Disp R-CNN解读通过形状先验引导的立体三维目标检测实例视差估计
Posted AI 菌
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Disp R-CNN解读通过形状先验引导的立体三维目标检测实例视差估计相关的知识,希望对你有一定的参考价值。

摘要
最近的许多工作通过视差估计恢复点云,然后应用3D探测器解决了这一问题。视差图是为整个图像计算的,这是昂贵的,并且不能利用特定类别的先验。相反,我们设计了一个实例视差估计网络 iDispNet,它仅仅为感兴趣的目标区域里的像素预测视差,并且学习类别特定的形状先验,以便更准确的估计视差。
为了解决训练中视差标注不足的问题,我们提出在不需要雷达点云的情况下,使用统计形状模型生成密集视差伪真值,这使得我们的系统具有更广泛的适用性。在KITTI数据集上进行的实验表明,即使在训练时不使用雷达数据,Disp R-CNN 也达到了具有竞争力的性能,在平均精度方面比以前的先进方法高出20%。
代码开源:https://github.com/zju3dv/disprcnn
一、引言
三维物体检测方法以估计的视差图为输入,将其转换为深度图或点云来检测其中的物体。然而,由于视差估计网络是为一般的立体匹配而设计的,而不是为三维目标检测任务,这些管道有两个主要的缺点:
- 首先,视差估计过程是在全图像上进行的,在低纹理或非lamberterian表面,如车辆表面,往往不能产生准确的视差,而这些区域正是我们需要进行3D边界框估计的区域。
- 此外,由于图像中感兴趣的前景物体通常比背景物体占用更少的空间,视差估计网络和3D检测器在目标检测不需要的区域花费了大量的计算时间,导致运行速度较慢。
在这项工作中,我们的目标是探索如何用一个专门用于3D目标检测的视差估计模块来解决这些缺点。我们认为,从网络特征学习和运行效率的角度来看,在全图像上估计视差是次优的。为此,我们提出了一个名为 Disp R-CNN 的新系统,该系统通过一个用于实例级视差估计的网络来检测三维物体。视差估计只在包含感兴趣对象的区域执行,从而使网络聚焦于前景对象,并学习适合于3D对象检测的类别特定的形状先验。
实验表明,在物体形状先验的指导下,估计的实例视差捕获了物体边界的平滑形状和锋利边缘,而且比完整帧的对应值更准确。通过实例级视差估计的设计,在视差估计过程中减少了输入和输出像素的数量,减少了代价量搜索的范围,从而减少了整体三维检测框架的运行时间。
综上所述,本文的贡献如下:
- 提出了一种基于实例级视差估计的立体三维目标检测框架,该框架在精度和运行速度上均优于目前最先进的基线。
- 伪真值(pseudo-ground-truth)生成过程,为实例视差估计网络提供监督,并指导它事先学习物体形状,有利于三维目标检测。
二、方法
给定一对立体图像,目标是检测所有感兴趣对象实例的三维边界框。如下图所示,我们的检测管道由三个阶段组成:首先检测每个对象的二维边界框和实例掩码,然后仅估计属于对象的像素的视差,最后使用3D检测器从实例点云预测三维边界框。
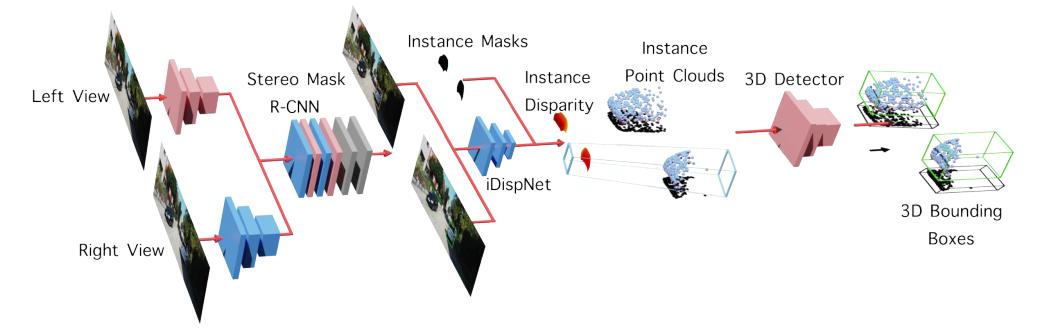
2.1 Stereo Mask R-CNN
Stereo Mask R-CNN 由两个阶段组成。第一阶段是 Stereo R-CNN 中提出的区域建议网络的立体变形,其中来自左右图像的对象候选框从同一组锚生成,以确保左右感兴趣区域(RoIs)之间的正确对应。第二阶段使用 Mask R-CNN 中提出的 RoIAlign 从特征地图中提取对象特征,接下来是两个预测头,生成2D边界框、分类分数和实例分割掩码。
2.2 Instance Disparity Estimation Network
视差估计模块负责立体三维目标检测中三维数据的恢复,其精度直接影响到三维检测性能。iDispNet只将目标RoI图像作为输入,只对前景像素进行监督,从而捕获特定类别的形状先验,从而产生更准确的视差预测。
正式地说,一个像素p的全帧视差定义为:
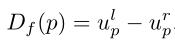
其中,
u
p
l
u_p^l
upl 和
u
p
r
u_p^r
upr 分别表示点 p 在左右视图中的水平像素坐标。通过 Stereo Mask R-CNN 获得的 2D 边界框,我们可以从完整图像中裁剪出左、右RoIs,并将它们在水平方向上对齐。将每个
R
O
I
s
(
w
l
,
w
r
)
ROIs (w^l, w^r)
ROIs(wl,wr) 的宽度设置为较大的值,以使两个roi共享相同的大小。
一旦 ROIs 对齐,左边图像(参考)像素 p 的视差位移从全帧视差变为实例视差,定义为:
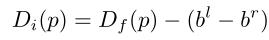
其中,
b
l
b^l
bl 和
b
r
b^r
br 分别表示两个视图中边界框的左边界坐标。我们的目标本质上是了解每个属于感兴趣对象 p 的实例差异
D
i
(
p
)
D_i(p)
Di(p)而不是
D
f
(
p
)
D_f(p)
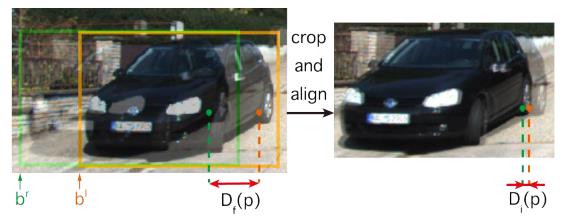
Df(p)。这种裁剪和对齐的过程如下图所示。
将左右两幅图像中的所有roi调整为共同大小 H × w。对于实例分割掩码给出的属于一个对象实例
O
O
O 的所有像素 p,定义实例视差的损失函数为:
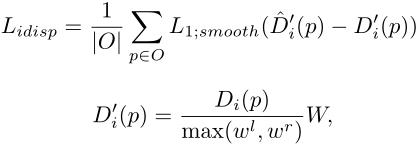
其中,
D
^
i
′
(
p
)
\\hatD'_ i(p)
D^i′(p)为点 p 预测的实例视差,
D
i
′
(
p
)
D'_ i(p)
Di′(p)是实例视差真值。
w
l
w^l
wl 和
w
r
w^r
wr表示两个视图中二维边界框的宽度,|O|表示属于对象
O
O
O的像素数。
一旦 iDispNet 输出实例视差
D
^
i
′
(
p
)
\\hatD'_ i(p)
D^i′(p),我们就可以计算出属于前景的每个像素 p 的3D位置,作为接下来的3D检测器的输入。三维坐标(X, Y, Z)推导如下:
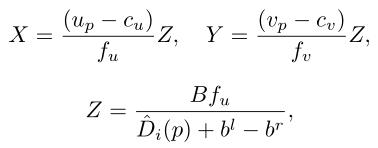
其中,B 是左右相机之间的基线长度,
(
c
u
,
c
v
)
(c_u, c_v)
(cu,cv)为相机中心对应的像素位置,
(
f
u
,
f
v
)
(f_u, f_v)
(fu,fv) 分别为水平焦距和垂直焦距。
2.3 Pseudo Ground-truth Generation
训练立体匹配网络需要大量密集视差地面真值,而大多数3D目标检测数据集都不提供这些数据,因为手动标注很困难。
得益于iDispNet只需要对前景预测,我们提出了一种在不需要LiDAR点云的情况下,为真实数据生成大量密集视差伪真值(Pesudo-GT)的有效方法。生成过程通过特定类别的形状先验模型来实现,从该先验模型可以重构对象形状并随后将其渲染到图像平面以获得密集的视差真实值。
我们使用体积截断符号距离函数(TSDF)作为形状表示。对于形状变化相对较小的一些刚性物体类别(如车辆),该类别的TSDF形状空间可以用低维子空间来近似。形式上,用子空间的基V表示,它由训练形状的前导主成分得到,平均形状表示为µ,实例的形状
φ
~
\\widetildeφ
φ
可以表示为:
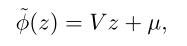
其中 z ∈ R K z∈R^K z∈RK是形状系数,K是子空间的维度。
给定一个实例的三维边界框ground-truth和点云,可以通过最小化以下代价函数来重建实例的形状系数z:
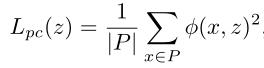
其中 φ(x, z) 为三维点x在形状系数z定义的TSDF体积中的内插值,P为实例对应的点云,|P|为点云中的点数。只有z在优化过程中被更新。直观地说,这个代价函数最小化点云到由 TSDF 的零点定义的物体表面的距离。点云可以从现成的视差估计模块或选择性的激光雷达点获得。
由于上述代价函数不限制物体形状的三维维度,我们提出以下维度正则化项,以减少物体溢出三维边界框的发生:
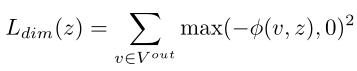
其中
V
o
u
t
V^out
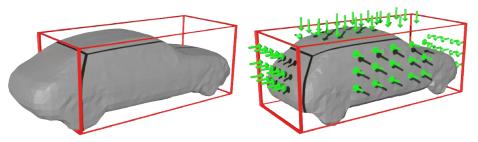
Vout表示在一个卷中定义在3D边界框之外的所有体素。尺寸正则化可视化如下图所示:
为了将形状系数限制在一个适当的范围内,使用以下正则化项来惩罚优化形状与平均形状的偏差:
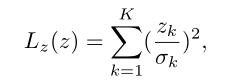
其中,
σ
k
σ_k
σk 是第k个主成分对应的第k个特征值。
综合以上各项,总成本函数为:
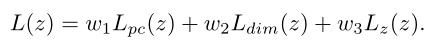
最后,根据优化后的物体形状渲染实例视差伪GT
D
i
D_i
Di 可以根据优化后的物体形状进行渲染如下:
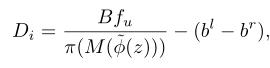
其中,M表示移动立方体操作,该操作将TSDF体积转换为三角形网格。π表示生成像素级深度地图的网格渲染器。下图显示了渲染视差伪GT的一些示例:

2.4 3D detection network
在我们的实现中,PointRCNN[27]被用作3D对象检测器。与传统方法输入整个场景的点云不同,我们使用由实例视差转换的实例点云作为PointRCNN的输入。输入点云子样本减少到768个。
三、实验
3.1 KITTI上3D目标检测
KITTI目标检测基准包含7481幅训练图像和7518幅测试图像。为了评估训练集,我们将其分为训练和验证集,分别包含3712和3769张图像。目标被分为三个层次: 简单,中等和困难,这取决于他们的二维边界框大小,遮挡,和截断程度。
如下表所示,在KITTI简单模式下,我们的方法获得了超过23.57%的改进 A P b e v AP_bev APbev,IOU值为0.7。这种巨大的改进来自 pseudo-GT,即使在训练时没有LiDAR真值,它可以提供大量的训练数据。
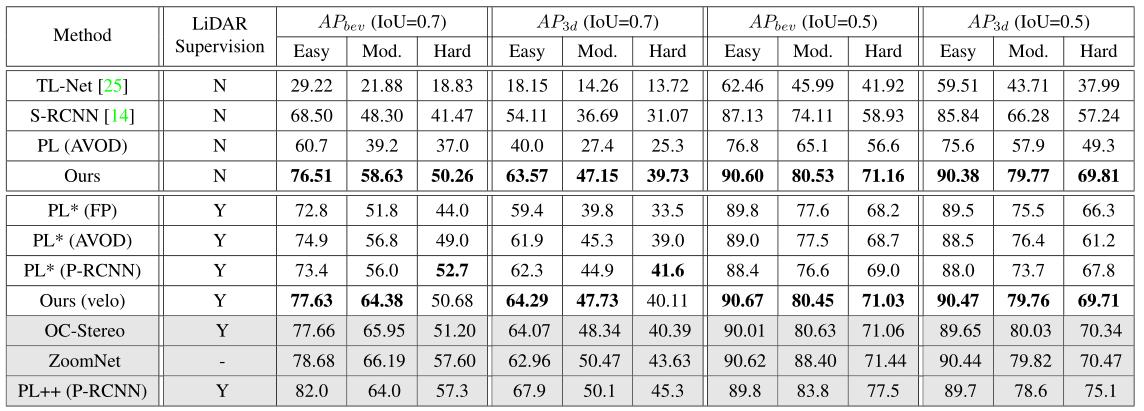
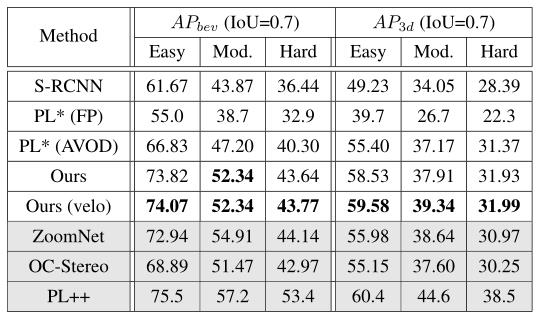
如下表所示,本文的方法比 PL*(AVOD)在IOU=0.7,简单模式和中等模式下的
A
P
b
e
v
AP_bev
APbev分别高7%和5%。并且,在简单模式下
A
P
3
d
AP_3d
AP3d提升4%。
下图展示了物体检测、实例视差估计和视差伪GT的一些定性结果:

3.2 消融研究
如下表所示,以伪GT作为真值,我们的iDispNet比全帧PSMNet获得更小的视差和深度误差。使用稀疏的激光雷达点作为真值,我们的iDispNet仍然比全帧方法PSMNet和最先进的深度立体方法GANet性能更好,尤其是在对象深度RMSE误差方面。
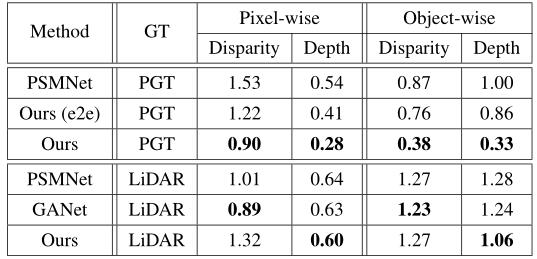
比较第二行和第三行,结果表明:重复使用从RPN中提取的特征限制了估计视差图的质量,这导致iDispNet的端到端版本给出次优结果。
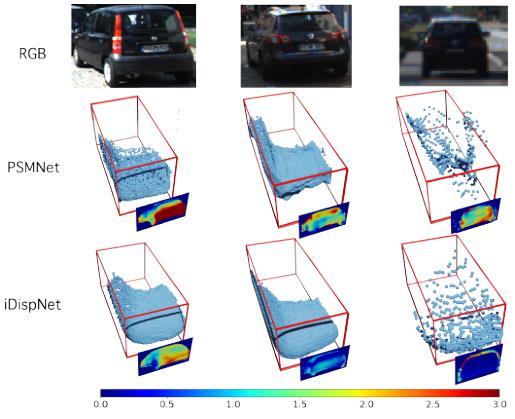
下图显示了实例视差估计的一些定性结果以及与全帧视差估计的比较。全帧PSMNet无法捕捉车辆的平滑表面和锐边,因此导致以下3D探测器难以从不准确的点云预测正确的边界框。相比之下,由于实例视差估计和视差伪GT的监督,我们的iDispNet提供了更准确和稳定的预测。
3.3 运行时间
显示了我们的方法与其他立体方法的运行时间比较。我们的方法需要0.425s,几乎超过了所有以前的立体方法。具体来说,我们的方法0.17s用于二维检测和分割,0.13s用于实例视差估计,0.125s用于从点云进行三维检测。这种效率归因于仅估计ROI中的视差和仅从实例点云中估计3D边界框,这大大减少了搜索空间。

3.4 失败案例
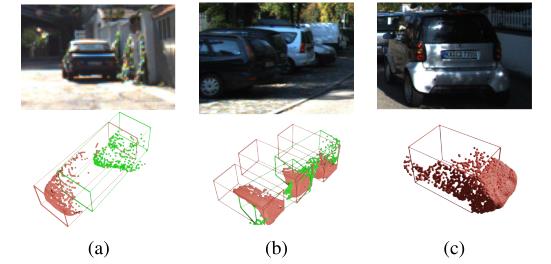
下图展示了一些故障案例,我们的3D对象检测方法最有可能在距离太远的对象上失败,如图7(a)所示,或者在图7(b)所示的强遮挡或截断情况下失败。原因是这些对象上的3D点太少,检测器无法预测正确的边界框。我们的伪GT生成最有可能在形状异常的物体上失败,如图7(c)中的汽车,它比其他汽车短得多。
四、总结
本文提出了一种基于立体图像的三维目标检测方法。关键思想是仅在检测到的二维边界框中估计实例级别的像素级视差,并基于从实例视差转换而来的实例点云检测对象。为了解决训练数据的稀缺性和稀疏性,我们提出将从CAD模型中学习到的形状先验知识整合起来,生成伪GT视差作为监督。在KITTI数据集的3D检测基准上的实验表明,我们提出的方法在很大程度上优于现有的方法,特别是在训练时没有激光雷达监控的情况下。
大家好,我是【AI 菌】,更多精彩内容可关注公众号:
以上是关于Disp R-CNN解读通过形状先验引导的立体三维目标检测实例视差估计的主要内容,如果未能解决你的问题,请参考以下文章
Stereo R-CNN 解读基于立体R-CNN的自动驾驶三维目标检测
Stereo R-CNN 解读基于立体R-CNN的自动驾驶三维目标检测