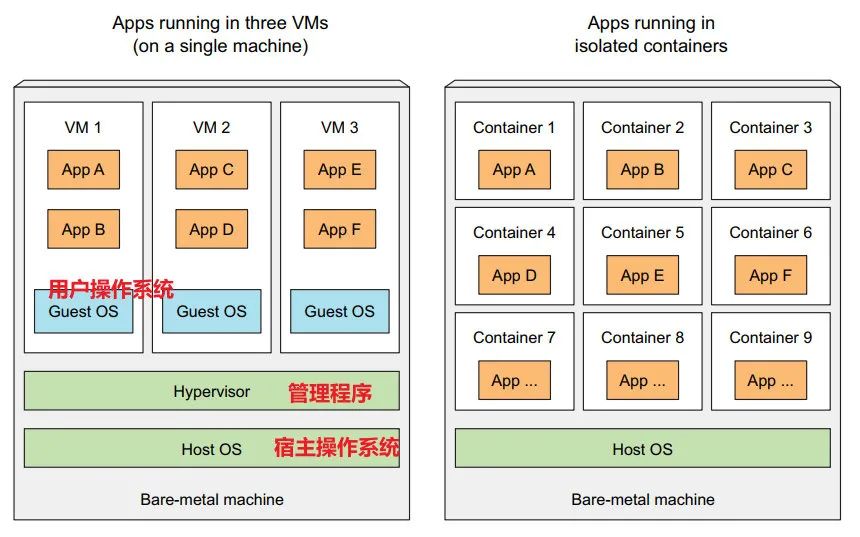
2:容器的隔离机制
Linux 命名空间, 每个进程只能看到自己的系统视图(文件、进程、网络接口、主机名等)
Mount: 挂载卷,存储;
PID:proceess ID , 进程树;
Network:网络接口;
Inter-process communication: IPC, 进程间通信;
UTS:本地主机名;
User ID: 用户。
Linux 控制组 (cgroups), 限制进程能使用的资源量(CPU、内存、网络带宽等)
3:容器限制了 只能使用 母机的 Linux 内核;
X86 上编译的应用 容器化后,不能运行在 ARM 架构的母机上;
Docker
1:Docker:打包、分发、运行应用程序的 ==平台==。
运行容器镜像的 软件,类似于 VMware
简化了 Linux 命名空间隔离 和 cgroups 之内的 系统管理;
镜像:经过 Docker 打包的 环境(包含应用程序的依赖,配置文件,运行 app)
镜像仓库:云端存储;
容器:基于 Docker 创建的运行时环境,是一个 运行在 Docker 主机上的进程, 和其他进程隔离且能使用的资源受限;
2:类似的容器运行时,还有 rock-it;
k8s 组成
1:一个 k8s 分成两类:
master node (主节点):主节点上的组件可以组成一个集群,负责集群的控制和调度
work node (工作节点):工作节点一般是多个,实际部署应用的 节点
2:组件
1:调度器:选择资源足够的 node 分配 pod
节点不够,Cluster Autoscaller 横向扩容节点控制 pod 选在哪个节点上【亲缘性 affinity】pod 要和 哪个 pod 在一块。
2:控制器:跟踪节点状态,复制 pod,持续跟踪 pod, 处理节点失败, 大部分资源都会对应一个 控制器
例如 Endpoint Controller 通知工作节点上的 kube-proxy 修改 iptables 。
本质是一个 死循环,监听 API 服务器的状态;
3:etcd 分布式数据存储,API 服务器将集群配置存入。比如每次提交一个 yaml 文件,校验通过后会存入;
4:kubelete: 接收 API 服务器通知 和 Docker 交互,控制容器的启动 上报 node 的资源总量
5:Docker 容器运行时, 拉取镜像、启动容器
6:pod:
1:独立的 IP 和 端口空间 ;
pod.hostNetwork: true, 使用宿主节点的网络接口和端口;containers.ports.hostPort: 仅把容器端口绑定在节点上。
2:独立的进程树,自己的 PID 命名空间
pod.hostPID: true, 使用宿主节点的 进程空间
pod.hostIPC: true, 使用宿主节点的 IPC 命名空间
3:自己的 IPC 命名空间,同 pod 可以通过进程间通信 IPC
4:同 pod 两个容器,可以共享存储卷
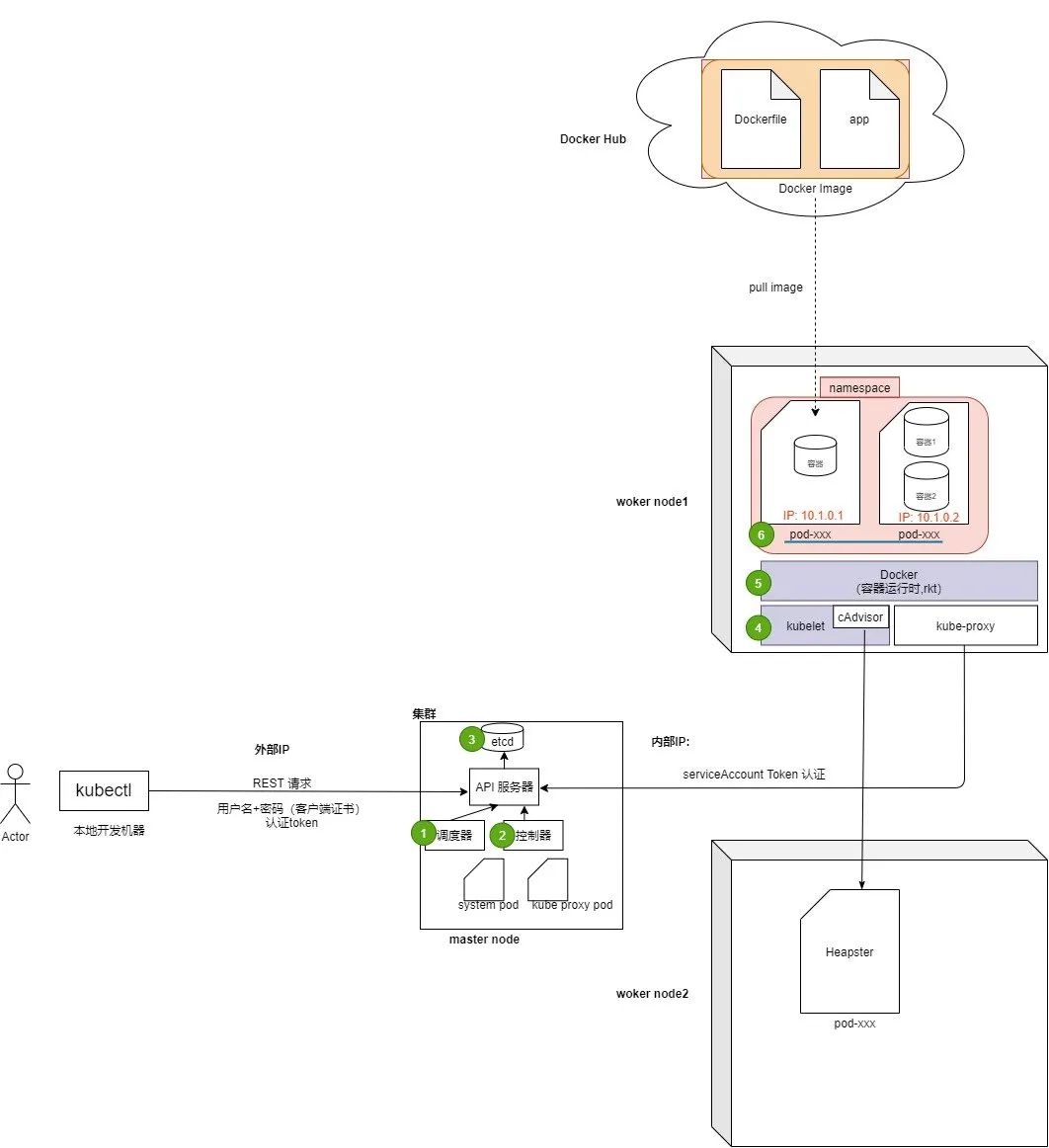
3: k8s 功能
1:自动处理失败 容器:重启, 可自动选择 新的 工作节点。【自修复】
2:自动调整 副本数:根据 CPU 负载、内存消耗、每秒查询 应用程序的其它指标 等;【==自动扩缩容==】
3:容器 移除或移动, 对外暴露的 静态 IP 不变(环境变量 or client 通过 DNS 查询 IP) 【==可实现复杂的 集群 leader 选举==】
4:可以限制某些容器镜像 运行 在指定硬件的机器群 【在 HDDS 系列的机器上选择一个】上:
- HDDS;
- SSD;
Docker 和 k8s
使用 Docker
安装 Docker
1:安装:略
2:docker run <image> :现在本地查找镜像, 若无, 前往 http://docker.io 中 pull 镜像。
其它可用镜像:http://hub.docker.com
# 运行一个镜像,并传入参数
docker run busybox echo "Hello World"
Unable to find image 'busybox:latest' locally
latest: Pulling from library/busybox
b71f96345d44: Pull complete
Digest: sha256:930490f97e5b921535c153e0e7110d251134cc4b72bbb8133c6a5065cc68580d
Status: Downloaded newer image for busybox:latest
Hello World
3:==docker 查看镜像本地是否已存在 --下载镜像-- 创建容器 -- 运行 echo 命令--- 进程终止 --- 容器停止运行;==
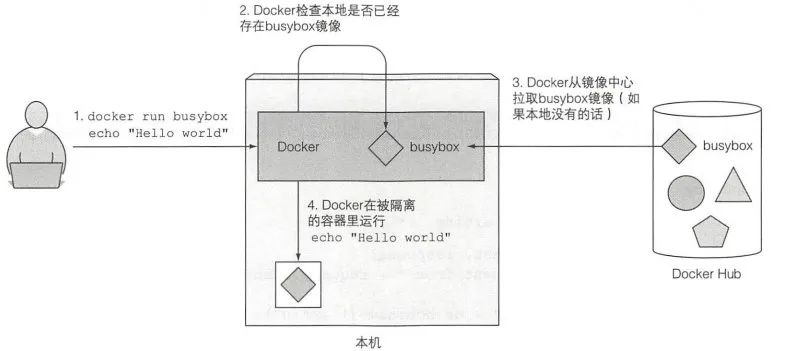
创建应用
1:创建一个简单的 node.js 应用, 输出主机名:
const http = require('http');
const os = require('os');
console.log("Kubia server starting...");
var handler = function(request, response) {
console.log("Received request from " + request.connection.remoteAddress);
response.writeHead(200);
response.end("You've hit " + os.hostname() + "\\n");
};
var www = http.createServer(handler);
www.listen(8080);
2:构建镜像,需要一个 Dockerfile 文件
和 app.js 同一目录
# From 定义了基础镜像,可以是 Ubuntu 等系统,但应尽量遵从精简
FROM node:7
# 本地文件添加到 镜像的根目录
ADD app.js /app.js
# 镜像被运行时 需要执行的命令
ENTRYPOINT ["node", "app.js"]
构建镜像
1:Dockerfile + app.js 就能创建镜像包:
# 基于当前目录 创建 kubia 镜像
$ docker build -t kubia .
Sending build context to Docker daemon 3.072kB
Step 1/3 : FROM node:7
7: Pulling from library/node
ad74af05f5a2: Pull complete
2b032b8bbe8b: Pull complete
a9a5b35f6ead: Pull complete
3245b5a1c52c: Pull complete
afa075743392: Pull complete
9fb9f21641cd: Pull complete
3f40ad2666bc: Pull complete
49c0ed396b49: Pull complete
Digest: sha256:af5c2c6ac8bc3fa372ac031ef60c45a285eeba7bce9ee9ed66dad3a01e29ab8d
Status: Downloaded newer image for node:7
---> d9aed20b68a4
Step 2/3 : ADD app.js /app.js
---> 43461e2e8cef
Step 3/3 : ENTRYPOINT ["node", "app.js"]
---> Running in 56bc0e5982ce
Removing intermediate container 56bc0e5982ce
---> 0d2c12c8cc80
Successfully built 0d2c12c8cc80
Successfully tagged kubia:latest
2: 镜像构建过程
Docker 客户端:在宿主机上的;
Docker 守护进程:运行在一个虚拟机内;【可以在远端机器】
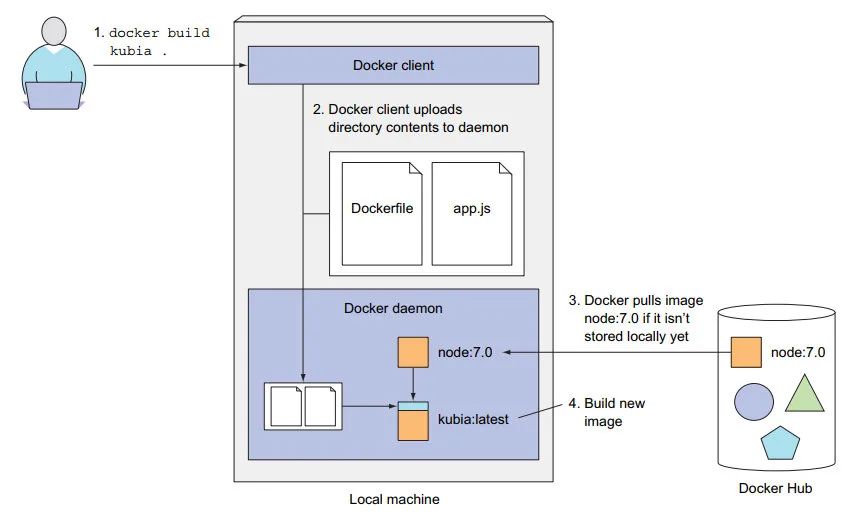
镜像分层
1:Dockerfile 中的的每一行 都会 形成一个 镜像层
最后一层 是 kubia:latest 镜像
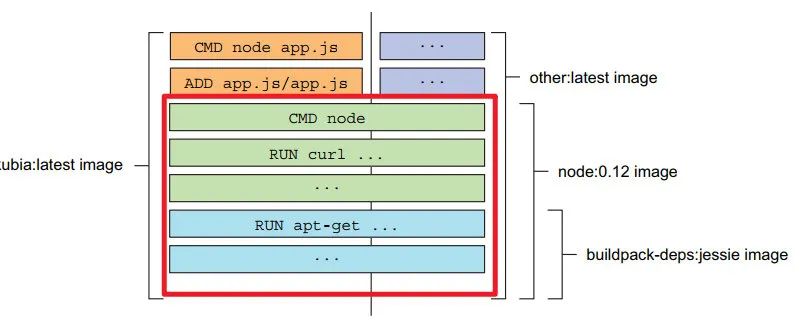
2:镜像分层的好处:节省下载,
3:查看本地新镜像 docker image
运行镜像
1:端口映射后,可用 http://localhost:8080 访问;
# 容器名称 # 本机8080 映射到容器的 8080 端口 # 镜像文件
docker run --name kubia-container -p 8080:8080 -d kubia
4099df6236c5d4905a268b213ab986949f6522122454de41f56293ce3508e958 # 容器 ID
# test,主机名就是 分配的 容器 ID
$ curl localhost:8080
You've hit 4099df6236c5
2: 查看运行中的容器:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
4099df6236c5 kubia "node app.js" 40 seconds ago Up 38 seconds 0.0.0.0:8080->8080/tcp, :::8080->8080/tcp kubia-container
2744c31527b9 gcr.io/k8s-minikube/kicbase:v0.0.22 "/usr/local/bin/entr…" 3 days ago Up 3 days 127.0.0.1:49172->22/tcp, 127.0.0.1:49171->2376/tcp, 127.0.0.1:49170->5000/tcp, 127.0.0.1:49169->8443/tcp, 127.0.0.1:49168->32443/tcp minikube
# 查看容器 详细信息
docker inspect kubia-container
查看容器内部
1:一个容器可以运行多个进程;
2:Node.js 镜像中 包含了 bash shell , 可在容器 内运行 shell :
# kubia-container 容器内 运行 bash 进程
docker exec -it kubia-container bash
# 退出
exit
-i,确保标准输入流保待开放。需要在 shell 中输入命令。-t, 分配一个伪终端(TTY)。
3: 查看容器内的进程;
$ docker exec -it kubia-container bash
root@4099df6236c5:/# ps axuf
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 12 0.6 0.0 20244 2984 pts/0 Ss 21:44 0:00 bash
root 18 0.0 0.0 17496 2020 pts/0 R+ 21:44 0:00 \\_ ps axuf
root 1 0.0 0.6 614432 26320 ? Ssl 21:41 0:00 node app.js
只能在 docker 的守护进程内查看
4:在母机上查看进程
user00@ubuntu:~$ ps axuf | grep app.js
app.js
root 3224898 0.0 0.6 614432 26320 ? Ssl 14:41 0:00 \\_ node app.js
容器和主机上的进程 ID 是独立、不同的;
5:容器 是独立的:
PID Linux 命名空间
文件系统 都是独立的
进程
用户
主机名
网络接口
停止和删除容器
1:停止容器,会停止容器内的主进程。
容器本身依然存在,通过 docker ps -a
docker stop kubia-container
# 打印所有容器, 包括 运行中的和已停止的
$ docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
4099df6236c5 kubia "node app.js" 6 minutes ago Exited (137) 4 seconds ago
# 真正的 删除容器
docker rm kubia-container
向仓库推送镜像
1:仓库 http://hub.docker.com 镜像中心;
2:按照仓库要求,创建额外的 tag
# 个人 ID
docker tag kubia luksa/kubia
# 查看镜像
docker images | head
# 自己的 ID 登录
docker login
# 推送镜像
docker push luksa/kubia
3: 可在任意机器上运行 云端 docker 镜像:
docker run -p 8080:8080 -d luksa/kubia
使用 kubernetes 集群
安装集群的方式
1:安装集群通常有以下四种方式:
本地 单点;
Google Kubernetes Engine(GKE) 上托管的集群;
kubeadm 工具安装;
亚马逊的 AWS 上安装 kubernetes
Minikue 启动 k8s 集群
1:安装略
2:启动 Minikube 虚拟机
minikube start
3: 安装 k8s 客户端(kubectl)
GKE 创建三节点集群
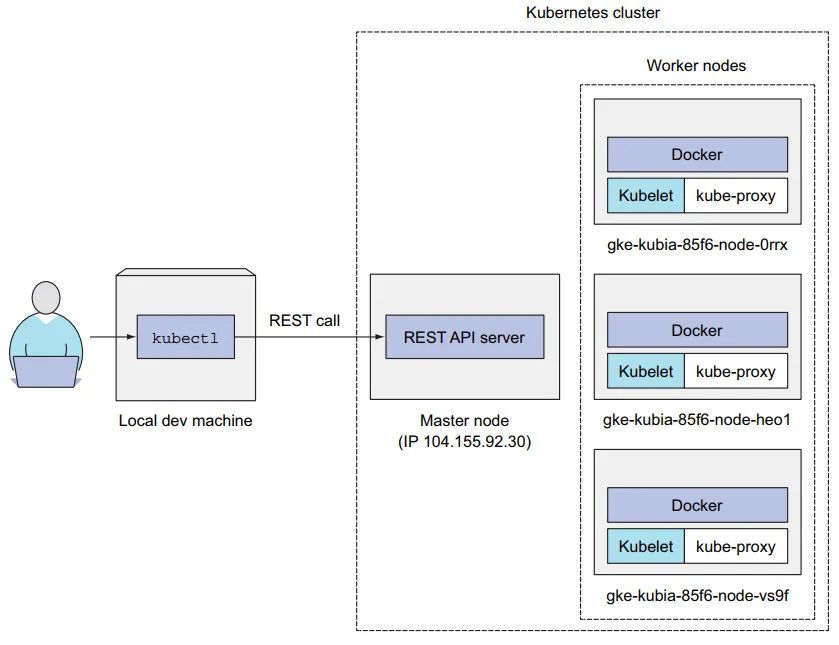
1:创建 3 个工作节点的示例:
gcloud container clusters create kubia --num-node 3 --machine-type f1-micro
2:本地发起请求 到 k8s 的 master 节点;master 节点负责 调度 pod, 以下创建了 3 个工作节点;
部署 Node.js 应用
kubectl run kubia --image=luksa/kubia --port=8080 --generator=run/v1
pod
1: 多个容器运行在一起:
一个 pod 可以包含任意数量的容器;
2:pod 拥有单独的 私有 IP、主机名、单独的 Linux 命名空间;
==Pod 是扩缩容的基本单位;==
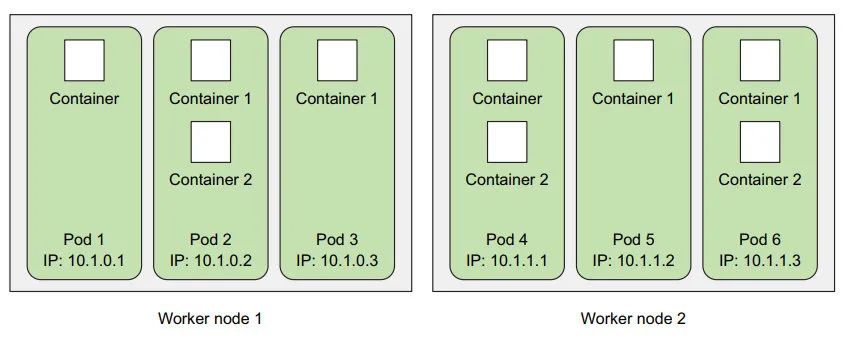
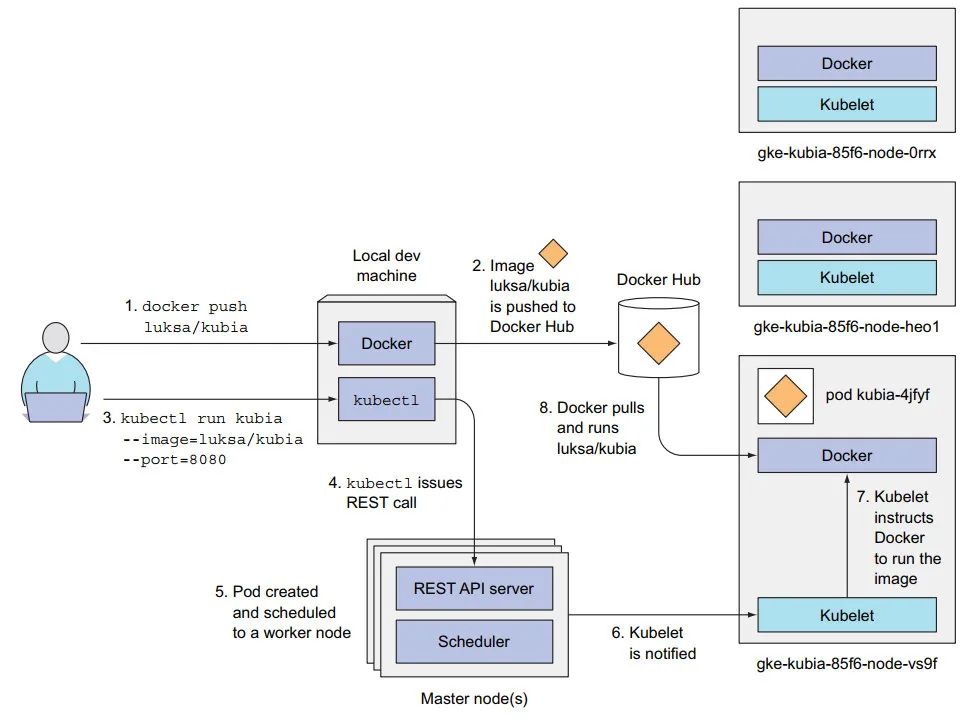
3:k8s 中 运行 容器镜像需要经历两个步骤:
1:推送 docker 镜像 到云端 【不同工作节点上的 Docker 能访问到 该镜像】;
2:运行 kubectl ,==创建一个 ReplicationController 对象 【运行指定数量的 pod 副本】;==
调度器 创建 pod,并 选择一个 工作节点,分配给 pod;
创建外部访问的服务
1:常规服务:ClusterIP 服务, 比如 pod, 只能从 集群内部访问;
2:创建 LoadBalancer 类型的服务,负载均衡,对外提供 公共 IP 访问 pod;
内部删减 pod, 移动 pod,外部 IP 不变, 一个外部 IP 可对应 多个 pod。
kubectl expose rc kubia --type=LoadBalancer --name kubia-http
kubectl get svc # 查看服务是否分配 EXTERNAL-IP(外部IP)
minikube service kubia-http可查看 IP:端口
系统逻辑部分
1:服务、pod、对象:
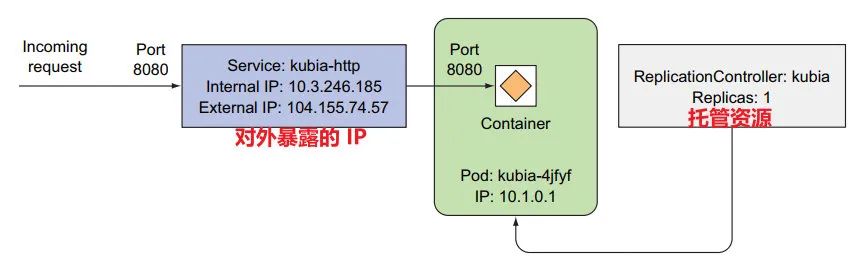
水平伸缩 pod 节点
kubectl get replicationcontrollers # 获取 ReplicationControllers 状态
告诉期望数量即可:
kubectl scale rc kubia --replicas=3
多次访问,服务作为负载均衡,会随机选择一个 pod:
和上面对比,这里有三个 pod 实例。
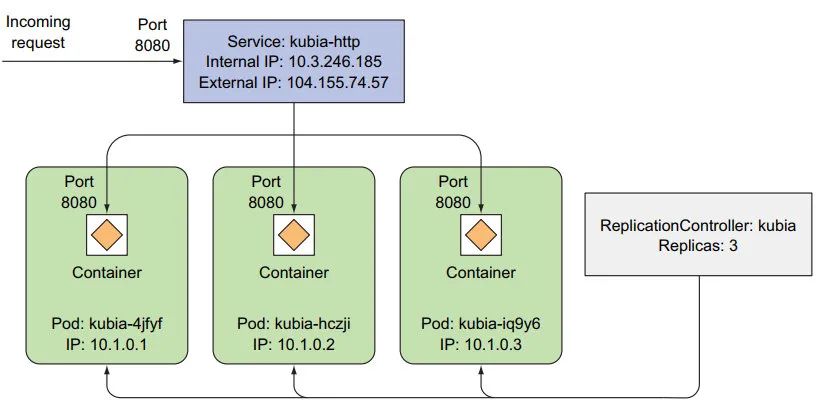
pod 运行在哪个节点上
1: pod 的 IP 和运行的工作节点

$ kubectl describe pod kubia-jppwd
Name: kubia-jppwd
Namespace: default
Priority: 0
Node: minikube/192.168.49.2 # 具体的节点
Dashboard
1:若是 GKE 集群, 可通过 kubectl cluster-info | grep dashboard 获取 dashboard 的 URL。
2:终端输入 minikube dashboard 会自动打开浏览器:
pod
Pod
1: 容器被设计为每个容器只运行一个进程, 保证轻量和一定的隔离性;
2:有些容器又有一些紧密的联系,例如常说的 side-car 容器,负责网络代理,日志采集的容器, 这些容器最好放一起。这就出现了 上层的 pod 。
pod 是 k8s 中引入的概念,docker 是可以直接运行容器的。
3:k8s 通过配置 Docker 让一个 pod 内的所有容器 共享 相同的 Linux 命名空间 【有些容器放到一个 pod 的好处】:
相同的 network 和 UTS 命名空间;
共享相同的主机名和网络接口;pod 中的端口,不能绑定多次;
两个 pod 之间可以实现 两个 IP 相互访问
不管两个 pod 是否在同一节点, 可以想 无 NAT 的平坦网络之间通信(类似局域网 LAN)
相同的 IPC 命名空间下运行;能通过 IPC 进行通信;
共享相同的 PID 命名空间
注意:文件系统来自容器镜像,默认容器的文件系统彼此隔离。
4:pod 是逻辑主机, 其行为与非容器世界中的物理主机或虚拟机非常相似。此外, 运行在同一个 pod 中的进程与运行在同一物理机或虚拟机上的进程相似, 只是每个进程都封装在一个容器之中。
5: pod 可以当做独立的机器,非常轻量, 可同时有大量的 pod;
6: pod 是扩缩容的基本单位;
7: pod 的定义包含三个部分:
metadata 包括名称、命名空间、标签和关于该容器的其他信息 。
spec 包含 pod 内容的实际说明 , 例如 pod 的容器、卷和其他数据 。
status 包含运行中的 pod 的当前信息,例如 pod 所处的条件 、 每个容器的描述和状态,以及内部 IP 和其他基本信息 。
一个简单 pod 包含的三部分:
apiVersion: v1 # 分组和版本
kind: Pod # 资源类型
metadata:
name: kubia-manual # Pod 名称
spec:
containers:
- image: luksa/kubia # 容器使用的镜像
name: kubia
ports:
- containerPort: 8080 # 应用监听的端口
protocol: TCP
8:可使用 kubectl explain 查看指定资源信息
kubectl explain pods
9:创建资源:
# 所有定义的 资源 manifest 都通过该指令来创建,非常重要
kubectl create -f kubia-manual.yaml
10:查看日志:
kubectl logs <pod-name>
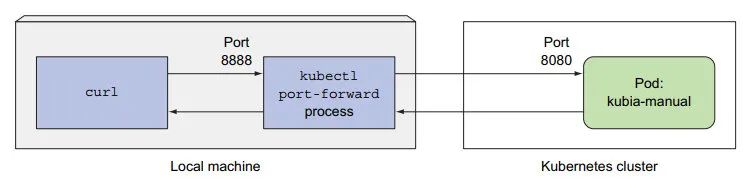
11:若不想通过 Service 与 pod 通信,可通过端口转发:
# 将 8888 端口 转发到 该 pod的 8080 端口
kubectl port-forward <pod-name> 8888:8080
curl localhost:8888
端口转发是
kubectl内部实现的。
标签
1:可使用 标签组织管理 pod
标签也能组织其他 k8s 资源
2:例如定义两组标签,可不同维度管理 pod
label_key = app: 按应用分类label_key = rel: 按版本分类
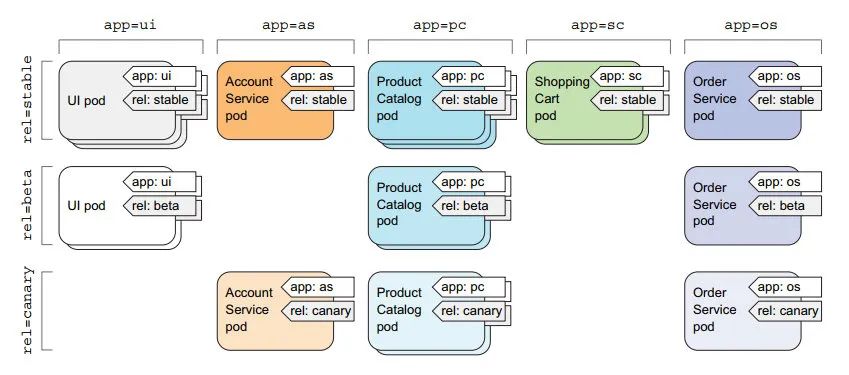
3:pod 中使用 labels 定义标签:
kind: Pod
metadata:
name: kubia-manual-v2
labels:
# 定义的两组标签
creation_method: manual
env: prod
4:可通过 -l 指定标签选择列出 pod 子集:
$ kubectl get po -l creation_method=manual
NAME READY STATUS RESTARTS AGE
kubia-manual-v2 1/1 Running 0 31s
使用多个标签, 中间用 逗号分隔即可。
pod 调度到特定节点
1:默认下,pod 调度到哪个 节点是不确定的,这由调度器决定。
2:有些情况,需要将 pod 调度到特定的节点上(比如偏计算的 pod 需要调度到 gpu 集群上)
3:给节点打标签
kubectl label node <node-name> <label-key>=<label_value>
4:通过 nodeSelector 调度到含有 gpu=true 标签的节点上。
apiVersion: v1
kind: Pod
metadata:
name: kubia-gpu
spec:
# 调度到含有 gpu=true 的节点上
nodeSelector:
gpu: "true"
containers:
- image: luksa/kubia
name: kubia
注意:含有该标签的节点可能有多个,届时将选择其中一个。
候选节点最好是一个集合,避免单个节点故障会造成服务不可用。
注解
1:注解(Annotation)和 标签类似,也是键值对。
有些注解是 k8s 自动添加的。
注解不能超过 256K
命名空间
1:命名空间(namespace, 简称 ns)可对对象分组。
资源名称只需要在命名空间内保证唯一即可, 跨命名空间可以重。
2:列出某个命名空间下的 pod
kubectl get po --namespace kube-system
3:命名空间,可控制用户在该命名空间的访问权限, 限制单个用户可用的 资源数量;
4:创建命名空间:
apiVersion: v1
kind: Namespace
metadata:
name: custom-namespace
5:尽管命名空间对 对象进行了分组, 但 ==并不提供实质上的隔离== ,例如不同命名空间的 pod 能否通信取决于网络策略。
6:删除 pod 有多种方式:
kubectl delete po <pod-name> # 按名称删除
kubectl delete po --all # 删除当前命名空间的所有 pod, 若 ReplicationController 未删除,将重新创建 pods
kubectl delete po -l <label-key>=<label-val> # 按标签删除
kubectl delete ns <ns-anme> # 删除整个命名空间
kubectl delete all --all # 删除当前命名空间内的所有资源,包括托管的 ReplicationController, Service, 但 Secret 会保留
托管集群
保持进程健康
1:进程异常的几种情形:
主进程 崩溃->kubelet 将 重启 容器;
内存泄漏, JVM 会一直运行,但会抛出 OutofMemoryErrors, 让程序 向 k8s 发出信号 触发 重启;
外部检查:应用死循环 or 死锁
存活探针
1:定期检查容器
2:三种探测机制:
HTTP Get 向容器发送请求;
TCP 套接字,与容器建立 TCP 连接;
Exec 探针,在容器内执行任意指令,查看退出状态码;
3:HTTP 探针,定期发送 http Get 请求;
/heath HTTP 站点不需要认证,否则会一直认为失败,容器 无限重启;
apiVersion: v1
kind: Pod
metadata:
name: kubia-liveness
spec:
containers:
# 镜像内有坏掉的应用
- image: luksa/kubia-unhealthy
name: kubia
# 存活探针
livenessProbe:
httpGet:
path: /
port: 8080
4:返回的状态码 137 和 143:
$ kubectl describe pod kubia-liveness
State: Running
Started: Thu, 17 Jun 2021 11:04:53 -0700
Last State: Terminated
Reason: Error
Exit Code: 137 # 有错误码返回
Warning Unhealthy 10s kubelet Liveness probe failed: HTTP probe failed with statuscode: 500
5:探针的附加信息:
查看状态时,可看到 存活探针信息:
Liveness: http-get http://:8080/ delay=0s timeout=1s period=10s #success=1 #failure=3
delay=0s: 容器启动后立即检测;timeout=1s:限制容器在 1s 内响应,否则失败;period=10s:每隔 10s 探测一次;failure=3:连续三次失败后,重启容器;
6:具有初始延迟的 存活探针:【程序还未 启动稳定】
# 第一次探针前,等15s,防止容器没准备好
initialDelaySeconds: 15
7:若无探针, k8s 认为进程还在运行,容器就是健康的。
8:探针的注意事项:
1:探针应该轻量,不能占用太多 cpu 【应 计入 容器的 CPU 配额】, 一般 1s 内执行完;
2:java 程序应该用 http get 探针,而非启动全新 JVM 获取存活信息的 Exec 探针(太耗时)
3:无需设置 探针的失败重试次数, k8s 为了确认一次探测的失败,==默认就会尝试若干次==;
9:重启容器由 kubelet 执行;主服务器上的 k8s Control Plane 组件不会参与;
==若整个节点崩溃, 则无法重启== 【kubelet 依赖于节点】;
若要保证节点挂了,pod 能重启,应该使用 RC 或 RS;
ReplicationController
1: 用于管理 pod 的多个副本;
2:会自动调整 pod 数量为 指定数量:
多余副本在以下几种情况下会出现:
有人会手动创建相同类型的 pod。
有人更改现有的 pod 的 ” 类型” 。
有人减少了所需的 pod 的数量, 等等。
3:ReplicationController 的功能:
确保一 个 pod (或多个 pod 副本)持续运行, 方法是在现有 pod 丢失时启动一 个新 pod。
集群节点发生故障时, 它将为故障节 点 上运 行的所有 pod (即受 ReplicationController 控制的节点上的那些 pod) 创建替代副本。
它能轻松实现 pod 的水平伸缩:手动和自动都可以
4: 根据 pod 是否匹配 标签选择器 来调整:
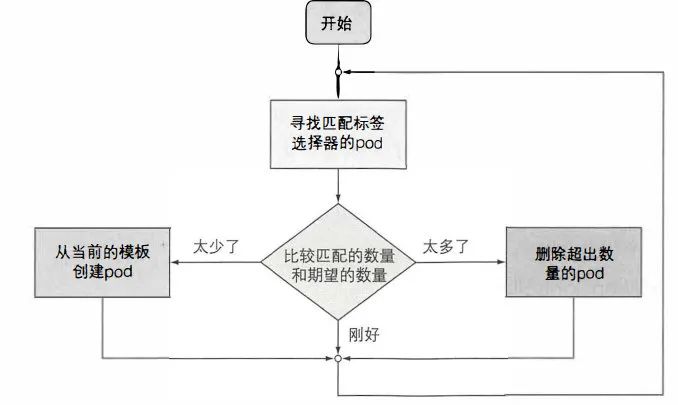
5: 更改标签选择器 和 pod 模板,对当前的 pod 没有影响;
也不关心 容器镜像、 环境变量和 其它;
只影响 创建新的 pod (新的 曲奇 切模 cookie cutter )
修改 pod 模板:
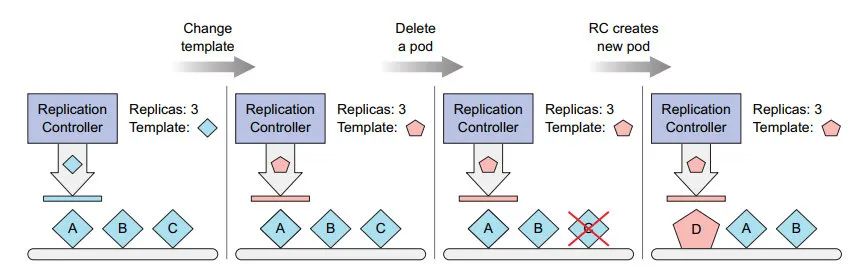
更改副本个数,就能实现动态扩缩容:
kubectl scale rc kubia --replicas=3 # 调整副本数为3
6: 创建对象:
上传到 API 服务器, 会创建 kubia 的 ReplicationController 【简称 RC】。
模板中的 pod 标签 必须 与 RC 一致,否则会无休止创建容器(达不到期望数量的 pod)
API 服务会校验 RC 的定义,不会接受错误配置;
可以不指定 RC 的选择器,会自动根据 pod 模板中的标签自动设置;
apiVersion: v1
kind: ReplicationController
metadata:
name: kubia
spec:
replicas: 3 # pod 副本数量
# 标签选择器,选择 标签 app = kubia的pod进行管理
selector:
app: kubia
# pod 模板
template:
metadata:
labels:
app: kubia
spec:
containers:
- name: kubia
image: luksa/kubia
ports:
- containerPort: 8080
7:删除 pod 标签(或者 移入另一个 RC 的掌控), 脱离 RC 掌控,RC 会自动起一个 新的 pod;
原 pod 可用于调试,完成后,手动删除 该 pod 即可;
实际 pod 数量, RC 通过就绪探针;
删除 pod, 允许 客户端监听到 API 服务器的通知,通过检查实际的 pod 数量 采取适当的措施;
kubectl delete pod <pod-name>
添加 pod 另外的标签, RC 并不 care;
8:通过 pod 的 metadata.ownerReferences 可以知道 该 pod 属于哪个 RC;
9:节点故障:例如网络断开;
RC 一段时间后检测到 pod 关闭(旧节点变为
unknown), 会启动新的 pod 代替原来的 pod;当旧节点恢复时, 节点状态变为
ready,unknownpod 会被删除;
10:更改 RC 的 标签选择器:
原有 pod 都会脱离管控;
RC 会创建(若无)新的指定数量、指定标签 的 pod
==RC 的标签选择器可以修改,但其他的 控制器对象 不能。==
11:删除 RC,默认会删除 RC 管理的 pod
可以使用 选项
--cascade=false保留 pod.
kubectl delete rc <rc-name> --cascade=false
使用 ReplicaSet 替换 ReplicationController
1:ReplicationController 最初是 用于赋值和异常时重新调度节点 的唯一 组件。
2:一般不会直接创建 ReplicaSet , 而是 创建 更高层级的 Deployment 资源时(第 9 章) 自动创建他们。
3:ReplicaSet 功能和 ReplicationController 一样, pod 选择器的 表达能力更强:
ReplicationController 只允许
k和v同时 匹配的标签;ReplicationController 只能匹配单个 kv;
ReplicaSet 基于 标签名 k 匹配;
4:若已经有了 3 个 pod,不会创建任何新的 pod,会将 旧 pod 纳入自己的管辖范围;
基础使用 和 RC 一样简单。
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: kubia
spec:
replicas: 3
selector:
matchLabels:
app: kubia
template:
metadata:
labels:
app: kubia
spec:
containers:
- name: kubia
image: luksa/kubia
5:matchExpressions 更强大的选择器;
selector:
# 标签 需要包含的 key 和 val
matchExpressions:
- key: app
operator: In
values:
- kubia
6:四个有效的运算符 operator:
In: Label 的值 必须与其中 一个指定的 values 匹配。Notln: Label 的值与任何指定的 values 不匹配。Exists: pod 必须包含一个指定名称的标签(值不重要)。使用此运算符时,不应指定 values 字段。DoesNotExist: pod 不得包含有指定名称的标签。values 属性不得指定 。
7: matchLabels 和 matchExpressions 可以同时指定,条件是与的关系。
8:删除 ReplicaSet 也会删除 pod:
kubectl delete rs <rs-name>
DaemonSet: 在每个节点上运行一个 pod
1:需在每个节点上运行日志收集 or 监控:如 k8s 的kube-proxy 进程
2:通过 系统初始化脚本 or systemd 守护进程启动;
3:无期望副本数概念,在 节点选择器下, 运行一个 pod;
和节点绑定在一起:节点下线,并不会再创建 新 pod;
==新节点加入 【添加 节点 label 后】, 匹配节点选择器, 自动创建一个 新的 pod ;==
无意中删除了 该 pod, 会自动创建一个 pod;
4:从 DaemonSet 的 pod 模板 创建 pod
5:通过 节点选择器 nodeSelector 选中 部分节点创建 pod;
apiVersion: apps/v1beta2
kind: DaemonSet
metadata:
name: ssd-monitor
spec:
selector:
matchLabels:
app: ssd-monitor
template:
metadata:
labels:
app: ssd-monitor
spec:
# 节点选择器,选择 标签为 disk=ssd 的节点
nodeSelector:
disk: ssd
containers:
- name: main
image: luksa/ssd-monitor
6: 节点可以设置为 不可调度 【通过调度器控制】, 防止 pod 部署到 该节点;
但 DaemonSet 管理的 pod 作为==系统服务,完全绕过调度器,== 即使 节点是 不可调度的,仍然可以运行系统服务;
7:从节点删除 节点标签, DaemonSet 管理的 Pod 也会被删除:
kubectl label node <node-name> disk=hdd --overwrite
Job:运行单个任务的 pod
1:Job: 一旦任务完成,不重启 容器;
两个地方会重启:
1:job 异常;
2:pod 在执行任务时,被从节点逐出;
2:会重启的资源
job 只有在执行失败的时候才会被重启;
被托管的 ReplicaSet 会重启, Job 若未完成,也会重启。

3:job 资源:
restartPolicy 配置为 Onfailure or Never:完成后 不需要 一直重启
apiVersion: batch/v1
kind: Job
metadata:
name: batch-job
spec:
template:
metadata:
labels:
# Job 未指定 pod 选择器,默认根据 pod 模板中的标签创建
app: batch-job
spec:
# job 不能使用默认的 Always 作为重启策略
restartPolicy: OnFailure
containers:
- name: main
image: luksa/batch-job
4:job 中串行运行多个 pod:
kind: Job
metadata:
name: multi-completion-batch-job
spec:
completions: 5 # 顺序执行 5 次
5:job 中并行运行多个 pod:
spec:
completions: 5 # 需要完成 5 次
parallelism: 2 # 最多同时 2 个并行
6:Job 在运行时,可调整 Job 数量:
kubectl scale job <job-name> --replicas 3
7:限制 Job 完成时间和失败重试次数:
activeDeadlineSeconds: 限制 Job 运行的时间
spec.backoffLimit: 默认 6,Job 失败前 可重试的次数
CronJob: 定期执行
1:时间格式:cron
2: 每隔 15 分钟运行一次:
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: batch-job-every-fifteen-minutes
spec:
# 每15分钟运行一次
schedule: "0,15,30,45 * * * *"
jobTemplate:
spec:
template:
metadata:
labels:
app: periodic-batch-job
spec:
restartPolicy: OnFailure
containers:
- name: main
image: luksa/batch-job
3:时间格式:
分钟
小时
每月中的第几天
月
星期几
4:注意事项
CronJob 根据
jobTemplate创建 job 对象;startingDeadlineSeconds超时未执行 视为 Failed;Job 能被重复执行,可能会被创建多个;
Job 应该是串行的, 中间不能有 遗漏的任务;
服务
1:服务可以说是 k8s 中最复杂的一环。
k8s 集群和普通集群不同的是,
pod 是临时的,随时会被创建和关闭(动态扩缩容)
pod 重启,,会分配新的 IP 地址;
2:Service 资源:外部访问后端 pod, 可提供一个统一可供外部访问的 IP 地址和端口
这里更多的是针对无状态服务,所有 pod 都是对等的, API 服务器只需 随机分配一个 pod
3:应用服务的两种情形:
外部集群 可通过 服务 连接 pod
内部 pod 之间也可通过服务连接
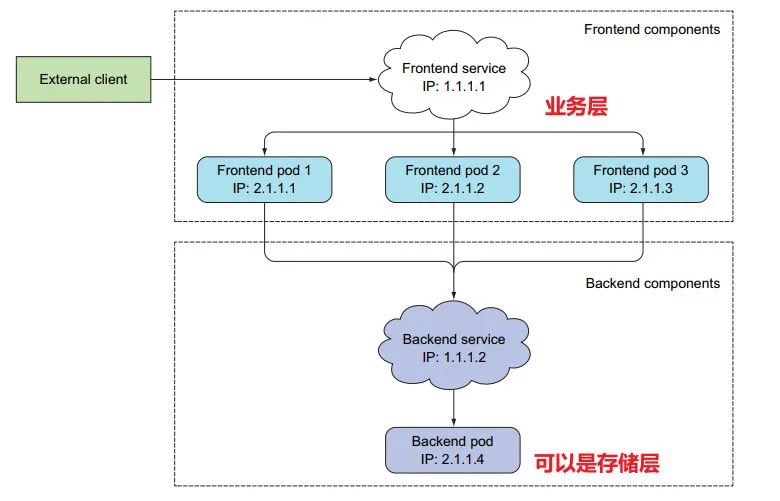
连接集群内部的 Service
4:服可通过标签选择器,选择 需要 连接的 pod
控制 Service 服务的范围。
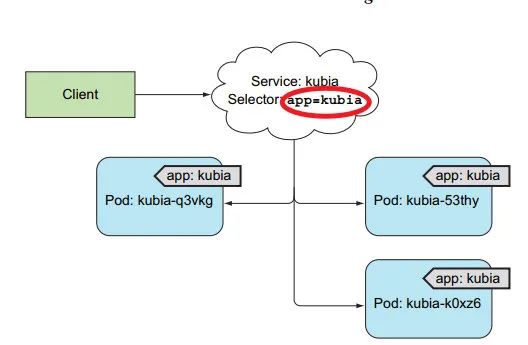
5:服务可通过 kubectl expose 创建,也可通过 yaml 创建。
apiVersion: v1
kind: Service
metadata:
name: kubia
spec:
ports:
# 服务对外的端口
- port: 80
# 服务转发到容器的端口
targetPort: 8080
# 连接pod 集合是带有 app: kubia 标签的 pods
selector:
app: kubia
创建 svc 后,会分配一个 集群 IP,==该 IP 对外不可用==,仅限于 集群内的 pod 访问 【pod 和 pod 之间也可通过 服务连接】。

集群内部测试服务,有三种方法向 Service 发送请求:
创建一个 pod 应用,并向 集群 IP 发送 requests;
ssh 登录到节点上,使用 curl
登录到其中的一个 pod 运行 curl 指令
6:可用 kubectl exec 在远程容器里执行:
user00@ubuntu:~$ kubectl get po
NAME READY STATUS RESTARTS AGE
kubia-jppwd 1/1 Running 0 5m13s
kubia-sxkrr 1/1 Running 0 5m13s
kubia-xvkpg 1/1 Running 0 5m13s
# -- 表示 Kubectl 执行命令的结束
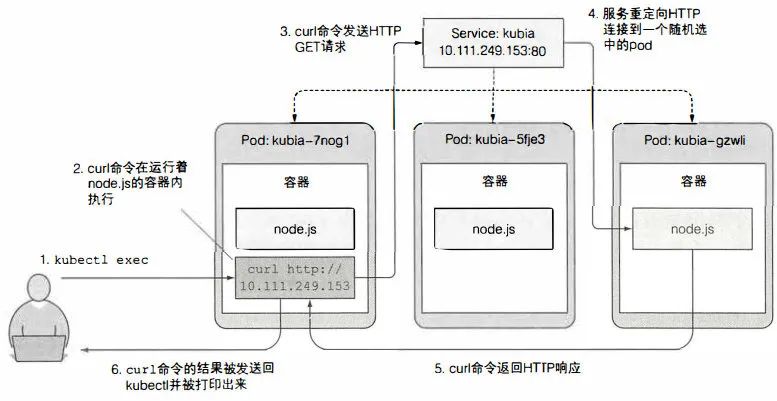
# -s 告诉 kubectl 需要连接不同的 API服务器,而非默认的
user00@ubuntu:~$ kubectl exec kubia-jppwd -- curl -s http://10.105.237.81
curl 的过程如下, Service 选择 pod 是随机选择一个。
7:Service 可以通过设置 sessionAffinity: ClientIP 来让同一个客户端的请求每次指向同一个 pod.
默认值是 None
8:Service 可同时暴露多个端口, 例如 http 请求时, 80 端口映射到 8080, https 请求时, 443 端口映射到 8443
9:在 Service 的生命周期内, 服务 ip 不变。
当 pod 创建时,k8s 会初始环境变量指向现在的 集群 IP
user00@ubuntu:~$ kubectl exec kubia-jppwd env | grep -in service
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
3:KUBERNETES_SERVICE_HOST=10.96.0.1
4:KUBERNETES_SERVICE_PORT_HTTPS=443
# 集群IP 和 端口
7:KUBIA_SERVICE_HOST=10.105.237.81
8:KUBIA_SERVICE_PORT=80
12:KUBERNETES_SERVICE_PORT=443
对应了两个服务:
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d21h
kubia ClusterIP 10.105.237.81 <none> 80/TCP 50m
10:每个 pod 默认使用的 dns:
$kubectl exec kubia-jppwd -- cat /etc/resolv.conf
nameserver 10.96.0.10
search default.svc.cluster.local svc.cluster.local cluster.local localdomain
options ndots:5
pod 是否适用 dns, 由 dnsPolicy 属性决定。
系统命名空间,通常有个 pod 运行 DNS 服务;
$ kubectl get po -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-74ff55c5b-pvqxv 1/1 Running 0 2d21h
11:在 pod 中,可使用全限定域名(FQDN) 来访问 Service。
格式如下:
kubia.default.svc.cluster.local
# kubia: Service 名称
# default: namespace
# svc.cluster.local: 所有集群本地服务中使用的可配置集群域后缀
若在同命名空间下, svc.cluster.local 和 default 可省略。
user00@ubuntu:~$ kubectl exec -it kubia-jppwd bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
root@kubia-jppwd:/# curl http://kubia.default.svc.cluster.local
You've hit kubia-sxkrr
root@kubia-jppwd:/# curl http://kubia.default
You've hit kubia-xvkpg
root@kubia-jppwd:/# curl http://kubia
You've hit kubia-xvkpg
12:集群 IP 是一个 虚拟的 IP, 只有配合服务端口才有意义。
root@kubia-jppwd:/# ping kubia
PING kubia.default.svc.cluster.local (10.105.237.81): 56 data bytes
^C--- kubia.default.svc.cluster.local ping statistics ---
51 packets transmitted, 0 packets received, 100% packet loss
连接集群外部的 Service
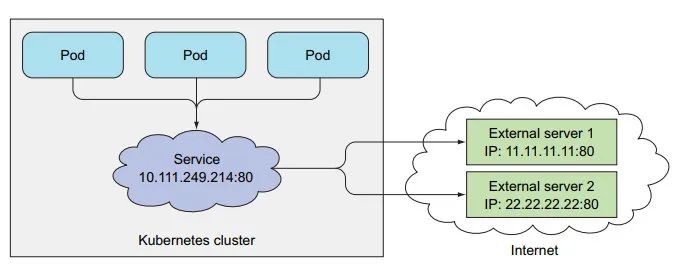
1:让 pod 连接到集群外部。
2:服务并不是和 pod 直接相连,中间有 Endpoint 资源
user00@ubuntu:~$ kubectl get svc kubia
Selector: app=kubia # 创建 endpoint 资源,选择的 pod 标签
TargetPort: 8080/TCP
Endpoints: 172.17.0.3:8080,172.17.0.4:8080,172.17.0.5:8080
Service 通过选择器构建 IP 和 端口 列表,然后存储在 endpoint 资源中
连接时,随机选择其中一个
3:当 Service 无节点选择器时,不会自动创建 Endpoint 资源。
apiVersion: v1
kind: Service
metadata:
# Service 名称,后面会用
name: external-service
spec:
ports:
- port: 80
# 无 选择器
手动指定 Endpoint 注意需要**==和 Service 同名称==**。
apiVersion: v1
kind: Endpoints
metadata:
# 和 Service 同名称
name: external-service
subsets:
# Service 重定向的 IP 地址
- addresses:
- ip: 11.11.11.11
- ip: 22.22.22.22
ports:
- port: 80
通过 endpoint 列表, 可连向其它地址。
4:也可创建具有别名的外部服务:
apiVersion: v1
kind: Service
metadata:
name: external-service
spec:
# 别名
type: ExternalName
externalName: api.somecompany.com
ports:
- port: 80
创建该服务后,内部 pod 可通过 external-service.default.svc.cluster.local 访问外部域名
将服务暴露给外部客户端
1:pod 向外部公开的服务,如 web 服务。
2:有以下几种方式,使外部可访问服务:
服务类型为 NodePort: 每个节点上开放一个端口,访问内部服务 (可被 Service 访问)。
服务类型 为 LoadBalance:NodePort 的一种扩展, 通过负载均衡器访问, 将流量重定向到所有节点的 NodePort;
创建 Ingress 资源:通过一个 IP 地址公开多个 服务 (运行在 HTTP 层)
NodePort
1:创建一个 NodePort 类型的 Service。
apiVersion: v1
kind: Service
metadata:
name: kubia-nodeport
spec:
# 服务类型为 NodePort
type: NodePort
ports:
# 集群IP的端口
- port: 80
# pod 开放的端口
targetPort: 8080
# 不指定端口,将随机选择一个端口
nodePort: 30123
selector:
app: kubia
2:现在可通过以下几种方式访问服务:
user00@ubuntu:~$ kubectl get svc
NAME TYPE CLUSTER-IP
kubia-nodeport NodePort 10.104.119.122 <none> 80:30123/TCP 5m21s
1: <集群 IP>:80
2: 多节点集群
节点 1IP:30123
节点 2IP:30123
注意:即使连到节点 1 的端口, 也可能分配到 节点 2 上执行。
设置
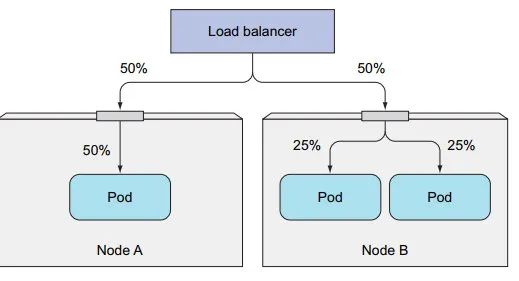
externalTrafficPolicy:local属性,可将 流量路由到当前节点所在的 pod . 若当前节点 pod 不存在,连接挂起。
externalTrafficPolicy:local 不利于负载均衡, 当节点上的 pod 分散不均时。
有个好处是,转发到本地 pod,不用进行 SNAT(源网路地址转换),这会将 改变 源 IP 记录。
开放 NodePort 端口。
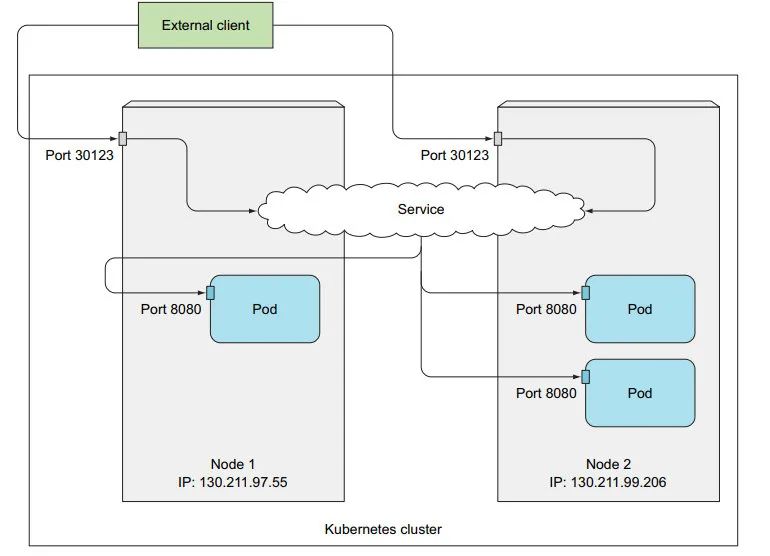
3:获取 节点 IP 【特意观察了下,节点 IP 和 机器 IP 不是一个,但在同一网关下】
user00@ubuntu:~$ kubectl get nodes -o json | grep address
"addresses": [
"address": "192.168.49.2",
可在本地机器上,向 节点IP:nodePort 发送请求:
$ curl http://192.168.49.2:30123
You've hit kubia-jppwd
minikue 可通过网页访问 minikube service <service-name>:

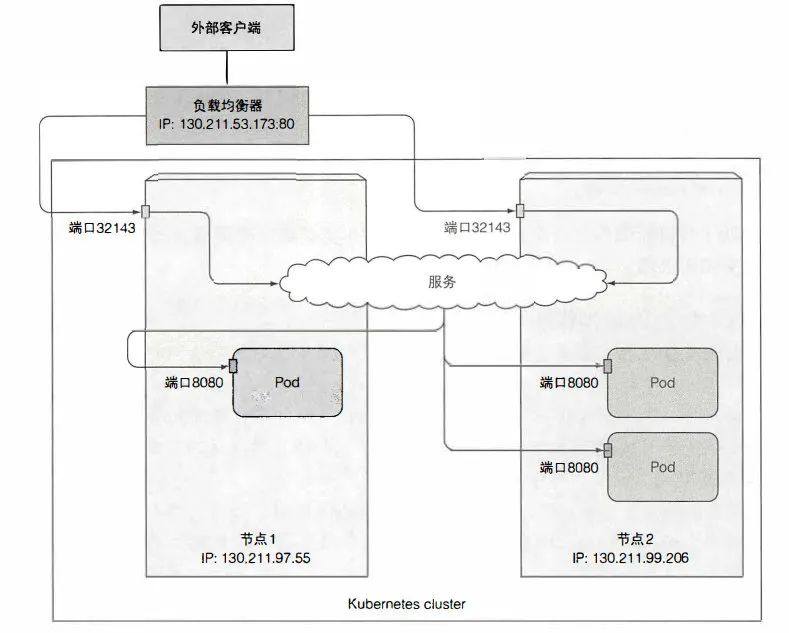
LoadBalancer
负载均衡器在 NodePort 外面包了一层。
1:负载均衡器放在节点前面,将请求传播到 健康的节点。
负载均衡器拥有 自己独一无二的 可公开访问的IP 地址, 并将连接重定向到服务。
apiVersion: v1
kind: Service
metadata:
name: kubia-loadbalancer
spec:
# 负载均衡器类型
type: LoadBalancer
ports:
- port: 80
targetPort: 8080
selector:
app: kubia
若没有指定特定端口,负载均衡器会随机选择一个端口。
$ kubectl get svc | grep load
# <EXTERNAL IP>
kubia-loadbalancer LoadBalancer 10.96.24.178 <pending> 80:30600/TCP 11m
2:创建服务后,要等待很长时间, 才能将 外部 IP 地址写入对象。
可通过外部 ip 直接访问:
curl http://<EXTERNAL IP>
3:可以通过 浏览器访问,但每次访问都是一个 pod, 即使 Session Affinity 设为 None
因为浏览器采用 keep-alive 连接,而 curl 每次开新连接。
4:请求连的时候, 会连接到负载均衡器的 80 端口, 并路由到某个节点上分配的 NodePort 上,随后转发到 一个 pod 实例上。
本质还是打开了 NodePort,仍能继续使用 节点IP:隐式 NodePort 端口访问:
$ curl http://192.168.49.2:30600
You've hit kubia-sxkrr
Ingress
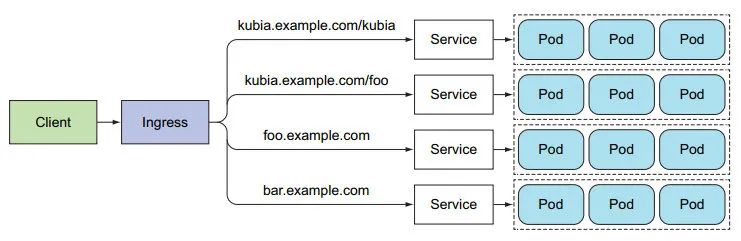
1:Ingress 也可对外暴露服务,准入流量控制。
2:Ingress 工作在 HTTP 层,通过一个 主机名 + 路径 就能转到不同的服务
而 每个 LoadBalancer 服务需要自己的负载均衡器和独有的 公有 IP 地址。
工作在更高层次的协议层,可以提供更丰富的服务。
ingress 可以绑定 ==多主机、同主机多路径。==
3:启用 Ingress 资源需要 Ingress 控制器。
通过
minikube addons list确认。
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: kubia
spec:
rules:
- host: kubia.example.com
http:
paths:
- path: /
backend:
# 将 kubia.example.com/ 请求转发到 nodeport 服务
serviceName: kubia-nodeport
servicePort: 80
4:kubia.example.com 访问服务的前提是 域名能正确解析为 ingress 的 IP。
$ kubectl get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
kubia <none> kubia.example.com 192.168.49.2 80 70s
然后再 /etc/hosts 加入映射:
root@ubuntu:~# cat /etc/hosts
127.0.0.1 localhost
127.0.1.1 ubuntu
192.168.49.2 kubia.example.com
通过地址访问:
# 必须 配置 hosts,直接通过 ingress IP 访问是不行的,无法知道访问的是哪个服务
$ curl http://kubia.example.com
You've hit kubia-xvkpg
5:ingress 访问流程如下:
以上是关于一文深入理解 Kubernetes的主要内容,如果未能解决你的问题,请参考以下文章