DSGN 解读用于三维目标检测的深度立体几何网络
Posted AI 菌
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DSGN 解读用于三维目标检测的深度立体几何网络相关的知识,希望对你有一定的参考价值。

摘要
大多数最先进的3D物体探测器严重依赖于激光雷达传感器,因为基于图像的方法和基于激光雷达的方法之间存在很大的性能差距。这是由于在三维场景中对预测的表示方式造成的。我们的方法,称为深度立体几何网络(DSGN),通过在一种可微分的体积表示(3D几何体)上检测3D目标来显著缩小这一差距,该方法有效地编码了3D规则空间的3D几何结构。通过这种表示,我们可以同时学习深度信息和语义线索。我们首次提供了一种简单有效的基于立体的单级三维检测管道,以端到端学习的方式联合估计深度和检测三维物体。我们的方法优于之前基于立体的3D检测器(AP高出10%),甚至在 KITTI 3D 物体检测排行榜上与几种基于雷达的方法取得了相当的性能。
一、引言
在本文中,我们提出了一种基于立体的端到端三维物体检测管道(如图1)——深度立体几何网络(DSGN),它依赖于从2D特征到有效的三维结构的空间转换,称为3D几何体积(3DGV)。

这种体积表示有两个主要优点。首先,它很容易施加像素对应约束,并将全深度信息编码到3D真实体中。其次,它为3D表示提供了几何信息,这使得学习真实世界对象的3D几何特征成为可能。据我们所知,目前还没有明确研究如何将3D几何图形编码到基于图像的检测网络中。我们的贡献概括如下:
- 为了弥补2D图像和3D空间之间的鸿沟,我们在平面扫描体中建立立体对应,然后将其转换为3D几何体,以便能够同时编码3D几何和语义线索,以便在3D规则空间中进行预测。
- 我们设计了一个端到端的pipeline,用于提取像素级特征用于立体匹配,高层特征用于目标检测。该网络联合估计场景深度和检测3D世界中的3D对象,使许多实际应用成为可能。
- 我们简单且完全可区分的网络性能优于官方Kitti排行榜上的所有其他立体式3D对象检测器(AP高出10%)。
二、动机
由于透视的作用,随着距离的增加,物体会显得更小,这使得根据物体大小和背景的相对比例来粗略估计深度成为可能。然而,同一类别的3D物体仍然可能有不同的大小和方向,这大大增加了准确预测的难度。
此外,透视的视觉效果导致附近的三维物体在图像中缩放不均匀。一辆普通的长方体汽车看起来像一个不规则的截锥。这两个问题对二维神经网络模拟二维成像和真实三维物体之间的关系提出了重大挑战。因此,与其依赖2D表示,通过反转投影过程,中间3D表示为3D目标理解提供了更有效的方法。
基于点云的表示方法。目前最先进的pipeline通过深度预测方法生成点云的中间三维结构,并应用基于激光雷达的三维目标探测器。主要可能的缺点是它涉及多个独立的网络,在中间转换过程中可能会丢失信息,使三维结构(如成本量)浓缩为点云。这种表示方法经常在物体边缘附近遇到条纹伪影。此外,对于多目标场景,网络难以区分。
基于体素的表示方法。体积表示作为另一种三维表示方法,研究较少。OFT-Netmono 直接将图像特征映射到3D体素网格,然后将其折叠到鸟瞰视图上的特征。但是,这个转换保持了该视图的2D表示,并没有显式编码数据的3D几何。
我们的优势。建立有效的三维表示的关键在于对三维空间的三维几何信息进行编码。立体相机为计算深度提供了一个明确的像素对应约束。为了设计一个统一的网络来利用这一约束,我们探索了能够同时提取用于立体对应的像素级特征和用于语义线索的高级特征的深度架构。
另一方面,像素对应约束被认为是沿着通过每个像素的投影射线施加的,深度被认为是确定的。为此,我们利用双目图像对创建一个中间平面扫描体来学习相机视锥架上的立体对应约束,然后将其转换为三维空间中的三维体。在这个带有从平面扫描体中提取的三维几何信息的三维体中,我们能够很好地学习真实物体的三维特征。
三、深度立体几何网络
在这个小节中,我们描述了我们的整体pipeline——深度立体几何网络(DSGN),如图2所示。以双目图像对
(
I
L
,
I
R
)
(I_L, I_R)
(IL,IR)为输入,利用连体网络提取特征,构造平面扫描体积(PSV)。像素对应是在这个体积上学习的。通过可微变形将PSV转化为三维几何体积(3DGV),建立三维世界空间中的三维几何。
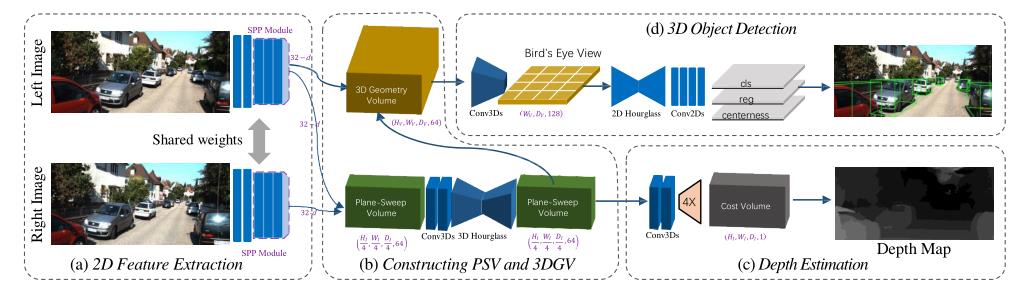
3.1 图像特征提取
用于立体匹配[22、4、15]和对象识别[16、43]的网络针对其各自的任务具有不同的体系结构设计。为了保证合理的立体匹配精度,我们采用了PSMNet的主要设计[4]。
由于检测网络需要基于高级语义特征和大上下文信息的判别特征,我们对网络进行修改以获取更高级的信息。另外,之后的3D CNN进行cost volume aggregation的计算量要大很多,这给了我们修改2D feature extractor的空间,而不会给整个网络带来额外的沉重的计算开销。
网络体系结构的细节。对2D特征提取器的关键修改如下:
- 将更多的计算从conv 3转移到conv 4和conv 5,即将conv 2到conv 5的基本块数从3,16,3,3改变为3,6,12,4。
- PSMNet中使用的SPP模块连接了conv 4和conv 5的输出层。
- 卷积conv 1的输出通道数为64,而不是32。基本残块的输出通道数为192,而不是128。
3.2 构建三维几何体
为了学习三维规则空间中的三维卷积特征,我们首先通过将平面扫描体变形到三维规则空间来创建一个三维几何体(3DGV)。在不丧失一般性的前提下,我们将三维世界空间中感兴趣的区域离散为一个三维体素占用网格(Wv、Hv、Dv),网格沿相机视图的右、下、前方向分布。Wv、Hv、Dv 分别表示栅格的宽度、高度和长度。每个体素的大小 (Vw, Vh, Vd)。
Plane-Sweep 体。在双目视觉,一对图像 ( I L , I R ) (I_L,I_R) (IL,IR)是用于构造disparity-based成本体积计算匹配代价, 匹配一个像素 i在左边图像 I L I_L IL和对应右边的图像 I R I_R IR水平转移的积分差距值d。视差和深度成反比。
以不同的方式构造代价体积,我们遵循经典的平面扫描方法,通过连接左侧图像特征 F L F_L FL和重投影的右侧图像特征 F R − > L F_R−>L FR−>L等间隔的深度间隔来构造平面扫描体,这避免了特征到3D空间的不平衡映射。
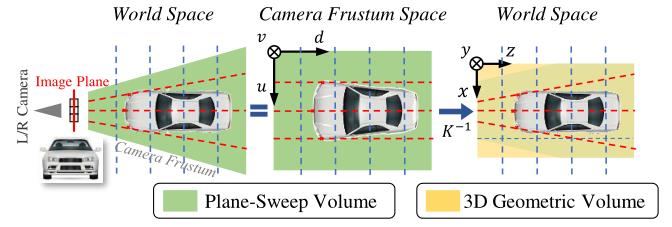
三维几何体积。在已知摄像机内部参数的情况下,通过逆三维投影,将计算匹配代价前的PSV最后一个特征映射从摄像机视锥空间(u, v, d)转换为三维世界空间(x, y, z)

其中fx, fy 是水平和垂直焦距。此变换是完全可微的,并通过消除预定义栅格(如天空)外部的背景来节省计算。它可以通过三线性插值的变形操作来实现。
图3说明了转换过程。在相机视锥体中引入常见的像素对应约束(红色虚线),在规则的三维世界空间(欧几里得空间)中学习目标识别。这两种表述显然有区别。
3.3 深度回归
为了计算平面扫描体积上的匹配代价,我们将平面扫描体积的最终特征映射减少两个三维卷积,得到一维代价体积(称为planessweep cost volume)。soft-arg-min用于计算所有深度候选的期望。
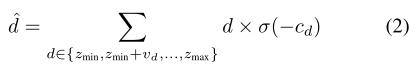
其中深度候选点在预定义网格[zmin, zmax]内均匀采样,间隔为vd。softmax作为激活函数,为每个像素选择一个深度平面。
3.4 三维目标检测
受最近的单级2D检测器FCOS[46]的启发,我们在pipeline中扩展了中心分支的思想,并设计了基于距离的策略来为现实世界分配目标。由于3D场景中同类物体大小相近,所以我们仍然保留了锚的设计。
基于距离的目标任务。考虑到目标的面向性,提出了基于距离的目标分配方法。距离定义为锚与真实边界框之间8个角的距离:

为了平衡正负样本的比例,我们让距离ground-truth最近的前N个锚点作为正样本,其中N = γ×k, k为鸟瞰图ground-truth box内体素的数量。γ调节阳性样本的数量。中心度定义为8个角的负归一化距离的指数为:
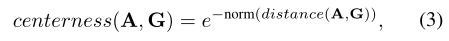
四、多任务训练
我们的网络具有立体匹配网络和三维目标检测器,采用端到端方式进行训练。我们训练了具有多任务损失的整体三维物体检测器为:
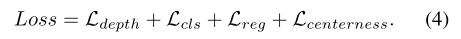
对于深度回归的损失,我们在该分支中采用Smooth L1作为损失函数:

其中,
N
D
N_D
ND是地面真实深度的像素数(从稀疏激光雷达传感器获得)。
对于分类的丢失,我们在网络中采用focal loss[31]来处理3D世界中的类不平衡问题:
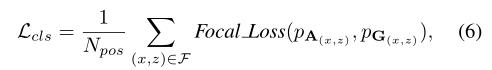
其中,
N
p
o
s
N_pos
Npos表示正样本的数量。
对于3D包围盒回归的损失,用光滑L1 loss作为对包围盒的回归:

其中,
F
p
o
s
F_pos
Fpos表示鸟瞰图中所有的正样本。
在我们的实验中,我们对Car使用第二个回归目标,对行人和自行车使用第一个回归目标。因为即使是人也很难从图像中准确预测或标注物体的方向,比如行人,联合优化下的其他参数估计会受到影响。
五、实验
5.1 训练
默认情况下,模型训练在4个批大小为4的NVIDIA Tesla V100 (32G) GPU上,即每个GPU保存一对384 × 1248大小的立体图像。我们应用Adam[23]优化器,初始学习率为0.001。我们为50个时代训练我们的网络,学习速率在50个时代下降了10%。整个训练时间大约为17小时。所使用的数据增强仅为水平翻转。
5.2 主要结果
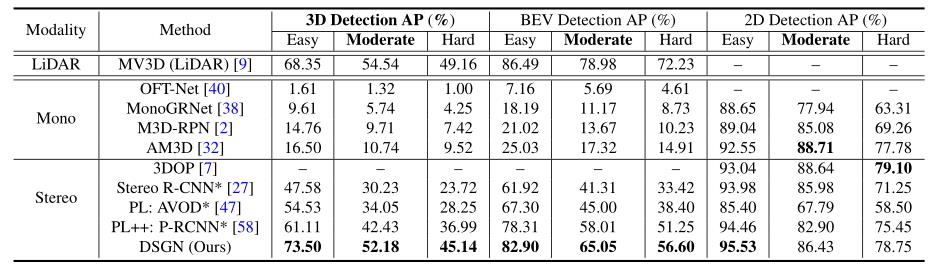
在KITTI测试集(官方KITTI排行榜)上进行比较,使用KITTI排行榜上的新评估指标进行评估。3D检测精度、鸟瞰图检测精度、2D检测精度分别如下:
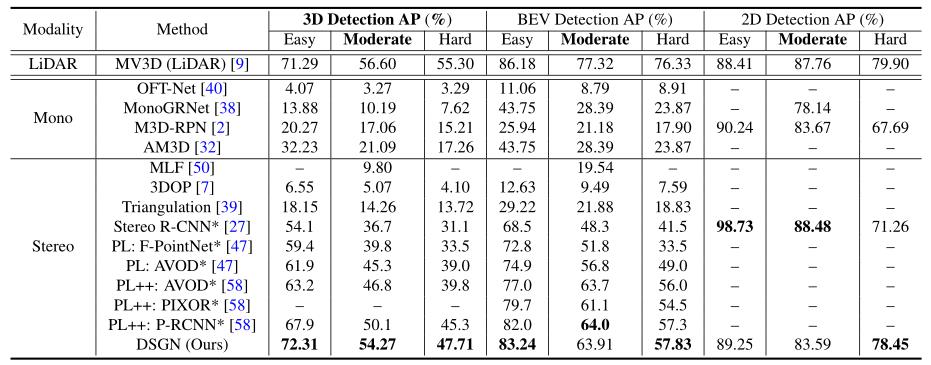
在KITTI验证集(官方KITTI排行榜)上进行比较,检测效果对比如下:
5.3 推理时间
在NVIDIA Tesla V100 GPU上,每对图像的DSGN推断时间平均为0.682s,其中左右图像的二维特征提取时间为0.111 s,构造平面扫描体和三维几何体的时间为0.285s,在三维几何体上的三维目标检测时间为0.284s。DSGN算法的计算瓶颈在于三维卷积层。
5.4 消融实验
消融深度编码方法的研究。 如下表所示,“Supervision”一栏中的“PSCV”和“3DV”分别表示在(plane-sweep) cost volume和3D volume中施加约束。结果评价为中等水平。
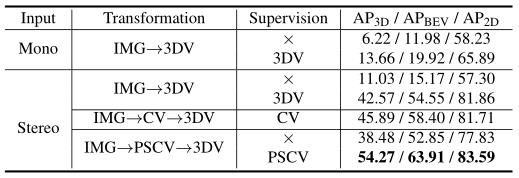
对深度估计的影响, 评价KITTI val 图像。PSMNet-PSV * 是PSMNet的一个变体,考虑到有限的内存空间,它使用一个3D沙漏模块而不是三个沙漏模块进行优化,并采用平面扫描方法来计算成本。

六、总结
我们提出了一种新的基于双目图像的三维目标检测器。结果表明,基于端到端立体的三维目标检测是可行和有效的。我们的统一网络通过将平面扫描体转换为三维几何体来编码三维几何。因此,它能够学习三维体上三维物体的高质量几何结构特征。联合训练让网络学习像素和高级特征,以完成重要的立体对应和三维目标检测任务。
在没有附加功能的情况下,我们的单阶段方法优于其他基于图像的方法,甚至在3D目标检测方面可以与一些基于激光雷达的方法相比。消融研究调查了表3中训练3D体积的几个关键部件。虽然改进是明确的和解释,我们的理解如何3D体转换工作将在我们未来的工作中进一步探索。
以上是关于DSGN 解读用于三维目标检测的深度立体几何网络的主要内容,如果未能解决你的问题,请参考以下文章
IDA-3D 解读基于实例深度感知的自动驾驶立体视觉三维目标检测
IDA-3D 解读基于实例深度感知的自动驾驶立体视觉三维目标检测
Stereo R-CNN 解读基于立体R-CNN的自动驾驶三维目标检测
Stereo R-CNN 解读基于立体R-CNN的自动驾驶三维目标检测